캐시 시스템에 필요한 fault tolerance 의미와 이를 제공하는 방안
여러 응용 서비스들에서 서비스 응답 속도를 빠르게 하고 조회 처리량을 늘리기 위하여, 확장 가능한 인메모리 캐시 시스템을 적용하는 것이 일반화되었다. 응용 서비스의 원본 데이터는 DB 같은 영구 저장소에 저장하고, 그 중에 자주 조회되는 데이터는 인메모리 기반의 캐시 시스템에 보관하여 반복된 조회 요청을 빠르게 처리함으로써 응용 서비스의 성능을 확대한다. 이러한 캐시 시스템은 어떤 고장이 발생하더라도 중단 없는 캐시 서비스를 제공하는 fault tolerance 특성을 가져야 한다. 캐시 시스템에 필요한 fault tolerance 의미를 설명하고, ARCUS 캐시 시스템에서 fault tolerance를 어떻게 제공하는 지를 소개한다.
캐시 시스템의 fault tolerance 의미
캐시 시스템은 DB 같은 원본 데이터 저장소에서의 조회 결과를 저장하고 반복된 조회 요청을 빠르게 처리하는 고성능의 인메모리 저장소이다. 캐시 시스템의 일부가 고장나서 정상적인 캐시 서비스를 제공하지 못한다면, 해당 응용은 원본 데이터 저장소인 DB로 다시 요청하게 되므로 캐시 사용에 따른 성능 개선 효과가 사라질 수 있다. 따라서, 캐시 시스템은 중단 없는 캐시 서비스를 제공할 수 있는 fault tolerance를 가져야 하며, 이를 위해 아래 2 가지 사항을 반드시 만족해야 한다.
첫째, 다수 캐시 노드들로 구성된 클러스터 시스템이어야 한다.
- 일부 캐시 노드에 고장이 발생하더라도 다른 정상 캐시 노드들은 캐시 서비스를 제공할 수 있다.
둘째, 고장난 캐시 노드는 클러스터에서 즉시 제거하여야 한다.
-
정상 캐시 노드들만으로 클러스터가 구성되도록 그 구성을 즉시 변경하여야 한다.
-
