SQLD를 준비하며 공부했던 내용으로, 2020 이기적 SQL 개발자(Developer) 이론서 + 기출문제를 참고했다.
DML(Data Manipulation Language)
-
INSERT: 테이블에 데이터를 입력하는 DML문
INSERT INTO table (column1, column2, ...)Values(expressions1, expressions2, ...);- 데이터에 문자열을 입력하면 ' '를 사용해야 함
- 특정 테이블의 모든 칼럼에 대한 데이터를 삽입하는 경우 칼럼명 생략
INSERT INTO EMP VALUES(1000,'임베스트')- 이 경우 EMP 테이블의 칼럼은 숫자형 데이텁 타입 한 개의 칼럼과 문자형 데이터 타입 한 개의 칼럼만 있어야 함
- INSERT문을 실행했다고 데이터 파일에 저장되는 것은 아니기에 저장하려면 TLC문인 Commit을 실행해야 함, Auto Commit 설정되었으면 바로 저장됨
-
SELECT: 데이터를 조회해서 해당 테이블에 바로 삽입할 수 있음, 입력되는 테이블은 사전에 생성되어 있어야 함
INESRT INTO DEPT_TEST SELECT * FROM DEPT; -
NOLOGGING: 데이터페이스에 데이터를 입력하면 로그파일(log file)에 그 정보를 기록함, Check point라는 이벤트가 발생하면 로그파일의 데이터를 데이터 파일에 저장함, Nologging 옵션은 로그파일의 기록을 최소화시켜 입력 시 성능을 향상시키는 방법, Buffer Cache라는 메모리 영역을 생략하고 기록함
ALTER TABLE DEPT NOLOGGING; -
UPDATE: 입력된 데이터의 값을 수정할 때 사용
-
원하는 조건으로 데이터를 검색해서 해당 데이터를 수정할 수 있음
-
만약 UPDATE문에 조건문을 입력하지 않으면 모든 데이터가 수정됨
UPDATE EMP SET ENAME = '조조' WHERE EMPNO = 100; -
EMP: 수정되는 테이블 / ENAME 칼럼의 값을 '조조'로 변경 / EMP 테이블에서 EMPNO가 100번인 직원을 수정함
-
UPDATE문에서 주의사항은 데이터를 수정할 때 조건절에서 검색되는 행 수만큼 수정된다는 것 (EMPNO: 100이 두 명이라면 두 명 모두 ENAME '조조'로 수정됨)
-
-
DELETE: 원하는 조건을 검색해서 해당되는 행을 삭제함
-
조건문을 입력하지 않으면 테이블의 모든 데이터가 삭제됨
-
DELETE로 데이터를 삭제한다고 해서 테이블의 용량이 초기화되지는 않음
DELETE FROM EMP WHERE EMPNO = 100; -
EMP 테이블에서 EMPNO가 100인 직원을 삭제함 / WHERE을 입력하지 않으렴 EMP테이블의 모든 데이터가 삭제됨
-
-
테이블의 모든 데이터 삭제
1) DELETE FROM 테이블명;
: 테이블의 모든 데이터 삭제, 데이터가 삭제되어도 용량은 감소하지 않음
2) TRUNCATE TABLE 테이블명;
: 테이블의 모든 데이터 삭제, 데이터가 삭제되면 테이블 용량은 초기화됨
-
SELECT: 테이블에 입력된 데이터를 조회하기 위해 사용
-
특정 칼럼이나 특정 행만을 조회할 수 있음
