SQLD를 준비하며 공부했던 내용으로, 2020 이기적 SQL 개발자(Developer) 이론서 + 기출문제를 참고했다.
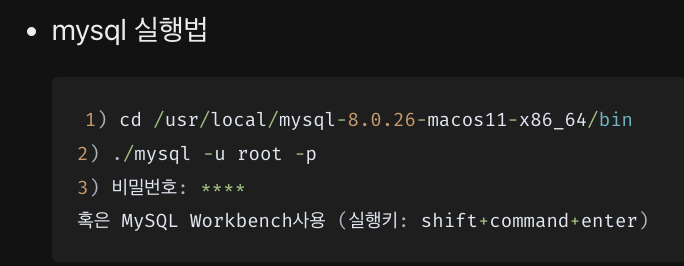
- mysql 실행법
1) cd /usr/local/mysql-8.0.26-macos11-x86_64/bin 2) ./mysql -u root -p 3) 비밀번호: **** 혹은 MySQL Workbench사용 (실행키: shift+command+enter)
데이터 모델링
데이터 모델링의 이해
-
데이터 모델링의 특징
1) 추상화: 공통적인 특징을 찾고 현실세계를 간략하게 표현
2) 단순화: 복잡한 문제를 피하고 누구나 쉽게 이해할 수 있도록 표현
3) 명확성: 명확하게 의미가 해석되어야 하고 한가지 의미를 가짐
-
데이터 모델링 단계
1) 개념적 모델링: 업무 전체에 대해 전사적인 관점에서 모델링, 기술적인 용어 사용 x, ERD 작성, 추상화 수준이 가장 높은 수준의 모델링
2) 논리적 모델링: 개념적 모델링을 논리적 모델링으로 변환, 식별자를 도출하고 모든 릴레이션 정의, 정규화 수행하여 데이터 모델의 독립성을 확보하고 재사용성을 높임
3) 물리적 모델링: 데이터베이스를 실제 구축하여 테이블, 인덱스 등을 생성, '성능, 보안, 기용성' 등을 고려하여 데이터베이스 구축
-
데이터 모델링 관점
1) 데이터: 비즈니스 프로세스에서 사용되는 데이터 의미, 구조 분석, 정적 분석
2) 프로세스: 비즈니스 프로세스에서 수행되는 작업을 의미, 시나리오 분석, 도메인 분석, 동적 분석
3) 데이터와 프로세스: 프로세스와 데이터 간의 관계를 의미한다. CRUD(Create, Read, Update, Delete) 분석
-
ERD 작성 절차
1) 엔터티 도출하고 그리기, 2) 엔터티 배치, 3) 엔터티 간의 관계 설정, 4) 관계명 서술, 5) 관계 참여도 표현, 6) 관계의 필수 여부 표현
-
데이터 모델링 고려사항
1) 데이터 모델의 독립성
-
독립성이 확보된 모델은 고객 업무 변화에 능동적으로 대응 가능
-
중복된 데이터를 제거하여 독립성 확보
-
데이터 중복을 제거하는 것이 정규화
2) 고객 요구사항의 표현
-
데이터 모델링으로 고객과 데이터 모델러 간에 의사소통
-
고객의 요구사항을 간결하고 명확하게 표현
3) 데이터 품질 확보
-
데이터베이스 구축 시에 데이터 표준을 정의, 표준 준수율 관리
-
데이터 표준을 확보하여 데이터 품질 향상
-
3층 스키마
-
3층 스키마: 사용자, 설계자, 개발자가 데이터베이스를 보는 관점에 따라 데이터베이스를 기술하고 이들간의 관계를 정의한 ANSI 표준, 데이터베이스의 독립성을 확보하기 위한 방법, 데이터 독립성을 확보하여 '데이터 복잡도 증가, 데이터 중복 제거, 사용자 요구사항 변경에 따른 대응력 향상, 관리 및 유지보수 비용 절감', 3단계 계층(view)로 분리
-
3층 스키마의 독립성: 논리적 독립성(개념 스키마가 변경되더라도 외부 스키마가 영향을 받지 않는 것), 물리적 독립성(내부 스키마가 변경되더라도 개념 스키마가 영향을 받지 않는 것)
-
3층 스키마의 구조
1) 외부 스키마: 사용자 관점, 업무상 관련이 있는 데이터 접근, 관련 데이터베이스의 view 표시, 응용 프로그램이 접근하는 데이터베이스 정의
2) 개념 스키마: 설계자 관점, 사용자 전체 집단의 데이터베이스 구조, 통합 데이터베이스 구조