클러스터의 캐시 노드 목록에서 고장난 캐시 노드를 제거하여 그 캐시 노드로 응용 요청이 들어가지 않도록 한다.
-
응용에 장착된 캐시 클라이언트들도 수정된 캐시 노드 목록을 인지하고, 정상 캐시 노드에만 요청을 보내야 한다.
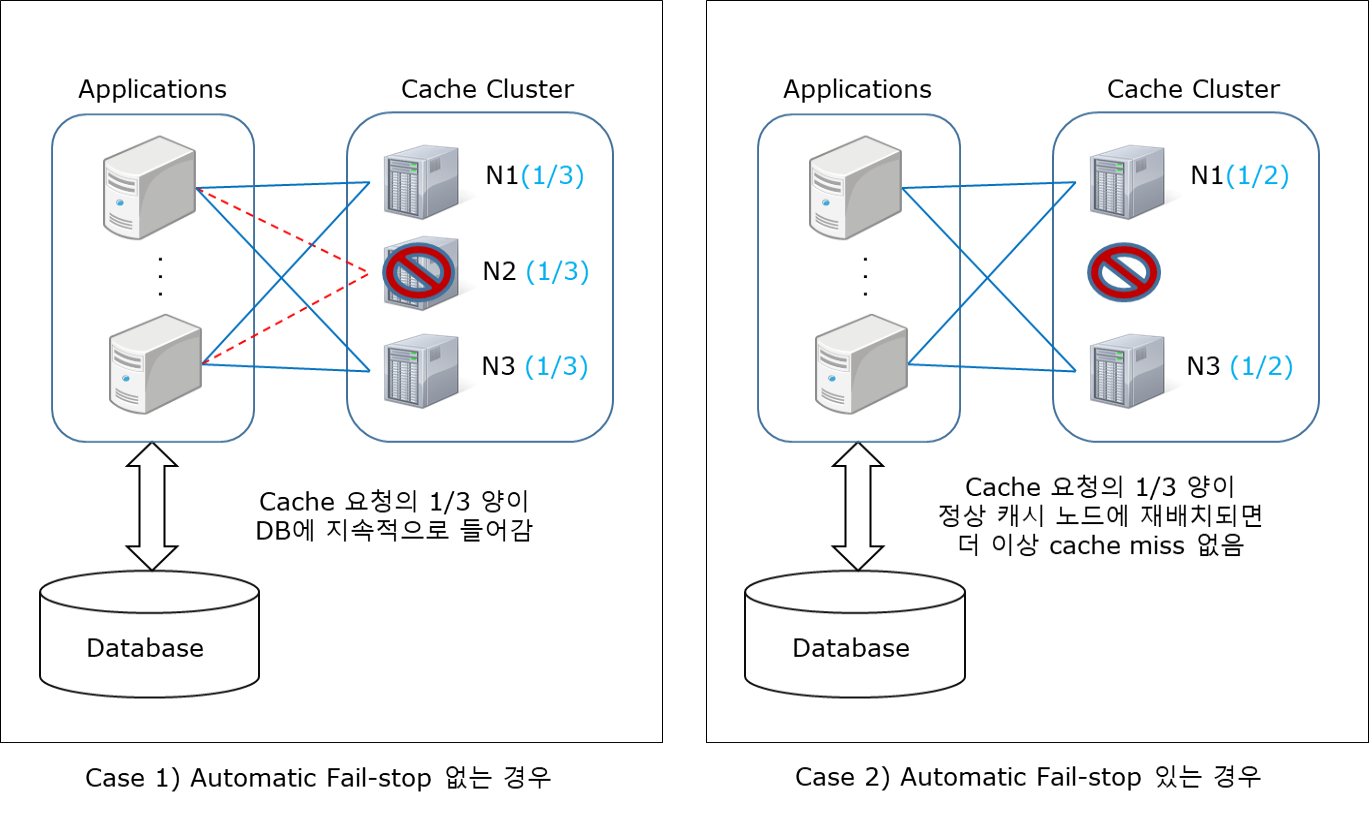
위의 첫째 사항은 쉽게 이해할 수 있어서 추가 설명을 생략하고, 둘째 사항은 예를 들어 설명한다. 아래 그림은 3개 캐시 노드로 구성된 클러스터에서 각 캐시 노드는 전체 캐시 데이터의 1/3씩 나누어 캐싱하고 있는 상태이다. 이 클러스터에서 N2 캐시 노드가 고장날 경우, N2 캐시 노드를 (1) 클러스터에 그대로 두는 경우와 (2) 클러스터에서 즉각 제거하는 경우를 구분하여 설명한다. 클러스터에서 고장난 캐시 노드를 자동으로 제거하는 기능을 본 기사에서 automatic failstop이라 부른다. 참고로, fail-remove 용어가 더 적합할 수 있으나, fail-stop 용어가 친숙하고 틀리지 않는 용어라서 사용한다.
Case 1) automatic failstop 기능이 없는 경우이다.
- 고장난 N2 캐시 노드는 여전히 캐시 클러스터에 소속되어 있다.
- 고장난 N2 캐시 노드로 보낸 요청은 모두 실패하여 DB로 재요청하게 되므로, 전체 캐시 요청의 1/3이 DB에 지속적으로 들어간다.
- DB 요청은 일반적으로 느린 응답과 낮은 처리량을 보이므로, 응용 서비스 성능이 떨어질 수 있다.
Case 2) automatic failstop 기능이 있는 경우이다.
- 고장난 N2 캐시 노드를 캐시 클러스터에서 제거하고 N1과 N3 캐시 노드로 전체 캐시 데이터의 1/2씩 담당하도록 변경된다.
- 처음 1/3 분량의 캐시 요청이 cache miss로 인해 DB에 들어가지만, N1과 N3 캐시 노드에 재캐싱된 이후에는 캐시 서비스가 정상화된다.
