일반 사용자를 대상으로 하는 대규모 응용에서는 데이터(특히, hot data) 조회 시에 DB로 많은 요청이 몰려 높은 부하가 발생합니다. 이러한 DB 단의 부하를 줄이기 위해, 자주 조회되는 데이터를 응용의 분산 캐시에 저장하여 신속하게 응답을 제공하도록 구현하는 것이 일반적인 방법입니다.
캐시를 응용에 적용할 때는 Demand-fill 방식을 많이 활용합니다. 데이터 조회 요청이 들어올 때 캐시에 데이터가 있다면 캐시의 데이터를 응답해주고, 없다면 DB 조회한 후 캐시에 데이터를 저장하고 응답해주게 됩니다. 따라서 캐시 데이터가 존재하는 동안은 빠른 응답을 제공해 줄 수 있습니다.
이 방식은 DB의 데이터가 수정될 때 캐시의 데이터와 불일치한다는 문제점이 있습니다. 그래서 DB와 캐시의 데이터 불일치 현상을 줄이기 위해 Expire time or Time-To-Live(TTL)를 설정합니다. (Demand-fill 방식 및 캐시를 응용에 적용하는 자세한 방법은 ARCUS 공통 모듈을 참고해주세요) 이러한 특징으로 인해 아래와 같은 문제가 생길 수 있습니다.
- 캐싱된 경우와 캐싱 만료된 경우에 요청에 대한 응답속도 차이 존재
- 캐시 데이터 만료 직후부터 데이터가 다시 캐싱될 때까지 수많은 조회 요청이 DB로 몰리는 현상
해당 문제는 캐시가 만료되어 DB 조회를 하면서 발생하는 문제이며 특히 2번의 문제를 cache stampede라고 지칭합니다.
Cache stampede

stampede란 많은 동물이 갑자기 빠르게 같은 방향으로 돌진하는 현상을 말합니다. cache stampede는 캐시 만료로 인해 많은 데이터 조회 요청이 DB로 갑자기 몰려 DB 부하 증가 및 그로 인한 조회 속도가 저하되는 현상으로 아래와 같은 문제를 일으킬 수 있습니다.
- 응용의 응답시간 지연
- 만료된 캐시 데이터를 다시 DB에서 조회하여 캐싱하는 작업이 중복하여 발생 즉, 캐시에 중복 쓰기(duplicate write) 발생
Cache stampede 방지대책
Cache stampede 문제를 해결하기 위한 논문이 VLDB라는 국제 학술대회에서 발표되었고, 그 논문에서 소개된 몇 가지 해결법은 아래와 같습니다.
-
External re-computation
- 주기적으로 백그라운드 프로세스에서 캐시 아이템을 재생성하여 cache miss를 방지
- 단점 : 주기적으로 재생성하는 아이템 목록(key 목록)이 필요
-
Locking
- 중복으로 DB 조회 및 캐시 쓰기가 일어나지 않도록 cache miss가 발생한 처음의 요청에 Lock을 부여해 캐시를 갱신
- 단점 : Cache miss 발생에 따른 중복 조회 및 쓰기의 문제만 해결 가능, 캐시 만료 시 응답지연 문제는 지속 -
Probabilistic Early Expiration(PER)
- 확률적 알고리즘을 이용해 캐시 데이터가 만료되기 전 계산된 확률로 미리 캐시를 갱신
이 중 논문에서 자세하게 제시된 해결법은 PER입니다. PER을 그림으로 설명하면 아래와 같습니다.
- 기존의 캐싱 형태

파란 구간은 캐싱이 적용되어있는 구간이고, 하얀 구간이 캐시가 만료(expired)된 구간입니다. 하얀 구간에서 cache miss가 발생하므로 DB로 조회 요청이 몰리는 구간이 됩니다.
- PER을 적용한 경우의 형태

캐시 아이템이 만료되기 전 재캐싱을 하여 만료 없이 캐싱이 계속 유지되는 형태입니다. 위의 그림(기본 캐싱)과 비교하여 보면 만료보다 앞서서 재캐싱이 일어나 만료가 발생하지 않는 것을 볼 수 있습니다.
PER은 요청을 처리하는 스레드가 캐시 데이터를 조회할 때마다 남은 만료 시간 대비 임의(random) 확률로 재캐싱을 수행하는 방안으로, 만료시간이 다가올수록 재캐싱 확률이 증가합니다. (확률을 이용한 알고리즘의 자세한 설명은 뒤에서 계속됩니다.)
그렇다면 실질적으로 해당 알고리즘이 어떠한 효과를 얻을 수 있는지 간단한 테스트를 통해 알아보겠습니다.
