
퀵 정렬 !?
- 분할 정복 방법을 통해 주어진 배열을 정렬한다.
- 분할 정보 : 문제를 작은 2개의 문제로 분리하고 각각을 해결 한 다음, 결과를 모아서 원래의 문제를 해결하는 전략 - 불안정 정렬에 속하며, 다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬이다.
- 불안정 정렬에는 퀵과 삽입 정렬이 있다.
- Merge Sort와 다르게 Quick Sort는 배열을 비균등하게 분할한다.
로직
- 배열 가운데서 하나의 원소를 고른다. 이를 피벗이라고 한다.
- 피벗 앞에는 피벗보다 값이 작은 모든 원소들이 오고, 피벗 뒤에는 피벗보다 값이 큰 모든 원소들이 오도록 피벗을 기준으로 배열을 둘로 나눈다. 이렇게 배열을 둘로 나누는 것을 분할이라고 한다. 분할을 마친 뒤에 피벗은 더 이상 움직이지 않는다.
- 분할 된 두 개의 작은 배열에 대해 재귀적으로 이 과정을 반복한다.
재귀 호출이 한 번 진행 될 때 마다 최소한 하나의 원소는 최종적으로 위치가 정해져있음으로, 이 알고리즘은 반드시 끝난다는 것을 보장할 수 있다.
- 분할 : 주어진 배열을 피벗을 기준으로 비균등하게 2개의 부분 배열로 분할한다. (피벗 중심으로 왼쪽: 피벗 보다 작은 요소들, 오른쪽 : 피벗보다 큰 요소들)
- 정복 : 부분 배열을 정리한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출을 이용해 다시 분할 정복 방법을 적용한다.
private static void quickSort(int[] arr, int left, int right)}
int L = left;
int R = right;
int pivot = arr[(left+right)/2]; //가운데 요소 피벗 지정
while(L <= R){
//피벗 왼쪽에는 피벗보다 작은 원소들이 위치해야 하고, 큰 원소강 있다면 반복문을 나온다.
while(arr[L]<pivot) L++;
//피벗 오른쪽에는 피벗보다 큰 원소들이 위치해야 하고, 작은 원소가 있따면 반복문을 나온다.
while(arr[R]>pivot) R--;
//L과 R이 역전되지 않고, 같은 경우가 아니라면 두 원소는 위치를 교환한다.
//이를 통해 피벗 기준으로 왼쪽에는 작은 원소가, 오른쪽에는 큰 원소가 위치하게 된다.
if(L <= R){
if(L != R){
swap(arr, L, R);
}
L++;
R--;
}
}
//L과 R이 역전된 후에 피벗의 왼쪽과 오른쪽에는 정렬되지 않은 부분 배열이 남아있을 수 있따.
// 이 경우, 남아있는 부분 배엘애 대해 퀵 정렬을 수행한다.
if(left<R) quickSort(arr,left, R);
if(L<right) quickSort(arr,L,R);
}
private static void swap(int[] arr, int left, int right){
int temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
}퀵 정렬 개선
- 피벗을 배열의 가운데 원소로 지정함으로써 어느 정도 성능을 개선한 상태이다.
- 하지만, 피벗 값이 최소나 최대 값으로 지정되면 피벗을 기준으로 원소들이 들어갈 값을 찾는데 오래 걸린다. 이 경우 시간복잡도가 O(N^2)이다.
- 즉, 정렬하고자 하는 배열이 오름차순 혹은 내림차순 정렬되어 있다면 O(N^2)의 시간복잡도를 가진다. 이때, 배열에서 가장 앞에 있는 값과 중간 값을 교환해준다면 확률적으로나만 시간 복잡도를 O(NlogN)으로 개선할 수 있다.
하지만, 이 방법으로 개선하더라도 퀵 정렬의 최악의 시간 복잡도가 O(NlogN)이 되는 것은 아니다.
시간 복잡도
- 최선의 경우 : T(N) = O(NlogN)
- 비교 횟수 : logN
레코드의 개수 N이 2의 거듭제곱이라고 가정했을 때, N=2^3의 경우
2^3 -> 2^2 -> 2^1 -> 2^0으로 줄어들어 순환 호출의 깊이가 3이다.