캐시 노드 고장은 야간, 주말 등의 임의 시점에 발생할 수 있어, 운영 관점에서 위의 2 경우는 큰 차이를 보인다. 캐시 노드 고장으로 DB에 지속적으로 높은 부하가 발생하여 응용 서비스 성능이 떨어진다면, 운영자가 빠르게 조치해야 한다는 것이 가장 힘든 부담이다. 이를 운영 관점에서 비교하면 다음과 같다.
Case 1) 운영자 또는 자동화 스크립트로 즉각 조치해야 한다.
- 고장난 캐시 노드를 다시 구동하거나, 캐시 클러스터에서 빨리 제거해야 한다.
- 모두가 잠든 야간이나 가족과 함께 있는 주말에 운영자가 직접 조치하는 것은 무리가 있으며, 야간/주말 운영자가 따로 필요할 수 있다.
- 메모리 고장 같은 하드웨어 고장인 경우, 자동화 스크립트로 캐시 노드를 재구동하는 것이 불가할 수 있다.
- 따라서, 캐시 노드 고장에도 응용 서비스 품질이 떨어지지 않도록, 충분한 DB 처리량을 미리 확보해 두는 것이 필요하다.
Case 2) 운영자의 즉각적인 조치가 필요 없다.
- 캐시 시스템이 자동으로 고장난 캐시 노드를 제거하므로, 운영자가 즉각 개입할 필요가 없다.
- 운영자는 업무 시간에 출근하여 캐시 노드의 고장 원인을 파악하고 해결한 후에, 캐시 노드를 다시 투입하면 된다.
캐시 시스템에서 고장난 캐시 노드를 제거할 수 있는 이유는 원본 데이터의 영구 저장소가 아니기 때문이다. 즉, 캐시 데이터는 원본 데이터 저장소에 다시 질의하여 얻을 수 있고, 이를 캐시 시스템에 다시 캐싱할 수 있기 때문이다. 참고로, 원본 데이터 저장소가 고장난다면, 데이터 손실이 없어야 하므로 즉각 데이터 회복(recovery)으로 복구하거나 데이터 복제를 통해 존재하는 다른 저장소로 failover한 이후에 복구하여야 한다.
Fault Tolerant ARCUS 캐시 클러스터
ARCUS 캐시 클러스터는 고가용의 ZooKeeper 시스템을 이용하여 캐시 노드 목록을 안전하게 관리하며, 아래 ZooKeeper 기능을 활용하여 캐시 시스템의 automatic failstop 기능을 구현한다.
첫째, ZooKeeper Watcher 기능으로, 최신의 캐시 노드 목록을 실시간으로 모든 캐시 클라이언트에게 공유한다.
- 캐시 노드 목록에 Watcher를 생성한 모든 캐시 클라이언트는 그 캐시 노드 목록에 변동이 생기는 즉시 실시간 이벤트 알림을 받고, 최신 캐시 노드 목록을 다시 조회한다.
- 이 방식으로 모든 캐시 클라이언트는 항상 최신의 캐시 노드 목록을 가진다.
둘째, ZooKeeper Ephemeral Node 기능으로, ARCUS 캐시의 기본적인 automatic failstop 기능을 구현한다.
- ZooKeeper node는 ZooKeeper에 저장하는 하나의 데이터 단위이다. ZooKeeper node 유형으로, persistence node는 영구히 저장되는 데이터이고, ephemeral node는 그 node를 생성한 ZooKeeper 연결(or 세션)이 살아있는 동안만 존재하는 일시적 데이터이다.
- 모든 캐시 노드는 ZooKeeper에 연결하여 자신의 캐시 노드 정보를 ephemeral node 유형으로 등록하고 ZooKeeper와의 연결을 유지한다. 캐시 노드를 정상 종료하면, 자신이 생성한 ephemeral node를 제거한 후에 ZooKeeper와의 연결을 끊는다.
- 캐시 노드가 비정상 다운되어 ZooKeeper와의 연결이 끊어지면, ephemeral znode 데이터는 자동 제거된다. 이를 통해 기본적인 automatic failstop 기능을 구현한다.
- 이러한 캐시 노드 목록의 변화는 앞서 기술한 ZooKeeper Watcher 기능으로 모든 캐시 클라이언트에게 공유된다.
