Intro
캐글의 안전 운전자 예측 경진대회 'Predict Future Sales' compeition에 참가해 다양한 feature engineering을 시도해보았다.
과거 판매 데이터를 바탕으로 향후 판매량을 예측하는 회귀 문제로, 독특하게 train data외에 3가지 데이터가 더 제공된다. 상점, 상품, 상품분류에 관한 정보를 담은 각각의 파일을 활용하여 데이터를 예측하는 것이다. 또한 타깃값(각 상점의 상품별 월간 판매량)은 반드시 0에서 20개 사이라는 것을 주의해야 한다.
EDA
데이터 둘러보기
-
데이터를 불러오고 먼저 sales_train 데이터를 살펴본다.
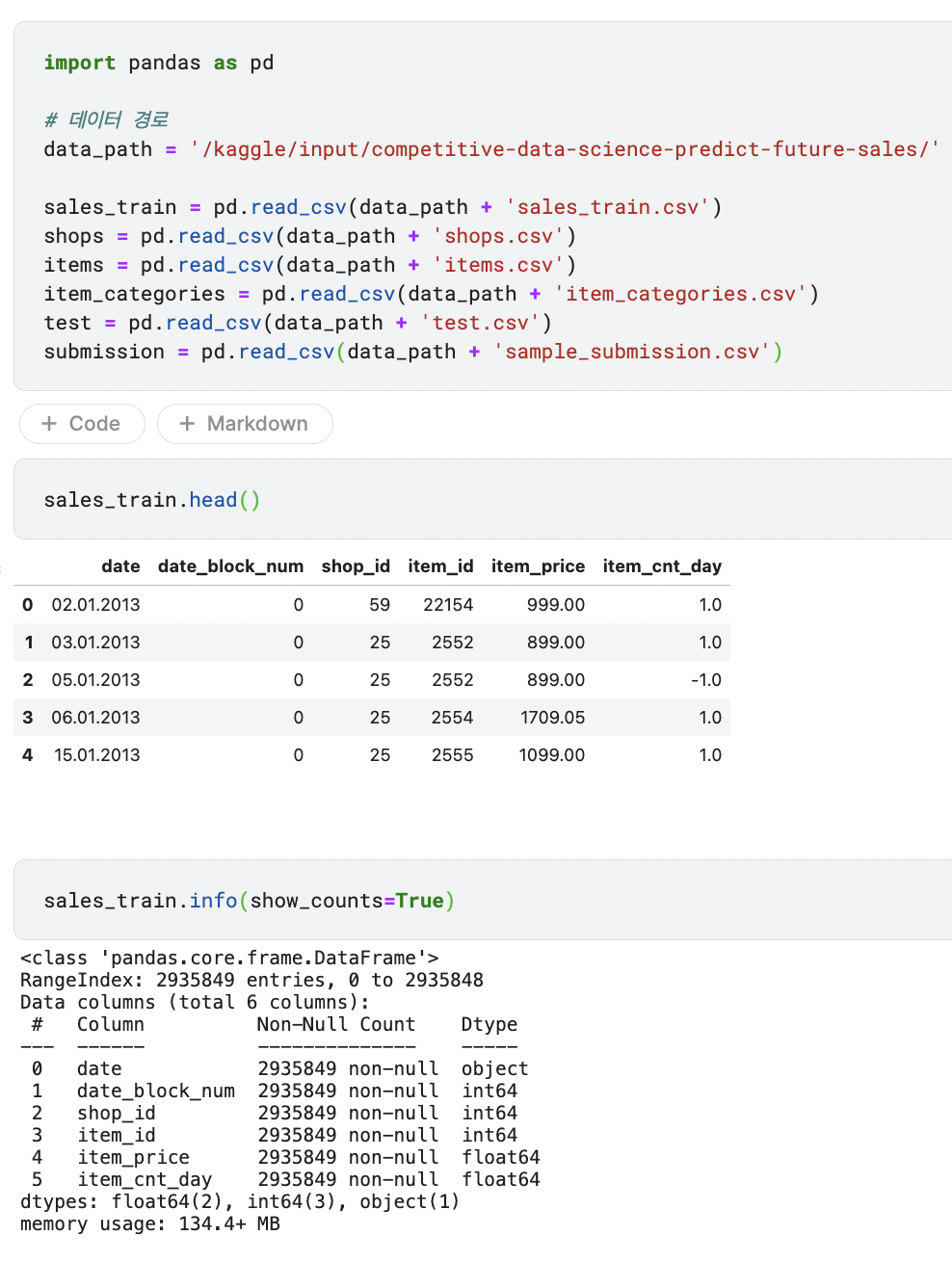
- date feature는 날짜를 나타내고, date_block_num은 월을 나타내는데, 2013년 1월부터 0으로 시작해 2월은 1, 33은 2015년 10월을 의미한다. 타깃값은 월별 판매량이므로 date_block_num만 있으면 되니 date feature는 제거하도록 한다.
- item_price는 상품 판매가로, 상점과 날짜에 따라 달라질 수 있음을 기억한다.
- item_cnt_day feature는 당일 판매량인데, 필요한 것은 월간 판매량이므로 이를 구하도록 한다. 각 상점의 상품별 일일 판매량을 월별로 합친 값이 곧 상점의 상품별 월간 판매량이다. date_block_num feature를 기준으로 그룹화해서 item_cnt_day 값을 합해 타깃값을 만든다.
- info()를 살펴보면 show_counts=True를 입력했는데, 비결측값 개수를 표시하기 위함이다. DataFrame의 행이 1,690,785개 보다 많거나 열이 100개 보다 많은 경우 비결측값 개수는 기본적으로 출력하지 않기 때문이다. 또한, 메모리 사용량이 134MB를 넘을 정도로 많으므로 작업 속도를 위해 줄여주는 작업이 필요해보인다.
- 본 데이터는 시계열 데이터로 순서가 중요하기에, 2013년 1월 ~ 2015년 9월까지의 판매 내역을 training data로 사용하고 2015년 10월 판매 내역을 valid data로 사용한다. 시간이 뒤섞이면 안되기에 OOF 등 여러 폴드로 나누는 것이 불가능하기 때문이다.
-
shops 데이터
- 상점에 관한 추가 정보가 담긴 shops 데이터를 살펴본다.

- 상점명은 러시아어로 되어 있는데, 다른 캐글러가 공유한 코드를 참고하면, 상점명의 첫 단어는 상점이 위치한 도시를 뜻한다. 이를 활용해 도시 feature를 새로 만들 수 있다.
- shop_id feature는 sales_train에도 있는 feature로, 이를 기준으로 sales_train과 shops를 병합할 수 있다.
- 상점에 관한 추가 정보가 담긴 shops 데이터를 살펴본다.
-
items 데이터
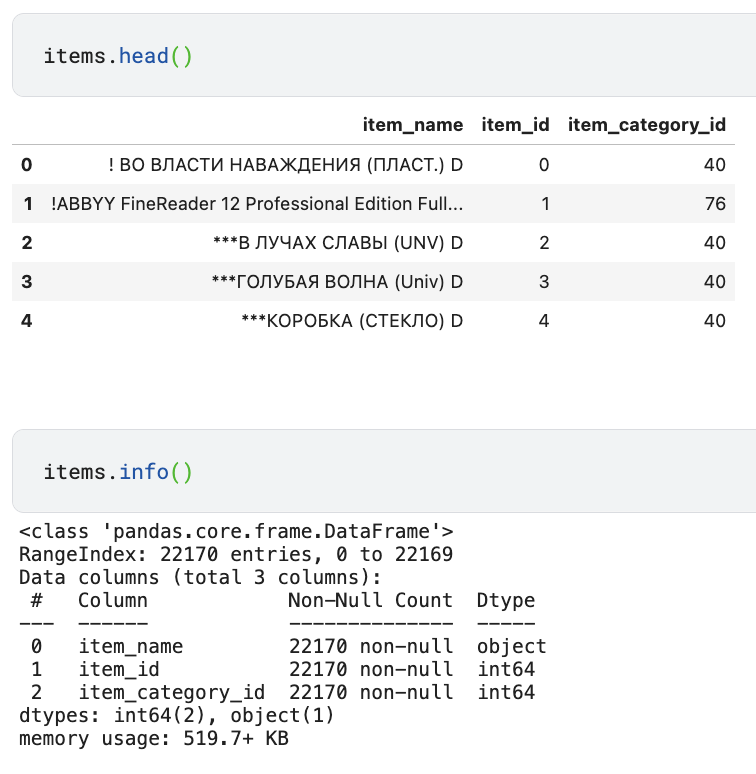
- 상품명에서는 유용한 정보를 얻기 힘드므로 feature를 제거하도록 하고, item_id를 기준으로 sales_train과 병합할 수 있다.
