cs231n 강의 중 'Lecture 9 | CNN Architectures'를 정리한 내용이다.
AlexNet
- 2012년, imageNet classification test에서 좋은 성능을 내어 우승한, 첫 딥러닝 기반 접근을 한 CNN 모델이다. 각 layer별로 ouput volume size와 parameter의 개수를 계산하는 방법을 알아두어야 좋다.

- 처음 ReLU를 사용해 non-linearity를 다루었다.
ZFNet
- AlexNet의 하이퍼파라미터를 개선한 모델로, 구조는 같으나 stride size, filter 수와 같은 하이퍼파라미터를 조절해 error rate를 낮추었다.

VGGNet
- layer가 훨씬 많은 deeper network로, 훨씬 적은 filter를 이용한다. 기존 AlexNet에서 8개였던 layer를 16-19개로 늘렸다. 필터는 3x3 크기만 계속 이용한다.
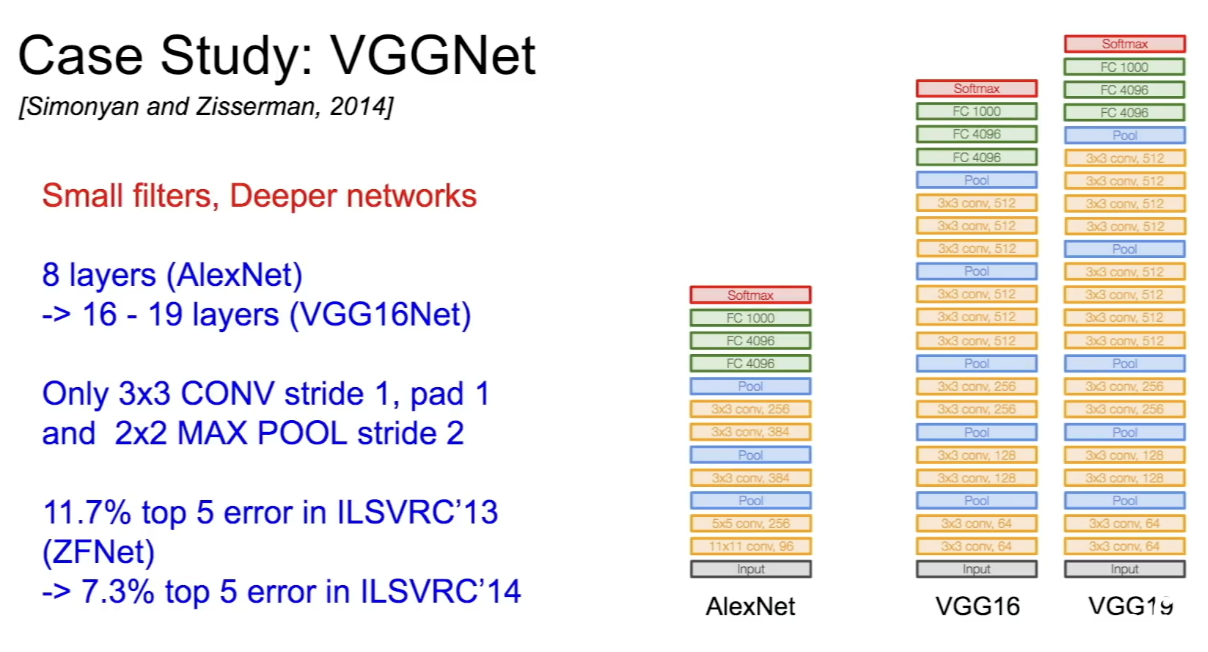
- 작은 필터를 이용해도 큰 필터와 똑같이 효과적인 recptive field를 갖는다. (receptive field는 CNN에서 input layer에 찍히는 부분을 뜻한다.) 작은 필터를 사용하면 파라미터의 수가 적고, 그만큼 깊게 depth를 쌓을 수 있다.

- 작은 필터를 이용해도 큰 필터와 똑같이 효과적인 recptive field를 갖는다. (receptive field는 CNN에서 input layer에 찍히는 부분을 뜻한다.) 작은 필터를 사용하면 파라미터의 수가 적고, 그만큼 깊게 depth를 쌓을 수 있다.
