요즘 하도 자연어 처리 분야가 인기인데다가 Multi-modal에 대한 연구도 활발히 진행되고 있어서 자연어 처리를 공부해야겠다는 생각이 들어 CS224N 스터디를 시작했다. 어차피 내가 나중에 다시 볼 목적으로 쓰기 때문에 최대한 한국어로 강의를 정리하려고 한다.

어떻게 인간의 언어를 컴퓨터가 인식할 수 있는 형태로 바꿀까?
인간의 언어란?
강의 도입부에서 교수자는 인간의 언어가 상당히 복잡하고 단순희 의미론적으로만 표현하기 어렵다고 했다. 이는 인간의 언어에서 단어 하나가 오로지 그 단어의 뜻만 가지는 것이 아닌 화자의 의도와 앞뒤 단어 사이의 관계에 따른 맥락을 모두 갖고 있기 때문이다. 이러한 인간 언어의 특성을 컴퓨터가 인식할 수 있도록 하는 방법으로 Word2Vector 기술이 거론된다.
WordVector - Represneting words by their context
단어 하나하나를 데이터로써 처리할 때 반드시 고려해야할 점은 단어와 단어 사이의 관계성을 반영해야한다는 것이다. 이에 Thesaurus(시소러스, 유의어 사전)가 이용된다. 뜻이 같거나 비슷한 것들끼리 묶어 놓은 것으로 단어 사이의 상위-하위 개념과 전체-부분 등 뜻의 유사성 외의 다른 단어 사이의 관계성도 정리해놓은 경우가 많다.
WordNet
이는 자연어 처리 분야에서 가장 널리 쓰이는 시소러스로 유의어와 상위-하위 관계 등을 정리해놓은 것이다. 그러나 이는
1. 단어가 갖는 뉘앙스의 차이를 반영하지 못 한다.
2. 신조어를 반영하기 어렵다.
3. 단어가 주관적으로 정리되어 있다.
4. 단어 사이의 유사도가 계산되지 않는다.
라는 단점이 있다.
WordNet의 단점을 극복하기 위해서 단어를 vector로 변환하는 것이 제기되었다.
One-hot Vector
One-hot Vector는 벡터의 원소 중 하나만 1이고 나머지는 모두 0인 vector로 어떤 특정 단어 하나를 위해 n번째의 원소만 1인 벡터를 만드는 방식이다. 이를 사용하게 되면 다음과 같은 문제점이 있다.
1. 벡터의 차원 = 표현하고자 하는 모든 단어의 개수
2. 각 단어 사이의 유사도 파악 불가
3. 그외 단어 사이의 관계성을 표현하기 위해서 제곱수로 벡터의 차원이 많아져야 한다.
Distributional Semantics
단어의 맥락적 의미를 반영하기 위한 방법으로 고정된 크기의 window를 이용해 문장 내에서 단어의 앞뒤 (=context)를 살피며 비슷한 문맥에서 나타나는 비슷한 단어들끼리 유사한 벡터를 가지도록 하는 것이다. 이를 Word Embeddings, Word Representations라고도 한다. 이를 이용해 만든 WordVector를 2차원 공간에 정사영하면 완전하지는 않아도 유사한 단어들이나 비슷한 맥락에서 자주 나오는 단어들끼리 가까이 위치한다는 것을 알 수 있다.
Word2Vec
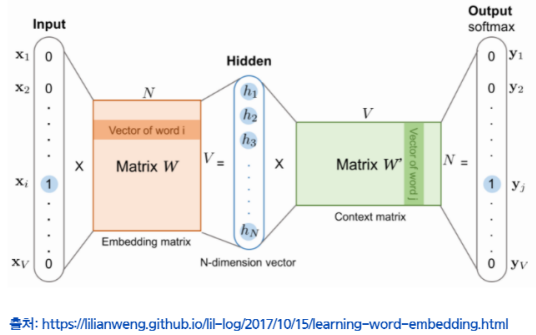 WordVector를 학습하는 프레임워크로, 이는 문장 내에서 중심 단어(center word)가 주어졌을 때 그 주변 맥락에 무슨 단어가 올지 추론하는 것을 반복하면서 단어의 출현 패턴을 학습한다.
