Intro
캐글의 플레이그라운드 대회 'Categorical Feature Encoding Challenge' compeition에 참가해 이진 분류 문제를 해결해보았다.
이 경진대회는 인위적으로 만든 데이터로 구성되어 있으며 각 feature와 타깃값의 의미를 알 수 없다는 특징을 가지고 있다. 또한 모든 데이터가 범주형이며, bin_으로 시작하면 이진 feature, nom_으로 시작하면 명목형 feature, ord_로 시작하면 순서형 feature이다. 타깃값도 범주형 데이터이며 0과 1 두개로 구성되어 있기에 이진분류 문제로 볼 수 있다.
EDA
데이터 둘러보기
import pandas as pd
# 데이터 경로
data_path = '/kaggle/input/cat-in-the-dat/'
train = pd.read_csv(data_path + 'train.csv', index_col='id')
test = pd.read_csv(data_path + 'test.csv', index_col='id')
submission = pd.read_csv(data_path + 'sample_submission.csv', index_col='id')-
index_col은 불러올 DataFrame의 인덱스를 지정하는 파라미터로, 열 이름을 전달하면 해당 열을 인덱스로 지정한다.
-
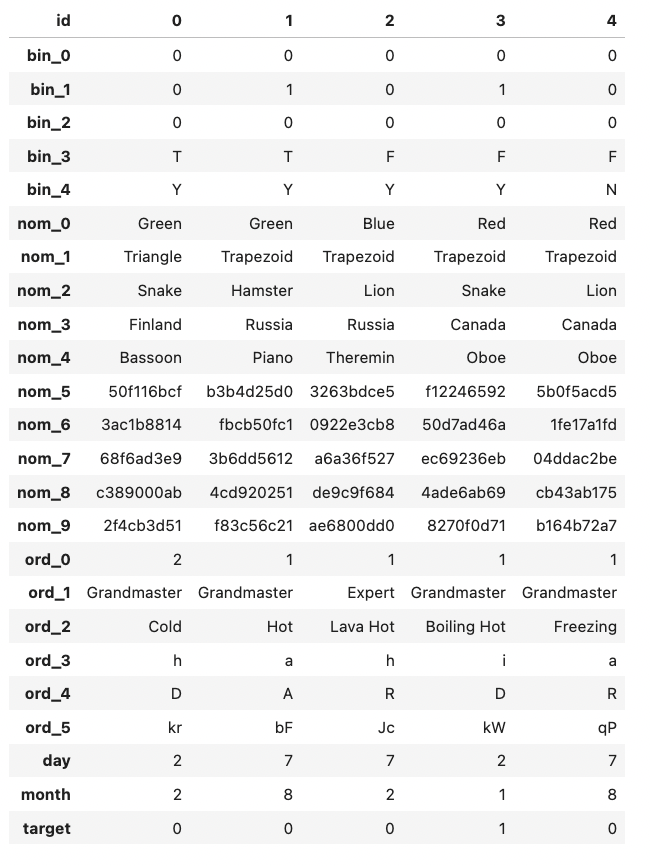
training data가 어떻게 이루어져 있는지 살펴보기 위해 보통 train.head()를 사용하는데 이는 feature의 개수가 많을 경우 생략되어 출력되므로 train.head().T 로 행과 열의 위치를 바꿔서 볼 수 있다.
-
feature 요약표를 만들어 각 feature의 데이터 타입이 무엇인지, 결측값, 고유값의 개수 등을 살펴볼 수 있다.
def resumetable(df): print(f'데이터 세트 형상: {df.shape}') summary = pd.DataFrame(df.dtypes, columns=['데이터 타입']) summary = summary.reset_index() summary = summary.rename(columns={'index': '피처'}) summary['결측값 개수'] = df.isnull().sum().values summary['고윳값 개수'] = df.nunique().values summary['첫 번째 값'] = df.loc[0].values summary['두 번째 값'] = df.loc[1].values summary['세 번째 값'] = df.loc[2].values return summary resumetable(train)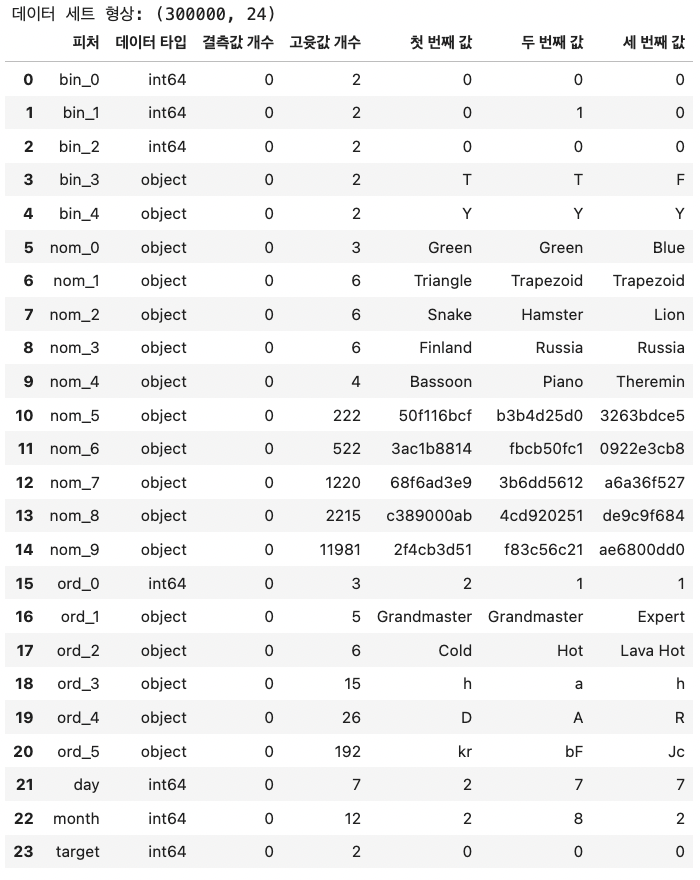
-
이진 feature: bin_0 ~ bin_4
- 이진 feature 이므로 고윳값이 모두 2개이고, bin 0, 1, 2는 실젯값이 0 또는 1으로 int64 타입인 반면 bin 3, 4는 T 또는 F, Y 또는 N으로 되어있는 object 타입이다. 나중에 모델링 할 때 T와 Y는 1, F와 N은 0으로 인코딩해준다.
-
명목형 feature: nom_0 ~ nom_9
- nom0 ~ nom4는 고윳값이 6개인 반면 nom5 ~ nom9는 고윳값이 많고 의미를 알 수 없는 값들이 입력되어있다.
-
순서형 featue: ord_0 ~ ord_5
- 순서형 feature는 순서가 중요하므로 유의하여 인코딩하도록 한다. ord_0 feature만 int64 타입이고, 나머지는 object 타입이다. 각 데이터의 순서를 파악하기 위해 unique()함수를 이용해 고윳값을 출력해본다.
for i in range(6): feature = 'ord_' + str(i) print(f'{feature} 고윳값: {train[feature].unique()}')
- ord_0의 고윳값은 모두 숫자이므로 숫자 크기에 순서를 맞춰주고, ord_1은 캐글 등급이므로 등급 단계에 따라 맞춰주고, ord_2는 차가운 순서부터 뜨거운 순서까지 맞춰주고, ord_3, 4, 5는 알파벳순으로 해주어 인코딩할 때 순서에 맞게 매핑할 수 있도록 해준다.
-> 순서형 feature는 고윳값들의 순서에 맞게 인코딩해준다.