SELECT * FROM EMP WHERE 사원번호 = 1000;- SELECT *: 조회를 원하는 칼럼을 선택 / FROM EMP: 조회를 원하는 테이블을 지정함 / WHERE 사원번호 = 1000;: 조회를 원하는 데이터의 조건을 지정
- SELECT문에서 EMP 테이블의 모든칼럼 '*'을 출력, WHERE절에 있는 조건문에 있는 행만 조회함
-
SELECT 문법
1) SELECT : 모든 칼럼을 출력, ''은 모든 칼럼을 의미함
2) FROM EMP: FROM절에는 테이블명을 씀
3) WHERE 사원번호 = 1000: 조건문을 지정함, EMP에서 사원번호가 1000번인 행을 조회
-
SELECT 칼럼 지정
1) SELECT EMPNO, ENAME FROM EMP; → EMP 테이블의 모든 행에서 EMPNO, ENAME 칼럼만 출력
2) SELECT * FROM EMP; → EMP테이블의 모든 칼럼과 모든 행 조회
3) SELECT ENAME || '님' FROM EMP; → EMP 테이블의 모든 행에서 ENAME 칼럼을 조회함, 단 ENAME 칼럼 뒤에 '님'이라는 문자 결합
-
ORDER BY를 사용한 정렬
-
SELECT문을 사용할 때 ORDER BY를 같이 사용할 수 있음
-
ORDER BY는 데이터를 오름차순 혹은 내림차순으로 출력함
-
ORDER BY가 정렬을 하는 시점은 모든 실행이 끝난 후 데이터를 출력해 주기 바로 전
-
ORDER BY는 정렬을 하기 때문에 데이터베이스 메모리를 많이 사용하게 됨, 대량의 데이터를 정렬하게 되면 정렬로 인한 성능 저하가 발생함
-
정렬을 회피하기 위해 인덱스를 생성할 때 사용자가 원하는 형태로 오름차순 혹은 내림차순으로 생성해야 함
-
특별한 지정이 없으면 ORDER BY는 오름차순으로 정렬함
SELECT * FROM EMP ORDER BY ENAME, SAL DESC; -
ENAME으로 오름차순 정렬, SAL로 내림차순 정렬함
-
ENAME 부분은 ENAME ASC와 같음, DESC는 내림차순 정렬
-
-
INDEX를 사용한 정렬 회피
-
정렬은 Oracle DB에 부하를 주므로 인덱스를 사용해서 ORDER BY를 회피할 수 있음
create table emp( empno numnber(10) primry key, ename varchar2(20), sal number(10) ); insert into emp values(1000, '임베스트', 20000); insert into emp values(1001, '조조', 20000); insert into emp values(1002, '관우', 20000); -
위와 같이 데이터를 입력하고 SELECT문을 실행하면 EMPNO순으로 오름차순 정렬되어 조회됨, EMPNO가 기본키이기 때문에 자동으로 오름차순 인덱스 생성
SELECT /*+ INDEX_DESC(A) */ FROM EMP A; -
'+ INDEX_DESC(A) /': 힌트 사용, EMP 테이블에 생성된 인덱스를 내림차순으로 읽게 지정, 따라서 SELECT문에 ' ORDER BY EMPNO DESC'를 사용하지 않았음
-
INDEX를 스캔한 후에 해당 EMPNO 값을 가지고 테이블의 데이터를 읽음, 테이블에서 해당 행을 찾으면 인출하여 사용자 화면에 조회됨