Cache stampede 해결방안 테스트
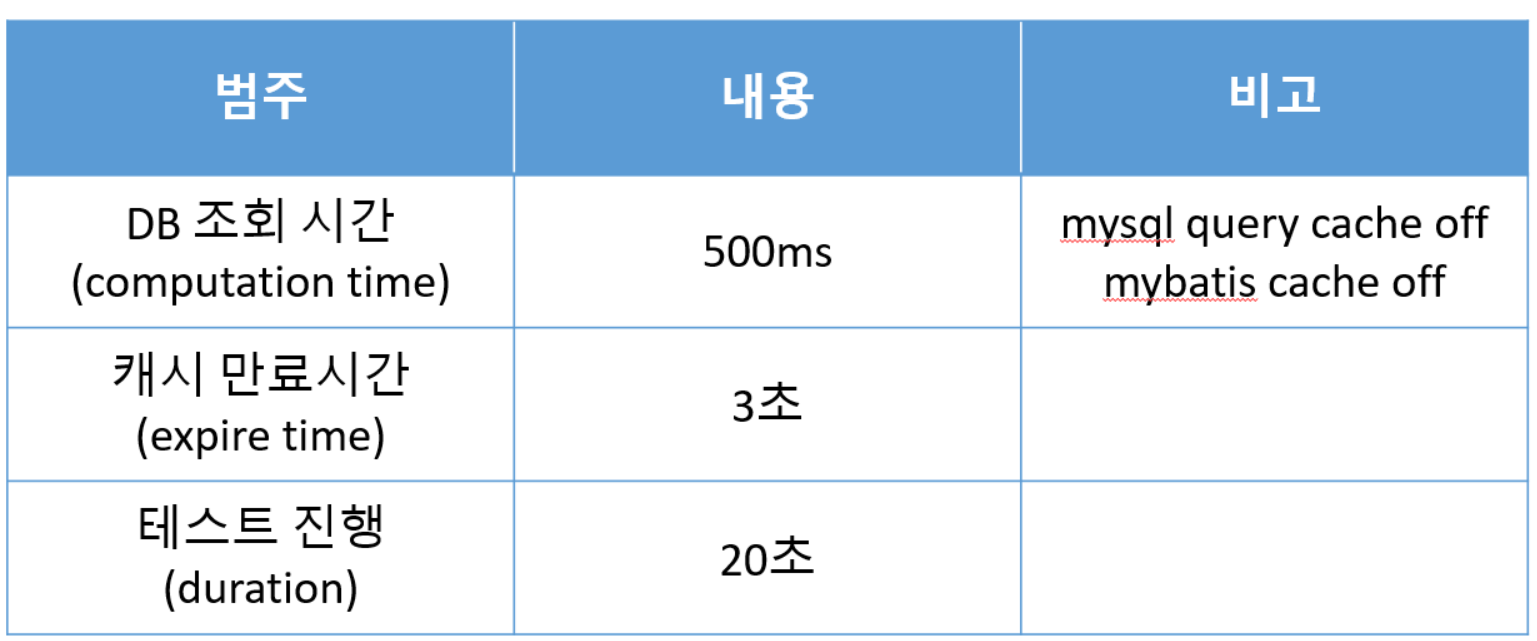
기본 캐싱과 PER 적용 경우에 캐시 만료 시의 효과를 비교해 보도록 하겠습니다. 테스트를 위한 환경은 아래와 같습니다.
-
테스트 조건
-
Jmeter 설정

-
측정 요소
- cache miss 발생 횟수
- cache stampede로 인한 응답 지연 속도
- cache stampede로 인한 중복 쓰기 횟수
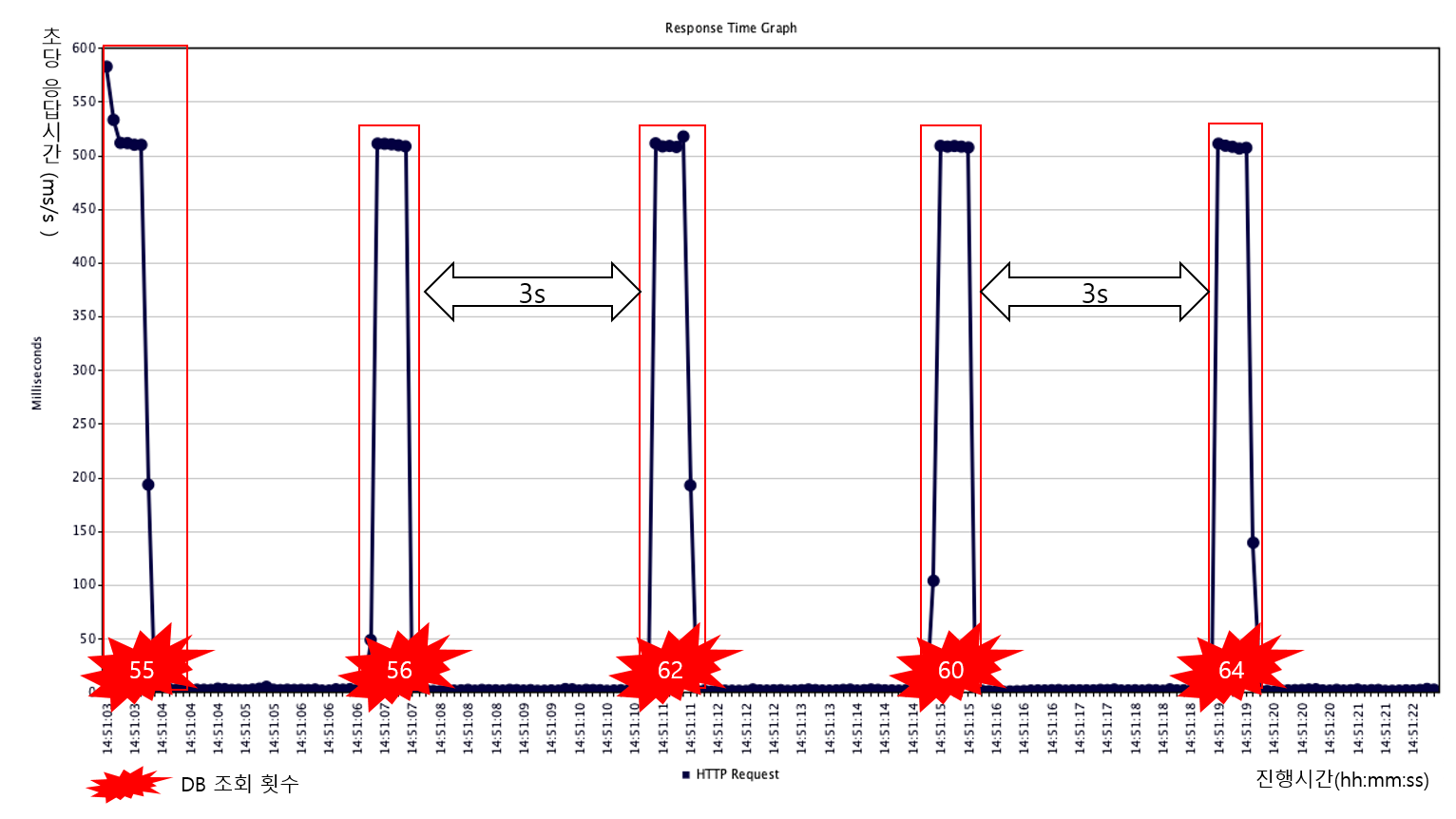
해당 기준으로 아무것도 적용하지 않는 기본 캐싱과 cache stampede 방지를 위해 PER을 적용하여 테스트한 결과는 아래와 같습니다.