-
item_categories 데이터
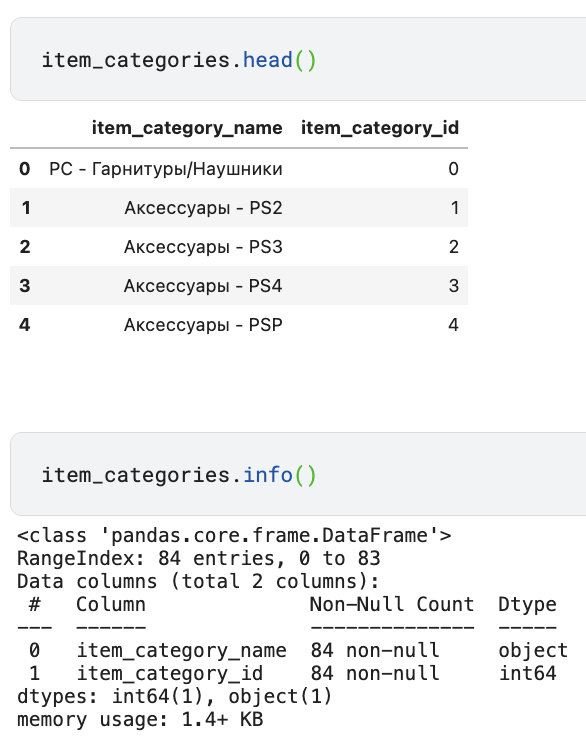
- 상품분류명에서 첫 단어는 대분류를 뜻하고, item_cateogry_id를 기준으로 sales_train과 병합할 수 있다.
-
test data
- test data의 식별자 ID, 상점 ID, 상품 ID로 구성이 되어 있고 각 상점의 상품별 월간 판매량을 예측해야 한다.
-
데이터 병합
- 하나 이상의 열을 기준으로 DataFrame 행을 합치는 merge()함수로 sales_train, shops, items, item_categories 데이터를 병합하고 이를 활용해 feature 요약표를 만들고 시각화도 해볼 수 있다.
train = sales_train.merge(shops, on='shop_id', how='left') train = train.merge(items, on='item_id', how='left') train = train.merge(item_categories, on='item_category_id', how='left') train.head()- 기준이 되는 DataFrame에서 merge()함수를 호출하고, 병합할 DataFrame을 인수로 넣어준다. on 파라미터에는 병합 시 기준이 되는 feature를 전달하고, how 파라미터에 'left'를 전달하면 왼쪽 DataFrame의 모든 행을 포함하는 결과를 반환한다.

-
Feature 요약표
-
병합한 train을 활용해 데이터 타입, 결측값 개수, 첫번째 값, 두번째 값을 포함하는 feature 요약표를 만든다.
def resumetable(df): print(f'데이터 세트 형상: {df.shape}') summary = pd.DataFrame(df.dtypes, columns=['데이터 타입']) summary = summary.reset_index() summary = summary.rename(columns={'index': '피처'}) summary['결측값 개수'] = df.isnull().sum().values summary['고윳값 개수'] = df.nunique().values summary['첫 번째 값'] = df.loc[0].values summary['두 번째 값'] = df.loc[1].values return summary resumetable(train)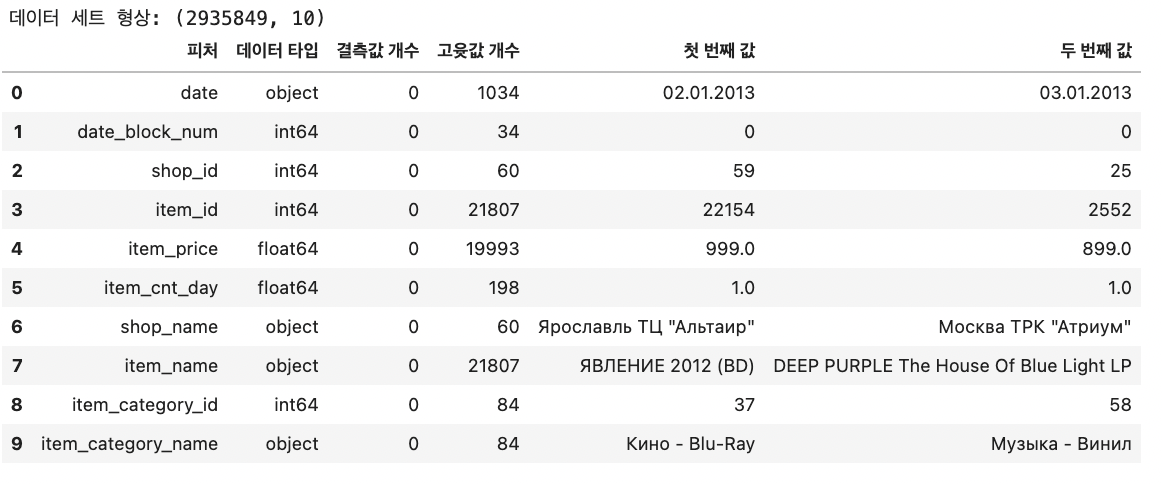
-
shop_id는 shop_name과, item_id는 item_name과, item_category_id는 item_category_name과 고윳값의 개수가 같은 것으로 보아, 1:1로 매칭됨을 알 수 있다. 따라서 둘 중 하나를 제거하도록 한다.
-
데이터 시각화
-
일별 판매량
-
train에서의 두 수치형 데이터 item_cnt_day, item_price feature를 박스플롯으로 시각화해본다.
import seaborn as sns import matplotlib as mpl import matplotlib.pyplot as plt %matplotlib inline sns.boxplot(y='item_cnt_day', data=train);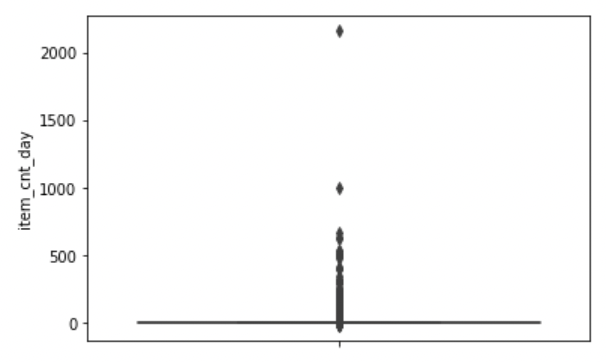
- 이상치 범위가 과도하게 넓어 박스 모양이 이상해졌으므로 이상치를 제거하도록 한다. item_cnt_day가 1000 이상인 데이터를 제거한다.
-
-
판매가(상품 가격)
- item_price feature도 박스플롯으로 그려준다.
sns.boxplot(y='item_price', data=train);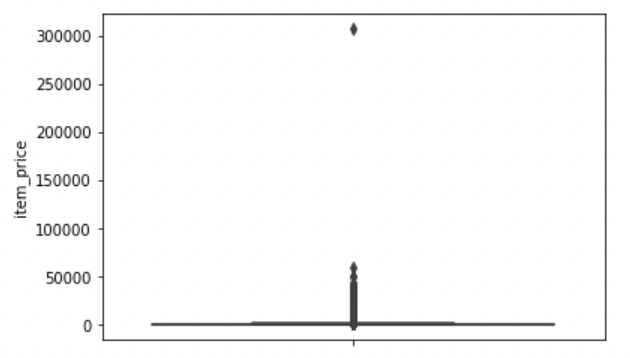
- 마찬가지로 박스가 이상하니 50000 이상인 이상치는 제거해준다.
- item_price feature도 박스플롯으로 그려준다.
-
그룹화
- groupby()로 데이터를 특정 featue 기준으로 그룹화해 원하는 집계값을 구한다.