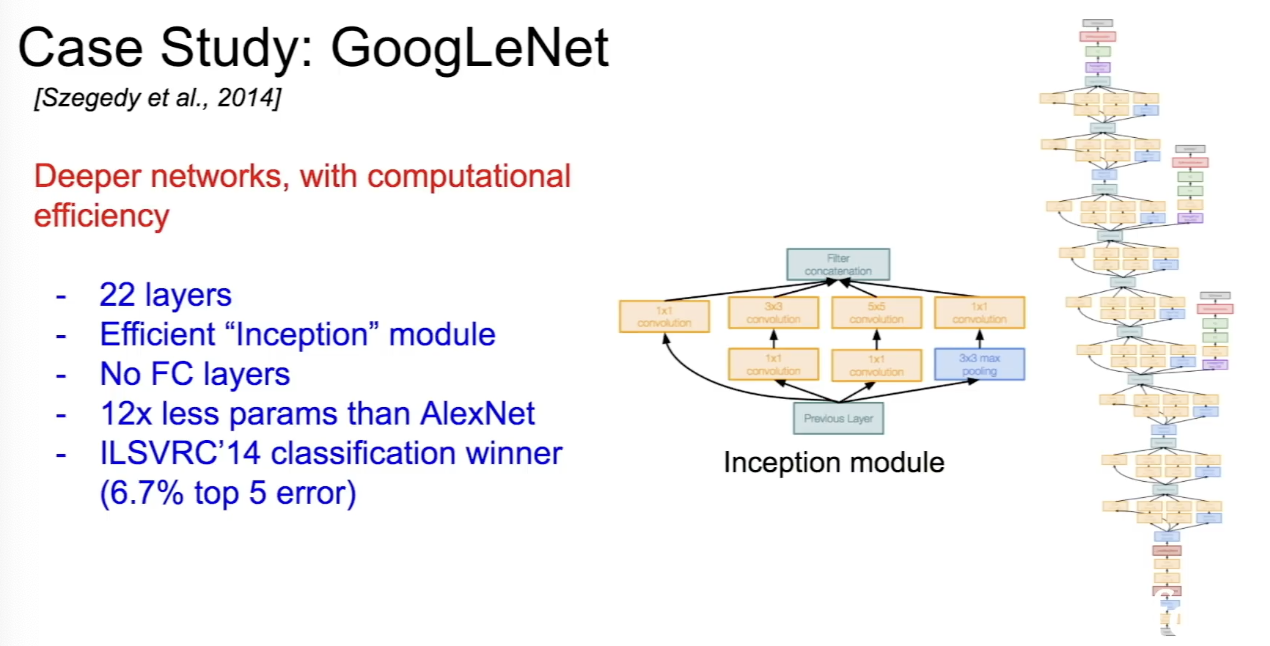
GoogLeNet
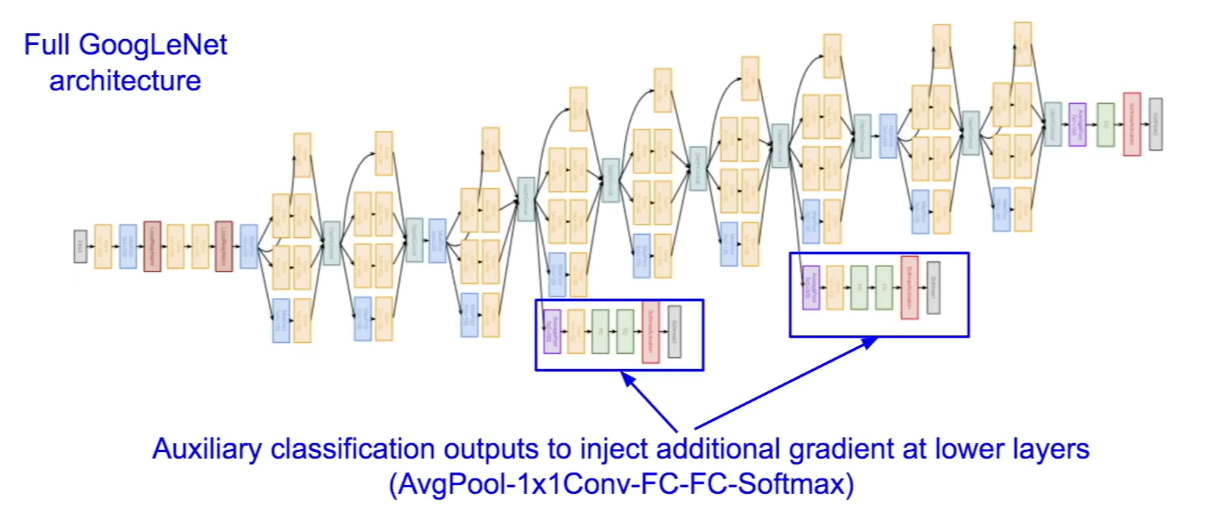
- layer가 22개인 deeper network로, computational efficiency에 초점을 맞춘 모델이다. Inceptual module을 사용해 computational efficiency를 높였다.

- FC layer가 없는 것이 특징이고, 파라미터를 줄이기 위해 없앴다. 파라미터는 500백만개로, AlexNet에 비해 훨씬 적다.
- Inception Module은 좋은 local network topolgy를 설계하고 이들을 쌓는 방식으로 구성된다.
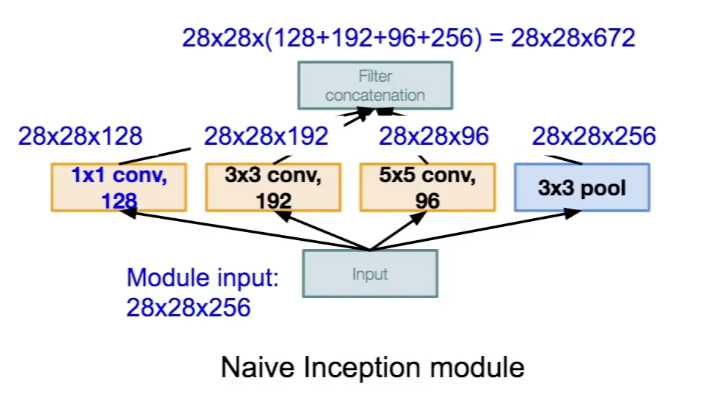
- 각 layer의 각각의 출력값을 합치는 방법이 naive inception module이다.
- 문제점은 computation 비용이 너무 크다는 것인데, pooling layer 또한 이 문제를 가중시킨다.
- 이를 해결하기 위해 "bottleneck" layers를 이용해 Conv 연산을 시작하기 전 feature map을 더 낮은 차원으로 보낸다.