-
-
마지막으로 일, 월, 타깃값 요약표 또한 살펴보도록 한다.
print('day 고윳값:', train['day'].unique()) print('month 고윳값:', train['month'].unique()) print('target 고윳값:', train['target'].unique())
데이터 시각화
타깃값 분포
-
카운트플롯으로 타깃값 분포를 살펴보아 데이터가 얼마나 불균형한지 파악한다. (수치형 데이터의 분포를 파악할 땐 주로 displot(), 범주형 데이터의 분포를 파악할 땐 countplot()을 사용한다.)
mpl.rc('font', size=15) # 폰트 크기 설정 plt.figure(figsize=(7, 6)) # Figure 크기 설정 # 타깃값 분포 카운트플롯 ax = sns.countplot(x='target', data=train) ax.set(title='Target Distribution');- x 파라미터에 타깃값 'target', data 파라미터에 train 을 전달하여 train['target']에서 고윳값별로 데이터가 몇 개인지 그려주었다.
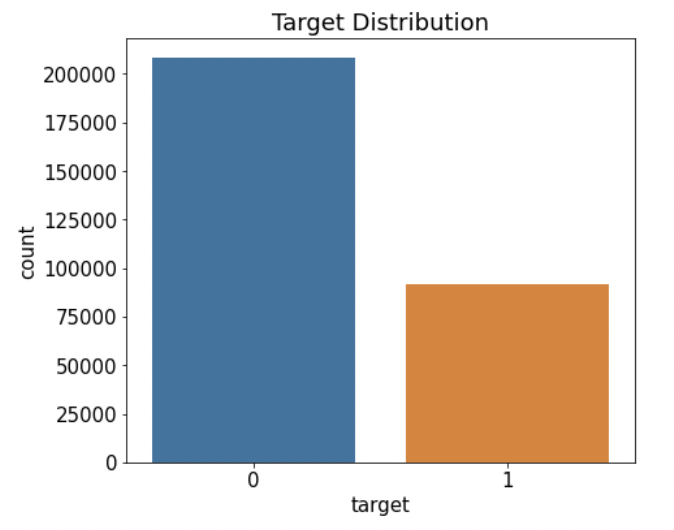
- 각 값의 비율을 그래프 상단에 표시해주기 위해 글자를 쓸 위치를 ax.patches를 통해 알아본다.
rectangle = ax.patches[0] # 첫 번째 Rectangle 객체 print('사각형 높이:', rectangle.get_height()) print('사각형 너비:', rectangle.get_width()) print('사각형 왼쪽 테두리의 x축 위치:', rectangle.get_x())
- 그래프의 높이 및 너비를 알았기에 이제 텍스트 위치를 넣어볼 좌표를 구해본다.
print('텍스트 위치의 x좌표:', rectangle.get_x() + rectangle.get_width()/2.0) print('텍스트 위치의 y좌표:', rectangle.get_height() + len(train)*0.001)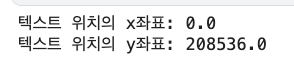
- 이제 비율을 표시해주는 코드를 함수로 구현하고, 카운트플롯을 다시 그려준다.
def write_percent(ax, total_size): '''도형 객체를 순회하며 막대 상단에 타깃값 비율 표시''' for patch in ax.patches: height = patch.get_height() # 도형 높이(데이터 개수) width = patch.get_width() # 도형 너비 left_coord = patch.get_x() # 도형 왼쪽 테두리의 x축 위치 percent = height/total_size*100 # 타깃값 비율 # (x, y) 좌표에 텍스트 입력 ax.text(x=left_coord + width/2.0, # x축 위치 y=height + total_size*0.001, # y축 위치 s=f'{percent:1.1f}%', # 입력 텍스트 ha='center') # 가운데 정렬 plt.figure(figsize=(7, 6)) ax = sns.countplot(x='target', data=train) write_percent(ax, len(train)) # 비율 표시 ax.set_title('Target Distribution');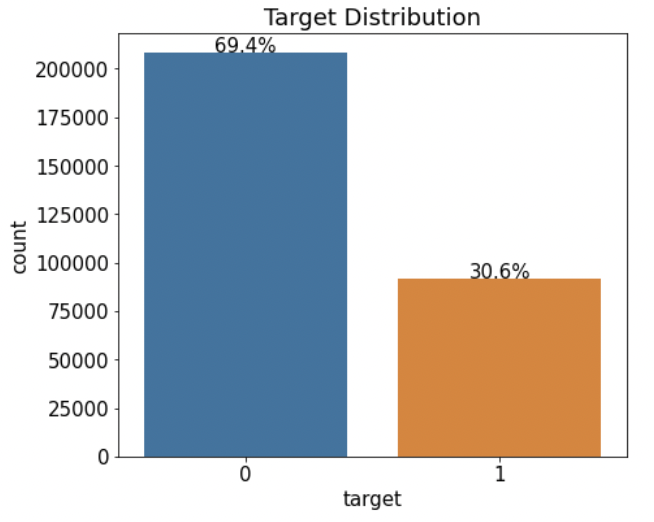
- s 파라미터에는 입력하려는 텍스트를 전달하고, ha는 텍스트를 수평 정렬 하는 파라미터이다.
- x 파라미터에 타깃값 'target', data 파라미터에 train 을 전달하여 train['target']에서 고윳값별로 데이터가 몇 개인지 그려주었다.
이진 feature 분포
-
이진 feature의 분포를 타깃값 별로 따로 그려본다. 범주형 feature의 타깃값 분포를 고윳값별로 구분해 그려보는 것은 특정 고윳값이 특정 타깃값에 치우치는지 확인할 수 있는 방법이다.