- 캐싱 (cache miss : 4회, 응답지연 : 500ms, 중복쓰기 : 242회)
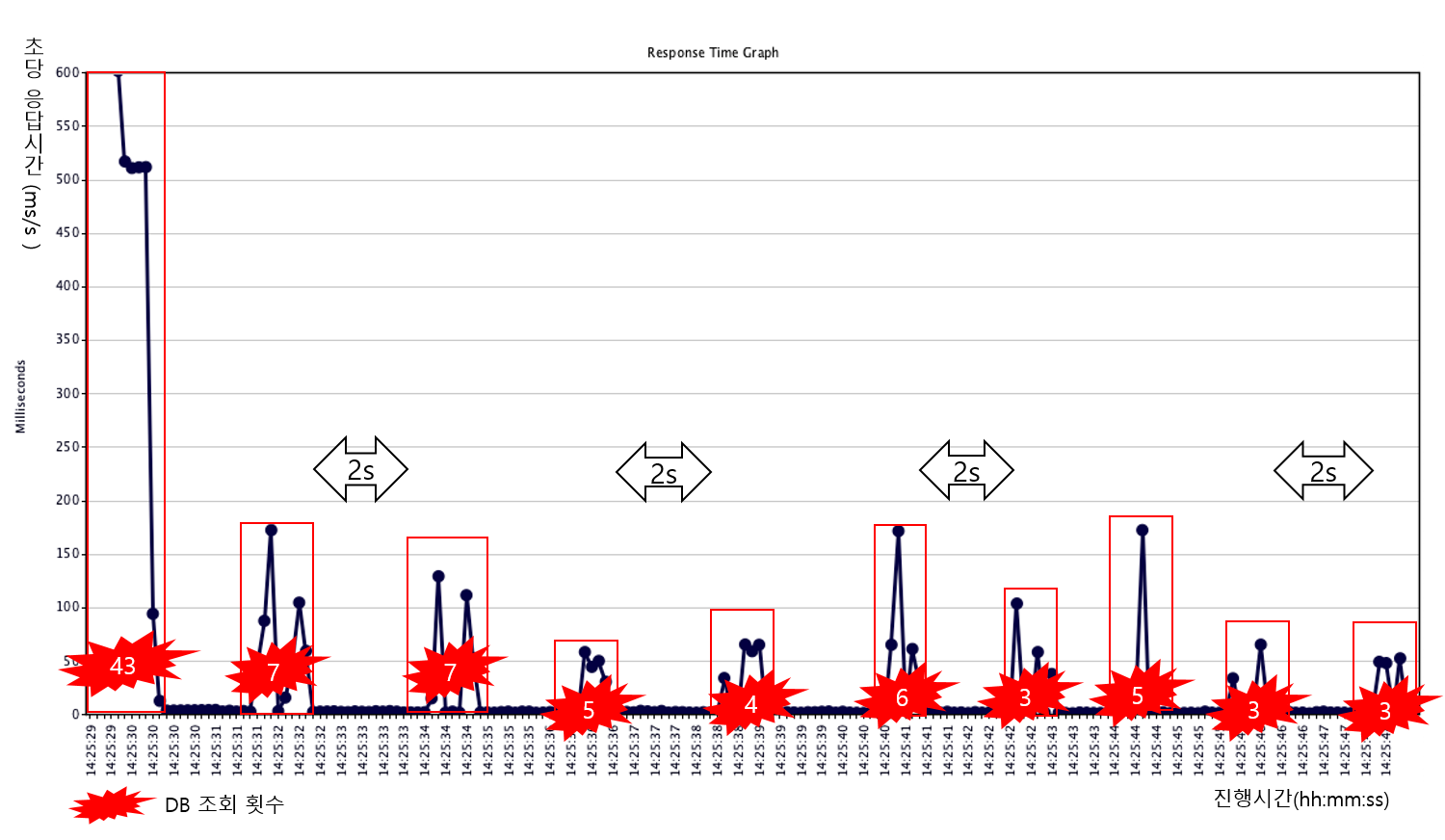
- PER (cache miss : 0회, 응답지연 : 100~200ms, 중복쓰기 : 43회)
결과를 살펴보면 기본 캐싱에서는 캐시가 만료되어 cache miss가 발생했고, 많은 요청이 한꺼번에 DB에 몰려 cache stampede 현상이 발생했습니다. 그래서 DB단에서 응답지연 현상이 발생했습니다. 그뿐만 아니라 cache miss로 인하여 모든 요청이 아이템을 캐싱하기 위해 중복으로 DB 조회 및 캐시 쓰기를 하는 현상이 발생하였습니다.
반면에 PER을 적용했을 경우는 미리 재캐싱이 이루어졌기 때문에 만료가 예정된 모든 구간에서 cache miss가 발생하지 않았고, 재캐싱 수행자들만 DB를 조회하여 응답 시간과 중복쓰기 횟수가 현저히 줄어들었음을 알 수 있습니다. 이를 통해 PER이 cache stampede 방지에 효과가 있음을 확인할 수 있었습니다.
