RNN이란?
- RNN(Recurrent Neural Network)은 입력과 출력을 시퀀스 단위로 처리하는 시퀀스(Sequence) 모델
- 순환 신경망(Recurrent Neural Network)은 시퀀스(seqence) 데이터를 사용
- 시퀀스 데이터란 시계열 데이터라고도 한다.
- 시점에 따라 데이터가 달라지는 것을 의미
- 텍스트와 같이 순서에 의미가 있는 데이터도 시퀀스 데이터
- 즉, 특정 시점의 데이터를 한 번에 수집하는 것이 아닌 시간의 흐름에 따라 데이터도 점차 수집하는 것을 의미
- 전체 데이터 셋을 구성하는 각 데이터 포인트의 수집 시점이 서로 다름
다른 신경망들과 다른점
- 순환 신경망은 출력된 결과가 다음 시점에서 사용됨. 출력 결과를 기억했다가 사용하는 방법
- 완전 연결 신경망이나 합성곱 신경망은 입력 데이터를 사용한 후 그 결과가 다시 입력층으로 돌아가진 않음
- 이를 피드포워드(feedforward) 신경망이라고 부름
텍스트 데이터는 단어의 순차가 중요한 데이터기 때문에 이러한 데이터는 순서를 유지하며 신경망에 주입해야 함. 단어의 순서가 마구 섞여서는 안됨
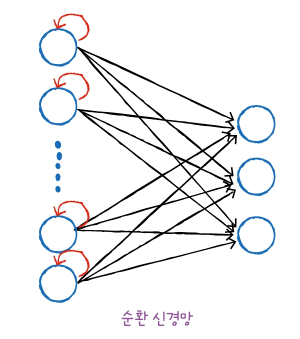
다음 샘플을 위해서 이전 데이터가 신경망 층에 순환될 필요가 있음. 이러한 신경망이 순환 신경망
완전 연결 신경망에 이전 데이터의 처리 흐름을 순환하는 고리 하나만 추가
- 순환신경망 예시
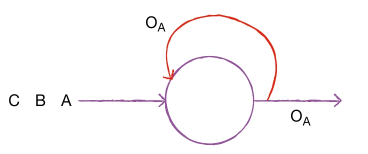
- 위 그림에서 첫 번째 샘플 A를 처리하고 난 출력 이 다시 뉴런으로 들어감
- 이 출력에는 A에 대한 정보가 다분히 들어 있음. 그 다음 B를 처리할 때 앞에서 A를 사용해 만든 출력 를 함께 사용함
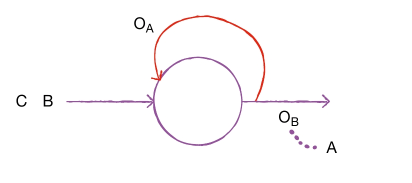
- 와 B를 사용해서 만든 에는 A에 대한 정보가 어느 정도 포함되어 있음. 그 다음 C를 처리할 때는 를 함께 사용
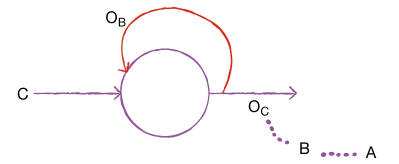
- 를 사용했으므로 당연히 B에 대한 정보가 어느 정도 포함되어 있을 것이며, 또 에는 A에 대한 정보도 포함되어 있음
- 따라서 에 B와 A에 대한 정보가 담겨 있다고 말할 수 있음
이렇게 샘플을 처리하는 한 단계를 타입스텝(timestep)이라고 말함
순환 신경망에서는 특별히 층을 셀(cell)이라 부름
한 셀에는 여러 개의 뉴런이 있지만 완전 연결 신경망과 달리 뉴런을 모두 표시하지 않고 하나의 셀로 층을 표시
셀의 출력을 은닉 상태(hidden state)라 부름
순환 신경망 구조
순환 신경망의 뉴런은 가중치가 하나 더 있음. 이전 타임스템의 은닉 상태에 곱해지는 가중치
셀은 입력과 이전 타입스텝의 은닉 상태를 사용하여 현재 타임스텝의 은닉 상태를 만듦.