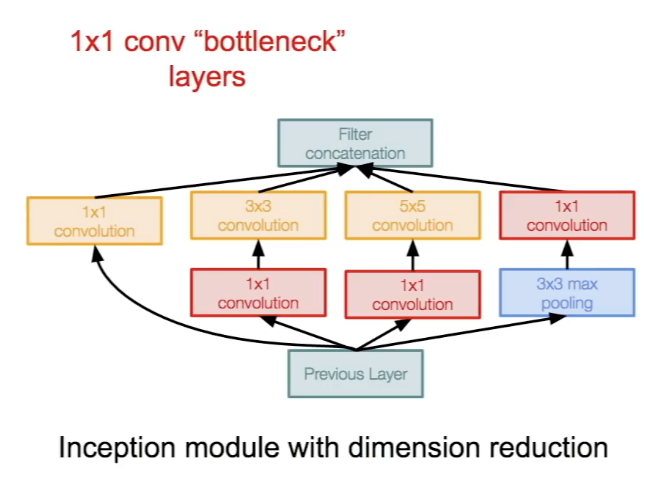
- 각 layer의 계산량이 bottleneck layer의 1x1 conv을 통해 줄어드는 것이다.
- GoogLeNet의 초반부는 conv-pool 과정이 반복되고, 이후 과정에선 auxiliary classification이 이루어지는 mini network 부분이 있는데, 중간 layer에서 실행되며 training을 하고 gradient를 얻어 학습을 돕는다.
ResNet
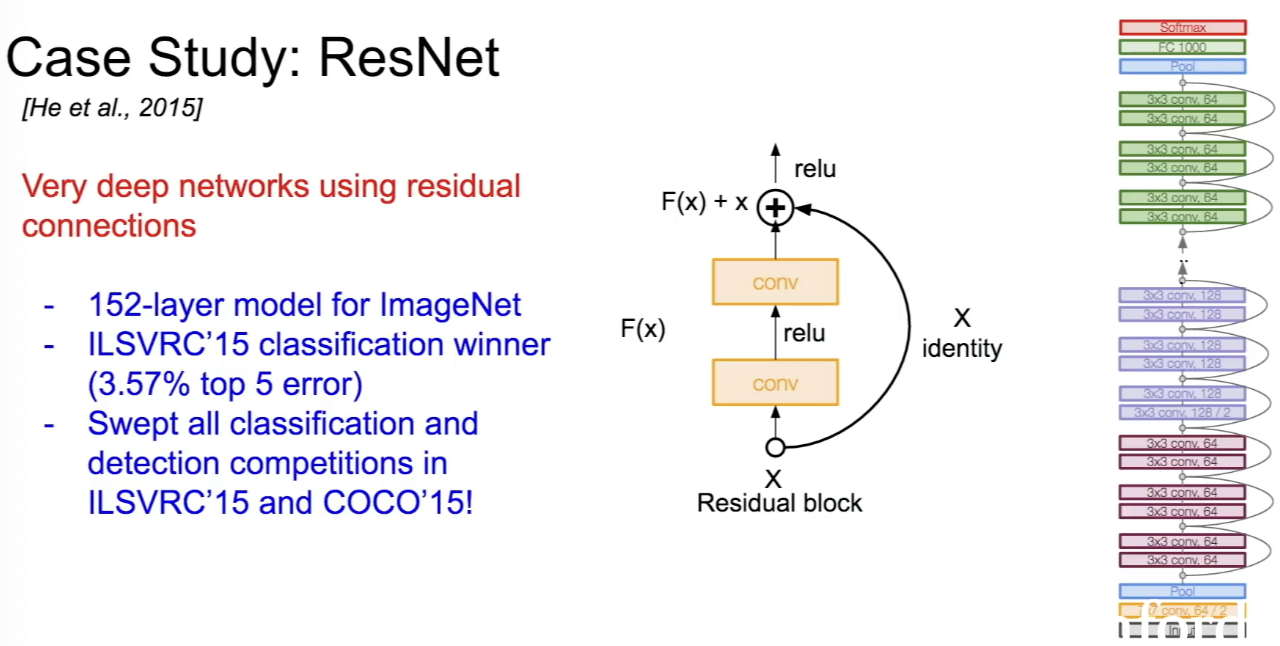
- ResNet은 지금까지 모델 중 가장 깊은 네트워크이며, residual connections를 이용한다.
- layerrk 152개인 모델이고, classification과 detection competition에서 많은 우승을 한 좋은 모델이다.
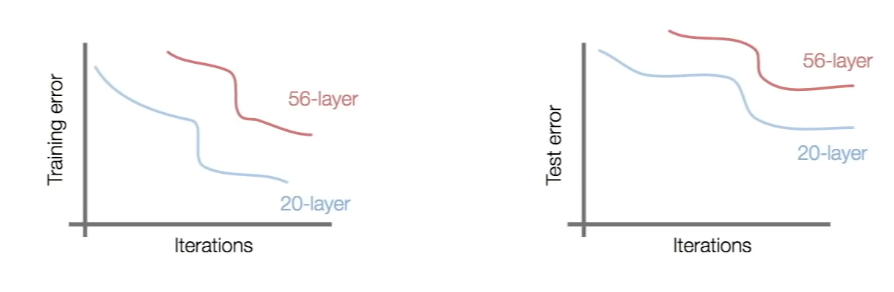
- 일반 CNN에 layer를 깊이 쌓으면 성능이 더 좋아질까와 관련된 아이디어에서 시작되었는데, 실제로 구현해본 결과 네트워크를 깊게만 쌓는다고 성능이 더 좋아지지는 않았다. 20-layer과 56-layer를 비교해본 결과 training error, test error 모두에서 56-layer가 성능이 더 나쁜 것을 보아 오버피팅이 발생한 것도 아니기에 optimization에 문제가 생겼다고 가설을 세웠다. 모델이 깊어질수록 optimize하기가 더 어려워진다는 것이다.
