CNN으로 만든 image classifier model을 보면 한 번 학습할 때 사용된 training dataset에 있는 class에 대해서만 분류가 가능하고 완전히 새로운 clas에 속하는 것을 학습하려면 아예 새로 학습을 시키던지, class의 개수를 늘려서 model의 output 부분을 바꾸던지 해야했다. 그것은 지속적으로 누적되는 실제 세계의 데이터에 대해서 기존의 model이 큰 비효율성을 갖고 있다는 문제를 시사한다. 이를 해결하고자 여러 새로운 학습 전략에 대한 방법론이 발표되었지만 각자 어느 정도 한계를 갖고 있었다. 그런 한계를 타파하고자 제시된 학습 전략 방법론으로 iCaRL이 있다.
간단 요약
iCaRL은 기존의 CNN image deep learning model이 가진
1. 다룰 수 있는 data representation의 고정
2. 점진적인 data scale에 대한 대응 불가능
이라는 한계를 극복하고자 제시된 image deep learning 학습 방법론이다. 특히 incremental learning에 대한 선행 연구들이 기존의 CNN 구조와 호환되지 않았던 한계도 고성능의 classifier와 data representation을 모두 학습하는 것으로 극복했다.
이 논문에서는 CIFAR-100과 ImageNet ILSVRC2012 학습 데이터를 이용해 iCaRL을 활용한 모델이 장기간에 걸쳐 많은 class를 학습할 수 있음을 보였다. (이론적으로 iCaRL 기반의 모델은 무한히 많은 class를 학습할 수 있다.)
Intro
이론적 배경
Incremental learning
https://ffighting.net/deep-learning-paper-review/incremental-learning/all-about-incremental-learning/
위 링크의 내용을 좀 참고해서 Inremental learning이 무엇인지 알아보았다.
단순하게 생각하면, deep learning model이 기존에 학습하지 않았던 새로운 데이터에 대해서만 추가로 학습할 수는 없을지에 대한 요구 사항이 반영된 것이다. 예를 들어, 동물의 종을 분류하는 image classifier model 있다고 했을 때 처음에 개, 고양이, 호랑이, 원숭이, 토끼 이렇게 학습을 시켜놨다고 해보자. 여기에 새로운 종으로 늑대가 발견되면 그 늑대에 대한 학습 데이터만 추가하는 것이 Incremental learning의 개념이라고 생각하면 된다.
이러한 Incremental learning에도 여러 연구 방향성이 있는데 그 중 Distillation(data 정제 과정)과 Memory(memory 사용 효율성)에 관한 연구로써 이뤄진 것이 iCaRL이다.
iCaRL 방법론은 Class-Incremental learning을 위해서 아래와 같은 방법을 사용한다.
scenario class-incremental learning
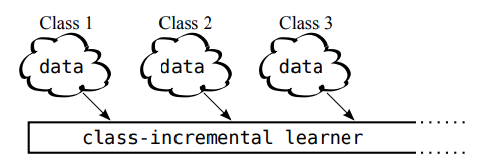
위 그림에서 보면 class-incremental learner가 점진적으로 진행되면서 새로운 class의 dataset을 학습하는 모양을 볼 수 있다. 이를 data stream을 학습하는 class-incremental learning이라 하여 scenario class-incremental learning이라 한다.
논문에서는 Incremental learning을 위해서 아래 요구 사항을 만족해야 한다고 한다.
1. 서로 다른 시간대에 존재하는 다른 class의 예시가 있는 data sream을 학습할 수 있다.
2. 지금까지 학습한 classes에 대해서 언제든지 우수한 multi-classifier 성능을 제공할 수 있다.
3. 필요한 계산 요구 사항과 메모리 공간의 범위과 제한적이거나 최소한 학습 데이터가 늘어남에 따라 천천히 증가하는 효율성이 있어야 한다.
기존의 연구들에 비해서 iCaRL은 1~3의 요구 조건을 충분히 만족하고 있으며, 아래의 구성 요소를 이용해 이를 구현했다고 말한다.
- Nearest-Mean of Exemplars classification
- Herding(군집화)에 기반한 prioritized exemplar selection
- representation learning using knowledge distillation and prototype rehearsal
위의 요소들이 iCaRL의 핵심 요소이며 각각에 대해서는 하나 씩 다음 챕터에서 설명하고자 한다.
data representation, representation learning
https://89douner.tistory.com/339
https://gggggeun.tistory.com/111
https://ebbnflow.tistory.com/276
위 링크의 내용들을 참고했다.
