준비
putty 접속
-
순서대로 실행
su hadoop
start_dfs
start_yarn
start_mr -
Spark 실행
nohup pyspark --master yarn --num-executors 3 &
웹사이트에client:8888로 접속 (client가 탄력적 ip가 아니라면 ec2에서 퍼블릭 Ipv4 주소 복사후:8888해주기
주피터 노트북 켠 후 아래 명령어 입력 ↓
from pyspark.sql import SparkSession
명령어 입력 후 client:4040 접속시 아래 화면 볼 수 있음
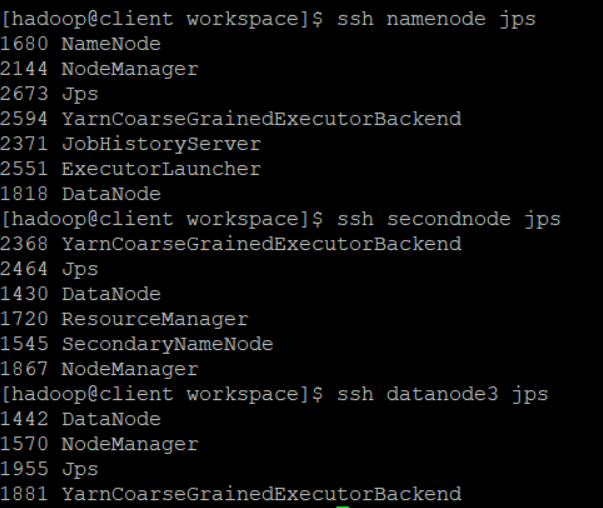
실행중인 프로세스 확인해보기
ssh [NodeName] jps
namenode, secondnode, datanode3 확인해보면 아래와 같이 실행되고 있음
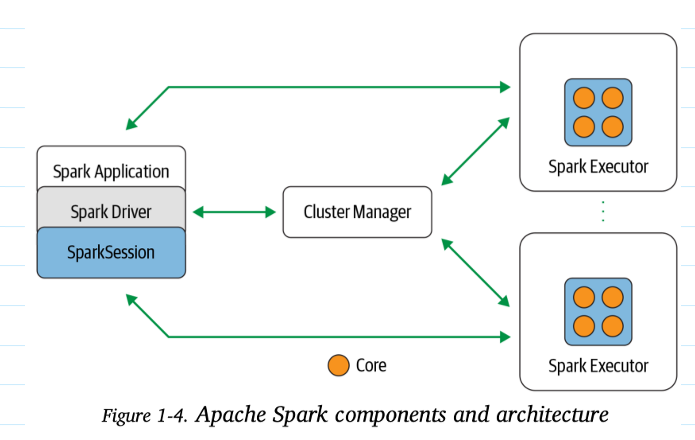
스파크 아키텍처(Spark Architecture)
데이터셋 준비
cd ~ 에서
wget https://mydatahive.s3.ap-northeast-2.amazonaws.com/mnm_dataset.csv 파일 다운로드