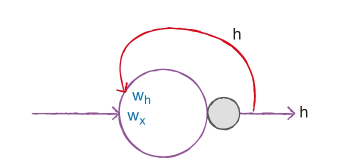
- 위의 그림에서 는 입력에 곱해지는 가중치이고 는 이전 타임스텝의 은닉 상태에 곱해지는 가중치다. 피드포워드 신경망과 마찬가지로 뉴런마다 하나의 절편이 포함되어 있지만 따로 표기하지 않는다.
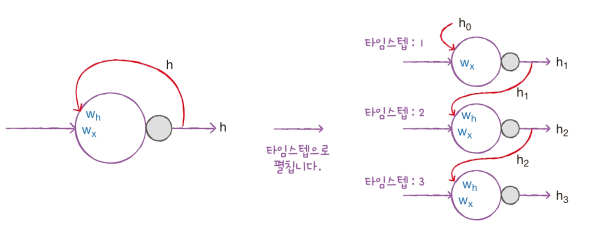
셀의 출력(은닉 상태)이 다음 스템에 재사용되기 때문에 타임스텝으로 셀을 나누어 그릴 수 있음
위 그림을 셀을 타임스텝으로 펼쳤다라고 말함
- 모든 타임스텝에서 사용되는 가중치는 1개
- 가중치 는 타임스텝에 따라 변화되는 뉴런의 출력을 학습합니다.
- 맨 처음 타임스텝 1에서 사용되는 이전 은닉 상태 은 입력할 이전 타임스텝이 없기 때문에 0으로 초기화합니다.
셀의 가중치와 입출력
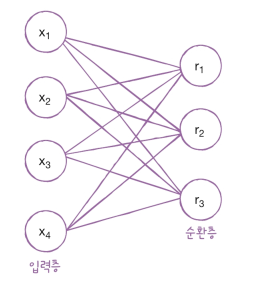
- 순환층에 입력되는 특성의 개수 4개, 순환층의 뉴런이 3개
- 의 크기
- 입력층과 순환층의 뉴런이 모두 완전 연결되기 때문에 가중치 의 크기는 4 x 3 = 12
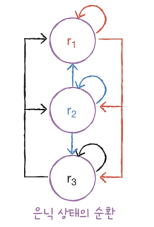
- 순환층에 있는 첫 번째 뉴런 은 은닉 상태가 다음 타임스텝에 재사용될 때 첫 번째 뉴런과 두 번째 뉴런, 세 번째 뉴런에 모두 전달됨
- 이전 타임스텝의 은닉 상태는 다음 타임스텝의 뉴런에 완전이 연결됨
- 이 순환 층에서 은닉 상태를 위한 가중치 는 3 x 3 = 9
- 즉, 이 순환층은 모두 12 + 9 + 3 = 24개의 모델 파라미터를 가짐
- 편향을 가지기 때문에 3을 더해줌
순환 신경망의 활성화 함수
-
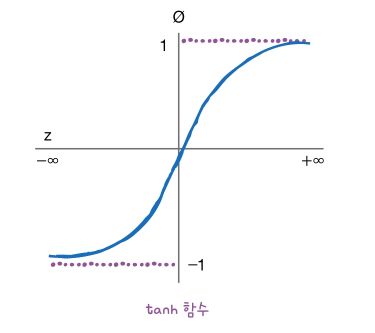
일반적으로 은닉층의 활성화 함수로 하이퍼볼릭 탄젠트 함수인 Tanh가 많이 사용됨
-
시그모이드와 Tanh 함수는 왜 그래디언트 소실 현상을 일으키는가?
그래디언트 소실 현상이란?