Data representation이란 DNN의 관점에서 어떻게 data를 표현하느냐, 즉 어떤 input 데이터를 어떻게 processing하여 representation할 것인지에 대한 문제를 말한다. 우리가 사칙연산을 할 때 로마자 표기보다는 아라비아식 숫자 표기를 선호한다는 점에서 information representation은 task의 난이도에 기여하는 바가 크다. 따라서 DNN에서도 가능하면 task의 난이도를 낮추기 위해 데이터 표현 방식을 최적화할 필요가 있는 것이다.
Data representation을 DNN의 관점에서 재해석하면, 다음과 같다.
image classifier model을 만드는 task라면,
해결해야하는 task는 image를 알맞은 category로 분류하는 것이고
문제를 해결하는 주체(알고리즘)은 linear classifier이고
task로 주어진 data는 image이고
그 image를 CNN을 이용해서 processing하여 data를 linear vector로 표현해서 linear classifier가 task를 쉽게 수행할 수 있도록 하는 것이다.
그럼 DNN이 task를 잘 수행하기 위해서는 좋은 data representation 방식을 사용하는 것이 좋을텐데 task가 바뀔 때마다 그 표현 방식들을 다 바꿔서 model을 만드는 것은 비효율적인 일이다.
그래서 CNN, DNN에서 최종 task의 유형에 따라 새로운 데이터 표현 방식을 뽑도록 학습하게 만드는 연구 동향이 있고 이를 representation learning이라 한다.
Knowledge Distillation
https://light-tree.tistory.com/196
https://audrb1999.tistory.com/29
위 링크의 내용을 참고했다.
Knowledge Distillation의 목적은 Teacher network(이미 잘 학습된 큰 네트워크)가 Student network(task를 수행하고자 하는 작은 네트워크)에게 학습한 지식을 전달하는 것이다.
model의 size가 커지면 커질수록 더 높은 성능이 나올 것이라는 점은 명백하지만 그에 따라 필요한 Computing resource가 커진다는 점이 문제되고 있다. 이러한 문제를 해결하기 위해서 제시된 것이 knowledge distillation이다. 작은 사이즈의 network로도 고성능을 낼 수 있도록 학습 과정에서 기존의 대형 모델의 지식을 작은 모델에 전달하는 것이 핵심이다. 그에 대한 방법론은 위의 링크에서 보는 것으로 하고 본문에서는 생략한다.
선행 연구
(작성 중)
iCaRL 방법론
구성요소
1. Nearest-Mean of Exemplars classification
일반적으로 CNN을 사용하는 AI model에서는 softmax로 출력된 output에서 최댓값을 class로 추정하는 방식의 classification 전략을 사용한다. 그러나 이 방식은 가중치 업데이트 부분과 feature extraction 부분이 분리되어 있어 새롭게 feature extraction을 할 때마다 모든 가중치를 업데이트 해야 한다. 이 문제를 해결하기 위해서 사용하는 방식이 Nearest-Mean of Exemplars classification인데, 직역하면 각각의 Exemplars class의 평균에 대해 가장 가까운 class로 classification을 하겠다는 의미이다.
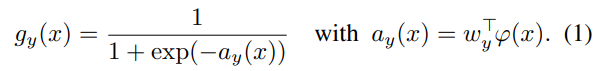 여기서 iCaRL은 softmax 대신 sigmoid output을 사용해서 최종 output을 출력한다.
여기서 iCaRL은 softmax 대신 sigmoid output을 사용해서 최종 output을 출력한다.
 이는 iCaRL의 분류 알고리즘의 수도코드이다.
이는 iCaRL의 분류 알고리즘의 수도코드이다.
image input = x라 할때,
기존의 class exemplar sets가 P_1~P_t까지 있고,
x가 feature extractor를 통과한 것을 ψ라 하면,
ψ와 가장 가까운 값의 평균을 갖고 있는 P_n의 class가 output인 class label y*가 된다.
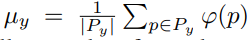 exemplar의 y번째 class의 feature의 평균은 위와 같이 계산한다.
exemplar의 y번째 class의 feature의 평균은 위와 같이 계산한다.