-
-
DISTINCT와 ALIAS
- DISTINCT: 칼럼명 앞에 지정하여 중복된 데이터를 한번만 조회하게 함
SELECT DEPTNO FROM EMP ORDER BY DEPTNO;-
이 경우 EMP 테이블의 DEPTNO 칼럼을 조회, DEPTNO가 중복되어 있을 수 있음
SELECT DISTINCT DEPTNO FROM EMP ORDER BY DEPTNO; -
DINSTINCT를 사용하여 중복된 데이터를 제거하여 조회함
-
- ALIAS: ALIAS는 테이블명이나 칼럼명이 너무 길어서 간략하게 할 때 사용함
SELECT ENAME AS "이름" FROM EMP a WHERE a.EMPNO = 1000;- 칼럼명을 '이름'으로 출력, EMP 테이블명 대신 'a'사용, 'a'를 테이블명처럼 사용
- DISTINCT: 칼럼명 앞에 지정하여 중복된 데이터를 한번만 조회하게 함
-
-
WHERE
-
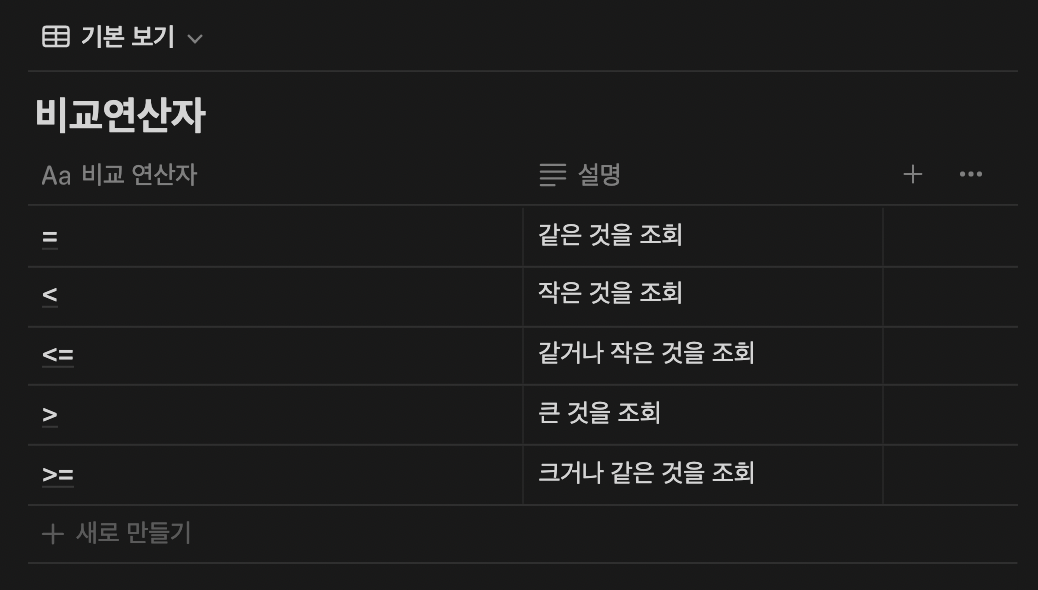
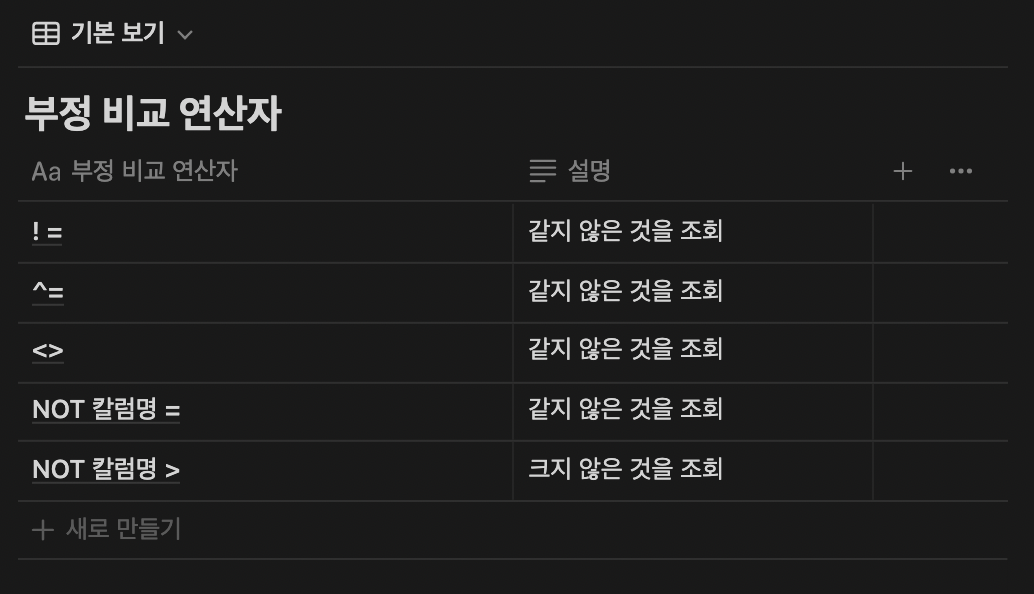
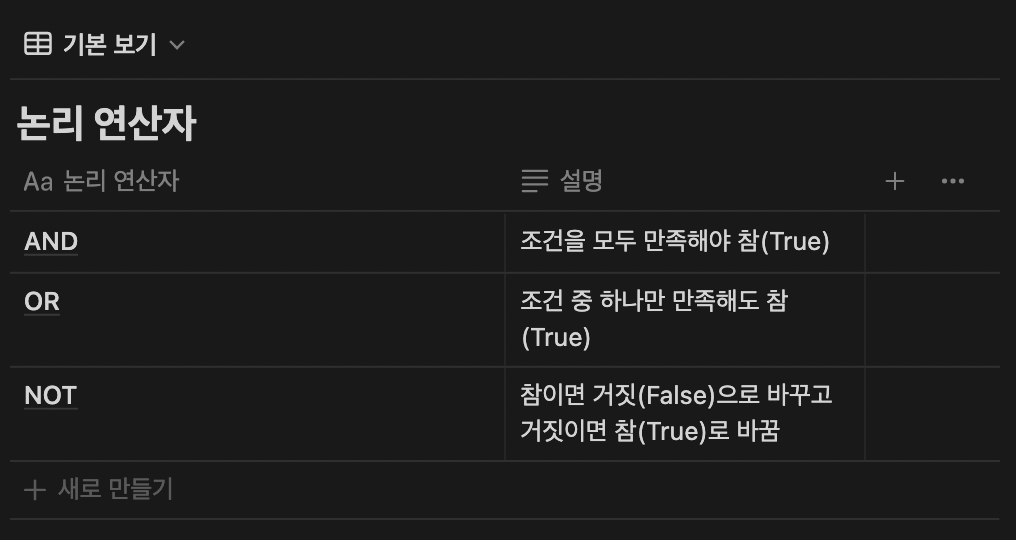
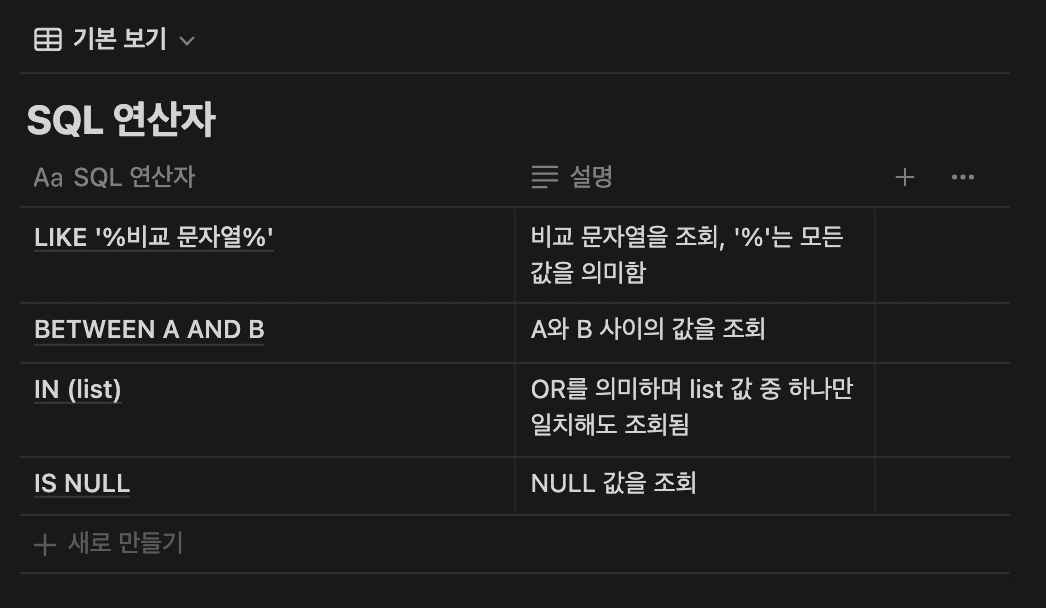
WHERE문이 사용하는 연산자: 비교 연산자, 부정 비교 연산자, 논리 연산자, SQL 연산자, 부정 SQL 연산자
SELECT * FROM EMP WHERE EMPNO=1001 AND SAL >=1000;- EMP 테이블에서 EMPNO가 1001이고 SAL이 1000보다 크거나 같은 것을 조회함
-
Like: 와일드카드를 사용해서 데이터를 조회할 수 있음
-
와일드카드
1) %: 어떤 문자를 포함한 모든 것을 조회함, '조%'는 '조'로 시작하는 모든 문자 조회
2) _(underscore): 한 개인 단일 문자를 의미함
SELECT * FROM EMP WHERE ENAME LIKE 'test%';- ENAME이 'test'로 시작하는 모든 데이터 조회SELECT * FROM EMP WHERE ENAME LIKE '%1';- ENAME의 마지막이 '1'로 끝나는 모든 것을 조회SELECT * FROM EMP WHERE ENAME LIKE '%est%';- ENAME의 중간에 'est'가 있는 모든 것을 조회함SELECT * FROM EMP WHERE ENAME LIKE 'test1';- LIKE문에 와일드카드를 사용하지 않으면 '='와 같음SELECT * FROM EMP WHERE ENAME LIKE 'test_';- ENAME 칼럼에서 'test'로 시작하고 하나의 글자만 더있는 것을 조회함 -
BETWEEN: 지정된 범위에 있는 값을 조회함
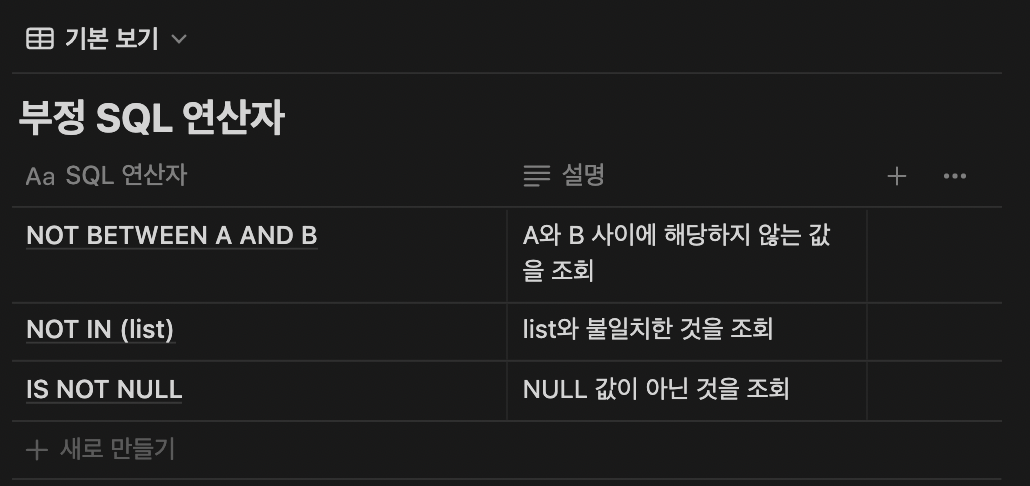
SELECT * FROM EMP WHERE SAL BETWEEN 1000 AND 2000;- SAL이 1000 이상 2000 이하 사이의 값을 조회함SELECT * FROM EMP WHERE SAL NOT BETWEEN 1000 AND 2000;- SAL이 1000 미만 2000 초과인 값을 조회함 -
IN: IN은 'OR'의 의미를 가지고 있어서 하나의 조건만 만족해도 조회가 됨