- 이 문제를 해결하기 위해 Residual mapping 방법을 사용한다.
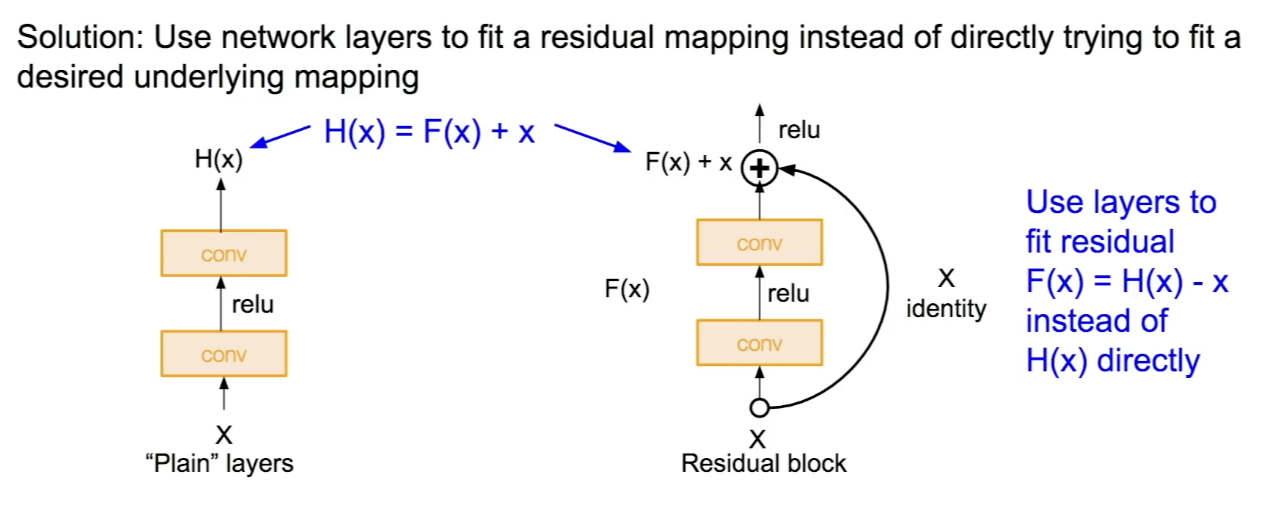
- layer가 직접 H(X)를 학습하는 것이 아니라 'H(X) - x'를 학습할 수 있게 한다. 이를 위해 skip connection을 한다. 이는 가중치가 없고 입력을 identity mapping으로 출력단에 내보낸다. 실제 layer는 입력 X의 residual만 학습하면 된다.
- 최종 출력값은 'input X + residual'이 된다. 이 방법은 layer가 full mapping 학습하지 않고 residual만 학습하면 되게 해서 학습이 쉬워진다.
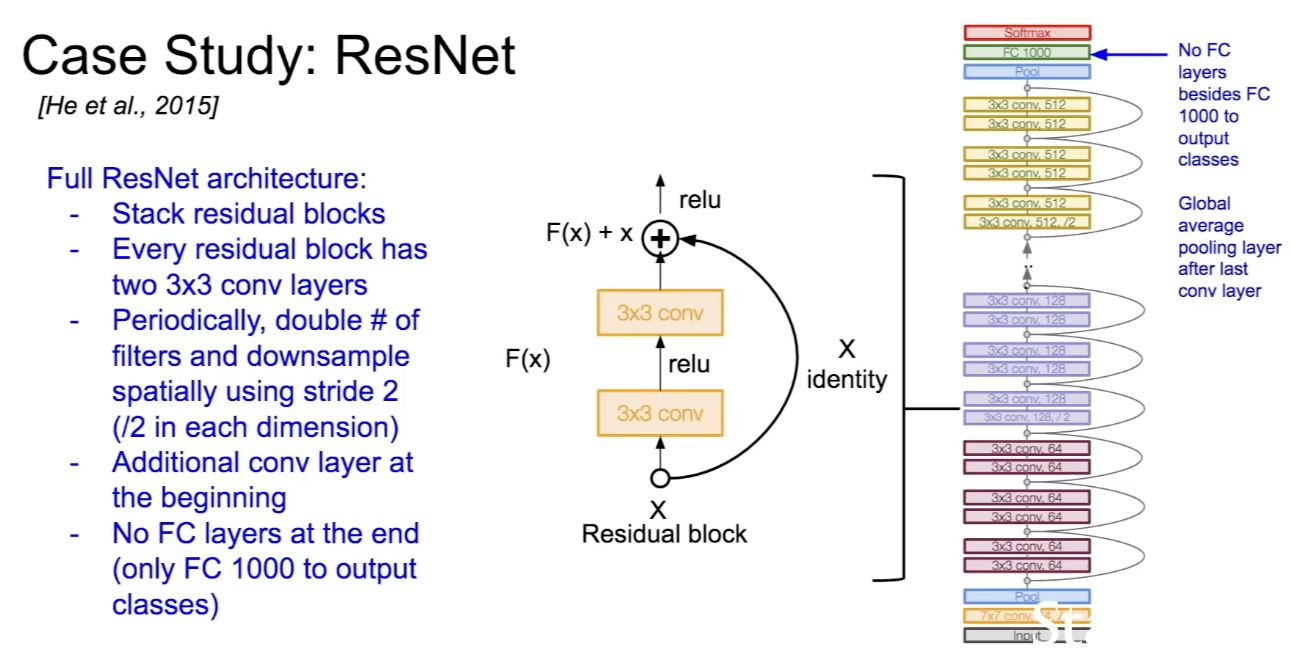
- ResNet의 구조는 residual block을 쌓은 형태로 구성되어 있고, 모든 residual block은 3x3 conv layer로 구성된다.