기울기 소실(Vanishing Gradient)이란 역전파(Backpropagation) 과정에서 출력층에서 멀어질수록 Gradient 값이 매우 작아지는 현상
-
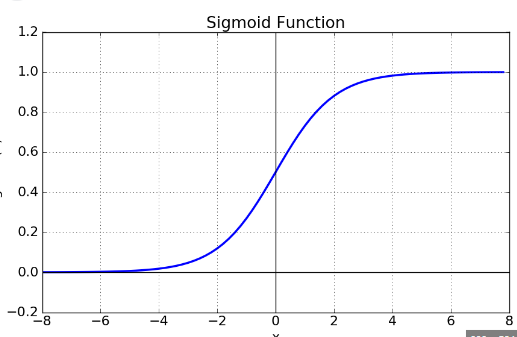
시그모이드 함수의 그림에서 알수 있듯이 값이 매우 크거나, 작을 때 출력 값은 0에 가까움
-
시그모이드 함수를 미분하면 가 되는데 z가 매우 크거나 매우 작을 때 모두 0에 근사하게 되어 그래디언트 소실 현상이 일어남
-
tanh 함수도 시그모이드와 비슷한 구조를 가지고 있고 미분하면 값을 갖고 z의 값이 매우 크거나 작을 때 모두 0에 근사하게 되어 시그모이드처럼 그래디언트 소실 현상이 발생
ReLU 계열의 활성화 함수 장점 (시그모이드, Tanh 활성화 함수와 비교했을 때)
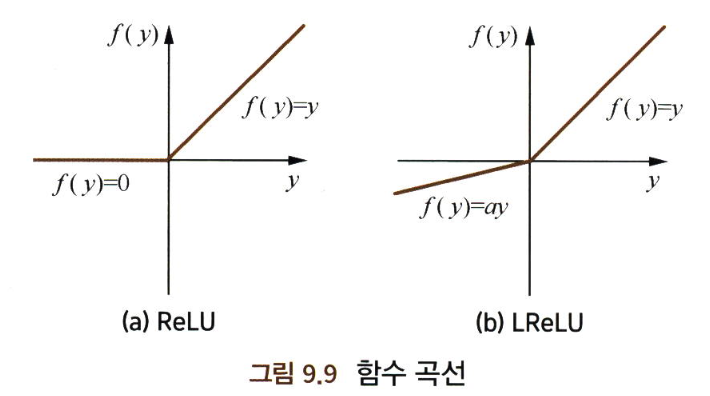
- 장점
- 계산적 관점에서 보면 시그모이드와 tanh 활성화 함수는 평균적으로 복잡도가 높으나, ReLU 활성화 함수는 하나의 임계치만 있으면 활성화 값을 얻을 수 있음
- ReLU의 비포화성(non-saturation)은 그래디언트 소실 문제를 효과적으로 해결하고, 상대적으로 넓은 활성화 경계를 제공
- ReLU의 단측면 억제가 네트워크의 희소 표현 능력을 제공
.- 한계점
- 훈련 과정에서 뉴런들이 죽는 문제가 발생
- 음의 그래디언트가 ReLU 유닛을 경과할 때 0이 되어 버려 이후에 어떤 데이터로 활성화되지 않기 때문에, 해당 뉴런을 지나는 그래디언트는 영원히 0이 되어 다른 데이터에 영향을 미치지 않는 것을 의미
- 실제 훈련 과정에서 학습률을 크게 설정하면 일정 비율의 뉴런이 사망해 파라미터 그래디언트를 업데이트할 수 없어 훈련 과정이 실패하는 경우가 발생
- 이런 문제를 해결하기 위해서 Leaky ReLU를 사용하기도 함
순환 신경망에서 ReLU함수를 사용할 수 있지만, 행렬 초깃값에 대한 일정한 제한을 둬야 한다. 그렇지 않으면 수치 문제가 더 쉽게 발생됨
- 순환신경망의 그래디언트 계산 공식에서 ReLU 함수를 사용하고 시작할 때 뉴런이 모두 활성화 상태에 있다고 가정하면 는 단위행렬이 되고 계산된 값은 W가 된다.