SELECT * FROM EMP WHERE JOB IN ('CLERK', 'MANAGER');- JOB 칼럼이 'CLERK'이거나 'MANAGER'인 레코드를 조회함SELECT * FROM EMP WHERE (JOB, NAME) IN (('CLERK','test1'),('MANAGER','test4'));- JOB 칼럼이 'CLERK'이거나 'MANAGER'인 레코드를 조회함 -
NULL 값 조회
1) NULL의 특징: 모르는 값을 의미함, 값의 부재를 의미함, NULL과 숫자 혹은 날짜를 더하면 NULL이 됨, NULL과 어떤 값을 비교할 때 '알 수 없음'이 반환됨
2) NULL값 조회: NULL을 조회할 경우는 IS NULL을 사용하고 NULL 값이 아닌 것을 조회할 경우 IS NOT NULL을 사용함
SELECT * FROM EMP WHERE MGR IS NULL;- MGR 칼럼이 NULL인 것을 조회함SELECT * FROM EMP WHERE MGR IS NOT NULL;- NULL값이 아닌 것을 조회함 -
NULL 관련 함수
1) NVL 함수: NULL이면 다른 값으로 바꾸는 함수, 'NVL(MGR, 0)'은 MGR 칼럼이 NULL이면 0으로 바꿈
2) NVL2 함수: NVL 함수와 DECODE 함수를 하나로 만든 것, 'NVL2(MGR, 1, 0)'은 MGR칼럼이 NULL이 아니면 1을, NULL이면 0을 반환함
3) NULLIF 함수: 두 개의 값이 같으면 NULL을, 같지 않으면 첫 번째 값을 반환함, 'NULLIF(exp1, exp2)'은 exp1과 exp2가 같으면 NULL을, 같지 않으면 exp1을 반환함
4) COALESCE: NULL이 아닌 최초의 인자 값을 반환함, 'COALESCE(exp1, exp2, exp3, ...)'은 exp1이 NULL이 아니면 exp1의 값을, 그렇지 않다면 그 뒤의 값의 NULL 여부를 판단하여 값을 반환함
-
-
GROUP 연산
-
GROUP BY: 테이블에서 소규모 행을 그룹화하여 합계, 평균, 최댓값, 최솟값 등을 계산할 수 있음
-
Having구에 조건문을 사용, ORDER BY를 사용해서 정렬 가능
SELECT DEPTNO, SUM(SAL) FROM EMP GROUP BY DEPTNO;- DEPTNO로 그룹을 만들고 그룹별 합계를 계산함
-
-
HAVING: GROUP BY에 조건절을 사용하려면 HAVING을 사용해야 함, WHERE절에 조건문을 사용하게 되면 조건을 충족하지 못하는 데이터들은 GROUP BY 대상에서 제외됨
SELECT DEPTNO, SUM(SAL) FROM EMP GROUP BY DEPTNO HAVING SUM(SAL) > 10000;- GROUP BY결과에서 급여합계가 10000 이상만 조회함 -
집계 함수
1) COUNT(): 행 수를 조회함
2) SUM(): 합계를 계산함
3) AVG(): 평균을 계산함
4) MAX(), MIN(): 최댓값과 최솟값을 계산함
5) STDDEV(): 표준편차를 계산함
6) VARIAN(): 분산을 계산함
-
COUNT 함수: 행 수를 계산하는 함수, COUNT(*)는 NULL 값을 포함한 모든 행 수를 계산하지만 COUNT(칼럼명)는 NULL값을 제외한 행 수를 계산함