WordVector를 학습하는 프레임워크로, 이는 문장 내에서 중심 단어(center word)가 주어졌을 때 그 주변 맥락에 무슨 단어가 올지 추론하는 것을 반복하면서 단어의 출현 패턴을 학습한다.
Distributional Semantics에서는 center word의 앞뒤 단어들을 통해 그 단어를 Vectorization 했다면, Word2Vec에서는 단어의 벡터를 학습하기 위해서 그 반대 과정을 반복해서 수행하는 것이라 생각하면 된다.
이 기법은
1) 우리가 충분히 많은 말뭉치(corpus)를 가지고 있을 때,
2) 모든 어휘의 단어들을 벡터로 표현하기 위해서,
3) 위치 t의 center word(=c)와 주변에 있는 context words(=o들)의 word vector 유사도를 통해,
4) c가 주어졌을 때 o가 나타날 확률을 계산하고,
5) 이 확률을 최대화하기 위해 c의 word vector를 계속 조정해나가는 작업을 한다.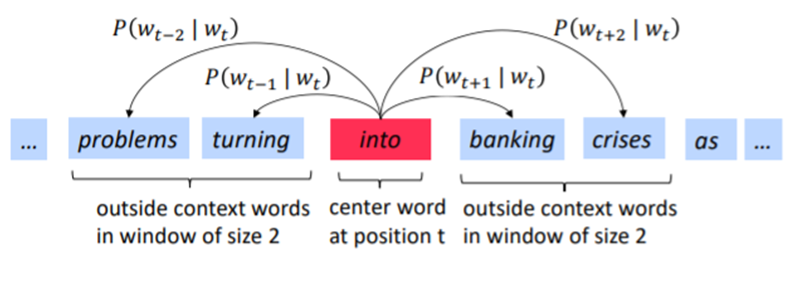
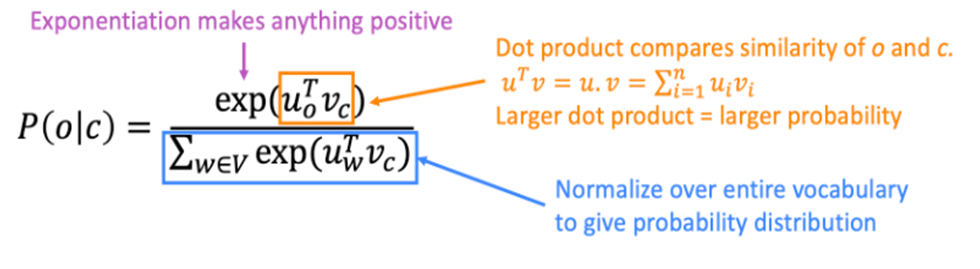
여기서 word vector의 유사도를 계산하는 방법(Likelihood)은 아래와 같다. (θ = word vector parameter)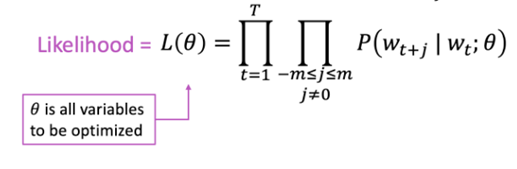
그리고 정답에서 먼 정도 즉, loss function(=objective function)을 계산하기 위해서는 아래와 같은 방법을 사용한다.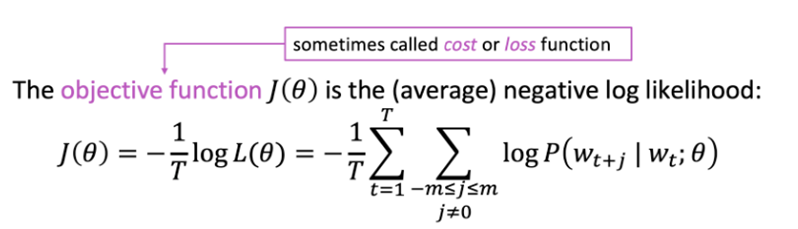 위에서는 '나타날 확률을 최대화한다'고 표현했지만 실제 연산 과정에서는 이 정답에서 멀어진 정도에 해당하는 loss function을 최소화하는 연산을 이용해 정답에 가까워지고자 한다.