3) 내부 스키마: 개발자 관점, 데이터베이스의 물리적 저장 구조
엔터티
-
엔터티: 업무에서 관리해야 하는 데이터 집합, 저장되고 관리되어야 하는 데이터, '개념, 사건, 장소' 등의 명사
-
엔터티 특징
1) 식별자: 엔터티는 유일한 식별자가 있어야 함 (ex. 회원ID, 계좌번호)
2) 인스턴스 집합: 2개 이상의 인스턴스가 있어야 함 (ex. 고객 정보 2명 이상)
3) 속성: 엔터티는 반드시 속성을 가짐 (ex. 회원ID, 패스워드, 이름, 주소)
4) 관계: 엔터티는 다른 엔터티와 최소한 한 개 이상 관계가 있어야 함 (ex. 고객은 계좌를 개설)
5) 업무: 엔터티는 업무에서 관리되어야 하는 집합 (ex. 고객, 계좌)
-
엔터티 종류
-
유형과 무형에 따른 엔터티 종류 (유형, 개념, 사건)
1) 유형 엔터티: 업무에서 도출되며 지속적으로 사용되는 엔터티 (ex. 고객, 강사, 사원 등)
2) 개념 엔터티: 유형 엔터티는 물리적 형태가 있지만, 개념 엔터티는 물리적 형태가 없음, 개념적으로 사용되는 엔터티 (ex. 거래소 종목, 보험 상품)
3) 사건 엔터티: 비즈니스 프로세스를 실행하면서 생성되는 엔터티 (ex. 주문, 체결, 취소주문, 수수료 청구 등)
-
발생 시점에 따른 엔터티 종류 (기본, 중심, 행위)
1) 기본 엔터티: 키 엔터티, 다른 엔터티로부터 영향을 받지 않고 독립적으로 생성되는 엔터티 (ex. 고객, 상품 등)
2) 중심 엔터티: 기본 엔터티와 행위 엔터티의 중간, 기본 엔터티로부터 발생되고 행위 엔터티를 생성 (ex. 계좌, 주문, 취소, 체결 등)
3) 행위 엔터티: 2개 이상의 엔터티로부터 발생 (주문 이력, 체결 이력)
-
속성
-
속성: 업무에서 필요한 정보인 엔터티가 가지는 항목, 더 이상 분리되지 않는 단위, 업무에 필요한 데이터 저장, 인스턴스의 구성요소
-
속성의 특징: 업무에서 관리되는 정보, 하나의 값만 가짐, 주식별자에게 함수적으로 종속됨 (기본키가 변경되면 속성의 값도 변경됨)
-
속성의 종류
-
분해 여부에 따른 속성의 종류
1) 단일 속성: 하나의 의미로 구성된 것 (ex. 회원 ID, 이름)
2) 복합 속성: 여러 개의 의미가 있는 것 (ex. 주소는 시, 군, 동 등으로 분해됨)
3) 다중값 속성: 속성에 여러 개의 값을 가질 수 있는 것, 엔터티로 분해됨 (ex. 상품 리스트)
-
특성에 따른 속성의 종류
1) 기본 속성: 비즈니스 프로세스에서 도출되는 본래의 속성 (ex. 회원ID, 이름, 계좌번호 등)
2) 설계 속성: 데이터 모델링 과정에서 발생하는 속성, 유일한 값을 부여 (ex. 상품코드, 지점코드 등)
3) 파생 속성: 다른 속성에 의해 만들어지는 속성 (ex. 합계, 평균 등)
-
도메인: 속성이 가질 수 있는 값의 범위 (ex. 속성 성별의 도메인은 남자와 여자)
-
관계
-
관계: 엔터티 간의 관련성을 의미, 존재 관게와 행위 관계로 분류
-
관계의 종류
1) 존재 관계: 두 개의 엔터티가 존재 여부의 관계가 있는 것, 엔터티 간의 상태를 의미 (ex. 고객이 은행에 가입하면 관리점이 할당되어 고객을 관리)
2) 행위 관계: 두 개의 엔터티가 어떤 행위에 의한 관련성이 있는 것, 엔터티 간에 어떤 행위가 있는 것 (ex. 증권사가 계좌를 개설하고 주문을 발주하여 관계가 생성)
-
