5장 빅데이터의 파이프라인
빅데이터 파이프라인을 자동화하기 위한 구조에 대해 살펴보겠다.
5-1 워크플로 관리
정기적인 데이터 관리를 자동화하여 안정된 배치 처리를 실행하기 위해 워크플로 관리 도구를 도입한다.
워크플로 관리
워크플로 관리(workflow management) : 기업 내에 정형적인 업무 프로세스(신청, 승인, 보고 등)와 같이 정해진 업무를 원할하게 진행하기 위한 구조.
워크플로 관리 도구 역할
- 정기적으로 태스크를 실행
- 비정상적인 상태를 감지하여 그것에 대한 해결을 도움
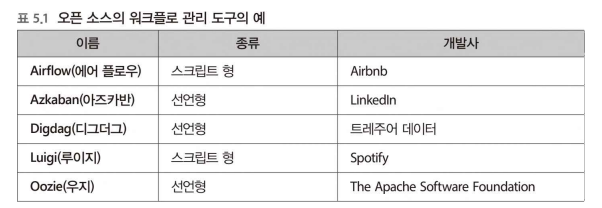
워크플로 관리 도구 종류
태스크(task) : 파이프라인 안에서 처리되는 개별 처리 단위
! 간단한 태스크 처리 같은 경우에는 도구를 사용하지 않고 스크립트로 처리할 수 있다!
그렇다면 왜 도구를 사용하는가?
- 태스크를 정기적인 스케줄로 실행하고 그 결과 통지하기
- 태스크 간의 의존 관계를 정하고, 정해진 순서대로 빠짐없이 실행하기
- 태스크의 실행 결과를 보관하고, 오류 발생 시에는 재실행할 수 있도록 하기
워크플로 관리 도구의 종류
-
선언형(declarative) : XML이나 YAML 등의 서식으로 워크플로를 기술하는 유형
- 누가 작성해도 동일한 워크플로가 되기 때문에 유지 보수성 up
- 동일 쿼리를 파라미터만 바꾸어 여러 번 실행하거나, 워크플로를 단순 반복적으로 자동 생성하는 경우에도 사용한다.
-
스크립트 형(scripting) : 스크립트 언어로 워크플로를 정의하는 유형
- 일반적인 스크립트와 동일하게 변수나 제어 구문을 사용할 수 있으므로, 태스크의 정의를 프로그래밍할 수 있다. 유연성 up
ETL 프로세스는 스크립트 형의 도구, SQL의 실행에는 선언형 도구 등으로 나누어 사용하는 것도 하나의 방법이다.
오류로부터의 복구 방법 먼저 생각하기
오류의 종류로는 다시 시도해서 회복 가능한 경우(ex. 통신 오류) 다시 시도해도 회복이 불가능한 경우(ex. 인증 오류) 등 종류가 다양하다.
따라서, 워크플로 관리에서는 오류로부터 자동 회복할 수 있는 설계는 배제한다.
대신, 수작업에 의한 복구(recovery)를 테스크를 설계한다.
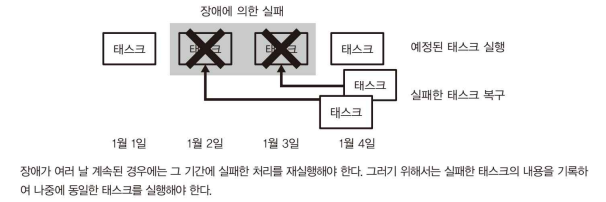
=> 실패한 태스크는 모두 기록하여 그것을 나중에 재실행하는 등...
플로우(flow) : 워크플로 관리 도구에 의해 실행되는 일련의 태스크
-
각 플로우에는 실행 시에 고정 파라미터가 부여되어 있다.
-
이 때, 동일 플로우에 동일 파라미터를 건네면, 완전히 동일한 태스크가 실행되도록 한다. 플로우가 도중에 실패해도 나중에 동일 파라미터로 재실행이 가능하기 떄문이다.
-
이러한 설계가 복구의 기초가 된다.