위에서는 '나타날 확률을 최대화한다'고 표현했지만 실제 연산 과정에서는 이 정답에서 멀어진 정도에 해당하는 loss function을 최소화하는 연산을 이용해 정답에 가까워지고자 한다.
앞뒤 단어의 출현 확률 계산 방식은 아래와 같다. (v = center word vector, u = context word vector) 연산에서 내적과 softmax를 사용한다. 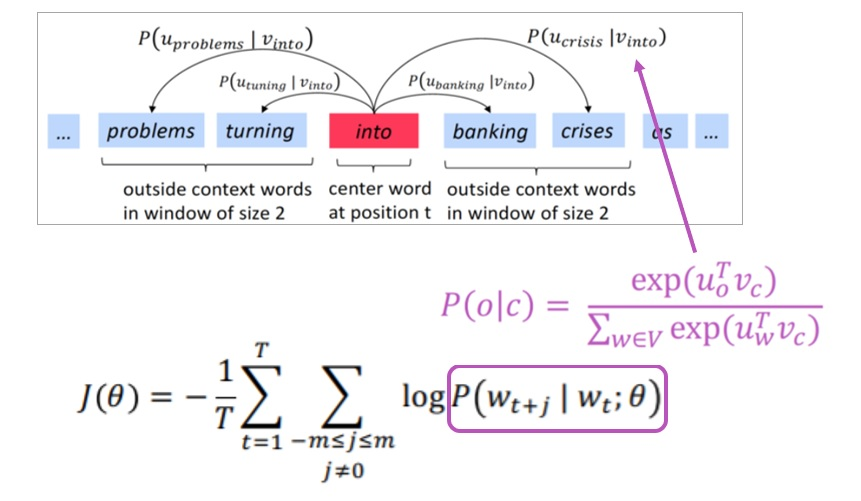
마지막으로 Optimization을 통해 목적 함수를 최소화함으로써 주어진 말뭉치 속의 단어들의 맥락적 의미를 가장 잘 표현하는 벡터를 찾는다.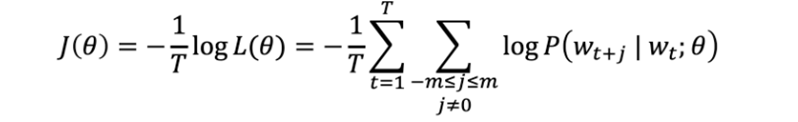
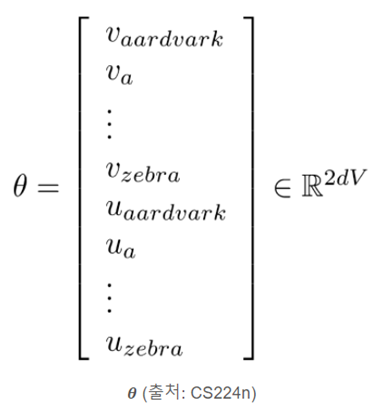
이러한 Word2Vec의 종류로는 Skip Gram(center word -> context word 추론)과 CBOW(context word -> center word 추론)이 있다. 위에서 설명한 것은 Skip Gram의 내용이다.
위와 같은 Word2Vec 모델을 학습시키기 위해서(=Optimization 시키기 위해서) loss 값을 최소화 해야하는데 이 때 Gradient Descent를 사용한다. (AI를 처음 배울 때 항상 언급되는 것이니 설명은 생략)