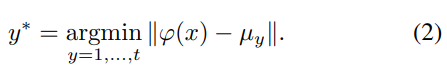 그리고 최종 output인 class label은 위와 같이 계산하여 결정한다.
그리고 최종 output인 class label은 위와 같이 계산하여 결정한다.
이런 알고리즘의 필요 조건으로 기존에 이미 학습되어 있는 exemplar set이 필요하며 새로운 dataset을 학습하는 것에 대한 대응 방식이 필요하다.
2. Herding(군집화)에 기반한 prioritized exemplar selection
 이 알고리즘 수도코드는 iCaRL에서 사용하는 incremental learning 방식을 나타내며, 이는 CNN을 기반으로 feature extraction을 수행한다. iCaRL 논문에서는 연속적인 시간에 따라 점진적으로 증가하는 data를 학습할 수 있는 전략을 강조했다. 이에 위 수도코드를 보면, 특정 시점까지 총 n개의 class수와 동일한 sigmoid output nodes를 포함한 classifier의 형태로 구조를 짠 것을 볼 수 있다. 여기서 CNN은 representation learning을 담당하는 부분으로 sigmoid를 사용한다고 해서 분류 기능에 문제가 생기지 않으며 총 학습하는 class의 개수를 몰라도 무방하다.
이 알고리즘 수도코드는 iCaRL에서 사용하는 incremental learning 방식을 나타내며, 이는 CNN을 기반으로 feature extraction을 수행한다. iCaRL 논문에서는 연속적인 시간에 따라 점진적으로 증가하는 data를 학습할 수 있는 전략을 강조했다. 이에 위 수도코드를 보면, 특정 시점까지 총 n개의 class수와 동일한 sigmoid output nodes를 포함한 classifier의 형태로 구조를 짠 것을 볼 수 있다. 여기서 CNN은 representation learning을 담당하는 부분으로 sigmoid를 사용한다고 해서 분류 기능에 문제가 생기지 않으며 총 학습하는 class의 개수를 몰라도 무방하다.
위 알고리즘의 학습 과정은 다음과 같다.
UPDATEREPRESENTATION을 통해 새로운 dataset과 기존의 K개의 data를 이용해 모델에 학습을 진행하고,
m <- K/t를 이용해 각 class당 저장할 exemplar의 갯수를 정하고,
REDUCEEXEMPLARSET을 통해 exemplar set의 class 당 이미지 수를 m개로 줄인다.
마지막으로, CONSTRUCTEXEMPLARSET을 통해 새로운 exemplar set인 P를 만든다.

위 알고리즘 4, 5는 알고리즘 2에서 추상화된 함수를 구체적으로 표현한 것으로 각각 CONSTRUCTEXEMPLARSET과 REDUCEEXEMPLARSET이다.
CONSTRUCTEXEMPLARSET은 중요한 data로 구성된 exemplar set을 메모리에 저장하는 과정이다. 이 함수를 이용해 exemplar에 들어오는 데이터가 해당 class를 가장 잘 대표하는 데이터들이면서 잘 대표하는 순서대로 exemplar를 구성한다. 이후 모든 exemplar에 속한 데이터의 수가 동일하게 유지하기 위해서 처음부터 m번까지의 데이터만 남기는 과정은 REDUCEEXEMPLARSET으로 수행한다.
3. representation learning using knowledge distillation and prototype rehearsal
 (그림 출처: https://ffighting.net/deep-learning-paper-review/incremental-learning/icarl/)
(그림 출처: https://ffighting.net/deep-learning-paper-review/incremental-learning/icarl/)
위 알고리즘은 2번 요소에서 쓰인 알고리즘에서 CNN이 추상화한 representation의 학습 과정을 더 구체적으로 나타내고 있다.
form combined training set 부분은 기존에 학습한 dataset과 새로운 dataset을 합치는 부분이다.
이후 network의 학습 결과(pre-update parameters)를 저장하는데 이때 새로운 class에 대한 output은 classification loss로 학습하고, 기존 데이터에 대한 output은 distillation loss로 학습한다.

(그림 출처: https://gbjeong96.tistory.com/44?category=976894)
실험 과정
위 챕터에서 iCaRL을 구성하는 3가지 요소를 살펴보았다. 위와 같이 구성한 학습 전략을 사용한 model을 이용해 성능을 테스트한 결과는 아래와 같다.