- train의 data_block_num feature를 기준으로 그룹화해 item_cnt_day feature 값의 합을 구한다. (월별 월간 판매량을 구한다.)
group = train.groupby('date_block_num').agg({'item_cnt_day': 'sum'}) group.reset_index() # 인덱스 재설정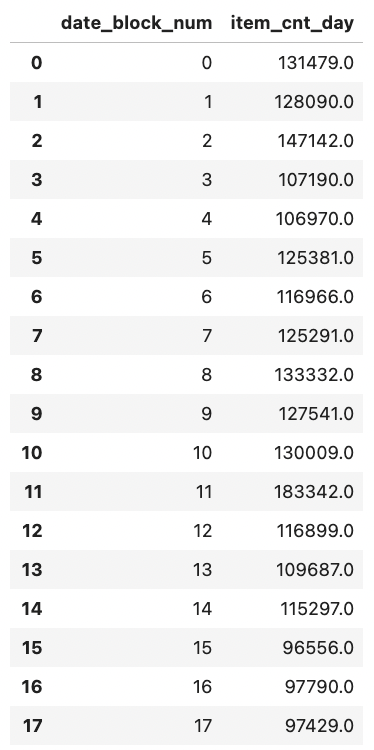
-
월별 판매량
-
groupby 합 연산 결과를 막대그래프로 시각화한다.
mpl.rc('font', size=13) figure, ax = plt.subplots() figure.set_size_inches(11, 5) # 월별 총 상품 판매량 group_month_sum = train.groupby('date_block_num').agg({'item_cnt_day': 'sum'}) group_month_sum = group_month_sum.reset_index() # 월별 총 상품 판매량 막대그래프 sns.barplot(x='date_block_num', y='item_cnt_day', data=group_month_sum) # 그래프 제목, x축 라벨, y축 라벨명 설정 ax.set(title='Distribution of monthly item counts by date block number', xlabel='Date block number', ylabel='Monthly item counts');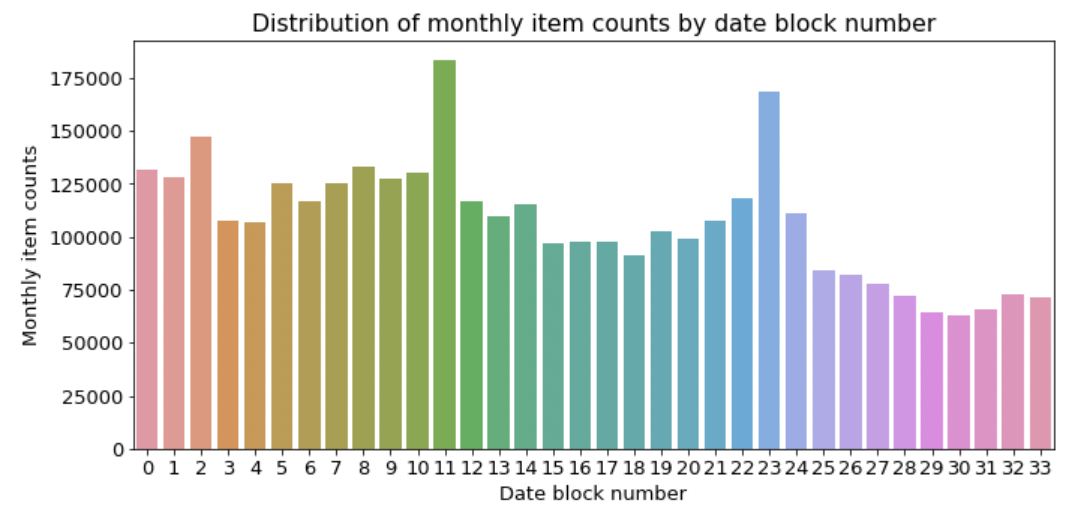
- 11, 13일 때 가장 판매량이 많은데, 이는 2013년 12월, 2014년 12월으로 연말해 판매량이 급증한 것을 알 수 있다.
-
-
상품분류별 판매량
-
nunique()가 feature 고윳값 개수를 알 수 있는데, 상품분류 feature는 총 84개로 너무 많으니 판매량 10,000개를 초과하는 상품분류만 추출해 막대그래프로 그려보도록 한다.
figure, ax= plt.subplots() figure.set_size_inches(11, 5) # 상품분류별 총 상품 판매량 group_cat_sum = train.groupby('item_category_id').agg({'item_cnt_day': 'sum'}) group_cat_sum = group_cat_sum.reset_index() # 총 판매량이 10,000개를 초과하는 상품분류만 추출 group_cat_sum = group_cat_sum[group_cat_sum['item_cnt_day'] > 10000] # 상품분류별 총 상품 판매량 막대그래프 sns.barplot(x='item_category_id', y='item_cnt_day', data=group_cat_sum) ax.set(title='Distribution of total item counts by item category id', xlabel='Item category ID', ylabel='Total item counts') ax.tick_params(axis='x', labelrotation=90) # x축 라벨 회전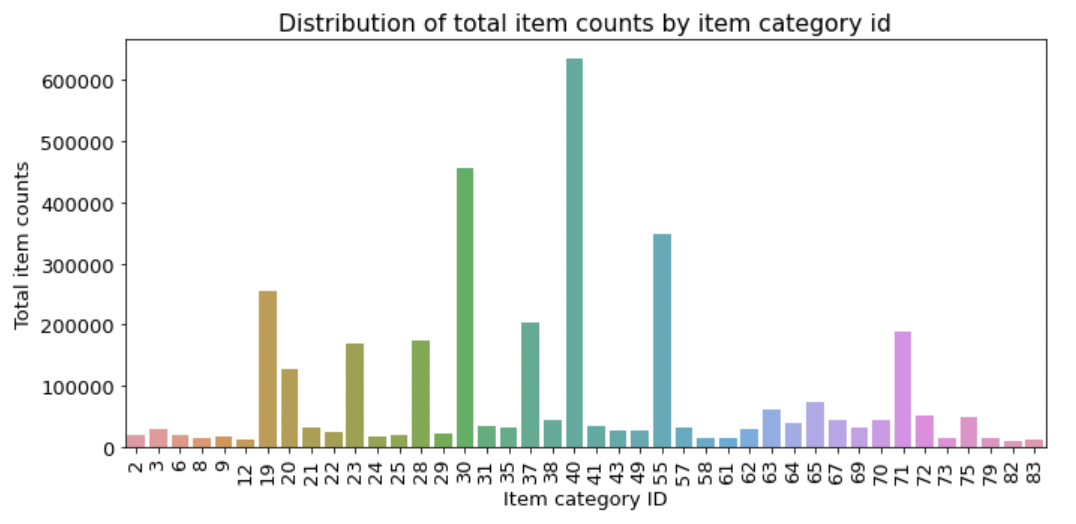
- ID가 40, 30, 55등 몇몇 상품분류가 다른 범주에 비해 많이 팔리는 것을 알 수 있다.
-
-
상점별 판매량
-
판매량이 10,000개를 초과하는 상점의 상점별 월간 판매량을 살펴본다.
figure, ax= plt.subplots() figure.set_size_inches(11, 5) # 상점별 총 상품 판매량 group_shop_sum = train.groupby('shop_id').agg({'item_cnt_day': 'sum'}) group_shop_sum = group_shop_sum.reset_index() group_shop_sum = group_shop_sum[group_shop_sum['item_cnt_day'] > 10000] # 상점별 총 상품 판매량 막대그래프 sns.barplot(x='shop_id', y='item_cnt_day', data=group_shop_sum) ax.set(title='Distribution of total item counts by shop id', xlabel='Shop ID', ylabel='Total item counts') ax.tick_params(axis='x', labelrotation=90)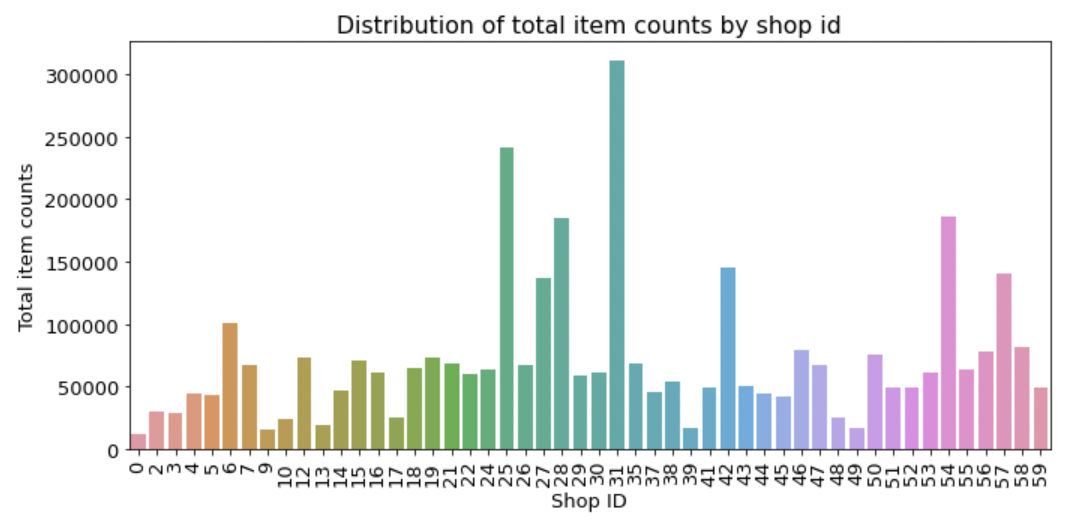
- ID 31, 25 등 7~8개의 상점이 다른 상점보다 많이 판매함을 알 수 있다.