셋째, ZooKeeper Ping 기능으로, timeout 기반의 캐시 노드 건강 상태를 검사하여 automatic failstop 기능을 구현한다.
- ZooKeeper에 연결 중인 모든 캐시 노드에 대해 주기적으로 ZooKeeper ping 데이터를 교환한다.
- ZooKeeper ping 데이터가 교환되지 않으면 해당 캐시 노드와의 ZooKeeper 연결이 만료되고, 그 연결로 생성한 ephemeral znode 또한 사라진다.
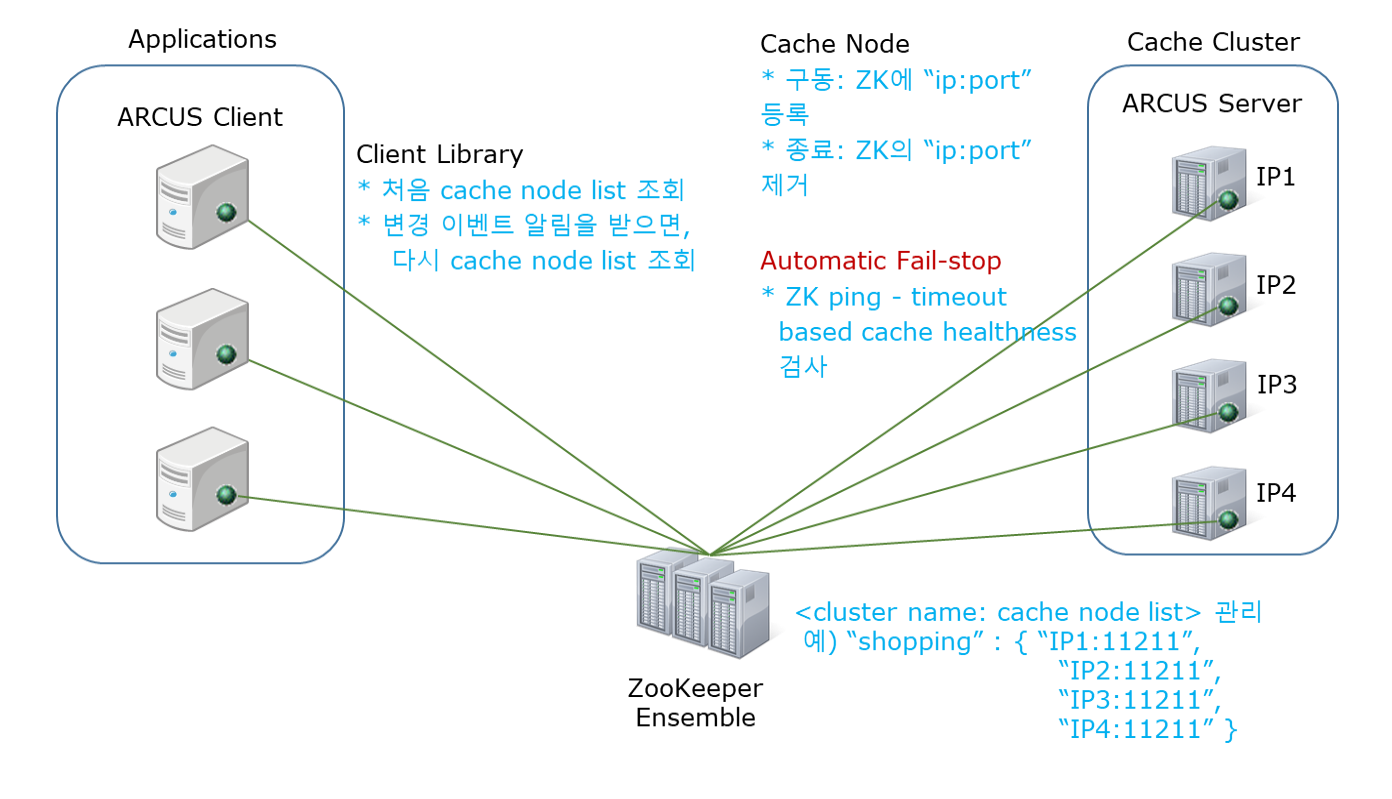
위의 ZooKeeper 기능으로 기본적인 automatic failstop 기능을 구현하고, ARCUS 캐시 클러스터의 수평 확장성(horizontal scalability)도 구현한다는 사실을 알 수 있다. ZooKeeper 활용하여 구현한 Scalable and Fault Tolerant ARCUS 캐시 클러스터의 구조를 아래 그림으로 설명하고자 한다.