- 그래디언트가 n개 층을 거친 후 값은 이 된다. 따라서 ReLU 함수를 활성화 함수로 사용한다고 하더라도 W가 단위행렬이 아니면 그래디언트가 소실 혹은 폭발하는 현상이 일어난다.
- 순환신경망에서 ReLU 함수를 은닉층의 활성화 함수로 사용한다면, W의 값이 단위행렬로 근사할 때 비교적 좋은 효과를 얻을 수 있음. 따라서 W를 단위행렬로 초기화해야 함
- W를 단위행렬로 초기화하고 ReLU 활성화 함수를 사용하면 LSTM 모델과 비슷한 결과를 얻을 수 있는 반면, 학습 속도가 LSTM 모델보다 더 빠름
순환 신경망 실습
- IMDB 리뷰 데이터셋
자연어 처리 분야에서는 훈련 데이터를 말뭉치(Corpus)라고 부름
컴퓨터는 숫자 데이터만을 전달하기 때문에 텍스트 데이터를 다룰 때는 텍스트 자체를 신경망에 전달하지 않는다.
텍스트 데이터의 경우 단어를 숫자 데이터로 바꾸는 일반적인 방법은 데이터에 등장하는 단어마다 고유한 정수를 부여하는 것이다.
분리된 단어를 토큰(token)이라고 부름
하나의 샘플은 여러 개의 토큰으로 이루어져 있고, 1개의 토큰이 하나의 타임스탬프에 해당함
from tensorflow.keras.datasets import imdb
(train_input, train_target), (test_input, test_target) = imdb.load_data(num_words=500)
# 훈련데이터와 테스트 데이터의 리뷰 중 가장 자주 등장하는 상위 500개의 단어만을 사용
print(train_input.shape, test_input.shape) # 훈련데이터와 테스트데이터의 크기와 차원 정보 확인
from sklearn.model_selection import train_test_split
import numpy as np
# 데이터셋을 훈련과 검증 데이터셋으로 분리
train_input, val_input, train_target, val_target = train_test_split(train_input, train_target, test_size=0.2, random_state=42)
lengths = np.array([len(x) for x in train_input])
# 단어들의 평균 길이와 중앙값을 출력
print(np.mean(lengths), np.median(lengths))
# 정답값을 확인
# 0-> 부정, 1-> 긍정
print (train_target[:20])
# 받은 데이터셋의 샘플별로 길이를 히스토그램을 그려서 파악
import matplotlib.pyplot as plt
plt.hist(lengths)
plt.xlabel('length')
plt.ylabel('frequency')
plt.show()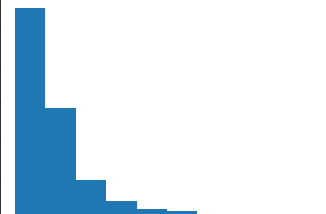
from tensorflow.keras.preprocessing.sequence import pad_sequences
train_seq = pad_sequences(train_input, maxlen=100)
val_seq = pad_sequences(val_input, maxlen=100)
* 리뷰의 데이터를 100개의 단어만 사용하여 모델을 생성
* 리뷰 데이터를 길이가 100이 되도록 잘라내거나 0으로 패딩