실제 응용 환경 적용을 위한 테스트
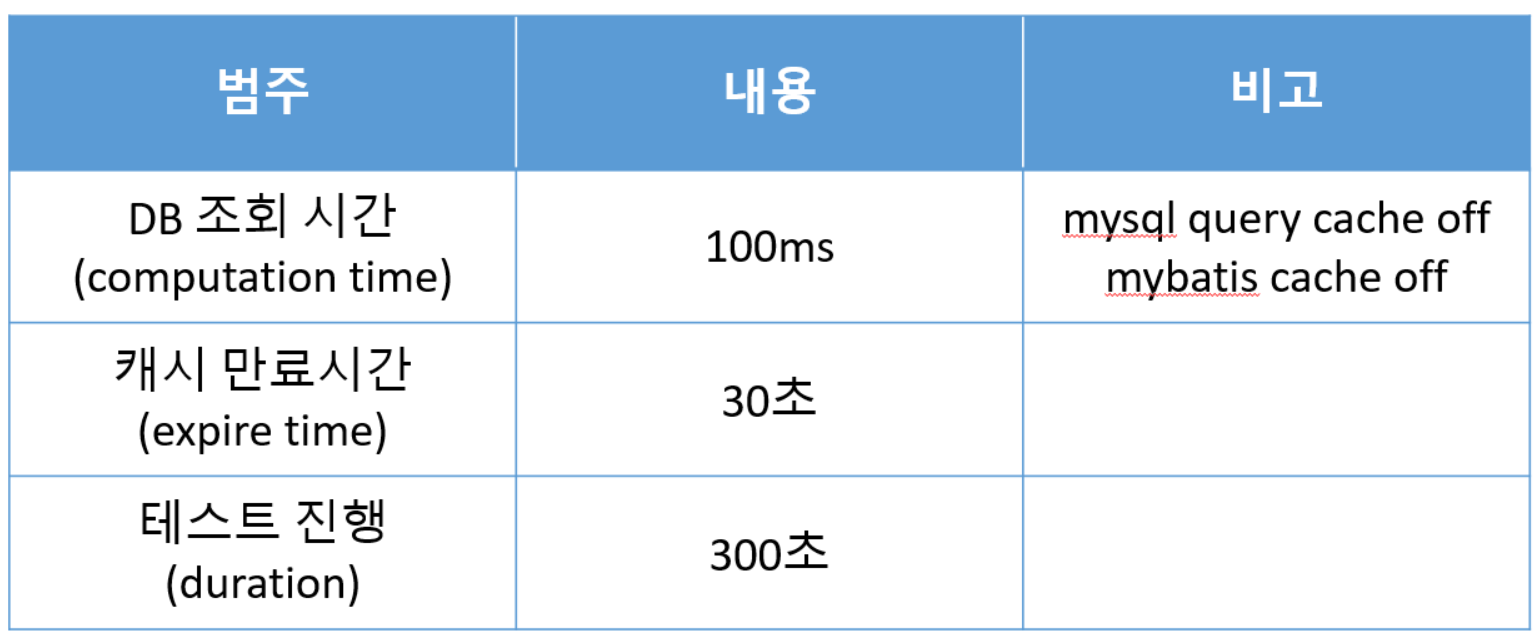
실제 응용에서는 DB 조회 시간이 대부분 수~ 수십ms 정도이며, 캐시 아이템의 만료시간도 짧게는 수십초 ~수분까지 설정하여 캐시를 사용하고 있습니다. PER이 실제 응용 환경에 적용이 가능한지 알아보기 위해 추가로 테스트를 진행해 보았습니다.
-
테스트 조건
-
Jmeter 설정
-
측정 요소
- cache miss 발생 횟수
- cache stampede로 인한 응답 지연 속도
- cache stampede로 인한 중복 쓰기 횟수
운영 환경에 맞춘 테스트의 결과는 아래와 같습니다.
-
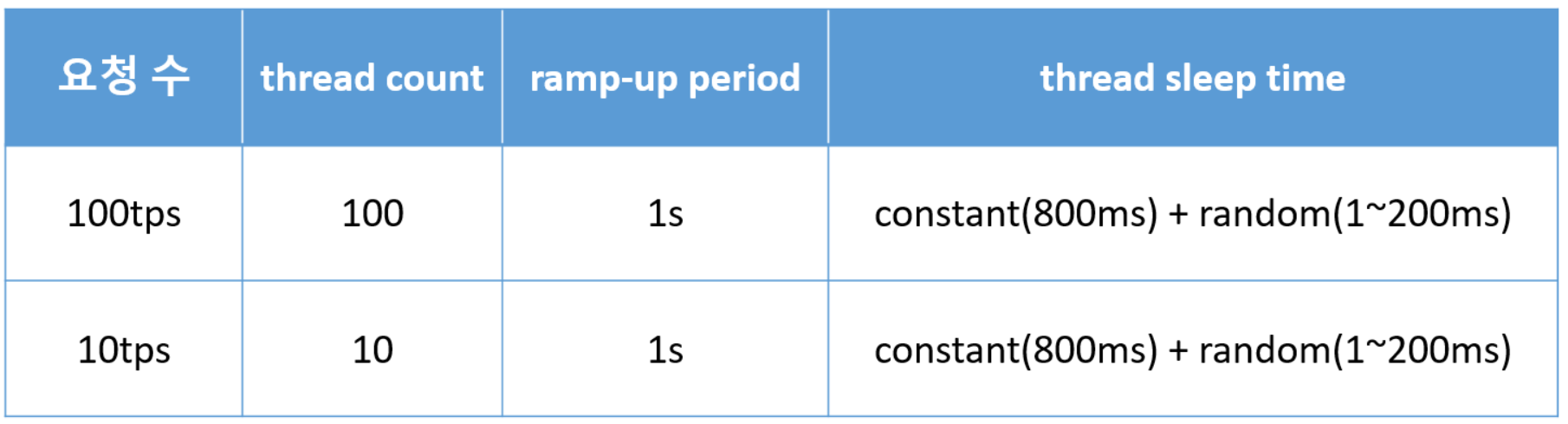
100tps (cache miss : 5회, 응답지연 : 0 ~ 100ms, 중복쓰기 : 95회)
-
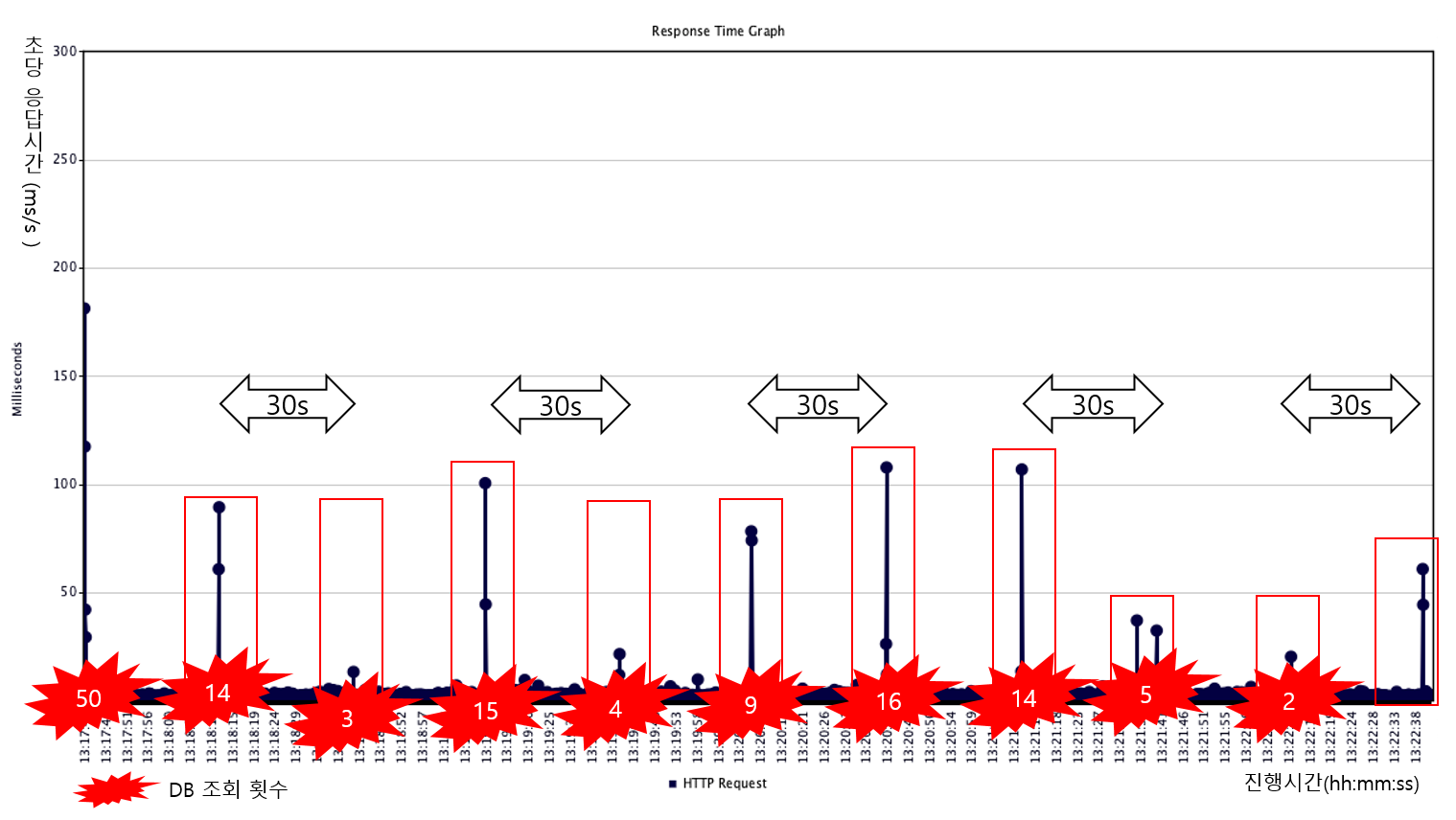
10tps (cache miss : 10회, 응답지연 : 100ms, 중복쓰기 : 20회)
실제 응용 환경에 맞추어 테스트 했을 경우 처음 테스트 결과와는 다른 결과가 나오게 됩니다.
처음 테스트와 비교하여 DB조회 시간만 달라진 100tps에서는 이전과 다르게 일부는 재캐싱, 일부는 cache miss 및 그로 인한 cache stampede 현상(응답지연과 중복 DB 조회 및 캐시 쓰기)이 반복적으로 발생하였습니다. 그리고 10tps에서는 모든 만료 구간에서 재캐싱이 일어나지 않고 cache miss가 발생했습니다. 왜 이런 결과가 발생한 것 일까요? 그 이유는 아래와 같습니다.
응용 환경 적용 테스트를 통한 문제점
1. ARCUS cache는 초 단위의 만료시간 측정으로 정밀하게 실제 시간에 만료되지 않음
- 실제 ms 단위로 재캐싱 여부를 결정하는 PER 알고리즘의 적용에 제한