- 주기적으로 필터를 두배씩 늘리고 stride는 2로 하여 downsampling을 진행한다.
- 초반에 Conv layer가 추가적으로 있고, 마지막에 FC layer는 없다. 대신 클래스 분류를 위해 FC 1000이 존재한다.
- ResNet은 Depth가 50이상일 때 Bottleneck layer를 사용해 efficiency를 개선한다.(GoogLeNet과 비슷하다.)
모델별 complexity 비교
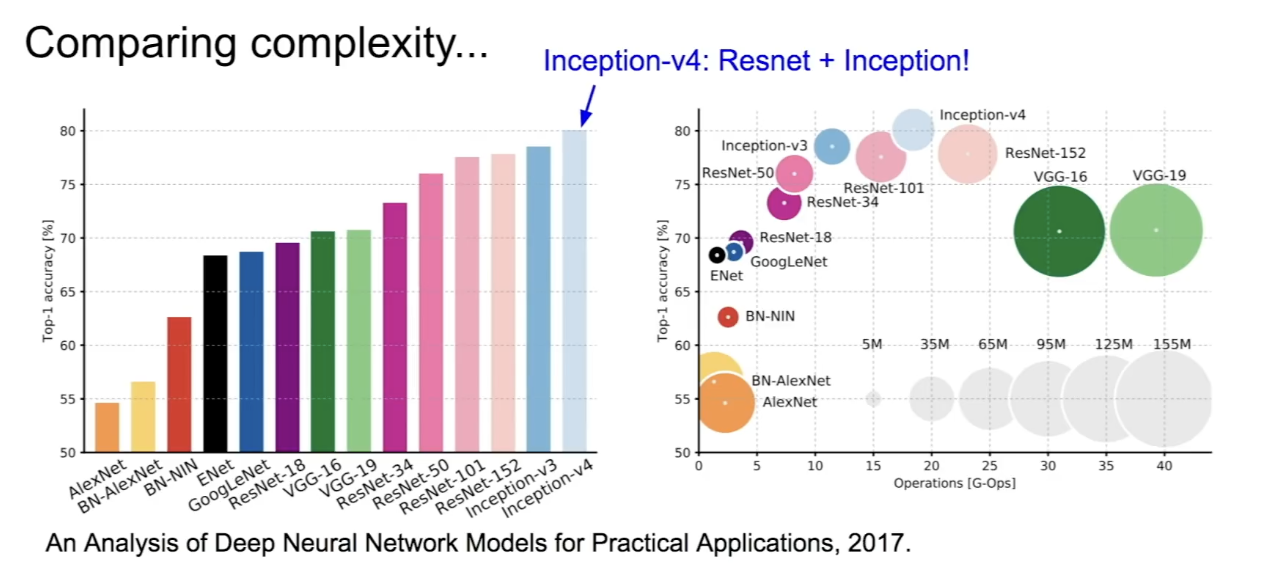
- inception v4 모델이 성능이 가장 좋은데, ResNet과 Inception 모델을 합친 것이다.
- 오른쪽 그래프는 연산량과 메모리 사용량을 고려한 것으로, X축은 연산량, 원의 크기가 메모리 사용량을 나타낸다.
- VGGNet은 메모리가 크고 계산량이 많지만 성능은 나쁘지않은, 효율성이 가장 떨어지는 모델이다. GoogLeNet이 가장 효율적이고, ResNet도 효율적이며 정확도가 높다.