import matplotlib.gridspec as gridspec # 여러 그래프를 격자 형태로 배치 # 3행 2열 틀(Figure) 준비 mpl.rc('font', size=12) grid = gridspec.GridSpec(3, 2) # 그래프(서브플롯)를 3행 2열로 배치 plt.figure(figsize=(10, 16)) # 전체 Figure 크기 설정 plt.subplots_adjust(wspace=0.4, hspace=0.3) # 서브플롯 간 좌우/상하 여백 설정 # 서브플롯 그리기 bin_features = ['bin_0', 'bin_1', 'bin_2', 'bin_3', 'bin_4'] # 피처 목록 for idx, feature in enumerate(bin_features): ax = plt.subplot(grid[idx]) # ax축에 타깃값 분포 카운트플롯 그리기 sns.countplot(x=feature, data=train, hue='target', palette='pastel', # 그래프 색상 설정 ax=ax) ax.set_title(f'{feature} Distribution by Target') # 그래프 제목 설정 write_percent(ax, len(train)) # 비율 표시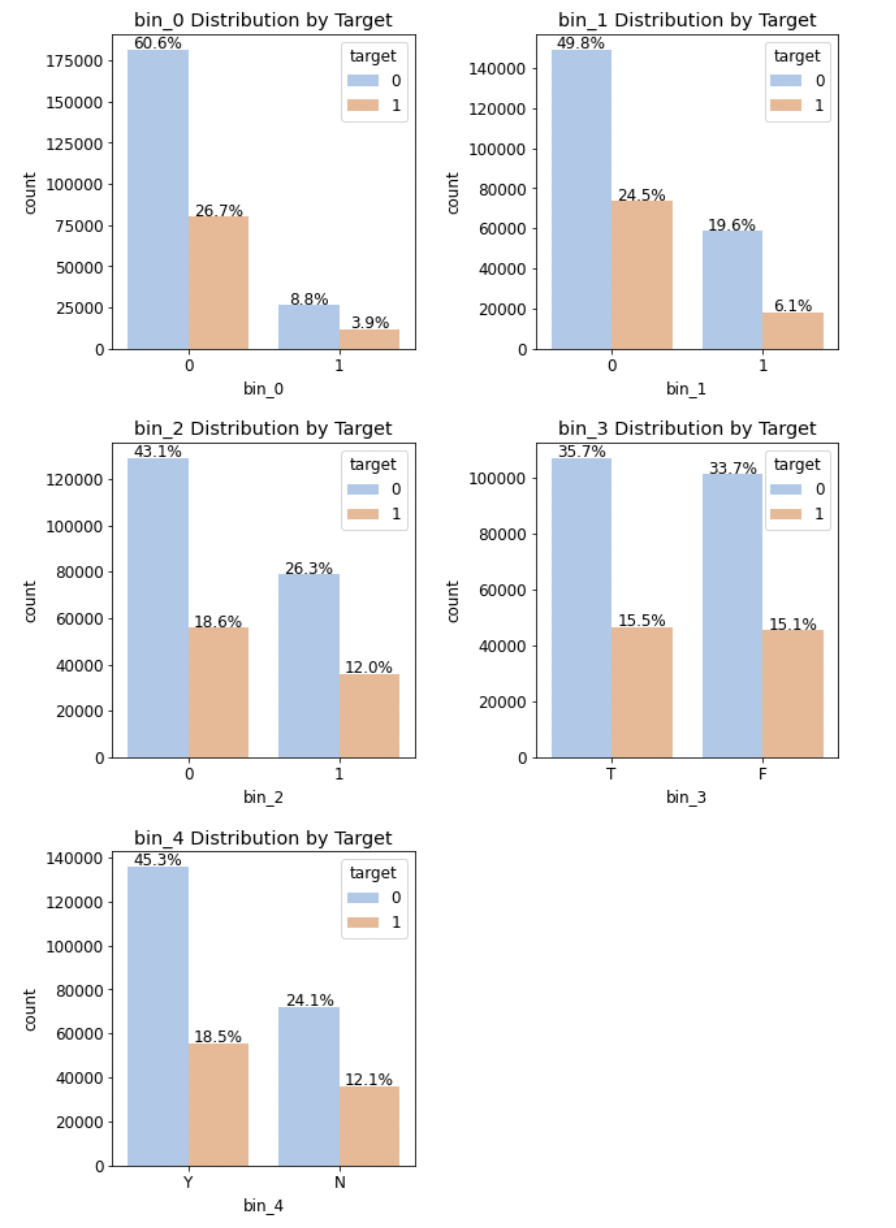
- 고윳값별로 나누어보아도 타깃값의 분포가 대부분 7:3 수준이기에 특정 타깃값에 치우치지 않았음을 확인할 수 있다.
명목형 feature 분포
- 이번엔 명목형 feature와 명목형 feature별 타깃값 1의 비율을 살펴보도록 한다. nom_5 ~ nom_9는 의미를 알 수 없었으므로 nom_0~ nom_4만 우선 살펴본다. 3 가지 step으로 진행된다.
- 교차분석표 생성 함수 만들기
-
교차 분석표는 범주형 데이터 2개를 비교 분석하는데 사용되는 표로, 각 범주형 데이터의 빈도나 통계량을 행과 열로 결합해놓은 표이다. 명목형 feature별 타깃값 1의 비율을 구하기 위해 crosstab()함수로 만든다.
pd.crosstab(train['nom_0'], train['target'])
-
고윳값별 타깃값 0과 1이 몇개인지를 나타내주는데, 비율로 표현하려면 normalize 파라미터를 추가해 정규화해준다. normalize 파라미터에 'index'를 전달하면 인덱스를 기준으로 정규화한다.
# 정규화 후 비율을 백분율로 표현 crosstab = pd.crosstab(train['nom_0'], train['target'], normalize='index')*100 crosstab
-
인덱스가 feature 이름(nom_0)으로 되어있으니 인덱스를 재설정해준다.
crosstab = crosstab.reset_index() # 인덱스 재설정 crosstab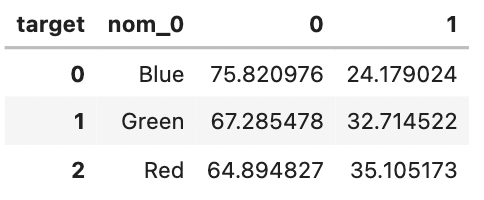
-
위의 교차분석표를 함수로 만들어둔다.
def get_crosstab(df, feature): crosstab = pd.crosstab(df[feature], df['target'], normalize='index')*100 crosstab = crosstab.reset_index() return crosstab- 데이터프레임과 feature이름을 인수로 전달해 사용한다.
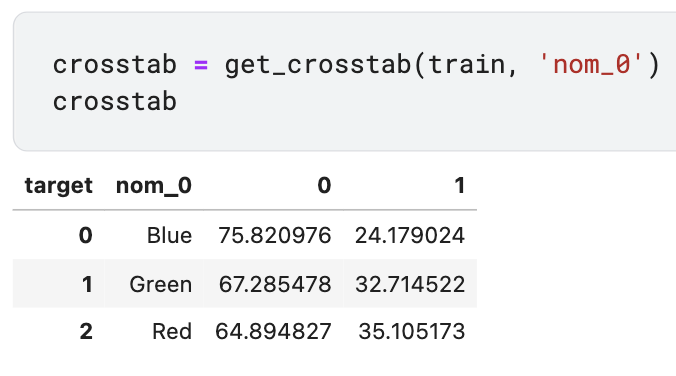
- 타깃값 1 비율만 가져오려면 해당하는 열의 이름을 인수로 전달한다. 다음 step에서 포인트플롯을 그릴 때 사용할 데이터이다.
crosstab[1]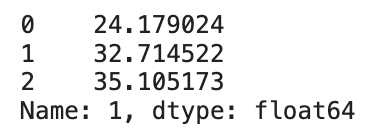
- 데이터프레임과 feature이름을 인수로 전달해 사용한다.
- 포인트플롯 생성 함수 만들기
- plot_pointplot()은 이미 카운트플롯이 그려진 축에 포인트플롯을 중복으로 그려준다.
def plot_pointplot(ax, feature, crosstab): ax2 = ax.twinx() # x축은 공유하고 y축은 공유하지 않는 새로운 축 생성 # 새로운 축에 포인트플롯 그리기 ax2 = sns.pointplot(x=feature, y=1, data=crosstab, order=crosstab[feature].values, # 포인트플롯 순서 color='black', # 포인트플롯 색상 legend=False) # 범례 미표시 ax2.set_ylim(crosstab[1].min()-5, crosstab[1].max()*1.1) # y축 범위 설정 ax2.set_ylabel('Target 1 Ratio(%)')- 축 하나에 서로 다른 그래프를 그리려면 x축을 공유해야 하기에 ax.twinx()로 x축은 공유하지만 y축은 공유하지 않는 새로운 축 x2를 만든다.