-
Baseline Model
Feature Engineering 1: Feature명 한글화
-
헷갈리는 Feature명이 많으니 한글화시켜준다.
sales_train = sales_train.rename(columns={'date': '날짜', 'date_block_num': '월ID', 'shop_id': '상점ID', 'item_id': '상품ID', 'item_price': '판매가', 'item_cnt_day': '판매량'}) shops = shops.rename(columns={'shop_name': '상점명', 'shop_id': '상점ID'}) items = items.rename(columns={'item_name': '상품명', 'item_id': '상품ID', 'item_category_id': '상품분류ID'}) item_categories = item_categories.rename(columns= {'item_category_name': '상품분류명', 'item_category_id': '상품분류ID'}) test = test.rename(columns={'shop_id': '상점ID', 'item_id': '상품ID'}) sales_train.head()
Feature Engineering 2: 데이터 다운캐스팅
-
더 작은 데이터 타입으로 변환하는 작업인 다운캐스팅(downcasting)을 수행한다. 주어진 데이터 크기에 딱 맞는 타입을 사용하는 것이 메모리 낭비를 막고 훈련 속도를 향상시켜주기에 다운캐스팅을 수행한다.
-
downcast()함수로 해당 feature 크기에 맞게 적절한 타입으로 바꿔준다.
def downcast(df, verbose=True): start_mem = df.memory_usage().sum() / 1024**2 for col in df.columns: dtype_name = df[col].dtype.name if dtype_name == 'object': pass elif dtype_name == 'bool': df[col] = df[col].astype('int8') elif dtype_name.startswith('int') or (df[col].round() == df[col]).all(): df[col] = pd.to_numeric(df[col], downcast='integer') else: df[col] = pd.to_numeric(df[col], downcast='float') end_mem = df.memory_usage().sum() / 1024**2 if verbose: print('{:.1f}% 압축됨'.format(100 * (start_mem - end_mem) / start_mem)) return dfall_df = [sales_train, shops, items, item_categories, test] for df in all_df: df = downcast(df)
Feature Engineering 3: 데이터 조합 생성
-
Test data에 있는 fetaure는 ID feature, 상점 feature, 상품ID feature로, 각 상점의 상품별 월간 판매량이 필요하므로 월, 상점, 상품별 조합이 필요하다. 월ID, 상점ID, 상품ID feature 조합을 만드는데, 월 ID별로 한 번이라도 등장한 상점ID, 상품ID가 있다면 그것들의 조합을 만든다. 원본 데이터에 없는 데이터는 판매량을 0으로 해서 만든다.
from itertools import product train = [] # 월ID, 상점ID, 상품ID 조합 생성 for i in sales_train['월ID'].unique(): all_shop = sales_train.loc[sales_train['월ID']==i, '상점ID'].unique() all_item = sales_train.loc[sales_train['월ID']==i, '상품ID'].unique() train.append(np.array(list(product([i], all_shop, all_item)))) idx_features = ['월ID', '상점ID', '상품ID'] # 기준 피처 # 리스트 타입인 train을 DataFrame 타입으로 변환 train = pd.DataFrame(np.vstack(train), columns=idx_features) train
-
월ID의 고윳값 별로 모든 상점ID 고윳값, 상품ID고윳값을 구해 조합을 생성한다.
-
이렇게 만든 train을 training data의 뼈대로 하여, train에 타깃값, shops, items, item_categories를 병합할 예정이다.
-
Feature Engineering 4: 타깃값(월간 판매량) 추가
-
train data에 타깃값인 각 상점의 상품별 월간 판매량을 추가해야하는데, sales_train의 판매량 feature는 일별 판매량을 나타내므로 groupby()를 활용한다. 월ID, 상점ID, 상품ID를 기준으로 그룹화해 판매량을 더한다.
# idx_features를 기준으로 그룹화해 판매량 합 구하기 group = sales_train.groupby(idx_features).agg({'판매량': 'sum'}) # 인덱스 재설정 group = group.reset_index() # 피처명을 '판매량'에서 '월간 판매량'으로 변경 group = group.rename(columns={'판매량': '월간 판매량'}) group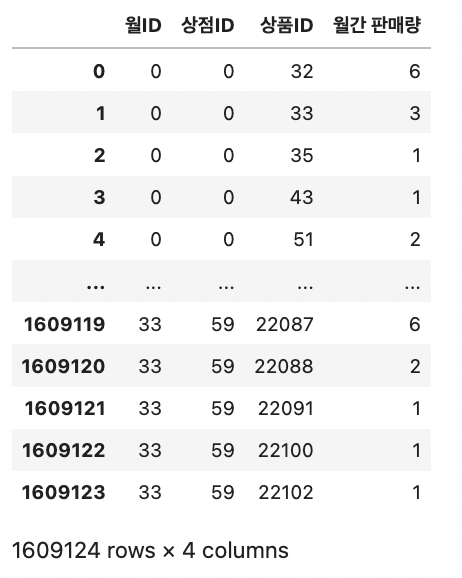
-
이렇게 만든 group을 앞의 train과 병합해준다.
# train과 group 병합하기 train = train.merge(group, on=idx_features, how='left') train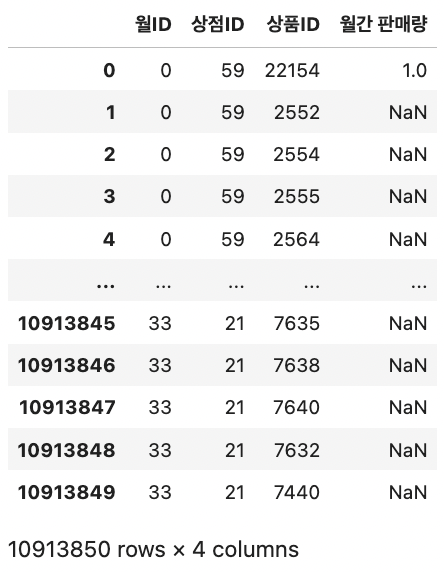
* 참고) garbage collection
-
할당한 메모리 중 더는 사용하지 않는 영역을 해제하는 기능으로, 메모리를 효율적으로 관리해준다. 틈틈이 garbage collection을 해주면 메모리가 초과되는 경우를 방지해준다.
import gc # 가비지 컬렉터 불러오기 del group # 더는 사용하지 않는 변수 지정 gc.collect(); # 가비지 컬렉션 수행
Feature Engineering 5: test data 이어붙이기
-
train data의 월ID는 0~33으로 마지막이 2015년 10월인데, test data는 2015년 11월 판매 기록이므로 월ID feature를 34로 설정해준다.
test['월ID'] = 34 -
test data에서 식별자 역할을 하는 ID feature를 제외하고 test data를 train data와 이어붙인다.
# train과 test 이어붙이기 all_data = pd.concat([train, test.drop('ID', axis=1)], ignore_index=True, # 기존 인덱스 무시(0부터 새로 시작) keys=idx_features) # 이어붙이는 기준이 되는 피처 -
결측값은 0으로 대체한다.
# 결측값을 0으로 대체 all_data = all_data.fillna(0) all_data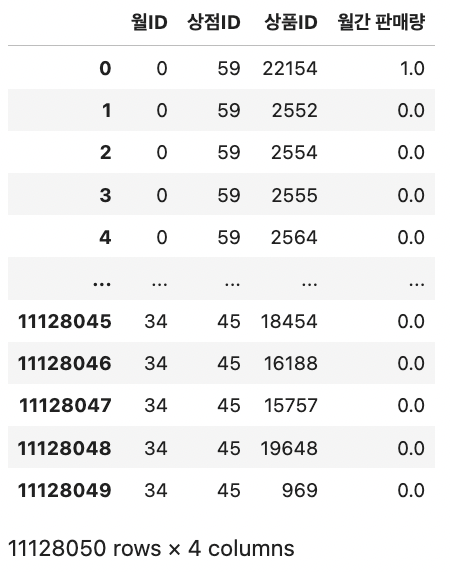
Feature Engineering 6: 나머지 데이터 병합 (최종 데이터 생성)
-
추가 정보로 제공된 shops, items, item_categories 데이터를 all data에 병합하고, 메모리 절약을 위해 downcasting과 garbage collection을 수행한다.