- 그림 하단의 ZooKeeper Ensemble은 각 캐시 클러스터에 대한 캐시 노드들의 “IP:Port” 목록을 관리한다.
- 캐시 노드가 구동되면 이 목록에 자신의 “IP:Port” 정보를 추가하고, 캐시 노드가 종료되면 이 목록에서 자신의 “IP:Port” 정보를 제거한다.
- 이러한 캐시 노드 목록은 응용 구동 시에 ARCUS 캐시 클라이언트가 조회하여 가지고 있으며, 캐시 노드 추가와 제거로 그 목록이 변경되면 그 즉시 변경 이벤트 알람을 받고 최신 캐시 노드 목록을 다시 조회하여 가진다. 응용은 최신 캐시 노드 목록을 기반으로 consistent hashing하여 캐시 데이터를 저장/조회할 캐시 노드를 찾아 해당 요청을 분배한다.
- ZooKeeper ephemeral node와 ZooKeeper ping 기능으로 캐시 노드의 프로세스 다운, 하드웨어 고장, 네트웍 장애 등의 고장을 감지하면, 자동으로 고장난 캐시 노드의 “IP:Port” 정보를 제거하여 failstop 시킨다.
캐시 노드의 hang 고장 탐지: mc heartbeat 기능
앞서 기술한 ZooKeeper ephemeral node와 ZooKeeper ping 기능으로 탐지하지 못하는 고장으로 ARCUS 캐시 노드가 정상적으로 서비스할 수 없는 hang 상태가 있다. 이러한 hang 상태를 탐지하기 위하여 ARCUS 캐시 노드는 자신에게 몇가지 캐시 요청을 보내고 그에 대한 응답이 제 시간에 오는 지를 확인하는 mc heartbeat 기능을 가지고 있으며, 이를 주기적으로 수행한다. 참고로, mc heartbeat 이란 용어는 ARCUS 캐시 노드가 memcached 기반으로 확장된 것이고, 이에 대한 heartbeart를 지칭한다.
ARCUS 캐시 노드는 mc heartbeat이 실패하는 경우에도 스스로 ephemeral node를 제거하고 종료하여 automatic failstop 한다.
Stale 데이터 제거: 자동 scrub stale 기능
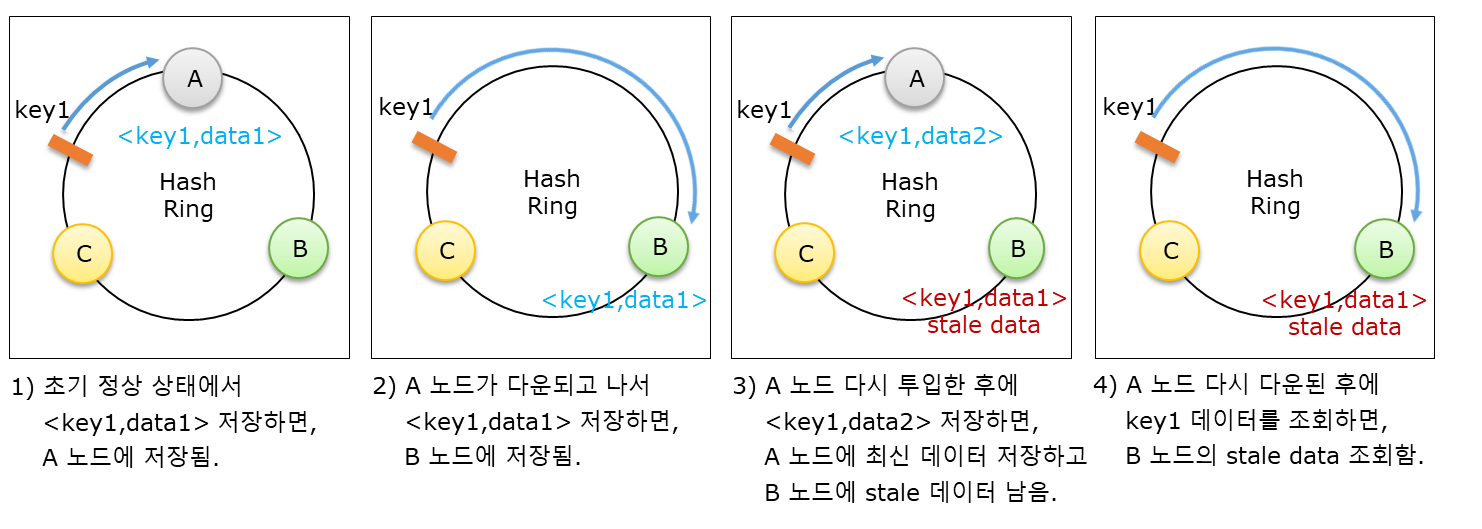