- feature 분포도 및 feature별 타깃값 1의 비율 포인트플롯 생성 함수 만들기
-
get_crosstab()과 plot_pointplot() 함수를 활용해 최종적인 그래프를 그린다.
def plot_cat_dist_with_true_ratio(df, features, num_rows, num_cols, size=(15, 20)): plt.figure(figsize=size) # 전체 Figure 크기 설정 grid = gridspec.GridSpec(num_rows, num_cols) # 서브플롯 배치 plt.subplots_adjust(wspace=0.45, hspace=0.3) # 서브플롯 좌우/상하 여백 설정 for idx, feature in enumerate(features): ax = plt.subplot(grid[idx]) crosstab = get_crosstab(df, feature) # 교차분석표 생성 # ax축에 타깃값 분포 카운트플롯 그리기 sns.countplot(x=feature, data=df, order=crosstab[feature].values, color='skyblue', ax=ax) write_percent(ax, len(df)) # 비율 표시 plot_pointplot(ax, feature, crosstab) # 포인트플롯 그리기 ax.set_title(f'{feature} Distribution') # 그래프 제목 설정nom_features = ['nom_0', 'nom_1', 'nom_2', 'nom_3', 'nom_4'] # 명목형 피처 plot_cat_dist_with_true_ratio(train, nom_features, num_rows=3, num_cols=2)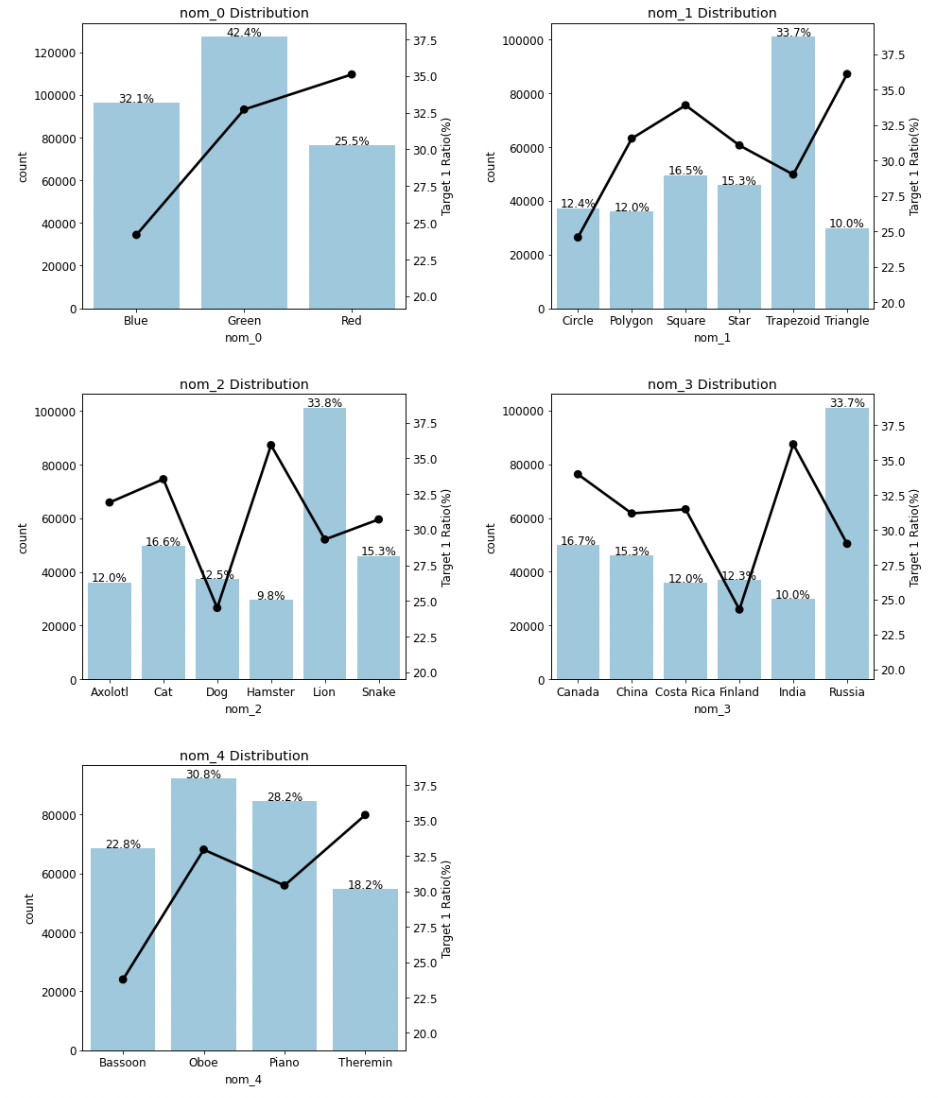
- 명목형 featrue는 순서를 무시해도 되므로 모두 원-핫 인코딩해주도록 한다.
순서형 feature 분포
- 순서형 feature는 ord_0 ~ ord_3과 ord_4 ~ ord_5의 고윳값 개수가 많이 다르기에 따로 그래프를 그려준다.
- 먼저 ord_0 ~ ord_3 feature의 분포를 그려볼텐데, ord_1과 ord_2의 feature 값들의 순서를 CatregoricalDtype()을 이용해 지정해준다. categories 파라미터에 범주형 데이터 타입으로 인코딩할 값 목록을 전달하고, ordered 파라미터를 Ture로 설정하면 categories에 전달한 값의 순서가 유지된다.
from pandas.api.types import CategoricalDtype
ord_1_value = ['Novice', 'Contributor', 'Expert', 'Master', 'Grandmaster']
ord_2_value = ['Freezing', 'Cold', 'Warm', 'Hot', 'Boiling Hot', 'Lava Hot']
# 순서를 지정한 범주형 데이터 타입
ord_1_dtype = CategoricalDtype(categories=ord_1_value, ordered=True)
ord_2_dtype = CategoricalDtype(categories=ord_2_value, ordered=True)
# 데이터 타입 변경
train['ord_1'] = train['ord_1'].astype(ord_1_dtype)
train['ord_2'] = train['ord_2'].astype(ord_2_dtype)plot_cat_dist_with_true_ratio(train, ord_features,
num_rows=2, num_cols=2, size=(15, 12))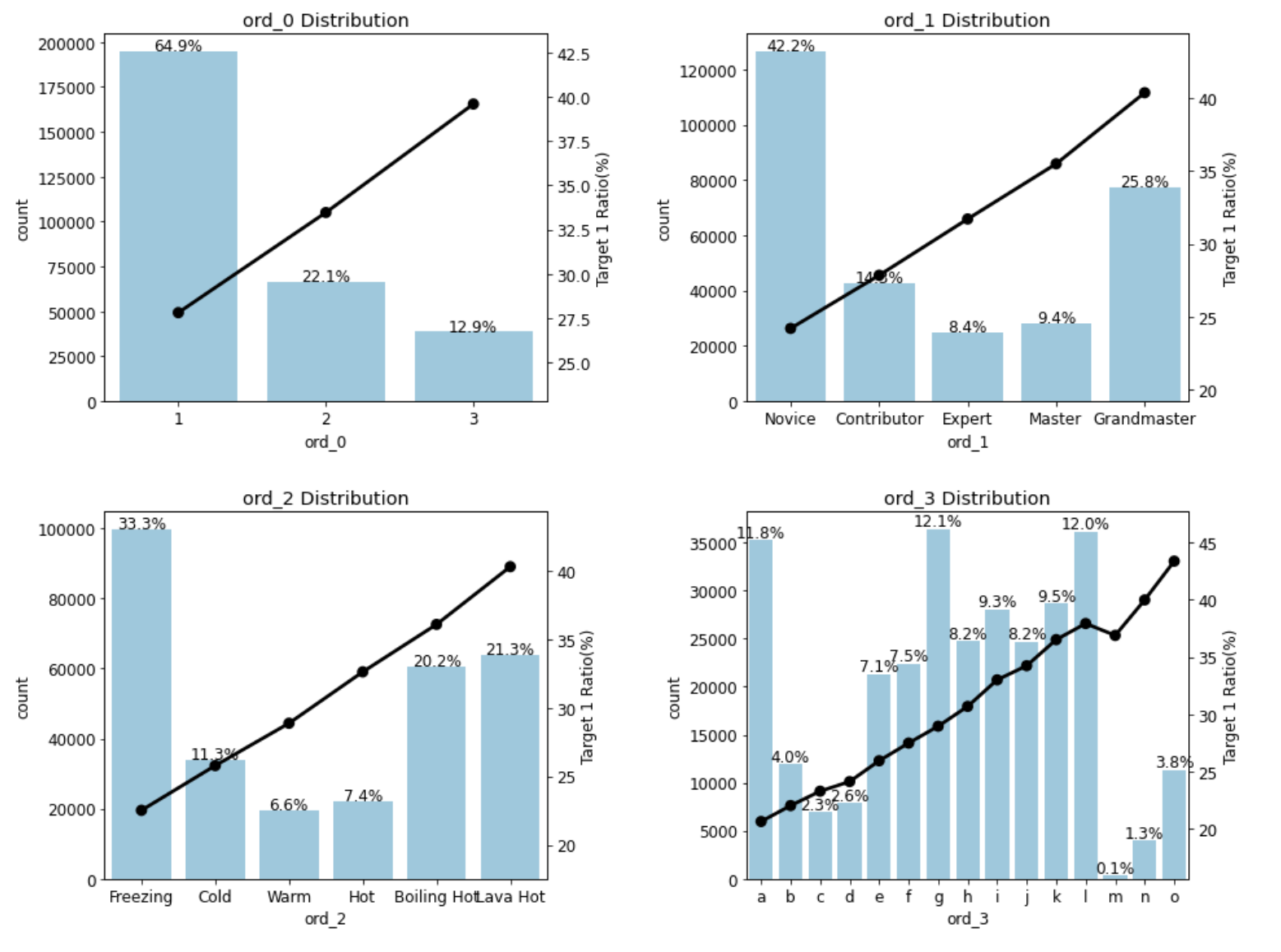
-
고윳값 순서에 따라 타깃값 1의 비율이 커진다는 것을 알 수 있다.