재시도(retry) : 여러 번 발생하는 오류에 대해서는 되도록 자동화하여 수작업 없이 복구하고자 할 때 할 수 있는 설계
-
곧바로 재시도하면 실패를 반복하는 일이 많기 때문에, 재시도 간격을 5-10분 정도로 두면 성공할 수 있다.
-
재시도는 그렇게 좋은 복구 방법이 아니다. 재시도 횟수가 너무 적으면 오류가 해결되기 전에 재시도가 끝날 수도 있고, 반대로 횟수가 너무 많으면 위험한 오류를 탐지할 수 없기 때문이다.
-
태스크의 성격상, 반복적이고 사소하지만 오류가 많이 나는 태스크에 대해 시도하면 좋은 복구 방법이다.
백필(backfill) : 플로우 전체를 처음부터 다시 실행하는 복구 방법
-
파라미터에 포함된 일시를 순서대로 바꿔가면서 일정 기간의 플로우를 연속해서 실행하는 구조
-
태스크의 실패가 며칠 동안이나 계속된 후에 이를 모두 모아서 재실행하고 싶을 때, 새롭게 만든 워크플로를 과걱로 거슬러 올라가 실행하고 싶은 경우에 사용한다.
-
작업의 크기가 큰 만큼 성능면에서 주의해야겠다.
멱등한 조작으로 태스크를 기술하기

재실행의 안정성이 복구를 설계할 때 전제되야 한다.
태스크가 중간까지 성공하고 오류가 생기고, 이 태스크(중간까지 성공한)가 기록 될 시 재실행 할 때, 중복되는 위험이 있다.
그래서, '마지막까지 성공'하거나 '실패하면 아무것도 남지 않음'만 존재해야 한다.
추가를 반복하면 데이터가 중복되지만, 치환은 반복해도 결과가 변하지 않으므로 멱등하다고 할 수 있다.
원자성 조작(atomic operation) : 각 태스크가 시스템에 변경을 가하는 것을 한 번만 할 수 있도록 하는 것.
=> 태스크를 쓰기 단위로 나누는 것으로 실천하는 방법이 있겠다.
멱등한 조작(idempotent operation) : 동일한 태스크를 여러 번 실행해도 동일한 결과가 되도록 하는 것
=> 테이블을 삭제한 후에 다시 만들기
멱등한 추가
-
항상 멱등한 조작이 가능하다면 좋겠지만, 그렇지 못 할 때가 많다. 이를 위한 기법으로 테이블 파티셔닝(table partitioning)이 자주 이용된다. 성능면이나 안정성에서 데이터를 테이블내에서 지웠다가 다시 삽입하는 경우보다 뛰어나다.
-
시스템에 따라 구현이 다르기 때문에 주의하자. ex) Hive는 파티셔닝을 대응하지만 Amazon Redshift는 그렇지 않다.
원자성을 지닌 추가
중간 테이블을 둬서 처리한 후 마지막에 목적 테이블엘 한 번에 추가하는 경우를 생각해보자
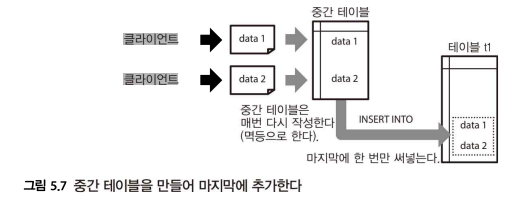
중간 테이블에서는 테이블을 치환하고 있기 때문에 이 부분은 멱등하다.
마지막 목적 테이블은 단순 추가이기 때문에 멱등하지 않다.
하지만 목적 테이블은 쓰기가 1회만 실행되므로 원자성을 지닌 조작이 된다.
워크플로 전체를 멱등으로 하기
각 태스크를 멱등으로 하는 것은 이상적이지만, 필수는 아니다.
최종적으로 워크플로가 안정적으로 실행되고 있는 한, 태스크가 멱등이지 않아도 동작에 지장은 없다.
추가가 문제시되는 것은 재시도 시에 중복의 위험이 있기 때문이다.
단, 워크플로에 문제가 아닌 데이터의 문제로 인해 재실행해야 하는 경우들이 있다.