관계 차수 (Cardinality): 두 개의 엔터티 간에 관계에 참여하는 수 (ex. 한 명의 고객은 여러 개의 계좌를 개설 → 1대N 관계)
-
관계 차수의 종류
1) 1대1 관계: 완전 1대1 (하나의 엔터티에 관계되는 엔터티의 관계가 하나인 경우로, 반드시 존재), 선택적 1대1 (하나의 엔터티에 관계되는 엔터티의 관계가 하나이거나 없을 수 있음)
2) 1대N 관계: 엔터티에 행이 하나 있을 때 다른 엔터티의 값이 여러 개 있는 관계 (ex. 고객은 여러 개의 계좌를 가짐)
3) M대N 관계: 두 개 엔터티가 서로 여러 개의 관계를 가짐 (ex. 한 명의 학생이 여러 개의 과목 수강, 한 개의 과목은 여러 명의 학생이 수강), 관계형 데이터베이스에서 M대N 관계의 join은 카테시안 곱이 발생하기에 M대N 관계를 1대N, N대1로 해소해야 함
4) 필수적 관계와 선택적 관계: 필수적 관계는 반드시 하나는 존재해야 하는 관계, 선택적 관계는 없을 수도 있는 관계
-
-
식별 관계와 비식별 관계
1) 식별 관계: 강한 개체는 다른 엔터티에 의존하지 않고 독립적으로 존재, 다른 엔터티와 관계를 가질 때 다른 엔터티에게 기본키를 공유함, 고객 엔터티의 기본키인 회원ID를 계좌 엔터티(약한 개체)의 기본키의 하나로 공유하는 것, 강한 개체의 기본키 값이 변경되면 식별 관계(기본키를 공유받은)에 있는 엔터티의 값도 변경됨 (Foreign key가 primary key 되는 것)
2) 비식별 관계: 강한 개체의 기본키를 다른 엔터티의 기본키가 아닌 일반 칼럼으로 관계를 갖는 것, 점선으로 표현 (Foreign key가 attribute 되는 것)
- 강한 개체: 누구에게도 지배되지 않는 독립적인 개체
- 약한 개체: 개체의 존재가 다른 개체의 존재에 달려 있는 개체
엔터티 식별자
-
주식별자 (기본키, Primary Key)
1) 최소성: 최소성을 만족하는 키, 2) 대표성: 엔터티를 대표, 3) 유일성: 엔터티의 인스턴스를 유일하게 식별, 4) 불변성: 자주 변경되지 않아야 함
-
키의 종류
1) 기본키: 후보키 중에서 엔터티를 대표할 수 있는 키
2) 후보키: 유일성과 최소성을 만족하는 키
3) 슈퍼키: 유일성은 만족하지만 최소성을 만족하지 않는 키
4) 대체키: 여러 개의 후보키 중 기본키를 선정하고 남은 키
5) 외래키: 하나 혹은 다수의 다른 테이블의 기본 키 필드를 가리키는 것, 참조 무결성을 확인하기 위해 사용됨, 허용된 데이터 값만 데이터베이스 저장하기 위해 사용
-
대표성 여부에 따른 식별자의 종류
1) 주식별자: 유일성과 최소성을 만족하면서 엔터티를 대표하는 식별자, 다른 엔터티와 참조 관계로 연결될 수 있음
2) 보조 식별자: 유일성과 최소성은 만족하지만 대표성을 만족하지 못하는 식별자
-
생성 여부에 따른 식별자의 종류
1) 내부 식별자: 엔터티 내부에서 스스로 생성되는 식별자
2) 외부 식별자: 다른 엔터티의 관계로 인하여 만들어지는 식별자
-
속성의 수에 따른 식별자의 종류
1) 단일 식별자: 하나의 속성으로 구성
2) 복합 식별자: 두 개 이상의 속성으로 구성
-
대체 여부에 따른 식별자의 종류
1) 본질 식별자: 비즈니스 프로세스에서 만들어지는 식별자
2) 인조 식별자: 인위적으로 만들어지는 식별자, 후보 식별자 중에서 주식별자로 선정할 것이 없거나 주식별자가 너무 많은 칼럼으로 되었을 경우 사용, 순서번호를 사용해 식별자를 만듦