-
ord_4와 ord_5 또한 그래프를 그려보는데, 고윳값 개수가 많기에 가로 길이를 늘려 2행 1열로 그려준다.
plot_cat_dist_with_true_ratio(train, ['ord_4', 'ord_5'],
num_rows=2, num_cols=1, size=(15, 12))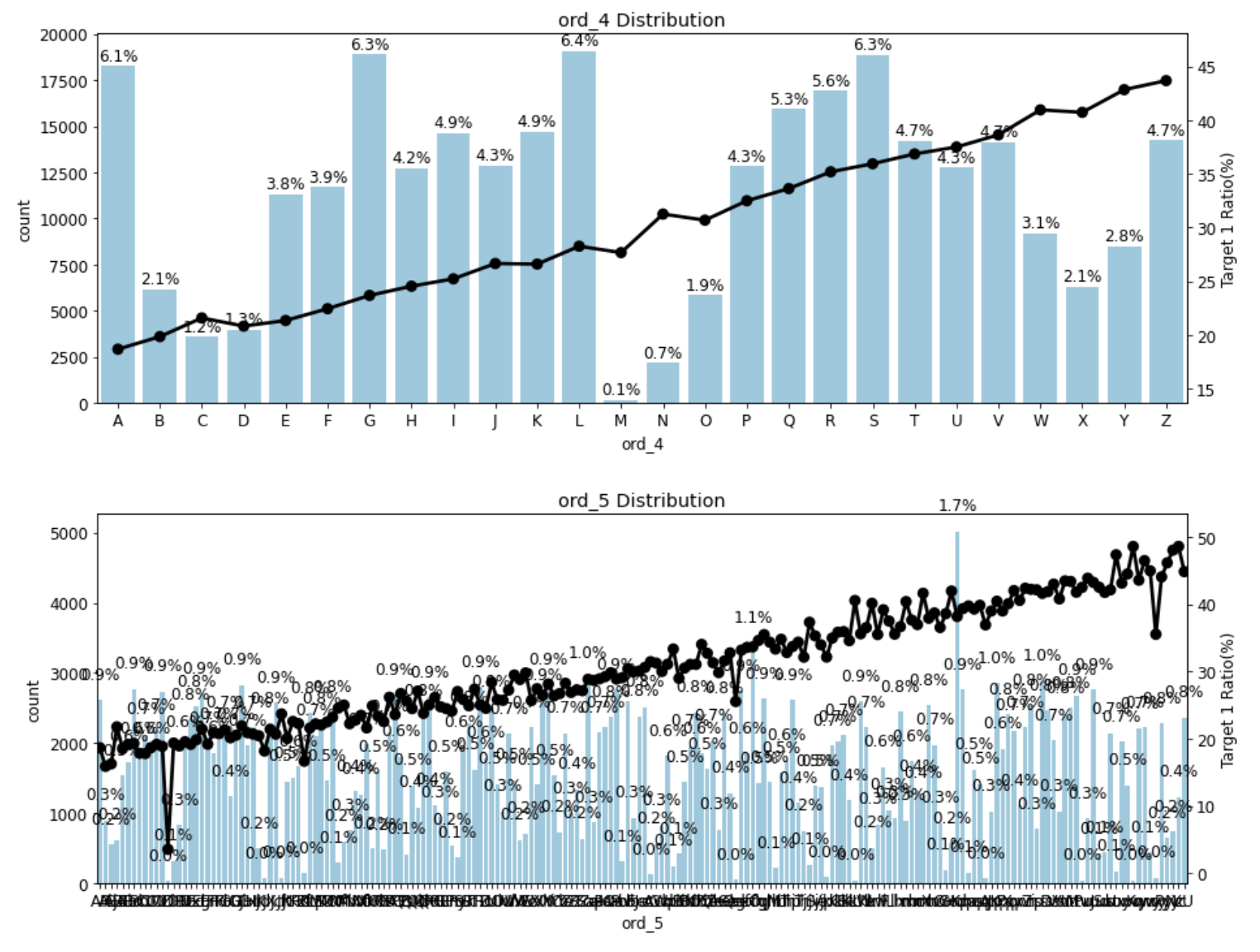
- ord_4와 ord_5 또한 마찬가지로 고윳값 순서에 따라 타깃값 1의 비율이 증가하는 것으로 보아 순서형 feature 모두 고윳값 순서에 따라 타깃값 1의 비율이 증가한다고 볼 수 있다.