# 나머지 데이터 병합 all_data = all_data.merge(shops, on='상점ID', how='left') all_data = all_data.merge(items, on='상품ID', how='left') all_data = all_data.merge(item_categories, on='상품분류ID', how='left') # 데이터 다운캐스팅 all_data = downcast(all_data) # 가비지 컬렉션 del shops, items, item_categories gc.collect();
-
상점명, 상품명, 상품분류명 feature는 ID와 일대일 매칭이되는 중복되는 feature이므로 제거해준다.
all_data = all_data.drop(['상점명', '상품명', '상품분류명'], axis=1)
Feature Engineering 7: 마무리
-
모든 데이터를 병합한 all_data를 활용해 train, valid, test data를 월ID기준으로 나누어 만든다.
-
train data: 2013년 1월 ~ 2015년 9월 (월ID: 32) 판매 내역
-
valid data: 2015년 10월 (월ID: 33) 판매 내역
-
test data: 2015년 11월 (월ID: 34) 판매 내역
# 훈련 데이터 (피처) X_train = all_data[all_data['월ID'] < 33] X_train = X_train.drop(['월간 판매량'], axis=1) # 검증 데이터 (피처) X_valid = all_data[all_data['월ID'] == 33] X_valid = X_valid.drop(['월간 판매량'], axis=1) # 테스트 데이터 (피처) X_test = all_data[all_data['월ID'] == 34] X_test = X_test.drop(['월간 판매량'], axis=1) # 훈련 데이터 (타깃값) y_train = all_data[all_data['월ID'] < 33]['월간 판매량'] y_train = y_train.clip(0, 20) # 타깃값을 0 ~ 20로 제한 # 검증 데이터 (타깃값) y_valid = all_data[all_data['월ID'] == 33]['월간 판매량'] y_valid = y_valid.clip(0, 20)- clip()을 활용해 타깃값을 0~20 사이로 제한해주었다.
-
train, valid, test data를 할당했으니 all_data를 제거해준다.
del all_data gc.collect();
모델 훈련 및 성능 검증
-
LightGBM을 사용해 Baseline Model을 만들텐데, 범주형 데이터는 cat_features에 따로 전달한다. 범주형 데이터 상점ID, 상품ID, 상품분류ID 중 상품, 상품분류ID만 전달하는데, 상품ID는 고윳값 개수가 너무 많아 모델의 성능을 떨어뜨리기 때문이다. 고윳값 개수가 너무 많은 범주형 데이터의 경우, 수치형 데이터로 취급해야 성능이 더 잘 나온다.
import lightgbm as lgb # LightGBM 하이퍼파라미터 params = {'metric': 'rmse', # 평가지표 = rmse 'num_leaves': 255, 'learning_rate': 0.01, 'force_col_wise': True, 'random_state': 10} # 범주형 피처 설정 cat_features = ['상점ID', '상품분류ID'] # LightGBM 훈련 및 검증 데이터셋 dtrain = lgb.Dataset(X_train, y_train) dvalid = lgb.Dataset(X_valid, y_valid) # LightGBM 모델 훈련 lgb_model = lgb.train(params=params, train_set=dtrain, num_boost_round=500, valid_sets=(dtrain, dvalid), categorical_feature=cat_features, verbose_eval=50)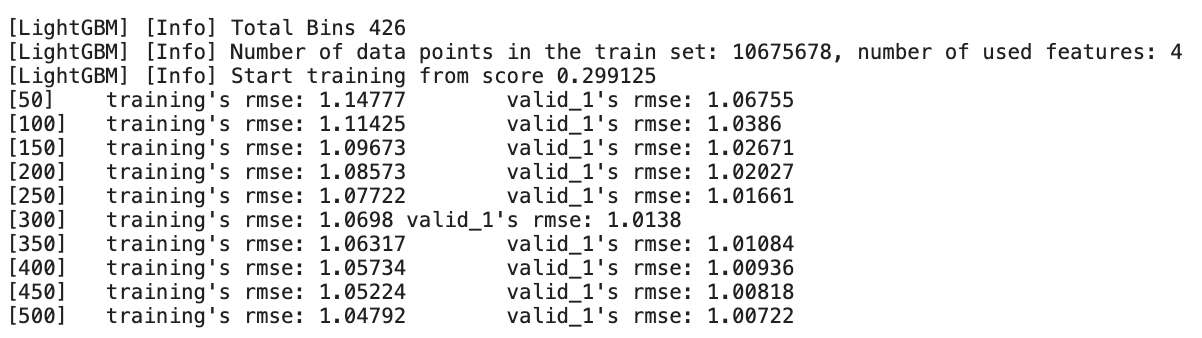
- 검증데이터로 측정한 RMSE 점수는 1.00722를 기록했다.
예측
-
타깃값은 0~20사이의 값이므로 예측한 값을 clip()함수로 범위를 제한해준다.
# 예측 preds = lgb_model.predict(X_test).clip(0, 20) -
메모리 사용량을 줄여주기 위해 garbage collection을 한번 해준다.
del X_train, y_train, X_valid, y_valid, X_test, lgb_model, dtrain, dvalid gc.collect(); -
해당 baseline model의 public score는 1.08160정도로, 상위 56% 정도되는데, feature engineering의 강화로 성능을 더 개선해보도록 한다.
성능 개선
개별 데이터 feature engineering
-
sales_train, shops, items, item_categories 데이터를 각각 feature engineering 해준다.
-
sales_train 이상치 제거 및 전처리
-
판매가가 0 ~ 50000 사이, 판매량이 0 ~ 1000 사이인 데이터만 추출한다.
# 판매가가 0보다 큰 데이터 추출 sales_train = sales_train[sales_train['판매가'] > 0] # 판매가가 50,000보다 작은 데이터 추출 sales_train = sales_train[sales_train['판매가'] < 50000] # 판매량이 0보다 큰 데이터 추출 sales_train = sales_train[sales_train['판매량'] > 0] # 판매량이 1,000보다 작은 데이터 추출 sales_train = sales_train[sales_train['판매량'] < 1000] -
상점명을 조금 다르게 기입해서 같은 상점인데 다르게 기록되어 있는 상점이 4쌍 있기에 각 쌍의 상점ID를 수정해준다. 상점명은 어차피 제거할 것이기에 수정하지 않아도 된다.
# sales_train 데이터에서 상점ID 수정 sales_train.loc[sales_train['상점ID'] == 0, '상점ID'] = 57 sales_train.loc[sales_train['상점ID'] == 1, '상점ID'] = 58 sales_train.loc[sales_train['상점ID'] == 10, '상점ID'] = 11 sales_train.loc[sales_train['상점ID'] == 39, '상점ID'] = 40 # test 데이터에서 상점ID 수정 test.loc[test['상점ID'] == 0, '상점ID'] = 57 test.loc[test['상점ID'] == 1, '상점ID'] = 58 test.loc[test['상점ID'] == 10, '상점ID'] = 11 test.loc[test['상점ID'] == 39, '상점ID'] = 40
-
-
shops 파생 feature 생성 및 인코딩
- 샹졈명의 첫 단어가 도시이기에 이를 활용해 도시 feature를 만든다. 상점명 feature를 공백 기준으로 나누고 첫번째 단어를 가져온다.
shops['도시'] = shops['상점명'].apply(lambda x: x.split()[0]) shops['도시'].unique()
-
첫 도시명 앞의 !는 제거해준다.
shops.loc[shops['도시'] =='!Якутск', '도시'] = 'Якутск' -
도시명은 범주형 feature이기에 레이블 인코딩을 해준다. 트리 기반 모델을 사용할 땐 레이블 인코딩을 사용해도 괜찮다.
from sklearn.preprocessing import LabelEncoder # 레이블 인코더 생성 label_encoder = LabelEncoder() # 도시 피처 레이블 인코딩 shops['도시'] = label_encoder.fit_transform(shops['도시']) -
상점명은 이제 필요없으므로 삭제 해준다.
# 상점명 피처 제거 shops = shops.drop('상점명', axis=1) shops.head()
-
items 파생 feature 생성
-
items도 상점과 마찬가지로 상품명을 제거해준다.
# 상품명 피처 제거 items = items.drop(['상품명'], axis=1) -
상품이 맨 처음 팔린 월을 feature로 만들어준다. sales_train을 상품 ID 기준으로 그룹화하고, 그룹에서 월ID의 최솟값을 구하면 해당 상품이 처음 팔린 달을 구할 수 있다.