SELECT COUNT(*) FROM EMP;- NULL을 포함한 전체 행수 계산 -
GROUP BY 사용 예제
(1) 부서별(DEPTNO), 관리자별(MGR)급여평균 계산
SELECT DEPTNO, MGR, AVG(SAL) FROM EMP GROUP BY DEPTNO, MGR;- AVG(SAL): 급여 평균 계산 / GROUP BY로 부서별, 관리자별 소그룹을 만듦(2) 직업별 급여합계중 급여합계가 1000이상인 직업
SELECT JOB, SUM(SAL) FROM EMP GROUP BY JOB HAVING SUM(SAL) >=1000;- HAVING 구에 조건을 넣음(3) 사원번호 1000~1003번의 부서별 급여합계
SELECT DEPTNO, SUM(SAL) FROM EMP WHERE EMPNO BETWEEN 1000 and 1003 GROUP BY DEPTNO;- HAVING 구에 조건을 넣음 -
SELECT문 실행 순서
→ FROM, WHERE, GROUP BY, HAVING, SELECT, ORDER BY 순으로 실행됨
SELECT ename FROM emp WHERE empno = 12 GROUP BY ename HAVING count(*)>=1 ORDER BY ename; -
명시적(Explicit) 형변환과 암시적(Implicit) 형변환
- 형변환: 두 개의 데이터의 데이터 타입(형)이 일치하도록 변환하는 것
- 명시적 형변환: 형변환 함수를 사용해서 데이터 타입을 일치시키는 것으로 개발자가 SQL을 사용할 때 형변환 함수를 사용해야 함
- 형변환 함수 1) TO_NUMBER(문자열): 문자열을 숫자로 변환 2) TO_CHAR(숫자 혹은 날짜, [FORMAT]): 숫자 혹은 날짜를 지정된 FORMAT의 문자로 변환 3) TO_DATE(문자열, FORMAT): 문자열을 지정된 FORMAT의 날짜형으로 변환
- 암시적 형변환: 개발자가 형변환을 하지 않은 경우 DBMS가 자동으로 형변환하는 것
- 인덱스 칼럼에 형변환을 수행하면 인덱스를 사용하지 못함
-
내장형 함수(BUILT-IN FUNCTION)
- 모든 데이터베이스는 SQL에서 사용할 수 있는 내장형 함수를 가짐
- 내장형 함수는 DBMS 벤더별로 약간의 차이가 있지만, 거의 비슷한 방법으로 사용 가능
- 내장형 함수로는 앞서 배운 형변환 함수, 문자열 및 숫자형 함수, 날짜형 함수가 있음
-
DUAL 테이블: Oracle 데이터베이스에 의해서 자동으로 생성되는 테이블
-
Oracle 데이터베이스 사용자가 임시로 사용할 수 있는 테이블로 내장형 함수를 실행할 때도 사용할 수 있음
DESC DUAL;-
Oralce은 기본적으로 DUAL 테이블이라는 Dummy 테이블이 존재
-
내장형 함수의 종류
- DUAL 테이블에 문자형 내장형 함수를 사용하면 다음과 같음
SELECT ASCII('a'), SUBSTR('ABC',1,2), LENGTH('A BC'), LTRIM(' ABC'), LENGTH(LTRIM(' ABC')) FROM DUAL;d - ASCII 함수는 문자에 대한 ASCII 코드 값을 알려줌, ASCII 코드는 대문자A를 기준으로 A(65), B(66) 등의 값