ARCUS 내부에서는 아이템 만료를 위한 시스템 계산이 초 단위 형태로 수행됩니다. 위의 그림을 통해 설명하겠습니다. 서로 다른 캐시 아이템을 0~1초 사이의 다른 지점에서 만료시간(expire time)을 3초로 설정하였을 경우 실제 만료는 동시에 수행됩니다. 예를 들어 위 그림처럼 0초 지점에서 3초를 설정했다면 3초에 만료가 되며, 0.5초 지점에서 3초를 설정하였다면 3.5초의 지점이 아닌 3초 지점에서 만료가 됩니다.그 이유는 ARCUS 내부에서는 초 단위의 타이머(timer)를 가지고 캐시 아이템의 만료 처리를 하기 때문입니다.
응용에서 만료시간을 ms 단위까지 자세하게 측정하더라도 ARCUS에서는 초 단위로 만료를 처리하기 때문에 응용과 ARCUS 사이에 ms 만큼오차가 발생하며, 이는 재캐싱 여부를 판별할 때에도 오차로 인한 영향을 미치게 됩니다. 위 100tps 테스트에서 번갈아서 반복 형태로 cache miss가 일어난 이유의 원인이 해당 문제로 인해 발생한 것입니다.
2. tps가 낮은 요청은 재캐싱 확률이 낮음

실제 응용에서 초당 100회 정도의 요청이 있는 캐시 데이터는 hot data에 해당됩니다. 하지만 응용에서 캐싱하는 데이터는 대부분 hot data가 아닐것 입니다. 초당 수회 또는 그 이하의 드문 요청이면, 위의 오른쪽 그림과 같이 재캐싱 여부를 판별하는 구간에 요청이 들어오지 않아서 재캐싱은 이루어지지 않고 cache miss가 발생합니다. 그 결과는 위 테스트 10tps의 그래프를 통해 보실 수 있습니다.
3. DB 조회 시간(computation time)이 짧을 수록 재캐싱 판별구간이 줄어들어 재캐싱 확률이 감소
해당 이유에 대해서는 PER에서 재캐싱을 판별하는 알고리즘에 대한 지식이 필요합니다. 쉽게 그림으로 설명해 보겠습니다.