CIFAR-100, ImageNet
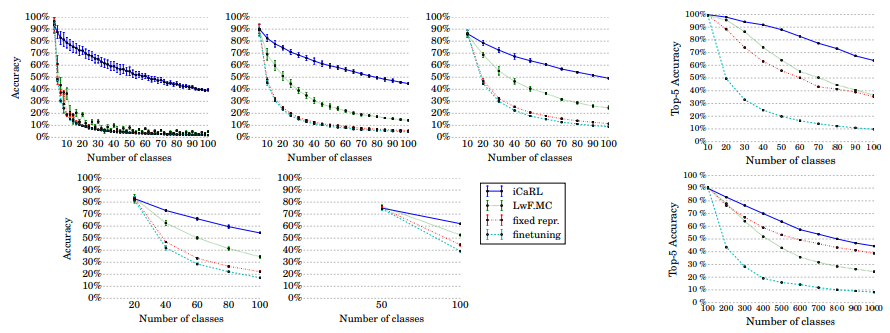 class-incremental learning 상황에서 기존의 방법과 비교해서 더 우수한 성능을 보이고 있다.
class-incremental learning 상황에서 기존의 방법과 비교해서 더 우수한 성능을 보이고 있다.
(여기서 비교된 방식들은 iCaRL, fine tuning, fixed representation, LwF이다.)
figure2 a)는 CIFAR-100 dataset을 각각 2classes 50회 / 5classes 20회 / 10classes 10회 / 20classes 5회 / 50classes * 2회로 나눠 incremental learning 방식으로 model들을 학습시킨 뒤, 모든 class의 classification accuracy의 평균을 측정한 것이다.
figure2 b)는 ImageNet dataset을 100classes, all classes로 나눠 incremental learning 방식으로 model들을 학습시킨 뒤 accuracy를 측정한 것이다.
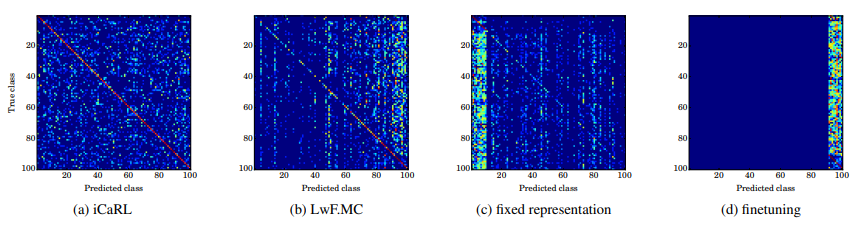 위 그림을 통해서 figure 2에서 비교한 4가지 방식들의 class별 성능을 비교할 수 있다.
위 그림을 통해서 figure 2에서 비교한 4가지 방식들의 class별 성능을 비교할 수 있다.
figure3 d) fine tuning 방식은 이전에 학습한 지식을 전부 잊고 마지막으로 학습한 것들에 대해서만 우수한 성능을 보이는 catastrphic forgetting 문제가 두드러진다.
figure3 c) fixed representation은 새로 학습하는 dataset에 대해서는 좋은 성능을 보이지 못 하고,
figure3 b) 또한 catastrophic forgetting 문제에 취약한 것을 볼 수 있다.
figure3 a) iCaRL은 전반적으로 고른 성능을 보이고 있다.
 iCaRL은 incrementally scaled up data에 대비하면서도 memory 사용의 효율성을 갖추고자 했다. figure 4는 iCaRL이 메모리 사용량이 커질 수록 NCM(이상적인 Nearest-Class-mean classifier)에 근접하는 성능을 보일 수 있음을 보이고 있다.
iCaRL은 incrementally scaled up data에 대비하면서도 memory 사용의 효율성을 갖추고자 했다. figure 4는 iCaRL이 메모리 사용량이 커질 수록 NCM(이상적인 Nearest-Class-mean classifier)에 근접하는 성능을 보일 수 있음을 보이고 있다.
총 정리
iCaRL의 장점
- 점진적으로 증가하는 학습 데이터에 대해 학습한 시점에 따라 고른 분포의 classification 성능을 보인다.
- 상대적으로 적은 memory 사용량으로 이상적인 수준에 근접한 성능을 보인다.
iCaRL의 한계