- SUBSTR 함수는 지정된 위치의 문자열을 자르는 함수
- LENGTH함수, LEN함수는 문자열의 길이를 계산함
- LTRIM 함수를 사용하면 문자열의 왼쪽 공백을 제거할 수 있음
- 함수를 중첩해서 사용 가능 → LENGTH(LTRIM(' ABC'))
- DUAL 테이블에 문자형 내장형 함수를 사용하면 다음과 같음
-
문자열 함수
1) ASCII(문자): 문자 혹은 숫자를 ASCII 코드값으로 변환함
2) CHAR(ASCII 코드값): ASCII 코드값을 문자로 변환함
3) SUBSTR(문자열,m,n): 문자열에서 m번째 위치부터 n개를 자름
4) CONCAT(문자열1, 문자열2): 문자열1과 문자열2를 결합함, Oracle은 '||', MS-SQL은'+' 사용
5) LOWER(문자열): 영문자를 소문자로 변환함
6) UPPER(문자열): 영문자를 대문자로 변환함
7) LENGTH 혹은 LENGTH(문자열): 공백을 포함해서 문자열의 길이를 알려줌
8) LTRIM(문자열, 지정된 문자): 왼쪽에서 지정된 문자 삭제, 지정된 문자를 생략하면 공백 삭제
9) RTRIM(문자열, 지정된 문자): 오른쪽에서 지정된 문자 삭제, 지정된 문자를 생략하면 공백 삭제
10) TRIM(문자열, 지정된 문자): 왼쪽 및 오른쪽에서 지정된 문자를 삭제, 지정된 문자를 생략하면 공백 삭제
-
날짜형 함수
1) SYSDATE: 오늘의 날짜를 날짜 타입으로 알려줌
2) EXTRACT('YEAR' | 'MONTH' | 'DAY' from dual): 날짜에서 년, 월, 일을 조회함
-
TO_CHAR는 형변환 함수 중 가장 많이 사용하는 것으로 숫자나 날짜를 원하는 포맷의 문자열로 변환
SELECT SYSDATE, EXTRACT(YEAR From sysdate), TO_CHAR(SYSDATE, 'YYYYMMD') FROM DUAL;- SYSDATE: 오늘 날짜를 Date 타입으로 알려줌 / EXTRACT(YEAR From sysdate): 오늘 날짜에서 연도를 구함 / TO_CHAR(SYSDATE, 'YYYYMMD': 오늘 날짜를 구하면 지정한 변환포맷의 문자형으로 변환함
-
-
숫자형 함수
1) ABS(숫자): 절댓값을 돌려줌
2) SIGN(숫자): 양수, 음수, 0을 구별함
3) MOD(숫자1, 숫자2): 숫자1을 숫자2로 나누어 나머지를 계산함, %를 사용해도 됨
4) CEIL/CEILINING(숫자): 숫자보다 크거나 같은 최소의 정수를 돌려줌
5) FLOOR(숫자): 숫자보다 작거나 같은 최대의 정수를 돌려줌
6) ROUND(숫자,m): 소수점 m자리까지 반올림, m의 기본값은 0
7) TRUNIC(숫자,m): 소수점 m자리까지 절삭, m의 기본값은 0
SELECT ABS(-1), SIGN(10), MOD(4,2), CEIL(10.9), FLOOR(10.1), ROUND(10.222,1) FROM DUAL;- SYSDATE: 오늘 날짜를 Date 타입으로 알려줌 / EXTRACT(YEAR From sysdate): 오늘 날짜에서 연도를 구함 / TO_CHAR(SYSDATE, 'YYYYMMD': 오늘 날짜를 구하면 지정한 변환포맷의 문자형으로 변환함 -