# 상품이 맨 처음 팔린 날을 피처로 추가 items['첫 판매월'] = sales_train.groupby('상품ID').agg({'월ID': 'min'})['월ID'] items.head()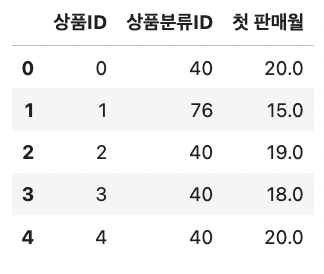
-
isna()로 결측값을 확인해 보면 결측값이 368개나 있는데, training data의 월ID는 33까지 있고 test data의 월ID가 34이기에 결측값을 34로 대체해주면 된다. 지금까지 한번도 팔리지 않았다면 첫 판매달이 월ID 34일 것 이기 때문이다.
# 첫 판매월 피처의 결측값을 34로 대체 items['첫 판매월'] = items['첫 판매월'].fillna(34)
-
-
item_categories 파생 feature 생성 및 인코딩
-
상품분류명의 첫 단어가 범주 대분류라는 점을 이용해 대분류 feature를 만든다. 더 큰 범주로 데이터를 묶으면 범주가 세밀할 때보다 성능 향상에 유리하다.
# 상품분류명의 첫 단어를 대분류로 추출 item_categories['대분류'] = item_categories['상품분류명'].apply(lambda x: x.split()[0])
-
대분류 하나가 범주를 일정 개수 이상 갖는게 성능 향상에 좋기에 고윳값이 5개 미만인 대분류는 모두 'etc'로 바꿔준다.
def make_etc(x): if len(item_categories[item_categories['대분류']==x]) >= 5: return x else: return 'etc' # 대분류의 고윳값 개수가 5개 미만이면 'etc'로 바꾸기 item_categories['대분류'] = item_categories['대분류'].apply(make_etc) item_categories.head()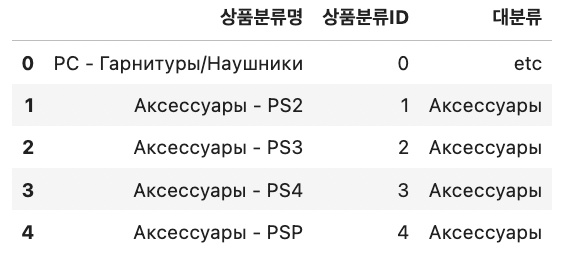
-
범주형 feature인 대분류를 인코딩하고, 상품분류명 feature는 더이상 필요없으니 제거한다.
# 레이블 인코더 생성 label_encoder = LabelEncoder() # 대분류 피처 레이블 인코딩 item_categories['대분류'] = label_encoder.fit_transform(item_categories['대분류']) # 상품분류명 피처 제거 item_categories = item_categories.drop('상품분류명', axis=1)
-
-
파생 feature 생성
-
월ID, 상점ID, 상품ID 별 '월간 판매량', '평균 판매가' feature를 만들고, '기준 feature별 상품 판매건수' feature를 만들어 준다.
group = sales_train.groupby(idx_features).agg({'판매량': 'sum', '판매가': 'mean'}) group = group.reset_index() group = group.rename(columns={'판매량': '월간 판매량', '판매가': '평균 판매가'}) train = train.merge(group, on=idx_features, how='left') train.head()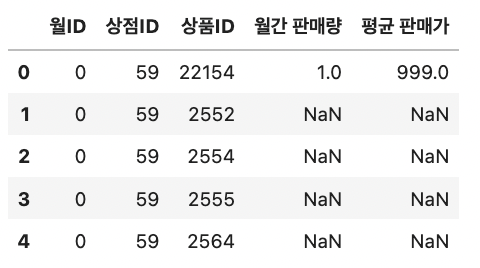
-
데이터 합치기
-
test data를 train에 이어붙인다.
# 테스트 데이터 월ID를 34로 설정 test['월ID'] = 34 # train과 test 이어붙이기 all_data = pd.concat([train, test.drop('ID', axis=1)], ignore_index=True, keys=idx_features) # 결측값을 0으로 대체 all_data = all_data.fillna(0) all_data.head()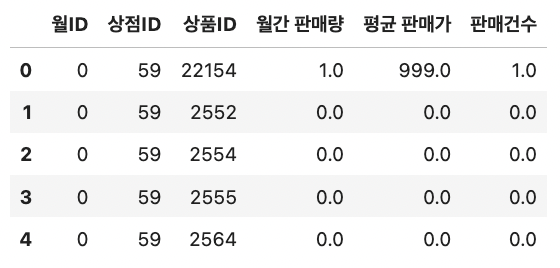
-
all_data에 shops, items, item_categories 데이터를 병합하고 데이터 다운캐스팅까지 실행해준다.
# 나머지 데이터 병합 all_data = all_data.merge(shops, on='상점ID', how='left') all_data = all_data.merge(items, on='상품ID', how='left') all_data = all_data.merge(item_categories, on='상품분류ID', how='left') # 데이터 다운캐스팅 all_data = downcast(all_data) -
shops, items, item_categories는 all_data에 병합했으니 garbage collection을 해준다.
# 가비지 컬렉션 del shops, items, item_categories gc.collect();
시차(time lag) feature 생성
-
시차 featre는 과거 시점에 관한 feature로, 시계열 문제에서 자주 사용된다. 타깃값과 관련된 "기준 feauture별 월간 평균 판매량" feature를 만들고 이를 활용해 시차 feature를 만들도록한다.
-
기준 feature별 월간 평균 판매량을 구해주는 함수를 만들어준다.
def add_mean_features(df, mean_features, idx_features): # 기준 피처 확인 assert (idx_features[0] == '월ID') and \ len(idx_features) in [2, 3] # 파생 피처명 설정 if len(idx_features) == 2: feature_name = idx_features[1] + '별 평균 판매량' else: feature_name = idx_features[1] + ' ' + idx_features[2] + '별 평균 판매량' # 기준 피처를 토대로 그룹화해 월간 평균 판매량 구하기 group = df.groupby(idx_features).agg({'월간 판매량': 'mean'}) group = group.reset_index() group = group.rename(columns={'월간 판매량': feature_name}) # df와 group 병합 df = df.merge(group, on=idx_features, how='left') # 데이터 다운캐스팅 df = downcast(df, verbose=False) # 새로 만든 feature_name 피처명을 mean_features 리스트에 추가 mean_features.append(feature_name) # 가비지 컬렉션 del group gc.collect() return df, mean_features- 함수에 전달되는 파라미터 df는 작업할 전체 데이터프레임, mean_features는 새로 만든 월간 평균 판매량 파생 피처명을 저장하는 리스트, idx_features는 기준 feature이다.
- '월간' 평균 판매량 파생 feature를 만드는 것이기에 기준 feature의 첫번째 요소는 '월ID'이다. 기존 feature가 많으면 지나치게 세분화되기에 기준 feature의 개수는 2개나 3개로 설정해준다.
-
만든 함수를 활용해 ['월ID', '상품ID']로 그룹화한 월간 평균 판매량과 ['월ID', '상품ID', '도시']로 그룹화한 월간 평균 판매량을 구하고 featue를 생성한다.
# 그룹화 기준 피처 중 '상품ID'가 포함된 파생 피처명을 담을 리스트 item_mean_features = [] # ['월ID', '상품ID']로 그룹화한 월간 평균 판매량 파생 피처 생성 all_data, item_mean_features = add_mean_features(df=all_data, mean_features=item_mean_features, idx_features=['월ID', '상품ID']) # ['월ID', '상품ID', '도시']로 그룹화한 월간 평균 판매량 파생 피처 생성 all_data, item_mean_features = add_mean_features(df=all_data, mean_features=item_mean_features, idx_features=['월ID', '상품ID', '도시']) item_mean_features
-
['월ID', '상점ID', '상품분류ID']를 기준 feature로 그룹화해 월간 평균 판매량을 구한 feature도 생성해준다.