이럴 때 멱등한 태스크는 안전하게 재실행할 수 있지만, 추가가 포함되어 있으면 그렇게 될 수 없다.
이런 경우를 대비해(재실행의 안정성을 위해) 각 플로우가 전체로서 멱등하게 되도록 구현해야 한다.
태스크 큐
워크플로 관리 도구의 또 다른 중요한 역할은 외부 시스템의 부하 컨트롤이다.
태스크 큐(task queue) : 대량의 태스크를 동시 실행하면 서버에 과부하가 걸리므로 제한이 필요한데, 이 때 사용할 수 있는 구조
- 모든 태스크를 큐에 저장하고 일정 수의 워크 프로세스가 그것을 순서대로 꺼내면서 병렬화가 실행된다.
병목 현상의 해소
pc에 자원을 무리하게 사용해서 태스크를 처리하려고 할 경우 병목 현상이 생기기 마련이다.

외부 & 내부 문제로 분류되는데 위 사진에 대책들로 해결하자. (흔히 내부 문제는 해결 가능하거나, 외부 문제는 해결 불가능하다.)
5-2 배치 형의 데이터 플로우
DAG를 사용한 배치 형의 분산 데이터 처리의 사고방식의 관해 보자
MapReduce의 시대는 끝났다
MapReduce 프로그램을 워크플로의 태스크로 등록함으로써 다단계의 복잡한 데이터 처리를 할 수 있었다.
이 후 기술적인 발전에 따라 현재는 다단계의 데이터 처리를 그대로 분산 시스템의 내부에서 실행할 수 있게 되었고 데이터 플로우라고 한다.
최근 경향으로는 배치 처리와 스트림 처리를 하나로 통합되어 통일된 프레임워크로부터 양쪽이 모두 실행되었다.
이제 아무리 복잡한 데이터 파이프라인이라도 단일 프로그램으로 실행하는 일이 많아질 수 있다.
하지만, MapReduce의 개념 자체는 지금도 접하게 될 기회가 많으므로, 구조를 간단하게 보자.
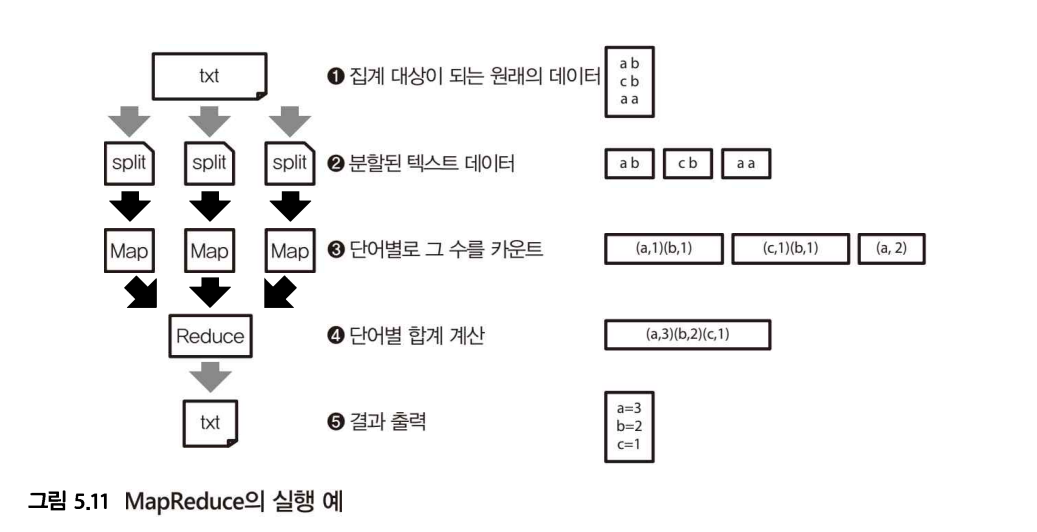
- 파일을 일정 크기로 나누는 스플릿을 만든다.
- 나눈 데이터를 읽어 들여 그중에 포함된 단어를 카운트한다.