날짜형(요일, 월) feature 분포
date_features = ['day', 'month']
plot_cat_dist_with_true_ratio(train, date_features,
num_rows=2, num_cols=1, size=(10, 10))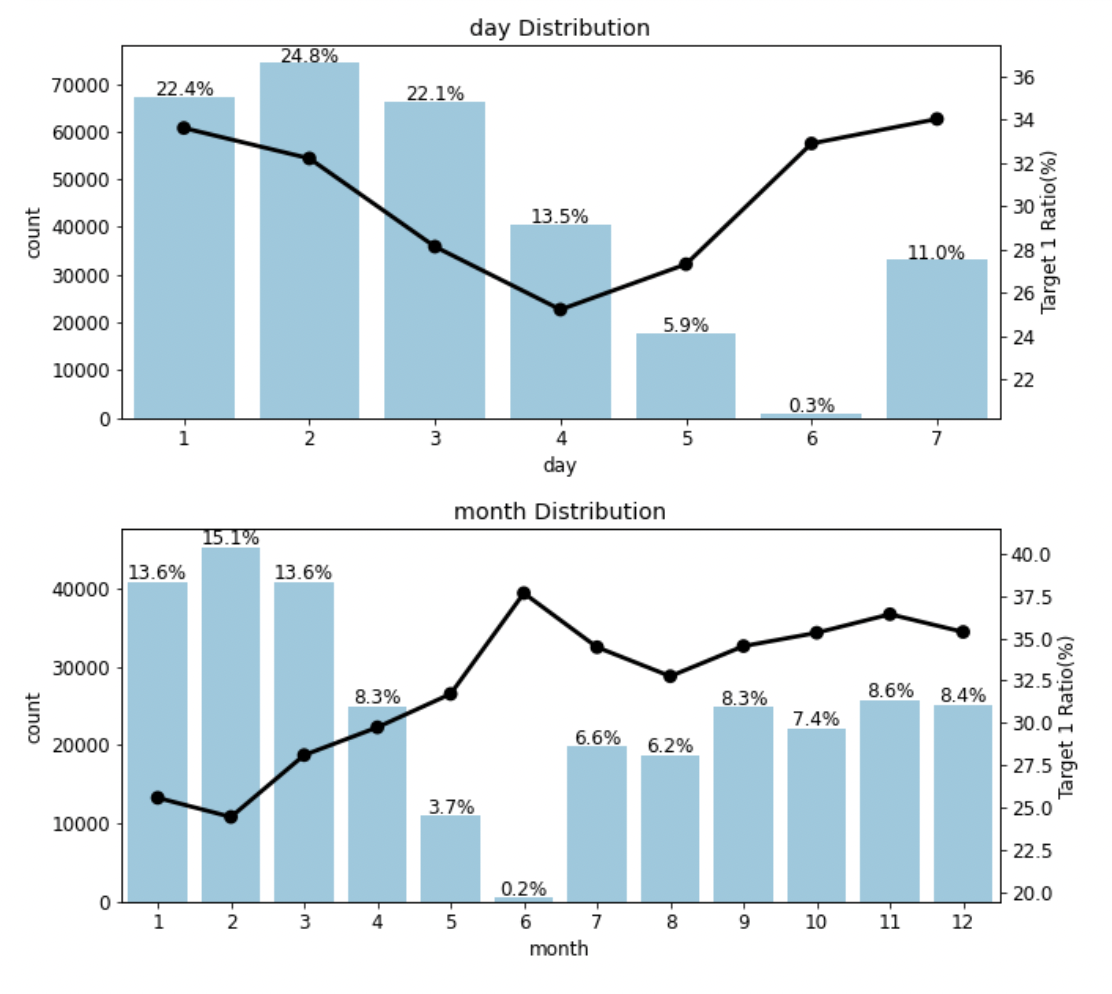
- 월의 경우 12월과 1월의 차이는 한 달임에도 숫자상으로는 11이라는 큰 차이가 있어 보이기에 원-핫 인코딩을 해준다.
Baseline Model
import pandas as pd
# 데이터 경로
data_path = '/kaggle/input/cat-in-the-dat/'
train = pd.read_csv(data_path + 'train.csv', index_col='id')
test = pd.read_csv(data_path + 'test.csv', index_col='id')
submission = pd.read_csv(data_path + 'sample_submission.csv', index_col='id')Feature Engineering
데이터 합치기
- 머신러닝 모델은 문자 데이터를 인식하지 못하기에 문자를 숫자로 바꿔주는 인코딩을 진행해야 한다. Training data와 Test data에 동일한 인코딩을 적용하기 위해 둘을 합쳐주고, 타깃값을 제거해 준다. (feature와 타깃값은 따로 분리해서 모델링해야 하기 때문)
all_data = pd.concat([train, test]) # 훈련 데이터와 테스트 데이터 합치기
all_data = all_data.drop('target', axis=1) # 타깃값 제거
all_data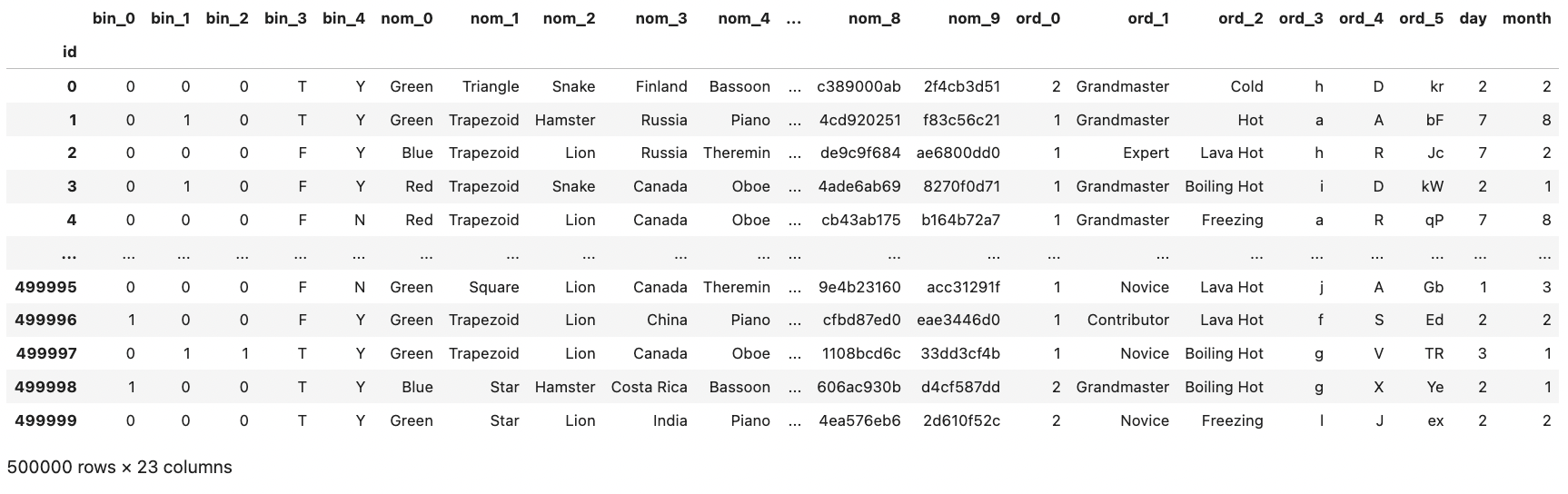
원-핫 인코딩
-
원-핫 인코더 객체를 생성하고 all_data의 모든 feature를 인코딩해 새롭게 저장해준다.
from sklearn.preprocessing import OneHotEncoder encoder = OneHotEncoder() # 원-핫 인코더 생성 all_data_encoded = encoder.fit_transform(all_data) # 원-핫 인코딩 적용
데이터 나누기
-
인코딩을 공통으로 적용해주었으므로 다시 training data와 test data를 나눠준다. 추가로 타깃값을 y 변수에 저장해둔다.
num_train = len(train) # 훈련 데이터 개수 # 훈련 데이터와 테스트 데이터 나누기 X_train = all_data_encoded[:num_train] # 0 ~ num_train - 1행 X_test = all_data_encoded[num_train:] # num_train ~ 마지막 행 y = train['target'] -
training data 중 일부를 valid data(검증 데이터)로 나누어준다. 제출 전에 모델 성능을 평가해볼 수 있다.
from sklearn.model_selection import train_test_split # 훈련 데이터, 검증 데이터 분리 X_train, X_valid, y_train, y_valid = train_test_split(X_train, y, test_size=0.1, stratify=y, random_state=10)- train_test_split()함수로 전체 데이터를 training data와 valid 혹은 test data로 나누어준다. 첫번째 인수로 feature(X_train), 두번째 인수로 타깃값(y)를 전달한다.