* pad_sequences() 함수가 제공
* 길이를 100으로 설정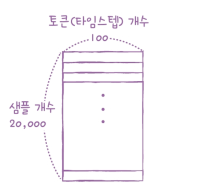
- 데이터가 길이보다 작으면 0으로 패딩
- 데이터가 긴 시퀀스는 앞부분을 자름 / 대체적으로 시퀀스의 뒷부분 정보가 더 유용하다고 기대
순환 신경망 만들기
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.SimpleRNN(8, input_shape=(100, 500)))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
train_oh = keras.utils.to_categorical(train_seq)
val_oh = keras.utils.to_categorical(val_seq)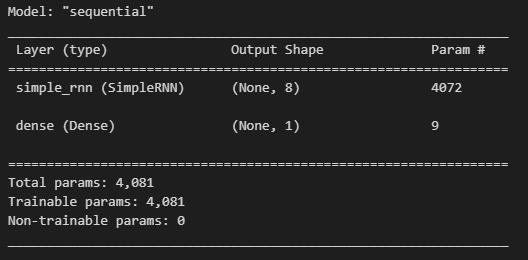
- 입력 토큰은 500차원의 원-핫 인코딩 배열
- 이 배열이 순환층의 뉴런 8개와 완전히 연결되기 때문에 총 500 x 8 = 4000
- 이 은닉 상태도 순환층의 뉴런과 완전히 연결되기 때문에 8(은닉 상태 크기) x 8(뉴런의 개수) = 64개의 가중치가 필요
- 4,000 + 64 + 8 = 4072
- 출력층에서는 하나의 출력 1로 8개의 은닉층의 모으기 때문에 8개 + 1개의 편향 = 9
훈련하기
# RMSprop 옵티마이저 생성 후 학습률을 설정
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
# ModelCheckpoint 콜백 생성하여 훈련 중에 모델의 가중치를 저장
# EarlyStopping 콜백을 생성하여 3번의 에포크 동안 향상되지 않으면 훈련 종료
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-simplernn-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
# 모델 훈련
history = model.fit(train_oh, train_target, epochs=100, batch_size=256,
validation_data=(val_oh, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])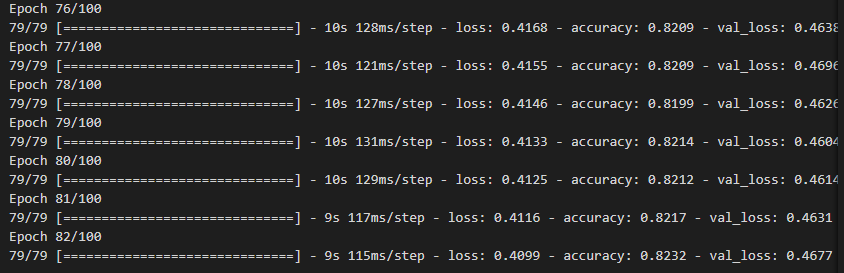
단어 임베딩
단어 임베딩(word embedding)이란?
- 임베딩(embedding)이란
- 사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자의 나열인 벡터로 변환한 값 혹은 그 일련의 과정 전체를 의미한다.
- 단어나 문장 각각을 벡터로 변환해 벡터 공간으로 끼워넣는다(embed)는 의미에서 임베딩이라는 이름이 붙었음
- 순환 신경망에서 텍스트를 처리할 때 즐겨 사용하는 방법은 단어 임베딩(word embedding)이다.
- 단어 임베딩은 각 단어를 고정된 크기의 실수 벡터로 바꾸어 줌
임베딩의 종류
- 행렬 분해 기반
- 행렬 분해(factorization) 기반 방법은 말뭉치 정보가 들어 있는 원래 행렬을 두 개 이상의 작은 행렬로 쪼개는 방식의 임베딩 기법을 가리킨다.
- 분해한 이후엔 둘 중 하나의 행렬만 쓰거나 둘을 더하거나 이어 붙여 임베딩을 사용한다.