- 분산 처리를 해야 하는데 같은 단어를 세는 경우도 있을테니, 분산 처리 결과 집계는 마지막에 해야 한다. 그래서 '단어별로 그 수 의 합계'를 구한다.
분할된 데이터를 처리하는 첫 번째 단계를 'Map', 그 결과를 모아서 집계하는 두 번째 단계를 'Reduce'라고 한다.
목적하는 결과를 얻을 때 까지 Map과 Reduce를 계속해서 반복하고 데이터를 변환해 나가는 구조가 MapReduce이다.
MapReduce를 대신할 새로운 프레임워크
DAG(directed acyclic graph) : MapReduce를 대신하는 새로운 프레임워크에 공통으로 들어가는 데이터 구조, 방향성 비순환 그래프라고도 한다.
DAG의 성질
- 노드와 노드가 화살표로 연결된다. (방향성)
- 화살표를 아무리 따라가도 동일 노드로는 되돌아오지 않는다. (비순환)
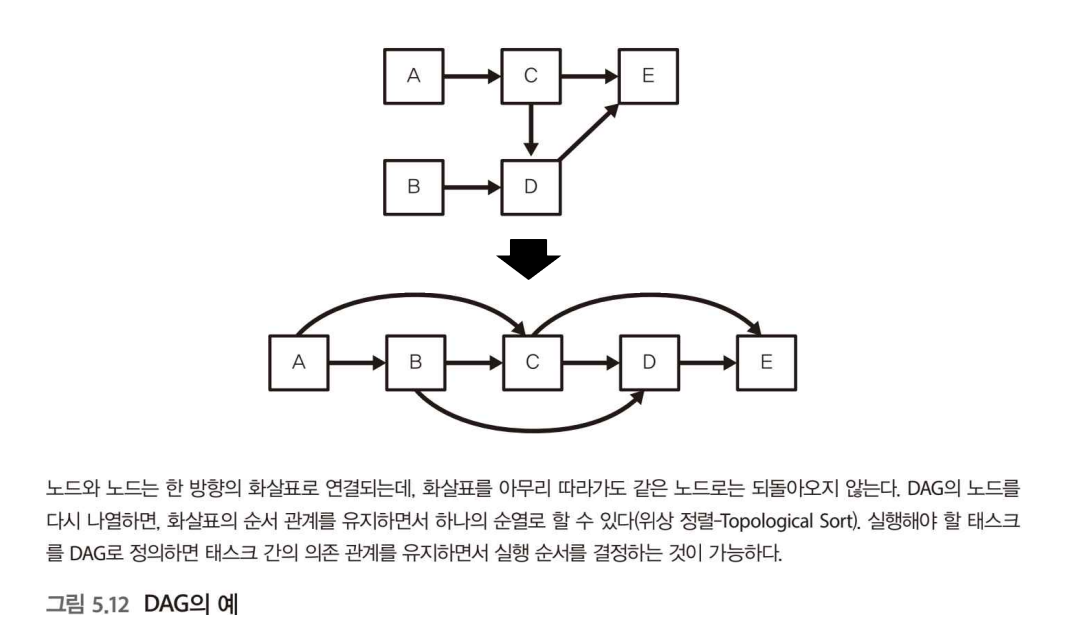
데이터 플로우에서는 실행해야 할 일련의 태스크를 DAG에 의한 데이터 구조로 표현한다.
그림은 실행 순서를 나타내며, 그 의존 관계를 유지하면서 실행 순서를 알맞게 정하면 모든 태스크를 빠짐없이 완료할 수 있다.
MapReduce와 DAG의 차이점은
MapReduce는 하나의 노드에서 처리가 끝나지 않으면 다음 처리로 진행할 수 없기 때문에 비효율적인 반면,
DAG는 각 노드가 모두 동시 병행으로 실행된다. 즉, 더 효율적이다!
데이터 플로우와 워크플로를 조합하기
실패하거나 정기적으로 실행하는 태스크가 있을 때 기록하여 복구하는 것은 데이터 플로우에서 못 하고, 워크플로 관리가 필요하다.
위와 같은 이유와 더불어 언제 오류가 발생할지 모르므로 복구를 고려해서 워크플로 안에서 데이터 플로우를 실행하는 것이 바람직하다.