ARCUS 캐시 클러스터는 수평 확장이 가능하면서 automatic failstop 기능으로 고장난 캐시 노드를 자동 제거한다. 응용에 장착된 ARCUS 캐시 클라이언트는 최신의 캐시 노드 목록을 기반으로 consistent hashing 로직을 수행하여 캐시 데이터를 여러 캐시 노드들에 분배하므로, 캐시 노드의 추가나 제거가 발생하면 자동으로 캐시 데이터의 재배치가 발생한다. 이러한 재배치에 의하여 stale 캐시 데이터가 발생하고 이러한 stale 데이터가 응용에게 노출되는 문제가 발생할 수 있다. 예를 들어, A, B, C 3개 캐시 노드로 구성된 클러스터에서 각 캐시 노드의 해시 위치가 consistent hashing 로직에 의해 아래 그림처럼 정해져 있고, key1의 해시 위치는 C 노드와 A 노드 사이에 존재한다고 가정한다. 이 상태에서 stale 데이터가 발생하고 응용에 노출되는 시나리오는 아래와 같다.
Time 1) 처음 정상 상태
- 응용이 <key1, data1> 데이터를 캐시에 저장하면, key1은 A 노드로 매핑되어 A 노드에 저장된다.
Time 2) 어떤 이유로 A 노드가 다운된 상태
- 응용이 key1 데이터를 조회하면 cache miss가 발생한다.
- 응용이 DB에서 다시 조회한 <key1, data1> 데이터를 캐시에 저장하면, 이번엔 key1이 B 노드로 매핑되어 B 노드에 저장된다.
Time 3) 고장난 A 노드를 수리하고 클러스터에 재투입한 상태
- 응용이 key1 데이터를 조회하면 cache miss가 발생한다.
- DB에서 key1 데이터는 data2로 변경되었다고 가정하고, 응용이 DB에서 조회한 <key1, data2> 데이터는 A 노드에 저장된다.
- 이 시점에 B 노드에 저장되어 있던 <key1, data1> 데이터는 stale 데이터가 된다.
Time 4) 어떤 이유로 A 노드가 다시 다운된 상태
- 응용이 key1 데이터를 조회하면, B 노드에 있던 stale 데이터인 <key1, data1> 데이터가 조회된다.
- 이러한 stale 데이터가 응용에게 노출되면, 응용은 예상하지 않은 결과를 사용자에게 보여줄 수 있다.
Stale 데이터가 자동으로 소멸되게 하려면, 각 캐시 데이터의 만료 시간(expire time)을 짧게 지정하는 방법이 있다. 하지만, 응용에서 생성하는 캐시 데이터의 용도나 성격에 따라 만료 시간을 짧게 지정할 수 없는 경우도 있으므로, 이러한 stale 데이터는 캐시 시스템에서 제거해 주어야 한다. ARCUS 캐시 시스템은 아래 방식으로 stale 데이터를 자동으로 제거하는 기능을 제공한다.