- Glove, Swivel등이 여기에 속함
.- 예측 기반 방법
- 어떤 단어 주변에 특정 단어가 나타날지 예측하거나, 이전 단어들이 주어졌을 때 다음 단어가 무엇일지 예측하거나, 문장 내 일부 단어를 지우고 해당 단어가 무엇일지 맞추는 과정에서 학습하는 방법
- word2vec, FastText, BERT, ELMo, GPT 등이 예측 기반 임베딩 기법
- word2vec, FastText는 단어 수준 임베딩, BERT, ELMo, GPT는 문장 수준 임베딩
.- 토픽 기반 방법
- 주어진 문서에서 잠재된 주제를 추론하는 방식으로 임베딩을 수행하는 기법
- LDA(잠재 디리클레 할당)이 대표적인 기법임
- LDA 같은 모델은 학습이 완료되면 각 문서가 어떤 주제 분포를 갖는지 확률 벡터로 반화하기 때문에 임베딩 기법의 일종

단어 임베딩으로 만들어진 벡터는 원-핫 인코딩 된 벡터보다 훨씬 의미 있는 값으로 채워져 있기 때문에 자연어 처리에서 더 좋은 성능을 내는 경우가 많음
model2 = keras.Sequential()
# 어휘사전의 크기 500으로 설정(IMDB 리뷰 데이터셋에서 500개의 단어만 사용하도록 설정 했기 때문)
# 임베딩 백터의 크기 16으로 지정 (원-핫 인코딩보다 훨씬 작은 크기의 벡터 사용)
# Input_length는 입력 시퀀스의 길이 (위에서 100으로 지정)
model2.add(keras.layers.Embedding(500, 16, input_length=100))
model2.add(keras.layers.SimpleRNN(8))
model2.add(keras.layers.Dense(1, activation='sigmoid'))
model2.summary()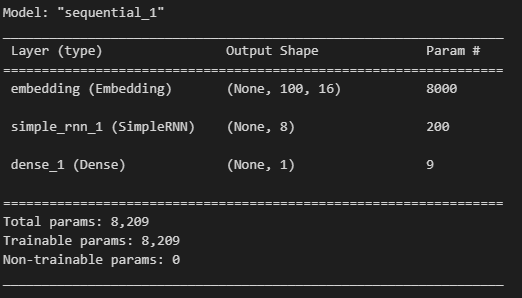
- 500개의 각 토큰의 크기가 16인 벡터로 변경되기 때문에 500 x 16 = 8000
- simple_rnn층은 임베딩 벡터의 크기가 16이므로 8개의 뉴런과 곱하기 위해서 필요한 가중치 16 x 8 = 128개를 가짐
- 은닉 상태에 곱해지는 가중치 8 x 8 = 64개
- 마지막 8개의 절편이 있으므로 128 + 64 + 8 = 200개
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model2.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-embedding-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model2.fit(train_seq, train_target, epochs=100, batch_size=256,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
원-핫 인코딩보다 좀 더 좋은 성능을 보임
네이버 기사로 단어/문장 간 관련도 계산 실습
- word2vec
import sys
import requests
from bs4 import BeautifulSoup
from datetime import date, datetime, timedelta
import pandas as pd
from urllib import parse
import os
from konlpy.tag import Mecab, Komoran
tokenizer = Komoran()
# 네이버 경제 부문 뉴스를 new파일에 저장 후 텍스트 데이터 처리
total = []
for roots, dirs, files in os.walk("./news"):
for idx,file in enumerate(files):
if idx % 100 ==0 : print(idx)
with open (roots + "/" + file, "r", encoding='utf-8') as f:
for text in f:
tmp = []
# 텍스트를 형태소 단위로 분리하고, 각 단어와 형태소를 순회
for word, morpheme in tokenizer.pos(text.strip()):
# 현재 단어의 형태소가 명사에 포함되고, 단어의 길이가 1이상인 경우 리스트에 담음
if morpheme in ['NNG', 'NNP', 'NNB', "NNM"] and len(word) > 1 :
#print(word, end=", ")
if word not in stop_words: tmp.append(word)
total.append(tmp)
from gensim.models import word2vec
# 위에서 만든 데이터 total을 학습 시키는 과정 / workers -모델 학습에 사용되는 스레드 4개
# min_count - 단어의 최소 등장 횟수 40회 이상, 주변 단어를 예측하기 위해 참고하는 문맥의 크기 10
# sample - 빈도가 높은 단어들은 일부만 샘플링하여 학습에 사용
model = word2vec.Word2Vec(total, workers = 4, min_count=40,
window=10, sample=0.001)
model.wv.most_similar("두산")