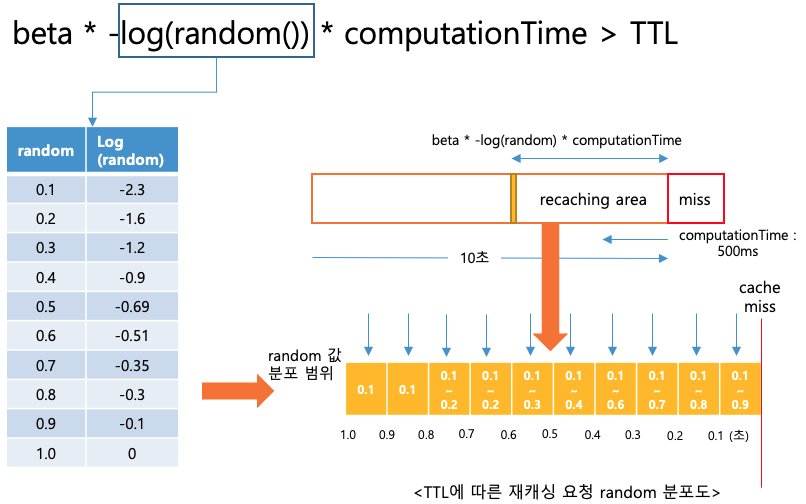
일단 재캐싱을 판별하는 알고리즘은 위의 수식과 같습니다. 실제 DB 조회 시간(computation time)에 확률적인 랜덤 값(-log(random())을 곱하여 잔여 만료 시간(TTL)과 비교해 재캐싱 여부를 결정합니다.
예를 들어 500ms의 DB 조회 시간의 경우 만료시간이 1.0 ~ 0.9초가 남은 시점에 재캐싱이 이루어질 확률은 1/10입니다. 위 그래프에서 보시는 것처럼 random 값이 0.1일때 500ms * 2.3(-log(0.1)) = 1150ms가 계산되어 실제 TTL(900 ~ 1000ms) 보다 크므로 재캐싱이 이루어지고 나머지의 랜덤 값(표 0.2 ~ 0.9)을 사용하여 계산한 결과는 잔여 만료 시간보다 작기 때문에 재캐싱이 이루어지지 않습니다. (노란색 그래프 안에 각 시간 별 random 값의 분포를 보실 수 있으며 그래프를 통해서 시간별 재캐싱 확률을 계산해 보실 수 있습니다.)
실제 응용에서는 DB 조회 시간이 수~ 수십ms 정도이기 때문에 해당 수식을 적용한다면 재캐싱 판별 구간이 상당히 줄어 많은 요청이 들어오더라도 재캐싱 요청을 할 가능성이 낮아집니다. 물론 범위를 늘려주기 위해 beta라는 상수를 이용해 설정할 수 있지만, 알고리즘을 적용한 API마다 DB조회 시간을 고려하여 상수를 다르게 적용하는 일은 사용자로서는 대단히 번거롭습니다.
결과 요약 및 요구사항
해당 내용을 정리하여 PER이 실제 환경에서 적용되기 위한 제약 조건을 정의하면 아래와 같습니다.
- 정확한 만료시간에 캐시 만료
- 높은 tps의 요청량 (최소 50tps 이상)
- DB 조회 시간이 클수록 효과적
해당 조건은 실제 서비스를 하는 ARCUS 공통모듈에 적용하기에는 제약사항이 많습니다. 그래서 공통모듈에 적용하기 위해 필요한 잼투인(JaM2in)만의 요구사항을 정의하고 그에 맞는 방안 도출이 필요했습니다.
- 캐시 만료 오차 범위 내에서 재캐싱
- 낮은 tps에서도 재캐싱 가능
- DB 조회 시간이 짧은 캐시 데이터에 대해서도 재캐싱 가능 효과 (DB 조회 시간과 무관하게 재캐싱)
- 지연시간 없이 모든 구간에서 수 ~ 수십ms 이내의 빠른 응답속도, 중복없는 DB조회 및 쓰기 요청
- 요청 스레드에서 재캐싱 판별 후 백그라운드 스레드에 재캐싱 요청
- PER의 경우 만료시간이 아주 짧게 남았을 때재캐싱 요청을 하므로 백그라운드 스레 드에서 재캐싱 수행시 짧은 만료 시간으로 인해 만료전에 캐싱을 완료하지 못하고 캐시 만료가 일어날 수 있음
위와 같은 요구사항을 통해 조금 더 구현 관점에서 cache stampede를 방지 할 수 있는 알고리즘을 고안하여 적용하게 되었습니다.
지속가능 캐싱 (sustainable caching)
지속가능 재캐싱 방법은 PER 알고리즘을 응용하여 고안된 방법입니다. 해당 방법은 DB 조회 시간 대신에 캐시 만료 시간의 10% 기준으로 PER 알고리즘을 적용하여 재캐싱 여부를 판별하는 방법으로, 낮은 요청에도 재캐싱이 이루어지게 합니다.

단순히 상수(beta)를 이용해 범위를 확장하지 않고, 만료 시간(expire time)의 1/10을 DB 조회 시간(computation time)으로 지정하여 사용합니다. 이것은 실제 응용 서비스에서 캐시 아이템의 TTL이 10% 남았을 때 재캐싱을 요청하는 형태로 캐싱 된 아이템을 만료시간의 90%만큼 사용하고 나머지 10%의 지점에서 계산을 통해 재캐싱을 수행합니다. 또한 DB 조회 시간에 관계없이 만료 시간을 통한 캐싱이 이루어지므로 재캐싱 범위에 영향이 없게 됩니다.
예를들어 만료설정 시간이 10초 이상일 경우 1/10에 해당하는 최소 시간은 1초로 해당 범위에서 재캐싱이 이루어지기 때문에 1tps에 해당하는 작은 요청량으로 요청이 들어와도 재캐싱이 이루어 지게 됩니다.
추가적으로 응답 지연을 제거하기 위해 재캐싱 요청 시 직접 캐싱 로직 수행을 하는 것이 아니라 충분한 시간을 가지고 백그라운드에서 재캐싱 작업이 수행되도록 요청을 하며, 중복 조회 및 쓰기 방지 기능도 추가하였습니다.
간단하게 재캐싱 유형 및 속성을 간단하게 정리하여 소개하면 아래와 같습니다.