- test_size는 검증 데이터 크기를 지정하는 파라미터로, 정수로 전달하면 개수, 실수로 전달하면 비율이다. stratify 파라미터는 지정한 값을 각 그룹에 공정하게 배분하는 것으로, 타깃값인 y를 전달했으므로 타깃값이 training data, valid data 각각에 같은 비율로 포함되게끔 나눠준다.
모델 훈련
-
선형 회귀 방식으로 분류를 수행하는 로지스틱 회귀 모델을 생성하고 훈련한다.
from sklearn.linear_model import LogisticRegression logistic_model = LogisticRegression(max_iter=1000, random_state=42) # 모델 생성 logistic_model.fit(X_train, y_train) # 모델 훈련- max_iter는 모델의 회귀 계수를 업데이트하는 반복 횟수를 의미한다.
모델 성능 검증
-
타깃값 예측 메서드 predict()는 타깃값 자체, 0인지 1인지를 예측하고, predict_proba()는 타깃값의 확률, 0일 확률과 1일 확률을 예측한다. 첫번째 열은 타깃값이 0일 확률, 두번째 열을 1일 확률을 나타낸다.
logistic_model.predict_proba(X_valid)
-
본 대회에서는 타깃값이 1일 확률을 예측하는 것이므로 predict_proba()로 예측한 결과의 두번째 열을 타깃 예측값으로 사용한다. 검증 데이터를 활용해 타깃값을 예측할 수 있다.
# 검증 데이터를 활용한 타깃 예측 y_valid_preds = logistic_model.predict_proba(X_valid)[:, 1]- y_valid_preds에는 검증 데이터 타깃값이 1일 확률이 저장된다.
-
타깃 예측값인 y_valid_preds와 실제 타깃값 y_valid를 이용해 ROC AUC 점수를 구해 모델 성능을 검증한다.
from sklearn.metrics import roc_auc_score # ROC AUC 점수 계산 함수 # 검증 데이터 ROC AUC roc_auc = roc_auc_score(y_valid, y_valid_preds) print(f'검증 데이터 ROC AUC : {roc_auc:.4f}')
예측 및 결과 제출
- Test data를 활용해 타깃값이 1일 확률을 예측하고 결과를 제출한다.
# 타깃값 1일 확률 예측 y_preds = logistic_model.predict_proba(X_test)[:, 1]# 제출 파일 생성 submission['target'] = y_preds submission.to_csv('submission.csv')
성능 개선 1
Feature Engineering 1: Feature 맞춤 인코딩
- Baseline model에서는 모든 feature를 원-핫 인코딩했는데, feature 특성에 맞게 인코딩해주면 성능이 더 좋아진다.
데이터 합치기
- 인코딩 전에 training data, test data를 합쳐 all_data를 만들고 타깃값은 제거한다.
# 훈련 데이터와 테스트 데이터 합치기 all_data = pd.concat([train, test]) all_data = all_data.drop('target', axis=1) # 타깃값 제거
이진 feature 인코딩
- 문자로 구성된 bin_3, bin_4의 feature값들을 map()함수로 숫자로 바꾸어준다.
all_data['bin_3'] = all_data['bin_3'].map({'F':0, 'T':1}) all_data['bin_4'] = all_data['bin_4'].map({'N':0, 'Y':1})
순서형 feature 인코딩
-
ord_1과 ord_2 feature 또한 map()함수로 순서를 맞춰 인코딩해준다.
ord1dict = {'Novice':0, 'Contributor':1, 'Expert':2, 'Master':3, 'Grandmaster':4} ord2dict = {'Freezing':0, 'Cold':1, 'Warm':2, 'Hot':3, 'Boiling Hot':4, 'Lava Hot':5} all_data['ord_1'] = all_data['ord_1'].map(ord1dict) all_data['ord_2'] = all_data['ord_2'].map(ord2dict) -
ord_3, 4, 5는 알파벳 순서대로 인코딩을 해줘야 하는데, OrdinalEncoder를 사용하면 된다.
from sklearn.preprocessing import OrdinalEncoder ord_345 = ['ord_3', 'ord_4', 'ord_5'] ord_encoder = OrdinalEncoder() # OrdinalEncoder 객체 생성 # ordinal 인코딩 적용 all_data[ord_345] = ord_encoder.fit_transform(all_data[ord_345]) # 피처별 인코딩 순서 출력 for feature, categories in zip(ord_345, ord_encoder.categories_): print(feature) print(categories)
- ord_encoder.cateogries_는 어떤 순서로 ordinal 인코딩을 적용했는지 보여준다.
- 알파벳 순으로 인코딩했기 때문에 feature 값이 a는 0.0, b는 1.0, c는 2.0 식으로 바뀐다.
명목형 feature 인코딩
-
먼저 list comprehension을 활용해 명목형 feature list를 만들어준다.
nom_features = ['nom_' + str(i) for i in range(10)] # 명목형 피처 -
원-핫 인코딩을 바로 all_data에서 하면 열 개수가 늘어나서 인코딩할 수 없기에 별도 행렬에 저장하고 이어서 all_data에서 명목형 feature를 삭제해준다.
from sklearn.preprocessing import OneHotEncoder onehot_encoder = OneHotEncoder() # OneHotEncoder 객체 생성 # 원-핫 인코딩 적용 encoded_nom_matrix = onehot_encoder.fit_transform(all_data[nom_features]) encoded_nom_matrix- 이후 encode_nom_matrix와 all_data를 합칠 것이기 때문에 중복되지 않도록 all_data에서 기존 명목형 feature를 삭제한다.
all_data = all_data.drop(nom_features, axis=1) # 기존 명목형 피처 삭제
날짜 feature 인코딩
- day와 month feature에도 원-핫 인코딩을 적용해준다.
date_features = ['day', 'month'] # 날짜 피처
# 원-핫 인코딩 적용
encoded_date_matrix = onehot_encoder.fit_transform(all_data[date_features])
all_data = all_data.drop(date_features, axis=1) # 기존 날짜 피처 삭제
encoded_date_matrixFeature Engineering 2: Feature Scaling
- Feature Scaling: 서로 다른 feature들의 값의 범위가 일치하도록 조정하는 작업
- 수치형 feature들의 유효 값 범위가 서로 다르면 훈련이 안되므로 featue scaling을 해준다. 순서형 feature를 제외한 값들은 모두 0과 1로 인코딩 해주었으므로 순서형 feature도 0~1사이의 값으로 scaling해준다.
순서형 feature Scaling
-
min-max 정규화를 해주어 feature값의 범위를 0~1로 조정한다.
from sklearn.preprocessing import MinMaxScaler ord_features = ['ord_' + str(i) for i in range(6)] # 순서형 피처 # min-max 정규화 all_data[ord_features] = MinMaxScaler().fit_transform(all_data[ord_features])
인코딩 및 스케일링된 feature 합치기
-
이진 feature, 순서형 feature가 인코딩되어 있는 all_data와 명목형 feature, 날짜 feature가 원-핫 인코딩되어 있는 encoded_nom_matrix, encoded_date_matrix를 모두 합친다.
