앙상블이란?
- 앙상블 학습을 통한 분류는 여러 개의 분류기를 생성하고 그 예측을 결합함으로써
보다 정확한 최종예측을 도출하는 기법- 앙상블 학습의 목표 - 다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측값을 얻는 것
- 정형 데이터 분류 시에는 앙상블이 뛰어난 성능을 보임
대표 알고리즘
랜덤 포레스트
그래디언트 부스팅 알고리즘 / XGBoost, LightGBM
앙상블 학습의 유형
보팅(Voting)
배깅(Bagging)
부스팅(Boosting)
이외에도 스태킹을 포함한 다양한 앙상블 방법이 존재
보팅(Voting)과 배깅(Bagging)
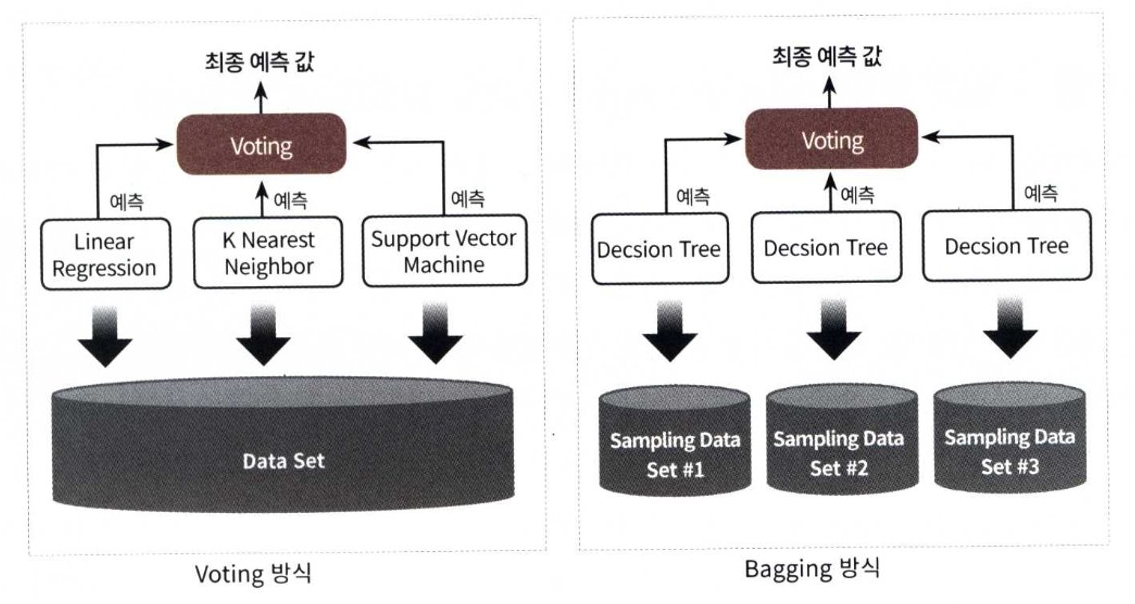
- 보팅 분류기 도식화
3개의 ML 알고리즘이 같은 데이터 세트에 대해 학습하고 예측한 결과를 가지고 보팅을 통해 최종 예측 결과를 선정
-
배깅 분류기 도식화
단일 ML 알고리즘(결정 트리)으로 여러 분류기가 학습으로 개별 예측을 하는데, 학습하는 데이터 세트가 보팅 방식과 다름
개별 분류기에 할당된 학습 데이터는 원본 학습 데이터를 샘플링해 추출하는데, 이렇게 개별 classifier에게 데이터를 샘플링해서 추출하는 방식을 부트스트래핑 분할 방식이라고 부름 -
con't
개별 분류기가 부트스트래핑 방식으로 샘플링된 데이터 세트에 대해서 학습을 통해 개별적으로 예측하는 수행한 결과를 보팅을 통해서 최종 예측 결과를 선정하는 방식이 바로 배깅 앙상블 방식
교차 검증이 데이터 세트간에 중첩을 허용하지 않는 것과 다르게 배깅 방식은 중첩을 허용