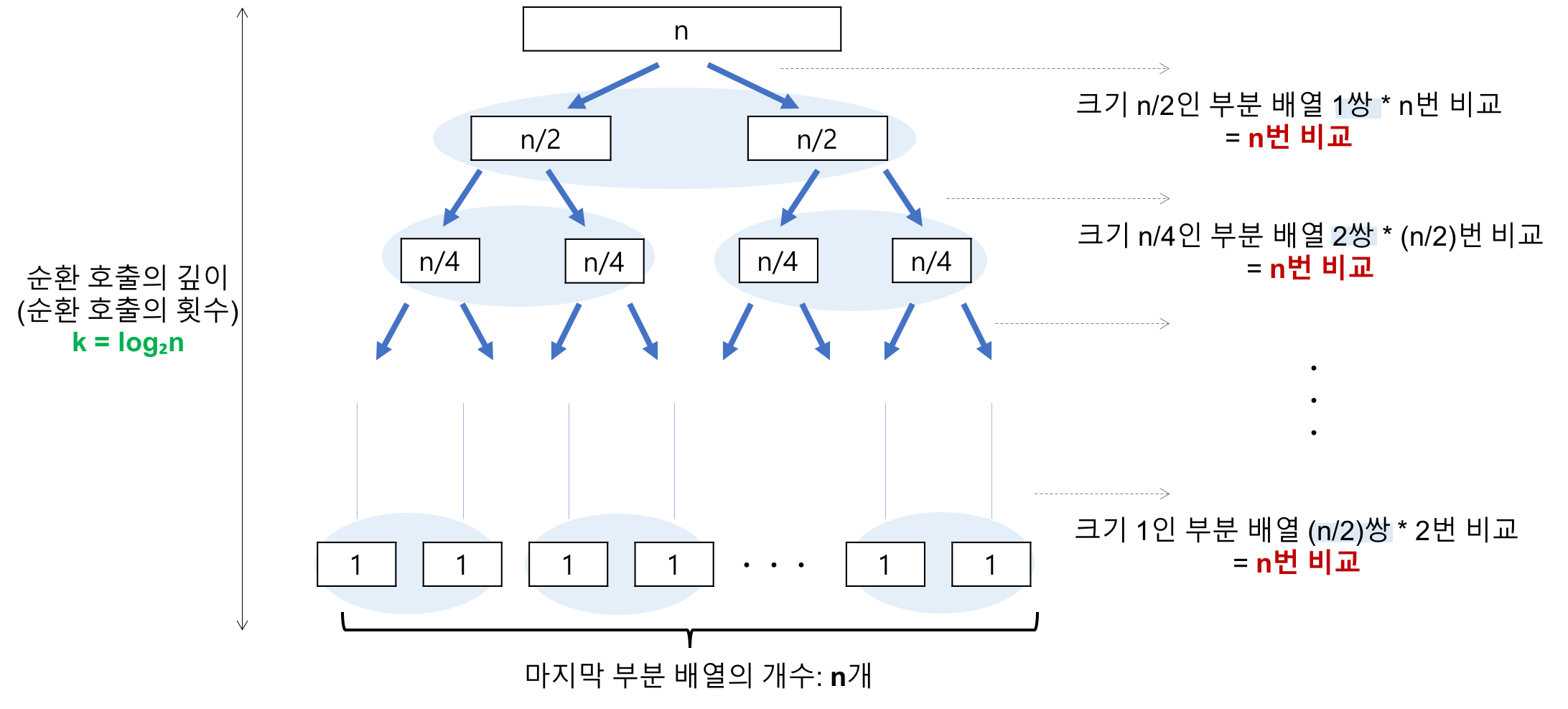
즉, N=2^k의 경우, k=logN이다.
각 순환 호출 단계의 비교 연산
각 순환 호출에서는 전체 리스트의 대부분의 레코드를 비교해야 하므로 평균 N번 정도 비교가 이루어진다.
따라서, 최선의 시간 복잡도는 순환 호출의 깊이(logN) x 각 순환 호출 단계의 비교 연산(n) = nlogn이 된다.
이동 횟수는 비교 횟수보다 적으므로 무시할 수 있다.
최악의 경우 : T(N) = O(N^2)
최악의 경우는 정렬하고자 하는 배열이 오름차순 혹은 내림차순 정렬되어 있는 경우이다.