두 matrix는 CSR 형식이므로 전달받은 데이터를 CSR 형식으로 바꿔주는 csr_matrix() 함수를 이용한다. hstack()은 행렬을 수평 방향으로 합친다.from scipy import sparse # 인코딩 및 스케일링된 피처 합치기 all_data_sprs = sparse.hstack([sparse.csr_matrix(all_data), encoded_nom_matrix, encoded_date_matrix], format='csr')
데이터 나누기
-
training data와 test data를 나누어준다. y는 모델 훈련 시 필요한 타깃값(정답)이다.
num_train = len(train) # 훈련 데이터 개수 # 훈련 데이터와 테스트 데이터 나누기 X_train = all_data_sprs[:num_train] # 0 ~ num_train - 1행 X_test = all_data_sprs[num_train:] # num_train ~ 마지막 행 y = train['target'] -
training data를 다시 training data와 검증 data로 나누어준다.
from sklearn.model_selection import train_test_split # 훈련 데이터, 검증 데이터 분리 X_train, X_valid, y_train, y_valid = train_test_split(X_train, y, test_size=0.1, stratify=y, random_state=10)
하이퍼파라미터 최적화
-
그리드서치로 로지스틱 회귀 모델의 하이퍼파라미터를 최적화한다. 규제 강도를 조절하는 파라미터 C(값이 작을수록 규제 강도가 세짐)와 max_iter 하이퍼파라미터를 탐색한다. 평가지표는 ROC AUC로 지정한다.
%%time from sklearn.model_selection import GridSearchCV from sklearn.linear_model import LogisticRegression # 로지스틱 회귀 모델 생성 logistic_model = LogisticRegression() # 하이퍼파라미터 값 목록 lr_params = {'C':[0.1, 0.125, 0.2], 'max_iter':[800, 900, 1000], 'solver':['liblinear'], 'random_state':[42]} # 그리드서치 객체 생성 gridsearch_logistic_model = GridSearchCV(estimator=logistic_model, param_grid=lr_params, scoring='roc_auc', # 평가지표 cv=5) # 그리드서치 수행 gridsearch_logistic_model.fit(X_train, y_train) print('최적 하이퍼파라미터:', gridsearch_logistic_model.best_params_)
모델 성능 검증
-
검증 데이터로 모델 성능을 검증해보기 위해 타깃 예측값을 구하고, 이어 ROC AUC를 구한다.
y_valid_preds = gridsearch_logistic_model.predict_proba(X_valid)[:, 1]from sklearn.metrics import roc_auc_score # ROC AUC 점수 계산 함수 # 검증 데이터 ROC AUC roc_auc = roc_auc_score(y_valid, y_valid_preds) print(f'검증 데이터 ROC AUC : {roc_auc:.4f}')
- Baselin model 보다 0.0008만큼 향상되었다.
예측 및 결과 제출
# 타깃값 1일 확률 예측
y_preds = gridsearch_logistic_model.best_estimator_.predict_proba(X_test)[:,1]
# 제출 파일 생성
submission['target'] = y_preds
submission.to_csv('submission.csv')- 프라이빗 점수 기준으로 상위 약 30%정도 되는 등수이다.
성능 개선 2
-
앞의 모델에서는 전체 training data를 9:1의 비율로 training data, valid data로 나누어 valid data는 검증용으로만 사용하였는데, 나누지 않고 training data 전체를 사용해 모델을 훈련한다면 성능이 향상된다. train_test_split()으로 나누는 부분을 삭제한다.
-
최종적으로 제출할 때 vaild data까지 포함한 전체 training data로 다시 훈련하여 제출하는 것이 성능 향상에 유리하다.
최종
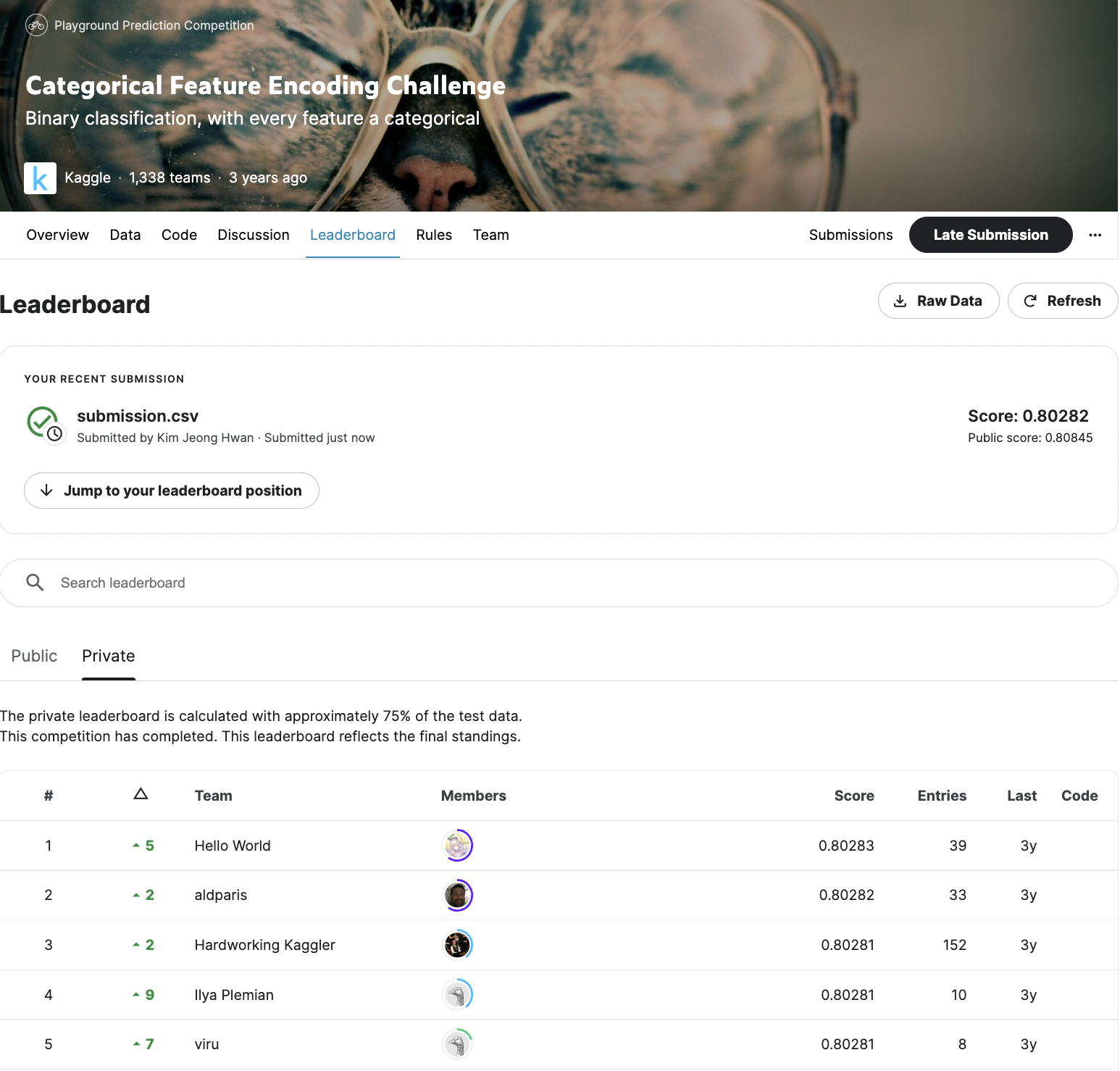
-
score: 0.80282로 1341명의 참가자 중 2위를 차지하였다.(2022.11.19 기준)
-
마지막에 제출할 때 valid data까지 모두 포함한 전체 training data로 모델을 다시 훈련해 제출한 부분에서 크게 등수를 올릴 수 있었기에 다른 대회에서도 최종 제출 전 이 방법을 적용해보면 좋을 것 같다.
-
github에 해당 코드를 올려두었다.
참고: 머신러닝·딥러닝 문제해결 전략 (캐글 수상작 리팩터링으로 배우는 문제해결 프로세스와 전략)
참고: https://www.kaggle.com/code/kabure/eda-feat-engineering-encode-conquer/notebook