DECODE: DECODE문으로 IF문을 구현할 수 있음 (특정조건이 참이면 A, 거짓이면 B로 응답)
SELECT DECODE(EMPNO, 1000, 'TRUE', 'FALSE') FROM EMP;- 비교문으로 EMPNO = 1000과 같으면 TRUE를 응답하고 다르면 FALSE를 응답함 -
CASE: IF~THEN~ELSE~END의 프로그래밍 언어처럼 조건문을 사용할 수 있음, 조건을 WHEN구에 사용하고 해당 조건이 참이면 THEN이 실행되고 거짓이면 ELSE가 실행됨
SELECT CASE WHEN EMPNO = 1000 THEN 'A' WHEN EMPNO = 1001 THEN 'B' ELSE 'C' END FROM EMP;- EMPNO와 1000, 1001을 비교하여 1000이면 'A' 출력, 1001이면 'B' 출력, 그렇지 않으면 'C' 출력 -
ROWNUM
-
ROWNUM은 SELECT문 결과에 대해서 논리적인 일련번호를 부여함
-
조회되는 행수를 제한할 때 많이 사용됨
-
화면에 데이터를 출력할 때 부여되는 논리적 순번, ROWNUM을 사용해서 페이지 단위 출력을 하기 위해서는 인라인 뷰(Inline viw)를 사용
-
인라인뷰: SELECT문에서 FROM절에 사용되는 서브쿼리(Sub Query)
SELECT * FROM EMP WHERE ROWNUM <=1;- 한 행을 조회함
SELECT * FROM (SELECT ROWNUM list, ENAME FROM EMP) WHERE list <=5;- FROM절에 SELECT문을 사용하면 inline view / ROWNNUM에 별칭 사용 / 5건의 행을 조회
-
ROWNUM과 BETWEEN구를 사용해 웹 페이지 조회를 구현
SELECT * FROM ( SELECT ROWNUM list, ENAME FROM EMP) WHERE list BETWEEN 5 AND 10;- 특정 행만 조회
-
-
ROWID
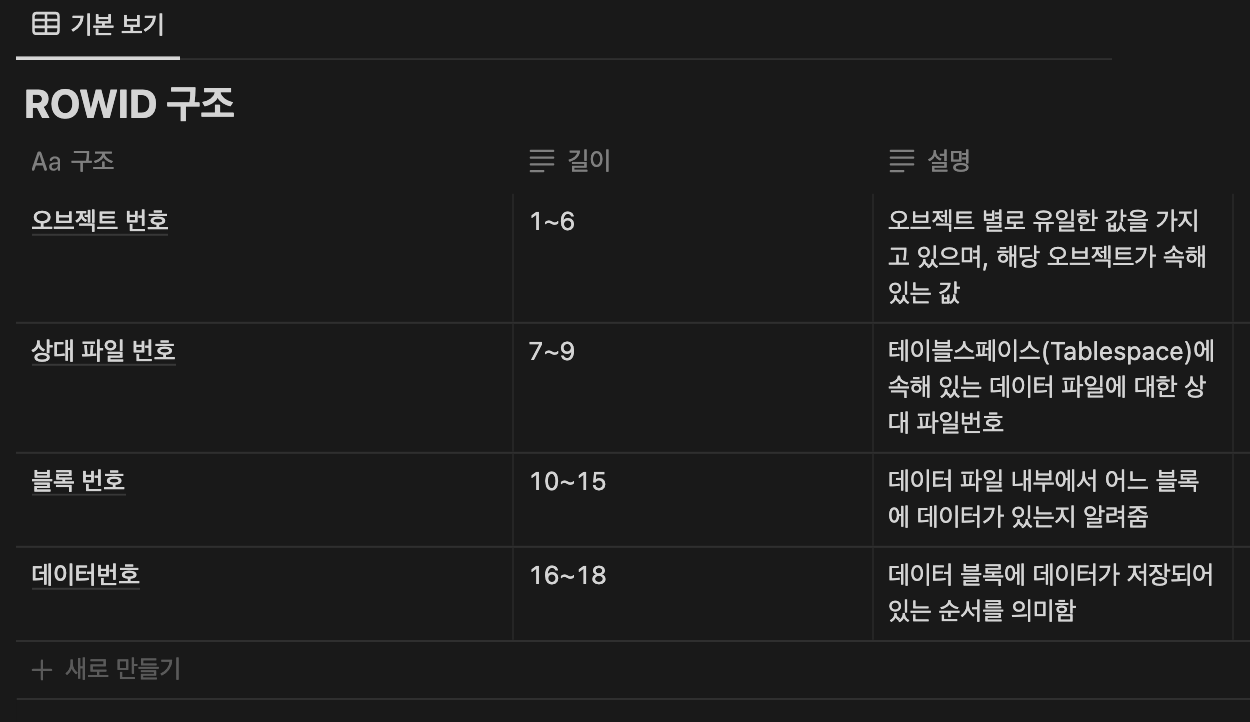
- ORACLE 데이터베이스 내에서 데이터를 구분할 수 있는 유일한 값
- "SELECT ROWID, EMPNO FROM EMP"와 같은 SELECT문으로 확인할 수 있음
- ROWID를 통해 데이터가 어떤 데이터 파일, 어느 블록에 저장되어 있는지 알 수 있음
-
ROWID 구조
- WITH구문
-
서브쿼리(Subquery)를 사용해서 임시 테이블이나 뷰처럼 사용할 수 있는 구문
-
서브쿼리 블록에 별칭을 지정할 수 있음
-
옵티마이저는 SQL을 인라인 뷰나 임시 테이블로 판단함
WITH viewData AS (SELECT * FROM EMP UNION ALL SELECT * FROM EMP ) SELECT * FROM viewData WHERE EMPNO=1000;
-
DCL(Data Control Language)
1) GRANT: 데이터베이스 사용자에게 권한을 부여함, 데이터베이스 사용을 위해서는 권한이 필요하며 연결, 입력, 수정, 삭제, 조회 가능
GRANT privileges ON object TO user;-
Privileges(권한)
1) SELECT: 지정된 테이블에 SELECT 권한 부여