비교 횟수 : (N)
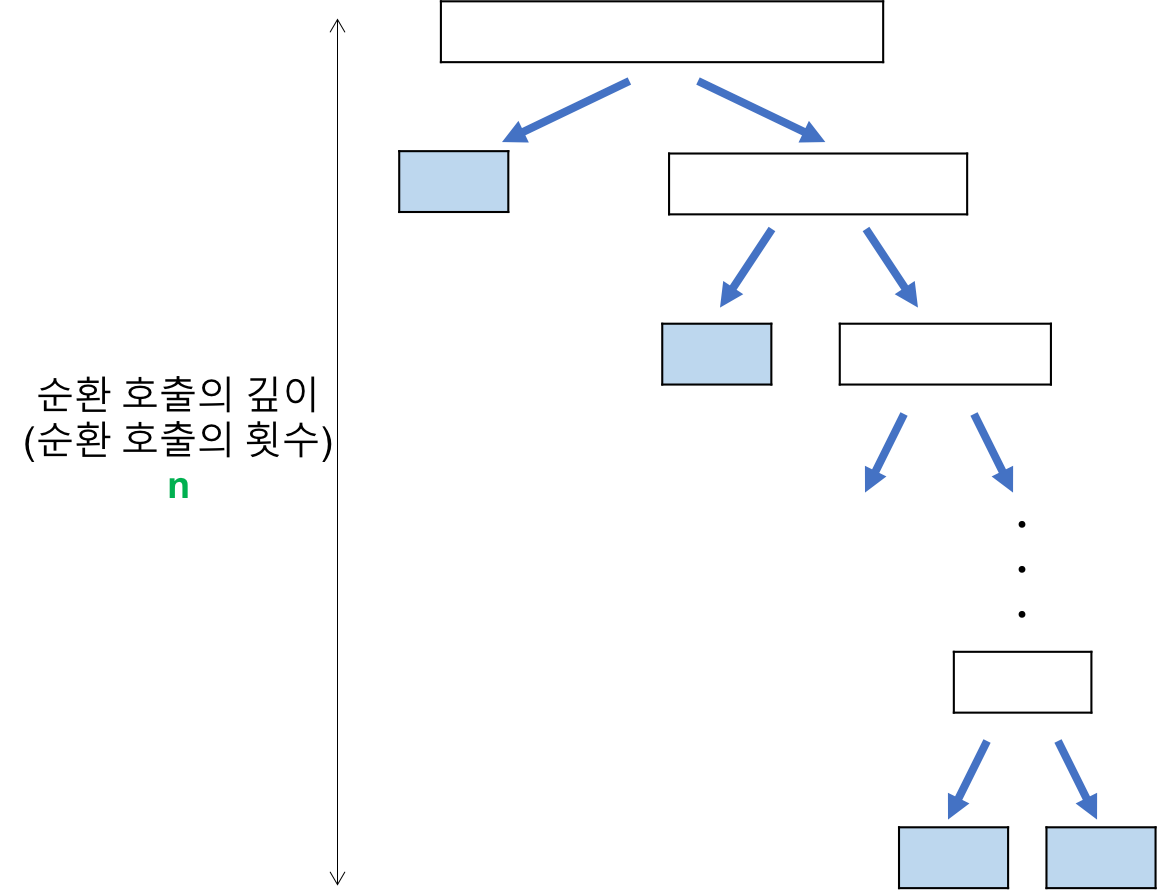
레코드의 개수 N이 2의 거듭제곱이라고 가정할 때, 순환 호출의 깊이는 N이다.
- 각 순환 호출 단계의 비교 연산
: 각 순환 호출에서는 전체 리스트의 대부분의 레코드를 비교해야 하므로 평균 N번 정도 비교가 이루어진다.
: 따라서 최악의 시간 복잡도는순환 호출의 깊이 x 각 순환 호출 단계의 비교 연산 = N^2이다.
: 이동 횟수는 비교 횟수보다 적으므로 무시할 수 있다.
공간 복잡도
- 주어진 배열 안에서 교환을 통해 정렬이 이루어짐으로 O(N)이다.
장점
- 불필요한 데이터의 이동을 줄이고 먼 거리의 데이터를 교환 할 뿐 아니라, 한번 결정된 피벗들이 추후 연산에서 제외되는 특성 때문에 시간 복잡도가 O(NlogN)을 가지는 다른 정렬 알고리즘과 비교했을 때도 가장 빠르다.
- 정렬하고자 하는 배열안에서 교환하므로 추가적으로 메모리 공간이 필요하지 않다.
단점
- 불안정 정렬이다.
- 정렬된 배열에 대해서는 Quick Sort의 불균형 분할에 의해 오히려 수행 시간이 더 많이 걸린다.
결론
Quick Sort는 평균적으로 가장 빠른 정렬 알고리즘이다.
Arrays.sort()를 할때 내부적으로 Dual Pivot Quick Sort라고 ..
Reference

developer