[6-1] NLTK 패키지를 활용한 규칙 기반 구구조 구문 분석
# NLTK 패키지 다운로드
!pip install nltk==3.3
# 구구조 구문 분석 규칙 작성
import nltk
grammar = nltk.CFG.fromstring("""
S -> NP VP
NP -> NN XSN JK | NN JK
VP -> NP VP | VV EP EF
NN -> '아이' | '케이크'
XSN -> '들'
JK -> '이' | '를'
VV -> '먹'
EP -> '었'
EF -> '다'
""")
#규칙 기반 구문 분석기 생성 및 구구조 구문 분석 수행: 제시된 ChartParser 외에도 ShiftReduceParser, RecursiveDescentParser 등 다양한 구문 분석 알고리즘이 제공된다.
parser = nltk.ChartParser(grammar)
sent = ['아이', '들', '이', '케이크', '를', '먹', '었', '다']
for tree in parser.parse(sent):
print(tree)
(S
(NP (NN 아이) (XSN 들) (JK 이))
(VP (NP (NN 케이크) (JK 를)) (VP (VV 먹) (EP 었) (EF 다)))) [6-2] Spacy를 이용한 의존 구문 분석
영어 문장의 의존 구문 분석 수행
Spacy 모델은 문장을 token들로 구성된 document로 처리한다.
각 token에는 품사, 의존 관계, 개체명 정보 등이 태깅된다.
이 예제에서 출력하는 정보들은 다음과 같다.
- token.text: token 문자열
- token.dep_: token과 token의 지배소 간의 의존 관계 유형
- token.head: 지배소 token
# Spacy 패키지 다운로드
!pip install spacy==2.1.9
import spacy
# 영어 multi-task 통계 모델
nlp = spacy.load('en_core_web_sm')
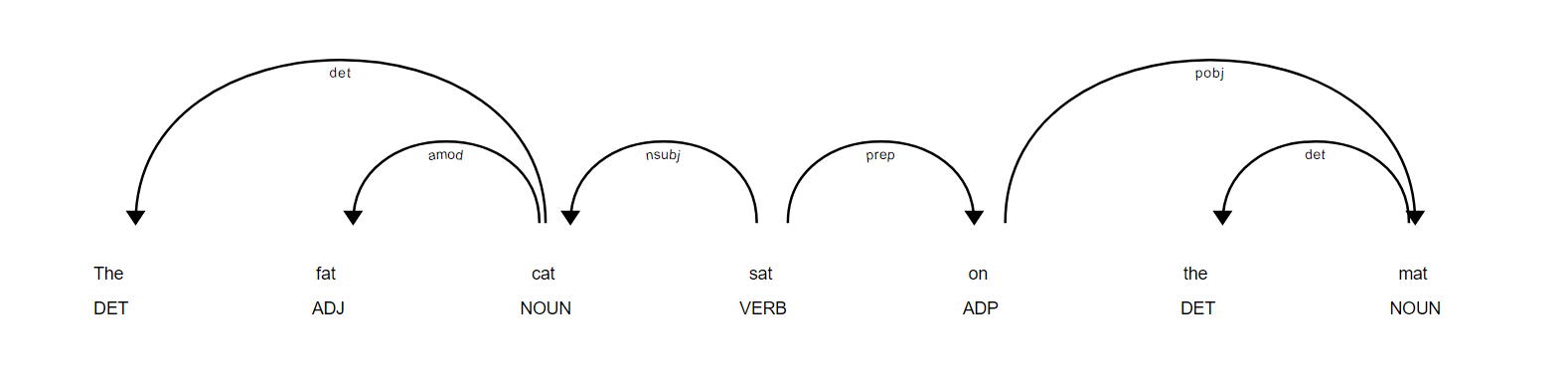
doc = nlp('The fat cat sat on the mat')
for token in doc:
print(token.text, token.dep_, token.head.text)
The det cat
fat amod cat
cat nsubj sat
sat ROOT sat
on prep sat
the det mat
mat pobj on
# 의존 구문 분석 결과를 시각화한다.
from spacy import displacy
# Jupyter, Colab 등에서 동작
displacy.render(doc, style='dep', jupyter=True)