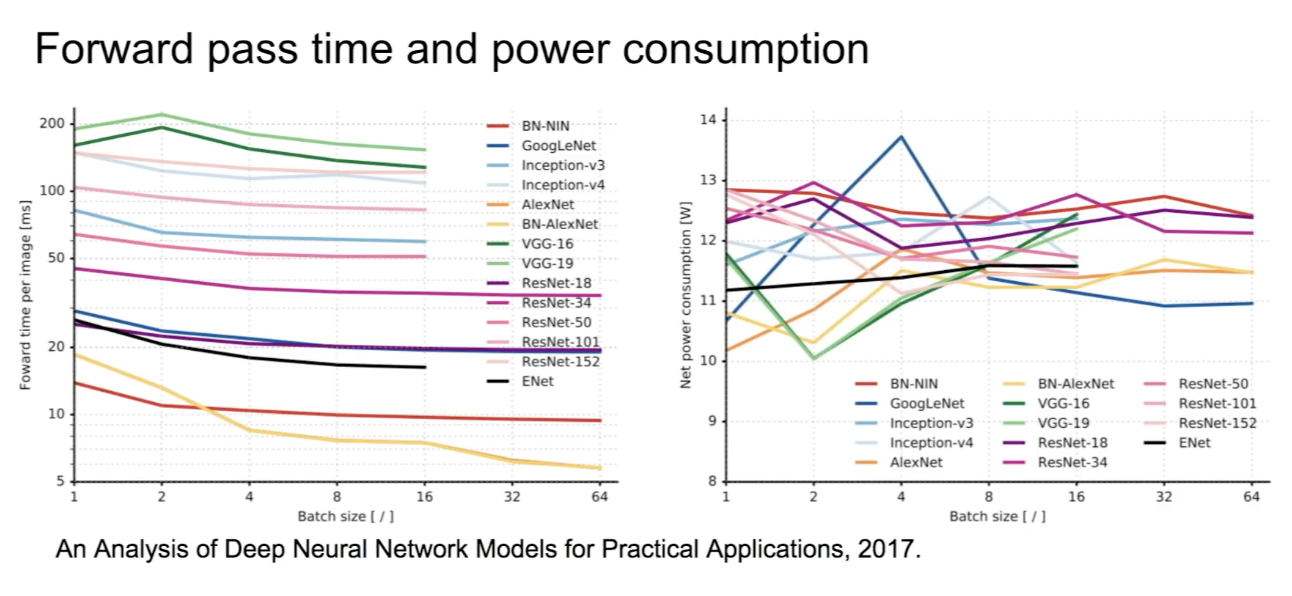
- forward pass 걸리는 시간과 power consumption을 나타내는 그래프로, 아까 본 것처럼 VGG가 가장 오래걸리는 것을 볼 수 있다.
Network in Network (NiN)
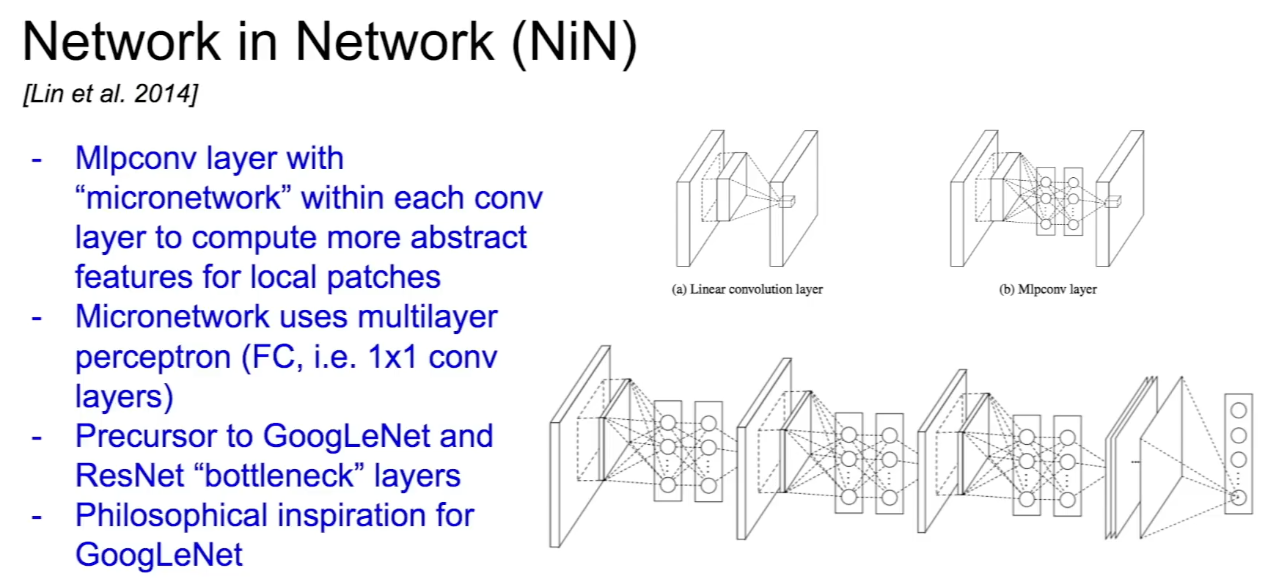
- MLP에서 각 conv layer 안에 MLP를 쌓는, 네트워크 안에 작은 네트워크를 넣는 구조이다. GoogLeNet, ResNet보다 먼저 bottleneck layer 개념을 이용했다.