-
PER
- 캐시 만료가 이루어지기 전 미리 재캐싱으로 miss 방지
- DB 조회시간(computation time)을 활용한 재캐싱
- 재캐싱 시 만료시간에 근접하여 재캐싱 진행하므로 해당 스레드에서 바로 재캐싱 -
SUS
- PER과 재캐싱 판별 알고리즘 로직 동일
- DB조회 시간(computation time)이 만료시간(expire time)의 10%미만 일 경우 expire time 비율을 활용해 재캐싱
- 재캐싱 시 백그라운드 프로세스에서 진행하며 중복 DB 조회 및 캐시 쓰기 방지 -
속성
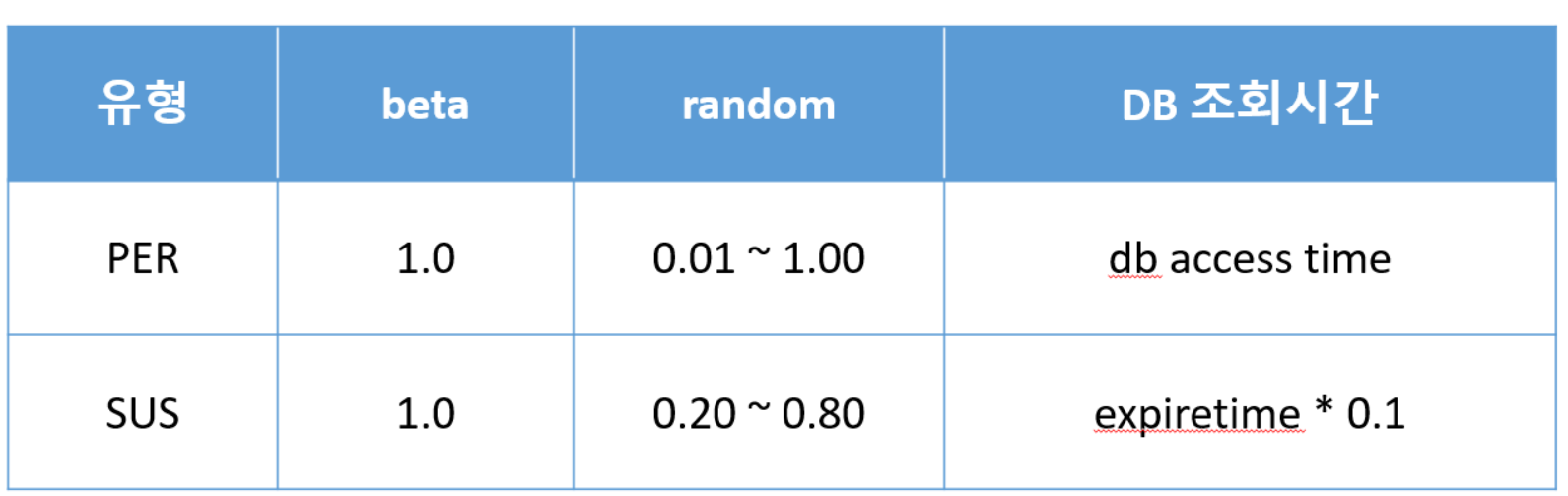
해당 알고리즘을 예제를 통해 비교 하면 아래와 같습니다 (DB조회 시간 : 100ms, 만료시간 : 30s)
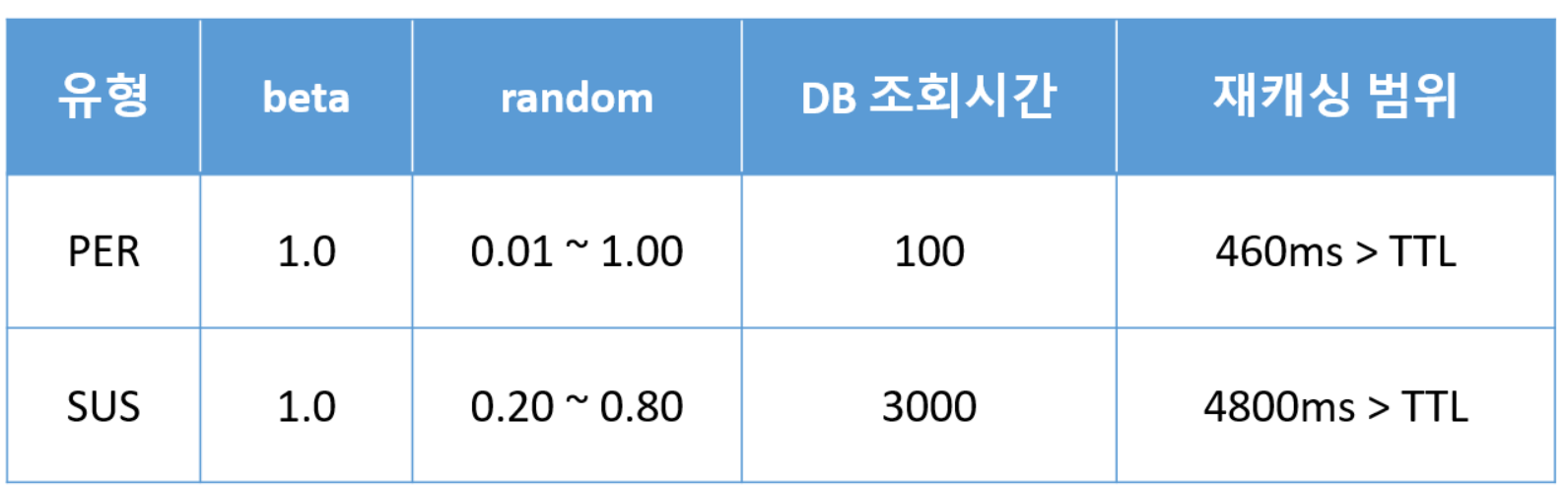
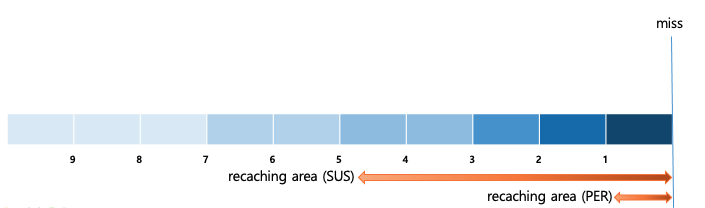
그래프로 예제의 재캐싱 범위를 확인하면 아래와 같습니다.
응용 환경에서의 SUS 방법 테스트
SUS 적용 성능 비교를 위하여 PER과 동일한 환경과 조건에서 테스트를 진행했습니다.