데이터를 읽어들이는 플로우 (p.204)
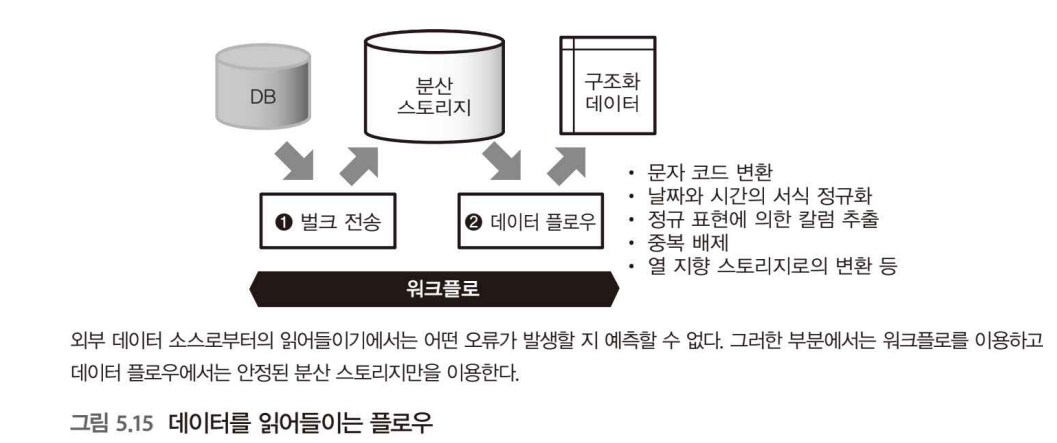
- 데이터 플로우로부터 읽어 들일 데이터는 성능적으로 안정된 분산 스토리지에 배치하도록 한다.
- 외부의 데이터 소스에서 데이터를 읽어 들일 때는 벌크 형의 전송 도구로 태스크를 구현한다.
데이터의 복사가 완료되면, 텍스트 데이터의 가공이나 열 지향 스토리지로의 변환 등의 부하가 큰 처리는 데이터 플로우에서 맡아서 실행할 수 있다.
여기까지 하나의 태스크로 구현하면, 정기적으로 데이터를 읽어 들이기 위한 워크플로가 완성된다.
데이터를 써서 내보내는 플로우
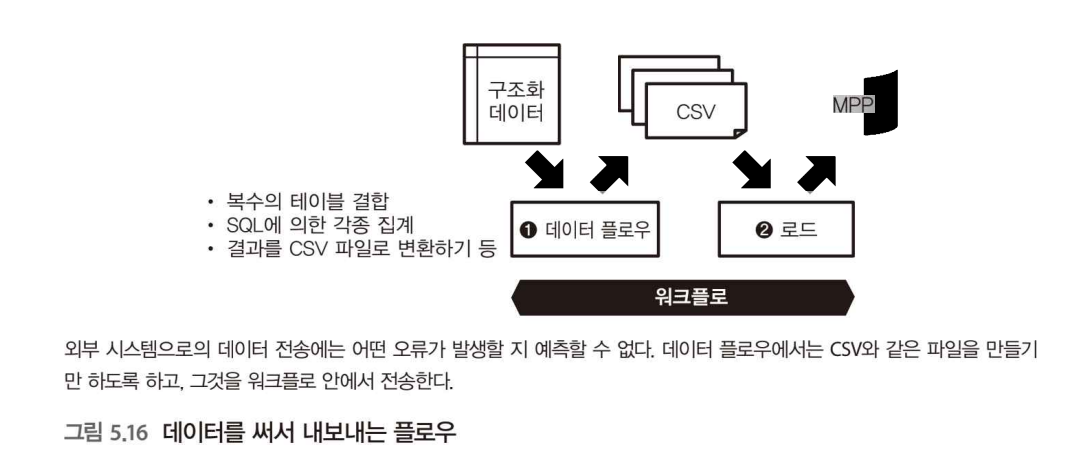
- 데이터 플로우의 출력은 데이터를 CSV 파일과 같이 취급하기 쉬운 형식으로 변환(성능상의 문제로)하여 분산 스토리지에 넣는다.