따라서 10000개의 데이터를 10개의 분류기가 배깅 방식으로 나누더라도 각 1000개의 데이터 내에는 중복된 데이터가 있음
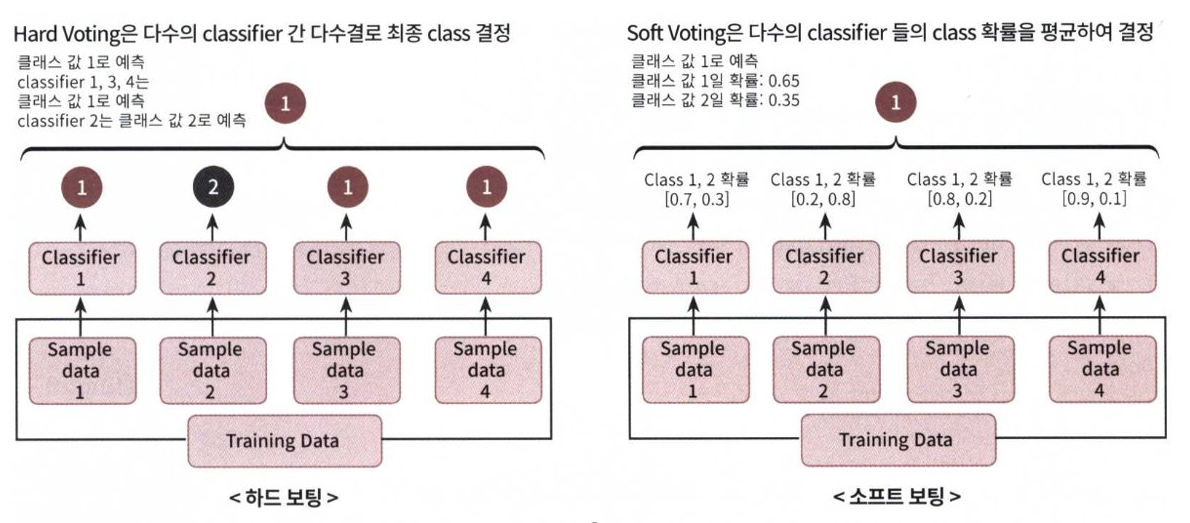
보팅 유형 - 하드 보팅(Hard Voting)과 소프트 보팅(Soft Voting)
-
하드 보팅(Hard Voting)
하드 보팅을 이용한 분류(Classification)는 다수결 원칙과 비슷합니다.
예측한 결괏값들중 다수의 분류기가 결정한 예측값을 최종 보팅 결괏값으로 선정하는 것 -
소프트 보팅(Soft Voting)
분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결괏값으로 선정
일반적으로 소프트 보팅이 보팅 방법으로 적용. 소프트 보팅이 예측 성능이 좋아서 더 많이 사용
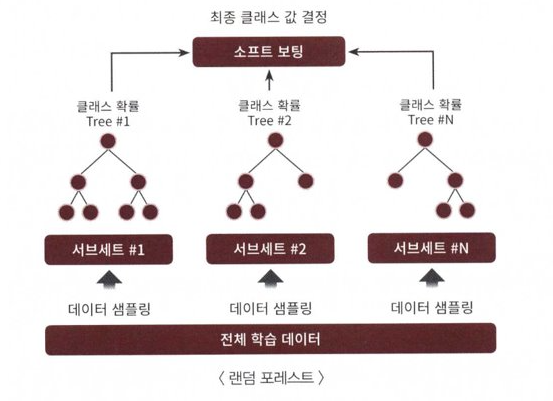
랜덤 포레스트란?
같은 알고리즘으로 여러 개의 분류기를 만들어서 보팅으로 최종 결정하는 알고리즘
배깅의 대표적인 알고리즘은 랜덤 포레스트
랜덤 포레스트의 기반 알고리즘은 결정 트리로서,
결정 트리의 쉽고 직관적인 장점을 그대로 가지고 있음
뿐만 아니라 부스팅 기반의 다양한 앙상블 알고리즘 역시 대부분 결정 트리 알고리즘을 기반 알고리즘을 채택
- 장점
앙상블 알고리즘 중 비교적 빠른 수행 속도
다양한 영역에서 높은 예측 성능을 보임- 원리
여러 개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로
각자의 데이터를 샘플링해 개별적으로 학습을 수행한 뒤 최종적으로
모든 분류기가 보팅을 통해 예측 결정을 하게 됨
GBM(Gradient Boosting Machine)란?