2) INSERT: 지정된 테이블에 INSERT 권한 부여
3) UPDATE: 지정된 테이블에 UPDATE 권한 부여
4) DELETE: 지정된 테이블에 DELETE 권한 부여
5) REFERENCES: 지정된 테이블을 참조하는 제약조건을 생성하는 권한을 부여함
6) ALTER: 지정된 테이블에 수정할 수 있는 권한 부여
7) INDEX: 지정된 테이블에 인덱스를 생성할 수 있는 권한 부여
8) ALL: 테이블에 대한 모든 권한 부여
GRANT SELECT, INSERT, UPDATE, DELETE ON EMP TO LIMBEST;- SELECT~DELETE: 부여되는 권한, LIMBEST 사용자에게 EMP 테이블에 대해서 SELECT~DELETE 권한을 부여함
-
WITH GRANT OPTION: 특정 사용자에게 권한을 부여할 수 있는 권한을 부여, 권한을 A 사용자가 B에 부여하고 B가 다시 C를 부여한 후에 권한을 취소(Revoke)하면 모든 권한이 회수됨
-
WITH ADMIN OPTION: 테이블에 대한 모든 권한을 부여, 권한을 A 사용자가 B에 부여하고 B가 다시 C에게 부여한 후에 권한을 취소하면 B사용자 권한만 취소됨
GRANT SELECT, INSERT, UPDATE, DELETE, ON EMP TO LIMBEST WITH GRANT OPTION;- 권한을 부여할 수 있는 권한을 부여
2) REVOKE: 데이터베이스 사용자에게 부여된 권한을 회수함
REVOKE privileges ON object FROM user;TCL(Transaction Control Language)
1) COMMIT
-
COMMIT은 INSERT, UPDATE, DELETE문으로 변경한 데이터를 데이터베이스에 반영
-
변경 전 이전 데이터는 잃어버림, 즉 A값을 B로 변경하고 COMMIT을 하면 A값은 잃어버리고 B값을 반영함
-
다른 모든 데이터베이스 사용자는 변경된 데이터를 볼 수 있음
-
COMMIT이 완료되면 데이터베이스 변경으로 인한 LOCK이 해제(UNLOCK)됨
-
COMMIT이 완료되면 다른 모든 데이터베이스 사용자는 변경된 데이터를 조작할 수 있음
-
COMMIT을 실행하면 하나의 트랜잭션 과정을 종료함
-
DDL 및 DCL을 사용하는 경우엔 자동 COMMIT됨
2) ROLLBACK
-
ROLLBACK을 실행하면 데이터에 대한 변경 사용을 모두 취소하고 트랜잭션을 종료함
-
INSERT, UPDATE, DELETE문의 작업을 모두 취소함, 이전에 COMMIT한 곳까지만 복구함
-
ROLLBACK을 실행하면 LOCK이 해제되고 다른 사용자도 데이터베이스 행을 조작할 수 있음
3) SAVEPOINT(저장점)
-
SAVEPOINT는 트랜잭션을 작게 분할하여 관리하는 것으로 SAVEPOINT를 사용하면 지정된 위치 이후의 트랜잭션만 ROLLBACK할 수 있음
-
SAVEPOINT의 지정은 SAVEPOINT <SAVEPOINT명>을 실행함
-
지정된 SAVEPOINT까지만 데이터 변경을 취소하고 싶은 경우 "ROLLBACK TO <SAVEPOINT명>을 실행
-
"ROLLBACK"을 실행하면 SAVEPOINT와 관계없이 데이터의 모든 변경사항을 저장하지 않음