ResNet을 개선하기 위한 연구들과 다른 architectures
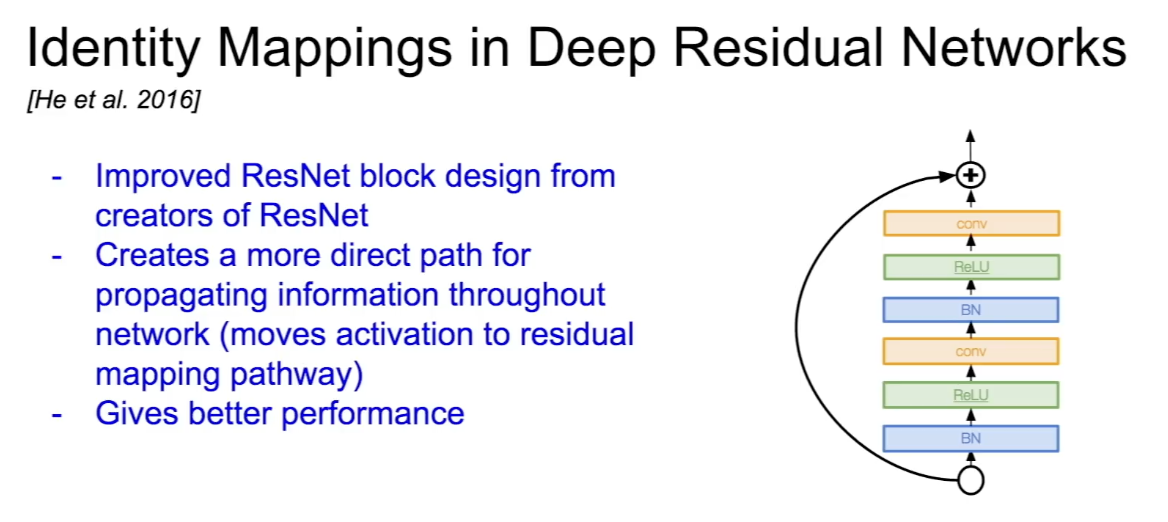
Identity Mappings in Deep Residual Networks
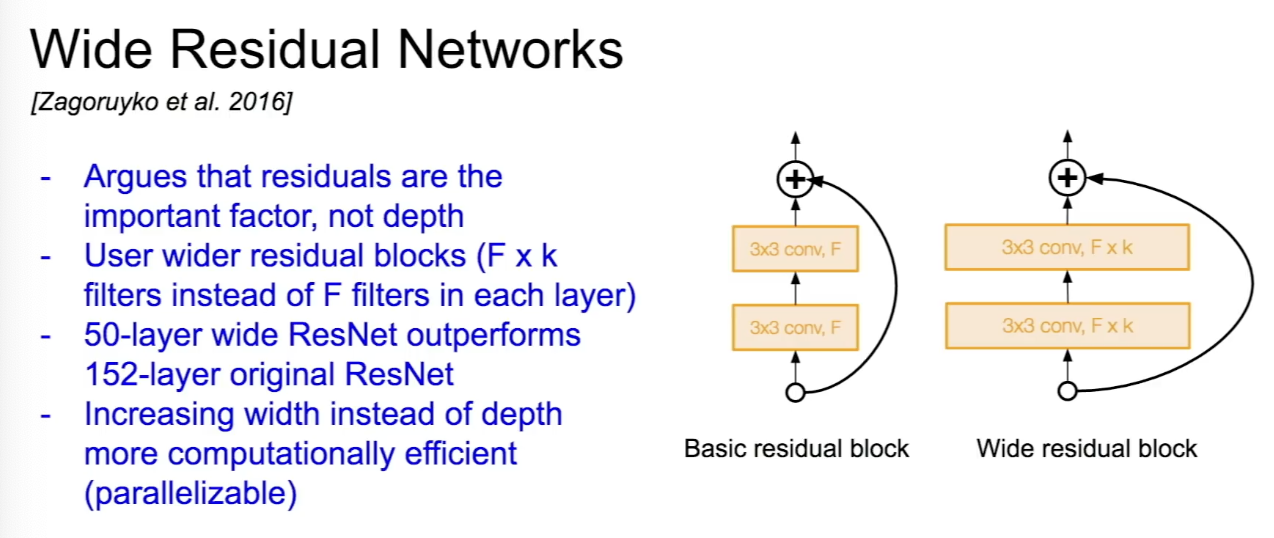
Wide Residual Networks
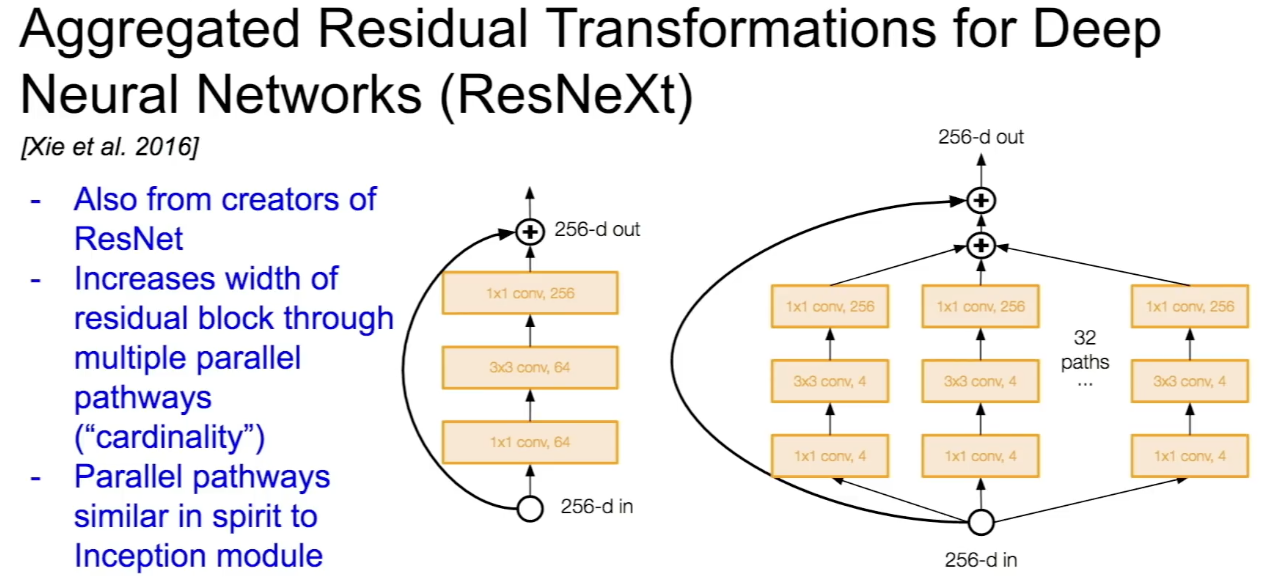