# 그룹화 기준 피처 중 '상점ID'가 포함된 파생 피처명을 담을 리스트 shop_mean_features = [] # ['월ID', '상점ID', '상품분류ID']로 그룹화한 월간 평균 판매량 파생 피처 생성 all_data, shop_mean_features = add_mean_features(df=all_data, mean_features=shop_mean_features, idx_features=['월ID', '상점ID', '상품분류ID']) shop_mean_features -
시차 feature 생성 원리 및 함수 구현
-
df의 복사본을 만들고, 월ID를 1씩 더해서 시차 feature를 만들고 기존 df에 병합한다. 이러면 한 달 전 시차 feature가 만들어진다.
def add_lag_features(df, lag_features_to_clip, idx_features, lag_feature, nlags=3, clip=False): # 시차 피처 생성에 필요한 DataFrame 부분만 복사 df_temp = df[idx_features + [lag_feature]].copy() # 시차 피처 생성 for i in range(1, nlags+1): # 시차 피처명 lag_feature_name = lag_feature +'_시차' + str(i) # df_temp 열 이름 설정 df_temp.columns = idx_features + [lag_feature_name] # df_temp의 date_block_num 피처에 1 더하기 df_temp['월ID'] += 1 # idx_feature를 기준으로 df와 df_temp 병합하기 df = df.merge(df_temp.drop_duplicates(), on=idx_features, how='left') # 결측값 0으로 대체 df[lag_feature_name] = df[lag_feature_name].fillna(0) # 0 ~ 20 사이로 제한할 시차 피처명을 lag_features_to_clip에 추가 if clip: lag_features_to_clip.append(lag_feature_name) # 데이터 다운캐스팅 df = downcast(df, False) # 가비지 컬렉션 del df_temp gc.collect() return df, lag_features_to_clip- 이 함수를 이용해 시차 feature를 생성한다.
-
-
시차 feature 생성 1: 월간 판매량
-
월간 판매량은 타깃값이므로 0~20 사이로 제한해야 하니 clip=True를 전달해 세 달치 시차 feature를 lag_features_to_clip 리스트에 저장해둔다.
lag_features_to_clip = [] # 0 ~ 20 사이로 제한할 시차 피처명을 담을 리스트 idx_features = ['월ID', '상점ID', '상품ID'] # 기준 피처 # idx_features를 기준으로 월간 판매량의 세 달치 시차 피처 생성 all_data, lag_features_to_clip = add_lag_features(df=all_data, lag_features_to_clip=lag_features_to_clip, idx_features=idx_features, lag_feature='월간 판매량', nlags=3, clip=True) # 값을 0 ~ 20 사이로 제한- feature가 많으니 행과 열을 바꿔 출력하면, 다음과 같고, 새로 만든 세 feature의 이름은 lag_features_to_clip에 저장되어 있다.
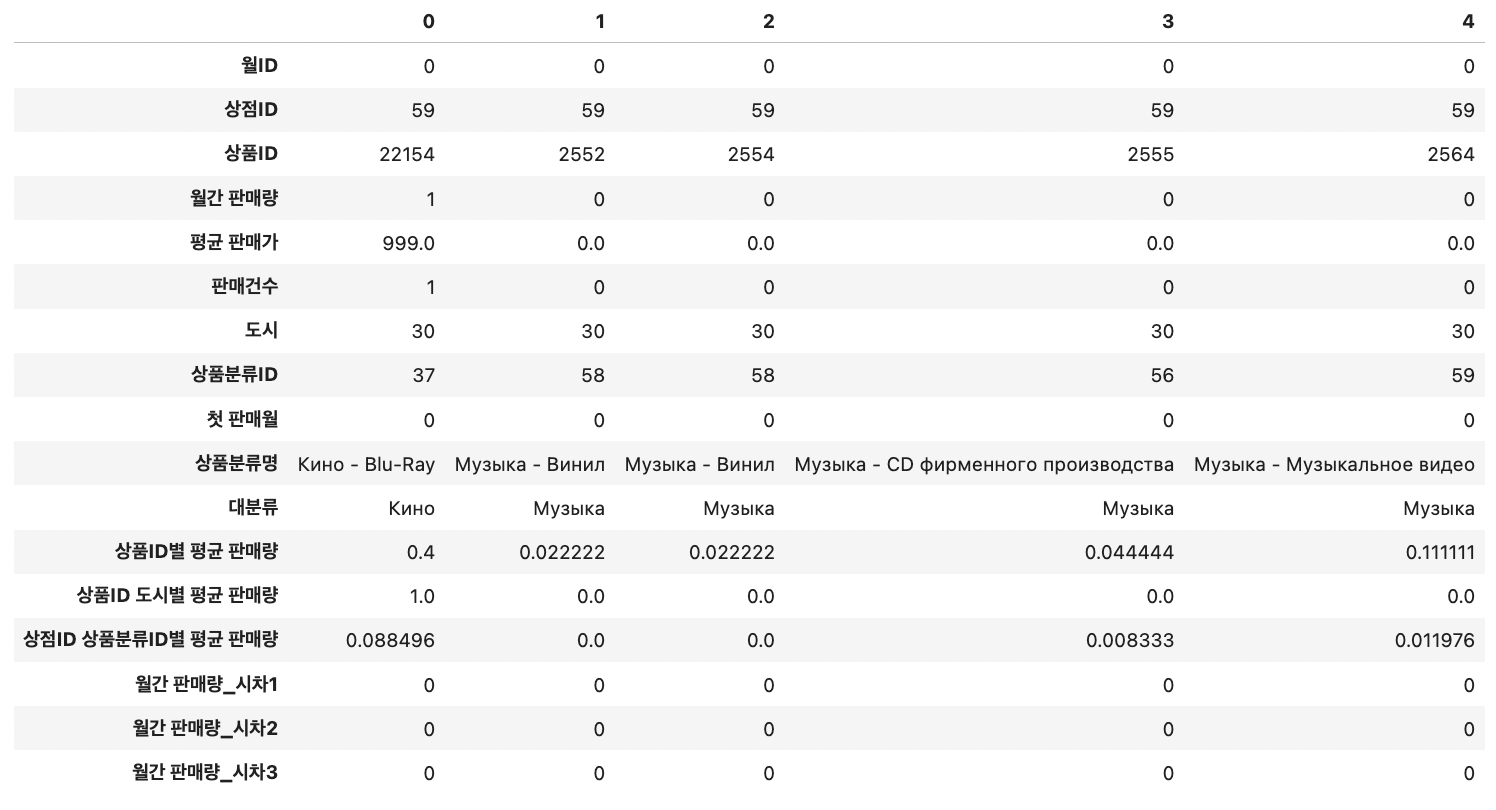

- feature가 많으니 행과 열을 바꿔 출력하면, 다음과 같고, 새로 만든 세 feature의 이름은 lag_features_to_clip에 저장되어 있다.
-
-
시차 feature 생성 2: 판매건수, 평균 판매가
-
타깃값이 아니므로 0~20사이로 제한할 필요 없으니 clip 파라미터는 생략한다.
# idx_features를 기준으로 판매건수 피처의 세 달치 시차 피처 생성 all_data, lag_features_to_clip = add_lag_features(df=all_data, lag_features_to_clip=lag_features_to_clip, idx_features=idx_features, lag_feature='판매건수', nlags=3) # idx_features를 기준으로 평균 판매가 피처의 세 달치 시차 피처 생성 all_data, lag_features_to_clip = add_lag_features(df=all_data, lag_features_to_clip=lag_features_to_clip, idx_features=idx_features, lag_feature='평균 판매가', nlags=3)
-
-
시차 feature 생성 3: 평균 판매량
- 앞서 '상품ID별 평균 판매량', '상품ID 도시별 평균 판매량' feature를 저장해둔 item_mean_features를 활용한다.
# idx_features를 기준으로 item_mean_features 요소별 시차 피처 생성 for item_mean_feature in item_mean_features: all_data, lag_features_to_clip = add_lag_features(df=all_data, lag_features_to_clip=lag_features_to_clip, idx_features=idx_features, lag_feature=item_mean_feature, nlags=3, clip=True) # item_mean_features 피처 제거 all_data = all_data.drop(item_mean_features, axis=1) - shop_mean_features에 저장된 '상점 상품분류ID별 평균 판매량' feature를 이용해 시차 feature를 생성해준다.
# ['월ID', '상점ID', '상품분류ID']를 기준으로 shop_mean_features 요소별 시차 피처 생성 for shop_mean_feature in shop_mean_features: all_data, lag_features_to_clip = add_lag_features(df=all_data, lag_features_to_clip=lag_features_to_clip, idx_features=['월ID', '상점ID', '상품분류ID'], lag_feature=shop_mean_feature, nlags=3, clip=True) # shop_mean_features 피처 제거 all_data = all_data.drop(shop_mean_features, axis=1)
- 앞서 '상품ID별 평균 판매량', '상품ID 도시별 평균 판매량' feature를 저장해둔 item_mean_features를 활용한다.
-
시차 feature 생성 마무리: 결측값 처리
- 세 달치 시차 feature를 만들면 월ID 3 미만에서 결측값이 생길 수 밖에 없으니 제거해준다.
# 월ID 3미만인 데이터 제거 all_data = all_data.drop(all_data[all_data['월ID'] < 3].index)
- 세 달치 시차 feature를 만들면 월ID 3 미만에서 결측값이 생길 수 밖에 없으니 제거해준다.