- 100tps (cache miss : 0회, 응답지연 : NONE, 중복쓰기 : 1회)
- 10tps (cache miss : 0회, 응답지연 : NONE, 중복쓰기 : 1회)
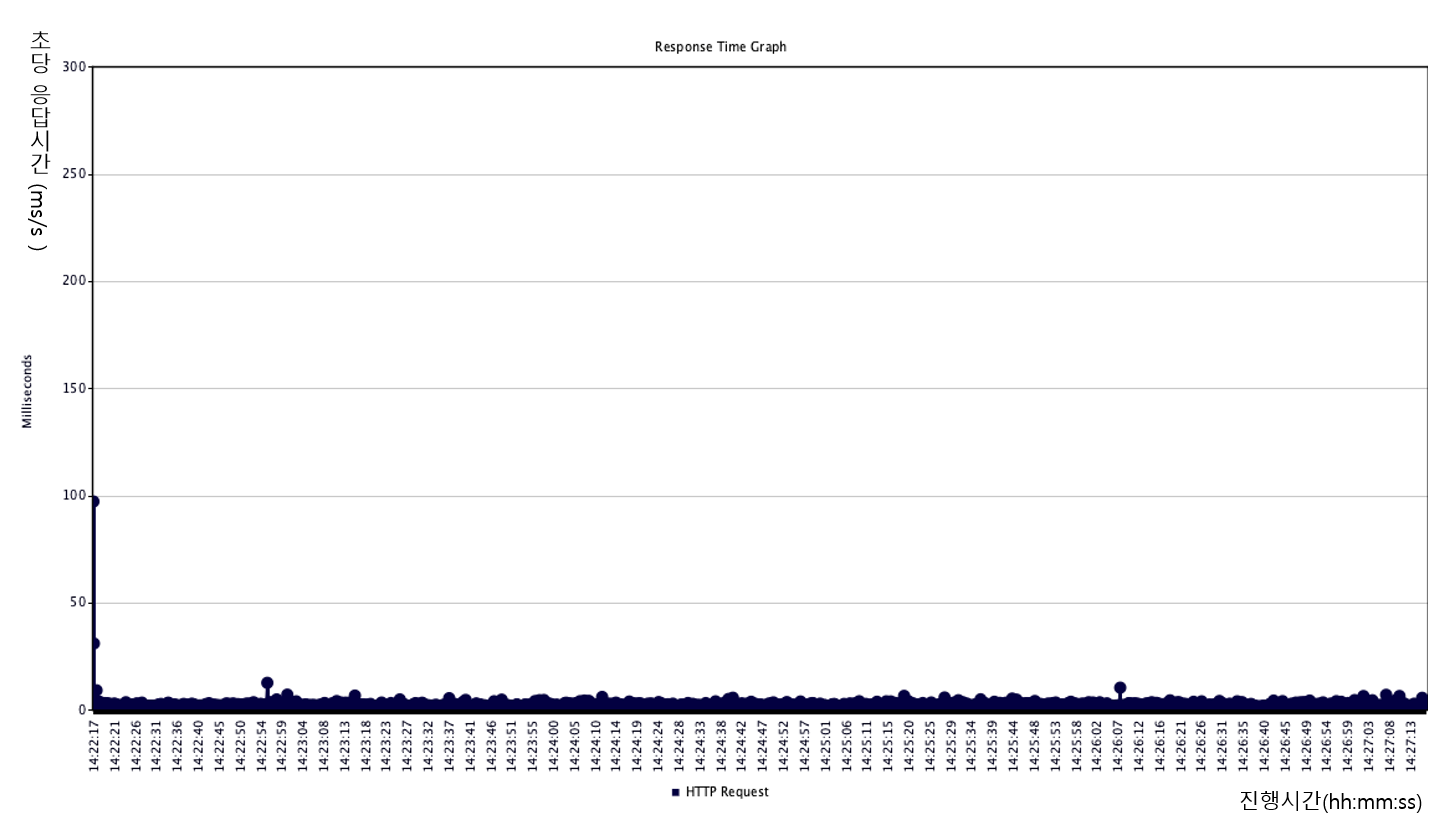
결과는 그래프로도 한눈에 볼수 있듯이, 실제 요구사항대로 알고리즘이 적용되어 큰 효과를 볼 수 있었습니다.
응답 지연없이 계속해서 캐싱된 데이터가 조회 되므로 아이템을 sticky하게 캐싱하여 응답받는 것과 비슷한 응답 효과를 낼 수 있습니다. 또한 재캐싱 요청시에도 중복 조회 및 쓰기 방지를 통해 DB의 부하도 경감할 수 있었습니다.
마치며
캐시 아이템의 만료시간 설정으로 인해 발생할 수 있는 문제를 살펴보았습니다. 그 중 많은 요청이 동시에 들어왔을 때 발생하는 cache stampede에 대한 문제와 그 문제를 해결하는 방법에 대해 알아보고, 응용에 적용하기 위한 테스트와 ARCUS 공통 모듈에 적용하는 sustainable caching 방법까지 함께 소개해 드렸습니다. 해당 방법은 많은 요청량 뿐만 아니라 적은 요청량에서도 DB의 조회시간에 관계없이 사용자에게 일정하게 빠른 시간내에 응답을 줄 수 있는 방법입니다. 앞으로 응용에 적용하기 위해 추가적인 준비 사항은 아래와 같습니다.
- 여러개의 API에 적용하여 동시 요청 테스트
- 백그라운드에서 재캐싱을 수행하기 위해 응용의 요청 수 별로 필요한 Thread 개수와 Queue의 적정 크기 도출
- 지속가능 캐싱 방법 도입시 이전과의 성능상 차이점 (WAS 처리량, DB 부하정도) 비교 및 수치화
또한 해당 알고리즘의 개선도 필요합니다.
- expire time이 1초 미만일 경우 (1초일 경우 DB조회 시간은 100ms로 설정됨) PER과 동일해 지는 알고리즘 개선
위와 같이 sustainable caching은 cache stampede를 해결하기 위해 요구사항을 반영한 하나의 방안이며 개선점과 테스트할 사항이 존재합니다. 이후에도응용에 적용하여 많은 테스트를 통해 수정과 개선이 이루어 질 것입니다. 이후의 포스팅도 기대해 주시기 바랍니다.