Aggregated Residual Transformations for Deep Neural Networks (ResNeXt)
Deep Networks with Stochastic Depth

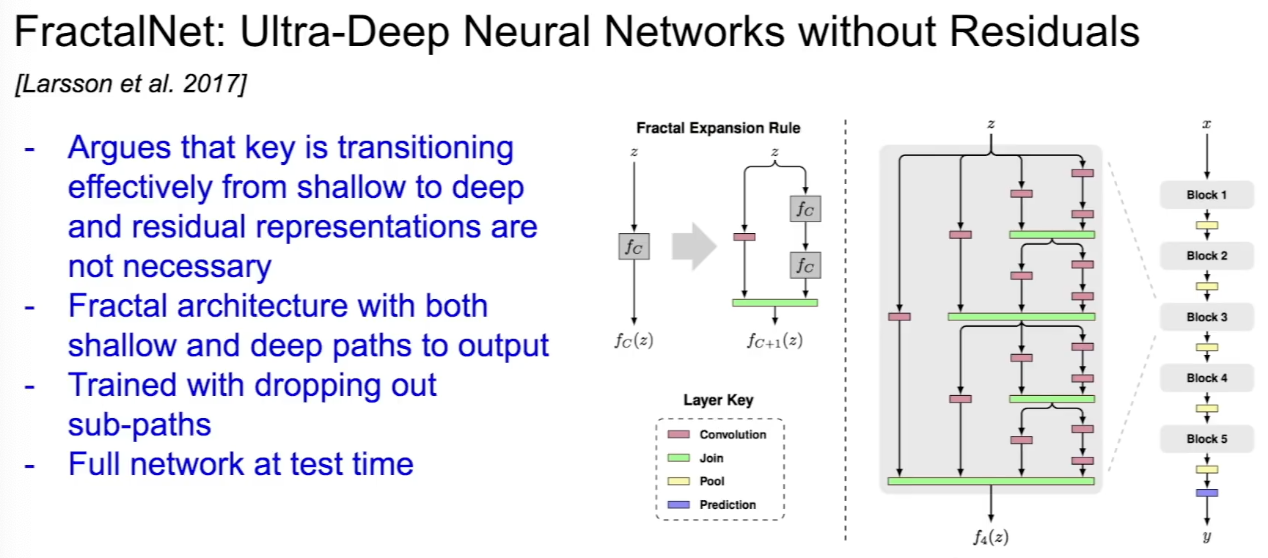
FractalNet
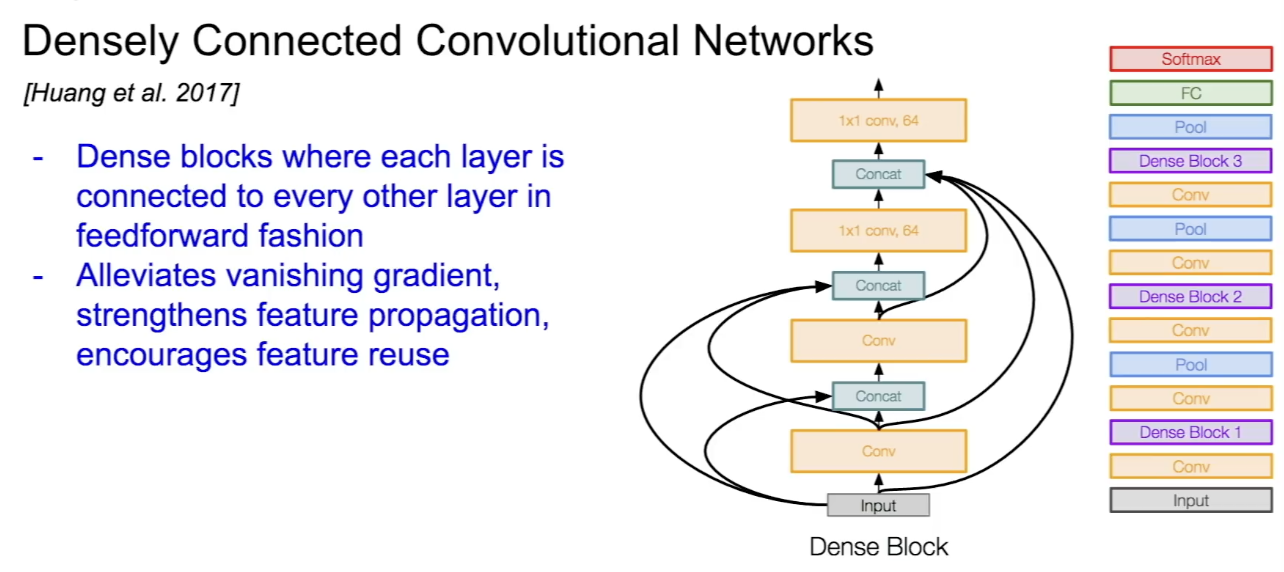
Densely Connected Convolutional Networks
SqueezeNet