기타 feature engineering
-
기타 feature 추가
-
월간 판매량 시차 feature들의 평균
all_data['월간 판매량 시차평균'] = all_data[['월간 판매량_시차1', '월간 판매량_시차2', '월간 판매량_시차3']].mean(axis=1)- 판매량과 관련된 feature이므로 0~20 사이로 값을 조정해야 한다.
# 0 ~ 20 사이로 값 제한 all_data[lag_features_to_clip + ['월간 판매량', '월간 판매량 시차평균']] = all_data[lag_features_to_clip + ['월간 판매량', '월간 판매량 시차평균']].clip(0, 20)
- 판매량과 관련된 feature이므로 0~20 사이로 값을 조정해야 한다.
-
시차 변화량
all_data['시차변화량1'] = all_data['월간 판매량_시차1']/all_data['월간 판매량_시차2'] all_data['시차변화량1'] = all_data['시차변화량1'].replace([np.inf, -np.inf], np.nan).fillna(0) all_data['시차변화량2'] = all_data['월간 판매량_시차2']/all_data['월간 판매량_시차3'] all_data['시차변화량2'] = all_data['시차변화량2'].replace([np.inf, -np.inf], np.nan).fillna(0) -
신상 여부
all_data['신상여부'] = all_data['첫 판매월'] == all_data['월ID']- 신상품인지 여부를 나타내는 feature를 추가해준다. 첫 판매월과 월ID가 같으면 신상품인것이다.
-
첫 판매 후 경과 기간
all_data['첫 판매 후 기간'] = all_data['월ID'] - all_data['첫 판매월']- 현재 월에서 첫 판매월을 빼 얼마나 기간이 지났는지 알 수 있다.
-
월
all_data['월'] = all_data['월ID'] % 12- 월ID feature를 12로 나눈 나머지가 월과 같다.
-
-
필요 없는 feature 제거
# 첫 판매월, 평균 판매가, 판매건수 피처 제거 all_data = all_data.drop(['첫 판매월', '평균 판매가', '판매건수'], axis=1) all_data = downcast(all_data, False) # 데이터 다운캐스팅- 다른 파생 feature를 만드는데 사용된 '첫 판매월' feature와 test data 값이 모두 0인 '평균 판매가', '판매건수' feature는 제거해주도록 한다.
-
info()로 데이터 feature 살펴보기

- 31개의 열이 있음을 알 수 있는데, 30개의 feature와 타깃값 '월간 판매량'으로 구성되어 있다.
-
training, valid, test data로 나누어주기
# 훈련 데이터 (피처) X_train = all_data[all_data['월ID'] < 33] X_train = X_train.drop(['월간 판매량'], axis=1) # 검증 데이터 (피처) X_valid = all_data[all_data['월ID'] == 33] X_valid = X_valid.drop(['월간 판매량'], axis=1) # 테스트 데이터 (피처) X_test = all_data[all_data['월ID'] == 34] X_test = X_test.drop(['월간 판매량'], axis=1) # 훈련 데이터 (타깃값) y_train = all_data[all_data['월ID'] < 33]['월간 판매량'] # 검증 데이터 (타깃값) y_valid = all_data[all_data['월ID'] == 33]['월간 판매량'] # 가비지 컬렉션 del all_data gc.collect();
모델 훈련 및 성능 검증
-
Baseline model과 대부분 같고, 하이퍼파라미터만 일부 다르다. early stopping 조건은 150 설정하고, 범주형 데이터에 도시, 대분류, 월이 추가 되었다.
import lightgbm as lgb # LightGBM 하이퍼파라미터 params = {'metric': 'rmse', 'num_leaves': 255, 'learning_rate': 0.005, 'feature_fraction': 0.75, 'bagging_fraction': 0.75, 'bagging_freq': 5, 'force_col_wise': True, 'random_state': 10} cat_features = ['상점ID', '도시', '상품분류ID', '대분류', '월'] # LightGBM 훈련 및 검증 데이터셋 dtrain = lgb.Dataset(X_train, y_train) dvalid = lgb.Dataset(X_valid, y_valid) # LightGBM 모델 훈련 lgb_model = lgb.train(params=params, train_set=dtrain, num_boost_round=1500, valid_sets=(dtrain, dvalid), early_stopping_rounds=150, categorical_feature=cat_features, verbose_eval=100)
최종
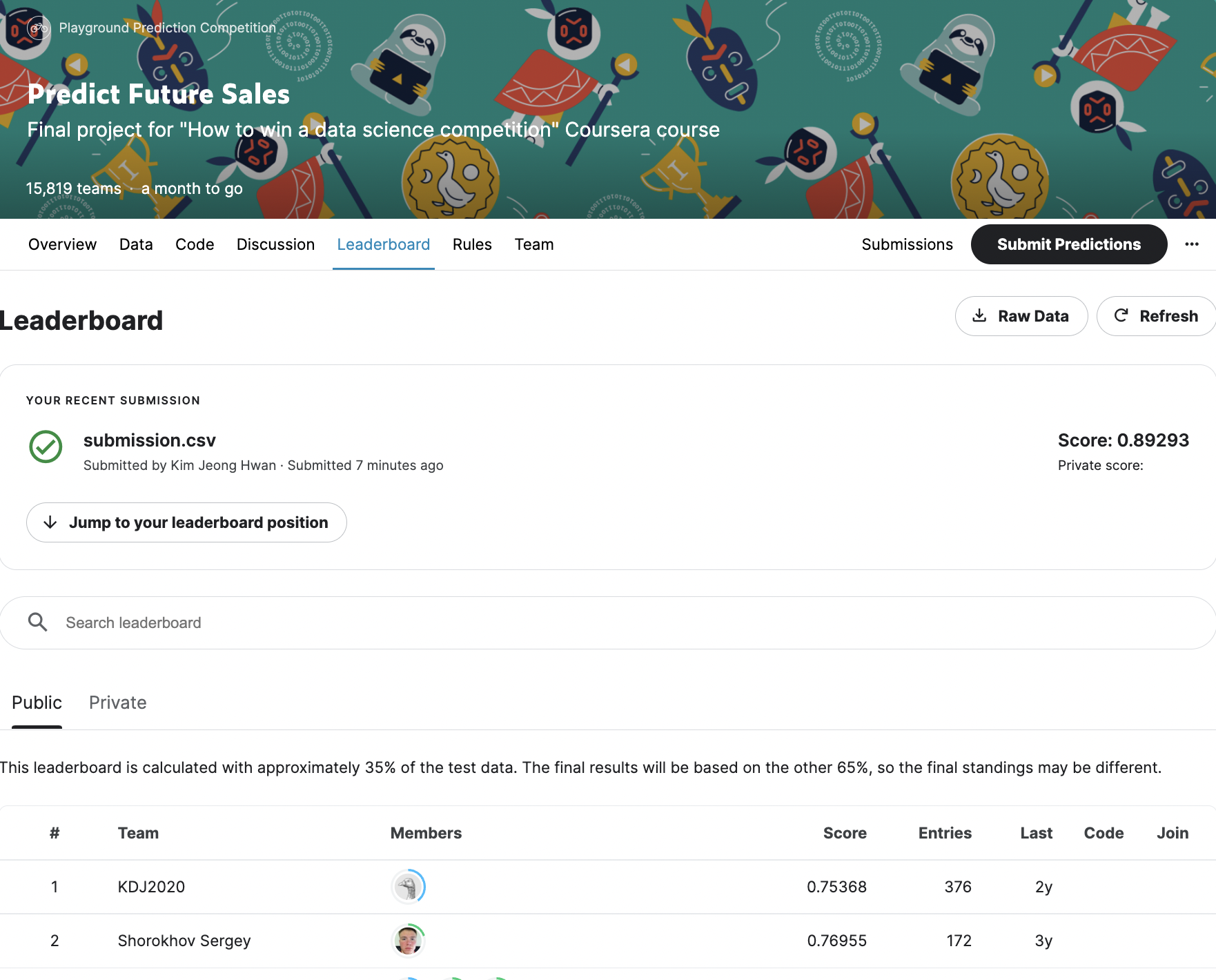
-
publis score 0.89293으로 총 15822명 중 2368등 정도의 점수를 기록했다 (2022.11.29기준). 상위 15% 수준이다.
-
github에 해당 코드를 올려두었다.
참고: 머신러닝·딥러닝 문제해결 전략 (캐글 수상작 리팩터링으로 배우는 문제해결 프로세스와 전략)
참고: http://kaggle.com/dimitreoliveira/model-stacking-feature-engineering-and-eda,
https://www.kaggle.com/code/dkomyagin/predict-future-sales-lightgbm-framework/notebook