- hdfs dfs 별명 붙이기 (계속 적을 때 간단히 사용하기 위해서)
vim ~/.bashrc
alias hd="hdfs dfs"약어 입력해주기
source ~/.bashrc적용
hd -ls /확인
hd -put mnm_dataset.csv /mydata/
로컬 파일 시스템에서 Hadoop 분산 파일 시스템(HDFS)로 파일을 업로드하기 위해 사용되는 HDFS 명령어
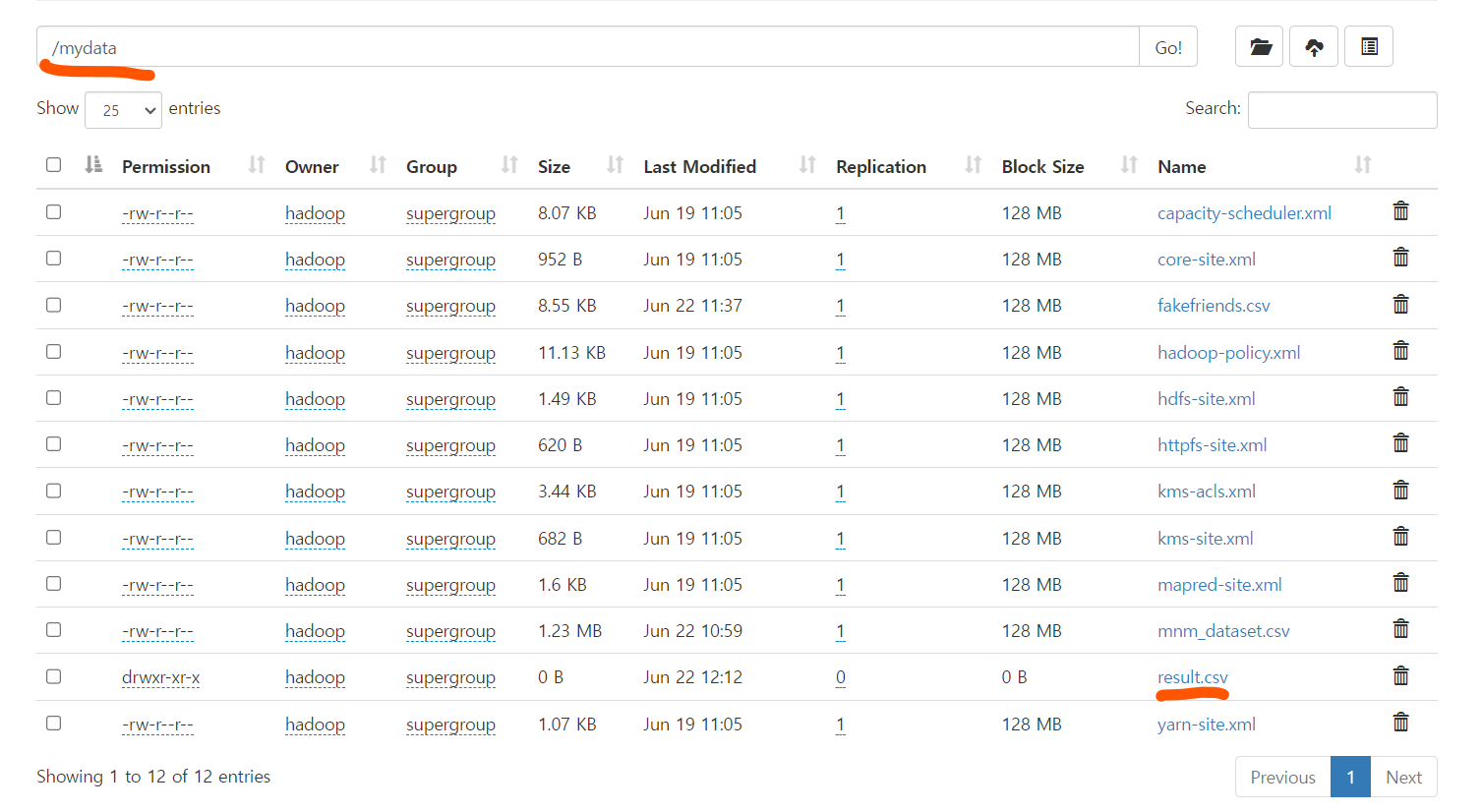
hd -ls /mydata 파일 업로드 확인
Jupyter Notebook
- from pyspark.sql import SparkSession 스파크세션 실행
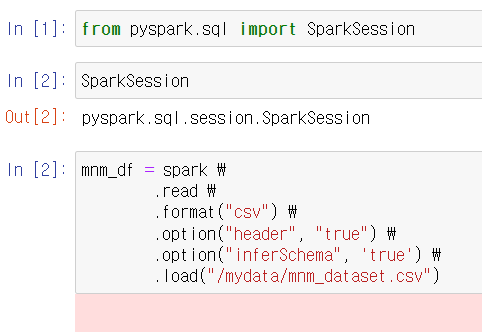
- mnm_df = spark \
.read \
.format("csv") \
.option("header", "true") \
.option("inferSchema", 'true') \
.load("/mydata/mnm_dataset.csv")
read format - csv 형식의 파일 불러오기 / option - 첫줄이 헤더, 스키마는 스파크가 알아서 설정 / load 뒤에는 경로
Spark의 특징 지연연산/액션