- 스토리지에 보관이 됐다면 남은 자원을 사용해 워크플로로 외부 시스템에 데이터를 전송한다.
데이터 플로우와 SQL을 나누어 사용하기
주로 데이터 분석을 목적으로 할 경우, SQL로 쿼리를 실행시키는 일이 많다. 그것을 호출하는 것 또한 워크플로의 업무다.
데이터 웨어하우스의 파이프라인 => 데이터베이스에서 실행하는 경우
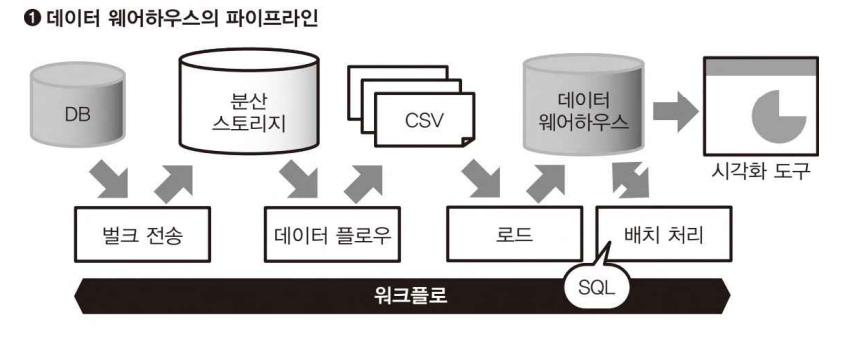
- 비구조화 데이터를 가공하여 CSV 파일 등으로 만들기, 스토리지에 넣기는 데이터 플로우에서 실행하고, 이후 태스크 실행이나 SQL에 의한 쿼리의 실행은 워크플로에 맡긴다.
데이터마트의 파이프라인 => 분산 시스템상의 쿼리 엔진에서 실행하는 경우
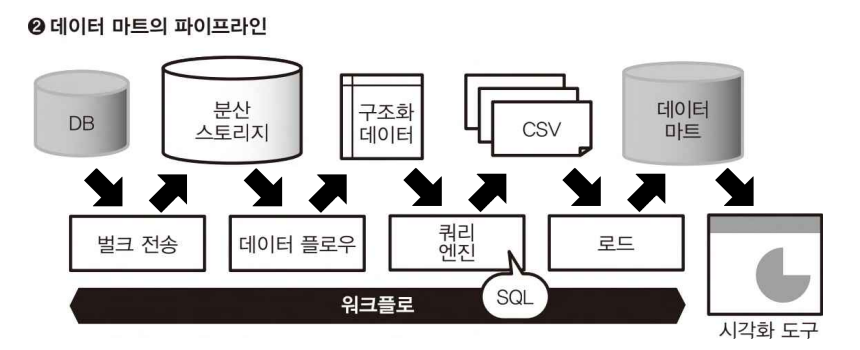
-
구조화 데이터를 만드는 부분까지가 데이터 플로우의 역할이다. 분산 스토리지 상의 데이터를 매일 반복되는 배치로 가공하여 열 지향의 스토리지형식으로 보관한다.
-
쿼리 엔진을 사용한 SQL 실행이나 그 결과를 데이터 마트에 써서 내보내는 것은 워크플로에서 실행한다.
대화식 플로우
애드 혹 데이터 분석에서는 다른 파이프라인 구조가 된다.