- Stale 데이터가 발생하는 시점은 새로운 캐시 노드가 추가되는 시점이다. 새로운 캐시 노드가 추가될 때마다 모든 ARCUS 캐시 노드는 stale 데이터를 제거하는 로직을 자동으로 수행한다.
- ARCUS 캐시 노드는 캐시 클라이언트와 마찬가지로 ZooKeeper Watcher 기능으로 최신의 캐시 노드 목록을 가져오면서 캐시 노드가 추가된 시점을 확인한다.
- ARCUS 캐시 노드는 캐시 클라이언트와 마찬가지로 키 분배(캐시 데이터 분배)를 위한 consistent hashing 로직을 동일하게 가지며, 캐시 노드가 추가되면 background thread를 생성하여 자신의 모든 캐시 데이터를 순차 접근하면서 stale 데이터를 찾아 제거한다.
캐시 데이터 복제와 fault tolerance
캐시 노드 고장 시의 fault tolerance를 보장하는 다른 방안으로, 복제(replication)를 통해 캐시 데이터를 이중화하고 master 노드의 고장 시에 slave 노드를 새로운 master 노드로 승격시키는 failover 기능으로 캐시 서비스를 중단 없이 제공할 수 있다. 이러한 복제 기능은 캐시 데이터의 손실(loss) 없이 fault tolerance를 제공하는 장점이 있지만, 이는 앞서 기술한 automatic failstop 기능의 완전한 대체제로 보기는 어렵고 상호 보완하는 기능으로 이해해야 한다. 그 이유는 다음과 같다.
첫째, 캐시 시스템에서는 이중화 목적의 복제만 제공하는 것이 일반적이다.
- 원본 데이터는 DB에 저장되어 있으므로, cache miss 시에 DB에서 다시 조회할 수 있다.
- 따라서, 캐시 데이터를 삼중화 이상으로 복제하는 경우는 거의 없다.
둘째, 이중화 캐시에서 master 노드와 slave 노드가 동시에 고장날 가능성이 희박하지만, 운영 방식에 따라 가능성은 존재한다.
- 두 캐시 노드가 동일한 하나의 switch 장치에 연결되어 있고, 그 switch 장비의 고장이 발생할 수 있다.
- 한 캐시 노드의 하드웨어 장비가 고장난 상태에서 새로운 장비의 수급이 늦어진다면 동시 고장의 발생 확률이 높아진다.
셋째, 복제를 사용하더라도 automatic failstop 기능이 준비되어야 한다.
- 이중화 캐시 노드가 모두 고장나는 최악의 경우를 대비하여, automatic failstop 기능이 필요하다.
캐시 시스템을 이중화하는 것은 비용이 많이 든다. 캐시 노드 고장으로 DB에서 다시 조회하는 성능이 아주 낮다면, 비용을 들여서라도 이중화할 충분한 이유가 된다. 예를 들어, 복잡한 조인(join) 연산이나 집계 연산으로 조회 결과를 얻어 캐싱하는 경우가 이에 해당된다. DB 조회 성능이 크게 떨어지지 않는 캐시 데이터인 경우는 automatic failstop으로 fault tolerance를 보장하는 것이 더 효율적인 방법이다.
마치며
캐시 시스템에서 제공해야 할 fault tolerance 특성을 정리하고, 이러한 특성을 제공하기 위하여 ARCUS 캐시 시스템에 구현한 automatic failstop 기반의 fault tolerance 제공 방식을 설명하였다. 캐시 시스템의 일부가 고장나더라도 응용 서비스의 캐시 사용에 따른 성능 개선 효과를 그대로 유지하면서 캐시 시스템 운영자의 피로도를 제거하기 위하여 automatic failstop 기반의 fault tolerance 제공은 반드시 필요하다고 본다.
ARCUS 캐시 시스템에서 fault tolerance 개선 사항으로, 여러 유형의 고장을 빨리 탐지하는 기능을 추가하여야 한다. ZooKeeper Ping 기능은 timeout 기반의 고장 탐지 기능으로, 고장 탐지에 일정 시간이 소요된다. 네트웍 문제가 아니라 고장 원인이 분명한 경우에는 이를 빠르게 탐지하여 failstop 시키는 것이 응용 서비스에게 유리하다.