mnm_df.show(n=5)액션 명령을 내려야 결과 표시

- 이후 실습
mnm_df에서 각 주의 색상별 합계를 계산한 다음, 합계를 기준으로 오름차순 정렬


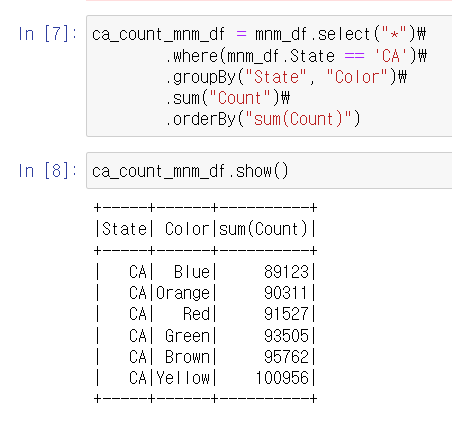
mnm_df에서 캘리포니아(CA) 주의 색상별 합계를 계산한 다음, 합계를 기준으로 오름차순 정렬
- 다른 예제
putty client cd ~에서
wget https://mydatahive.s3.ap-northeast-2.amazonaws.com/fakefriends.csv 예제 파일 받기
하둡 디렉토리에 업로드 시키기
hd -put fakefriends.csv /mydata/
Jupyter notebook
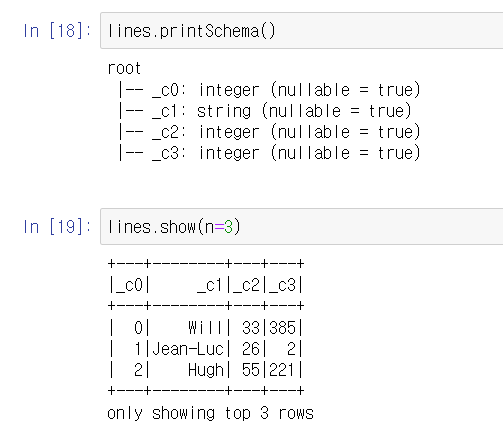
파일 불러오기
첫줄이 헤더는 아니고, 스키마는 알아서

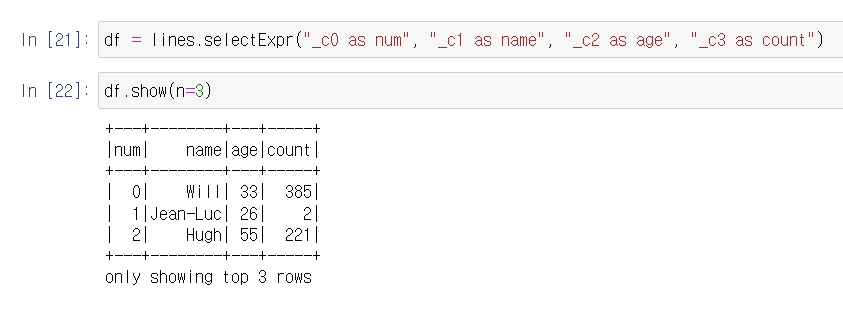
열이름 바꾸기
selectExpr
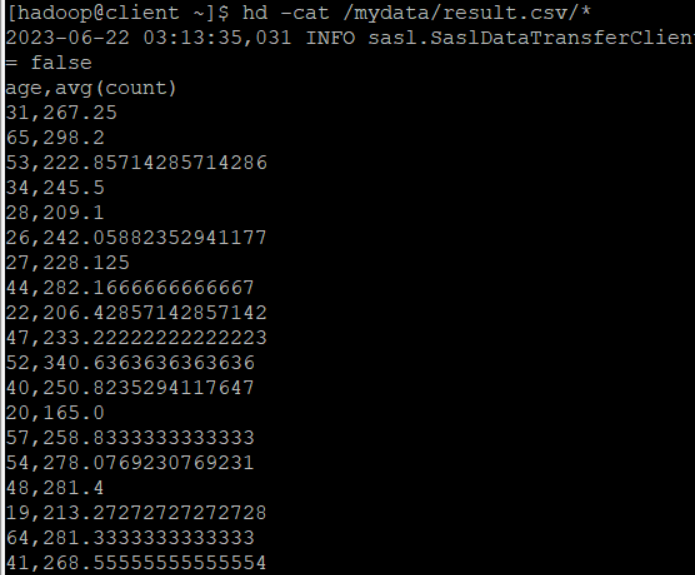
age별 count 평균

df_result로 변수 저장후 result.csv파일로 저장

namenode:50070 파일디렉토리에서 파일 확인
hd -cat /mydata/result.csv/*터미널에서 확인하기