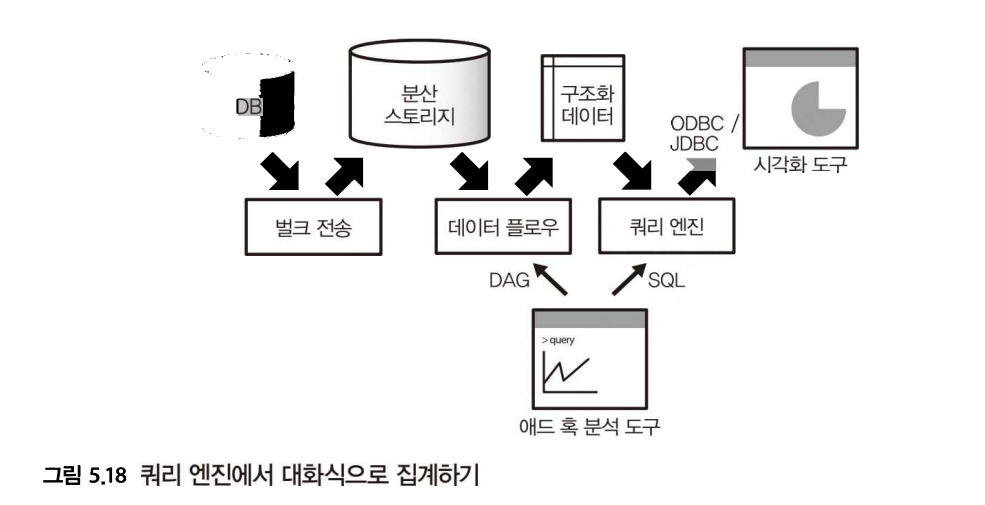
-
아직 구조화되지 않은 데이터를 애드 혹으로 분석할 때에는 데이터 플로우가 유용하다.
-
로우 데이터에 직접 접속하여 스크립트 언어를 사용하여 그 자리에서 데이터를 가공, 집계할 수 있다.
-
데이터가 구조화 됐다면 그 후의 집계는 고속 처리가 가능한데, 쿼리 엔진에 의한 SQL의 실행과 비교해도 뒤지지 않는다.
5-3 스트리밍 형의 데이터 플로우
실시간 처리에 알맞는 DAG를 사용하는 파이프라인을 보자
배치 처리와 스트림 처리로 경로 나누기
실시간에 가까운 데이터 처리에는 배치 처리에서 하는, 시간이 오래 걸리는, 과정을 모두 생략한 별개의 계통으로 파이프라인을 만든다.
실시간성이 높은 데이터 처리 시스템의 예
배치 처리에서는 분산 스토리지에 넣어 처리를 했다면 스트림 처리는 이러한 과정이 생략 되고 처리를 계속 하는 것이다.
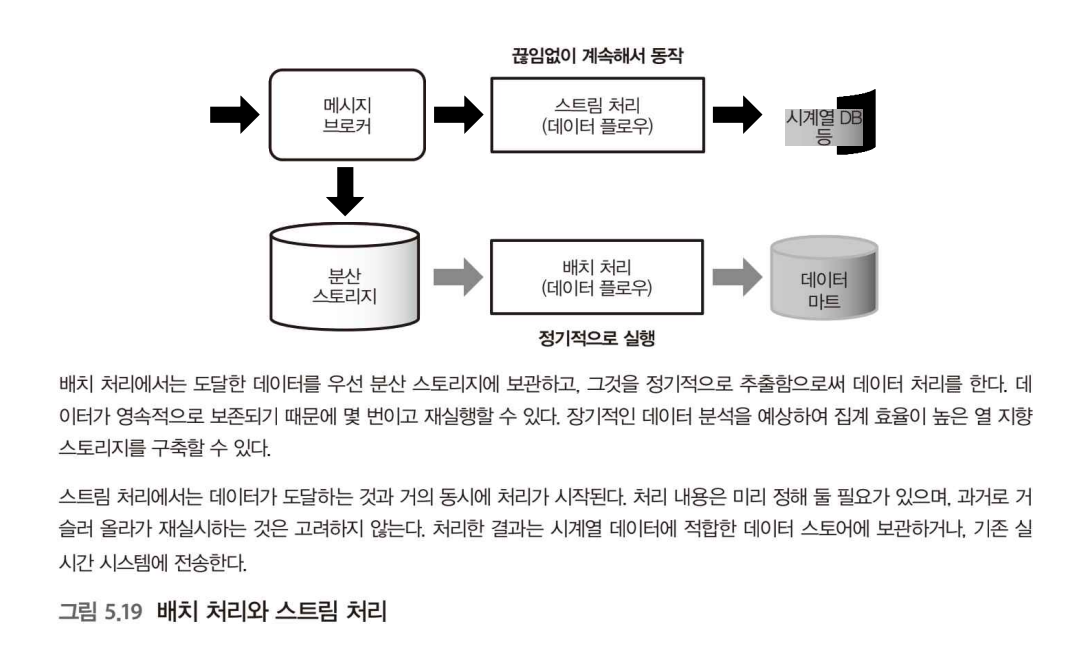
배치 처리와 스트림 처리 통합하기
배치 처리에서는 데이터를 작게 나눠 DAG에 넣는 반면, 스트림 처리에서는 끊임없이 데이터가 생성되며, 이것이 DAG에 들어감에 따라 처리된다.