부스팅 알고리즘은 여러 개의 약한 학습기(weak learner)를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식
부스팅의 대표적인 구현은 AdaBoost(Adaptive boosting)와 그래디언트 부스트(Gradient Boost)
AdaBoost는 오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표적인 알고리즘AdaBoost 알고리즘
GBM
AdaBoost와 유사하나, 가중치 업데이트를 경사 하강법(Gradient Descent)을 이용함
오류값 = 실제값 - 예측값
오류식 h(x) = y -F(x)
오류식을 최소화하는 방향성을 가지고 반복적으로 가중치 값을 업데이트하는 방식



XGBoost
트리 기반의 앙상블 학습에서 가장 각광받고 있는 알고리즘 중 하나
압도적인 수치의 차이는 아니지만, 분류에 있어서 일반적으로 다른 머신러닝보다 뛰어난 예측 성능을 나타냄
XGBoost는 GBM에 기반하고 있지만, GBM의 단점인 느린 수행 시간 및 과적합 규제(Regularization) 부재 등의 문제를 해결해서 매우 각광
XGBoost는 병렬 CPU 환경에서 병렬 학습이 가능해 기존 GBM보다 빠르게 학습을 완료할 수 있음
- 특징

LightGBM
LightGBM은 XGBoost와 함께 부스팅 계열 알고리즘에서 가장 각광을 받고 있음
LightGBM은 일반 GBM 계열의 트리 분할 방법과 다르게 리프 중심 트리 분할(Leaf Wise)
방식을 사용함
- 장점
XGBoost보다 학습에 걸리는 시간이 휠씬 작다는 점이며, 또한 메모리 사용량도 상대적으로 적음
LightGBM과 XGBoost의 예측 성능은 별다른 차이가 없음
또한 기능상의 다양성은 LightGBM이 약간 더 많음- 단점
적은 데이터 세트에 적용할 경우 과적합이 발생하기 쉬움
적은 데이터 세터의 기준은 일반적으로 10,000건 이하의 데이터 세트 정도라고 LightGBM 공식 문서에 기술되어 있음
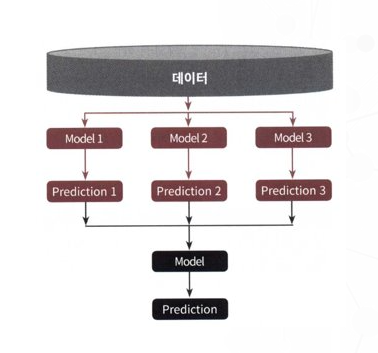
스태킹 앙상블
여러 개의 개별 모델들이 생성한 예측 데이터를 기반으로 최종 메타 모델이 학습할 별도의 학습 데이터 세트와 예측할 테스터 데이터 세트를 재 생성하는 기법
메타 모델 - 개별 모델의 예측된 데이터 세트를 다시 기반으로 하여 학습하고 예측하는 방식
스태킹 모델의 핵심은 메타 모델이 사용할 학습 데이터 세트와 예측 데이터 세트를 개별 모델의 예측값들을 스태킹 형태로 결합해 생성하는 것임
스태킹(Stacking)은 개별적인 여러 알고리즘을 서로 결합해 예측 결과를 도출한다는 점에서 앞에 소개한 배깅(bagging) 및 부스팅(Boosting)과 공통점이 있음
하지만 큰 차이점은 개별 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행한다는 것.
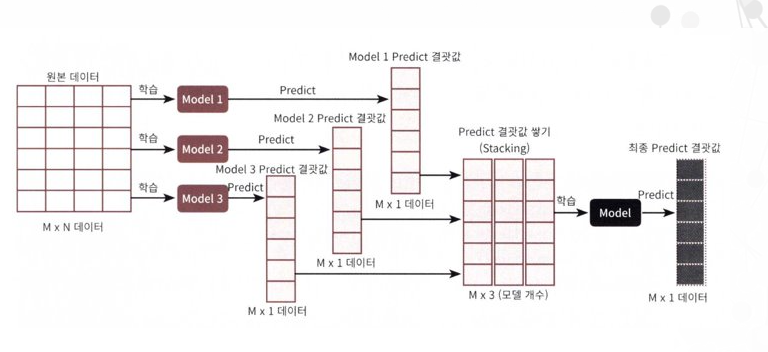
- M개의 로우, N개의 피처을 가진 데이터 세트에 스태킹 앙상블을 적용하는 예
각 모델별로 각각 학습을 시킨 뒤 예측을 수행하면 각각 M개의 로우를 가진 1개의 레이블 값을 도출
모델별로 도출된 예측 레이블 값을 다시 합해서(스태킹) 새로운 데이터 세트를 만들고 이렇게 스태킹된 데이터 세트에 대해 최종 모델을 적용해 최종 예측을 하는 것이 스태킹 앙상블 모델