- 유한 데이터(bounded data) : 배치 처리와 같이 실행 시에 데이터양이 정해지는 것
- 무한 데이터(unbounded data) : 스트림 처리와 같이 제한이 없이 데이터가 보내지는 것
Spark 스트리밍의 DAG (p.212)
스트림 처리의 결과를 배치 처리로 치환하기
스트림 처리에는 고질적인 문제가 있는데 '틀린 결과를 어떻게 수정할 것인가?', '늦게 전송된 데이터 취급'이다.
위에 문제를 해결하기 위해 스트림 처리와 별개로 배치 처리를 실행시켜 후자의 결과가 옳다고 한다.
람다 아키텍처 (lambda architecture)
데이터 파이프라인을 3개의 레이어로 구분한다.
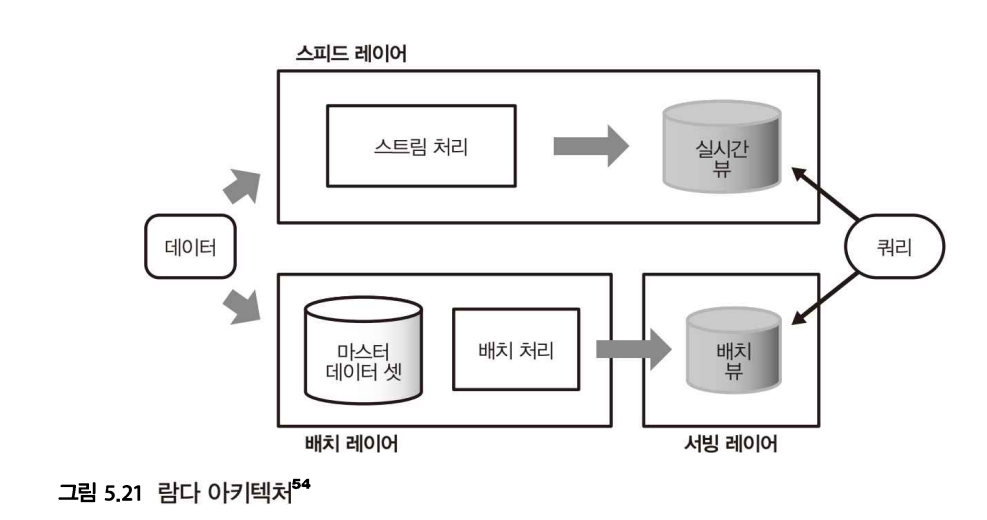
-
모든 데이터는 배치 레이어(batch layer)에서 처리한다.
- 과거의 데이터를 장기적인 스토리지에 축적, 여러번 다시 집계할 수 있게 한다.
-
배치 처리 결과는 서빙 레이어(serving layer)를 통해서 접근한다.
- 여기에 응답이 빠른 DB를 설치하여 집계 결과를 바로 추출한다.
- 서빙 레이어에서 얻어진 결과를 배치 뷰(batch view)라고 한다.
-
다른 경로로 스트림 처리를 위한 스피드 레이어(speed layer)를 설치한다.
- 스피드 레이어에서 얻은 결과를 실시간 뷰(realtime view)라고 한다.
마지막으로, 배치 뷰와 실시간 뷰 모두를 조합시키는 형태로 쿼리를 실행한다.
이렇게 스트림과 배치 처리를 상호 보완하는 구조가 람다 아키텍처이다.
카파 아키텍처 (kappa architecture)
람다 아키텍처에서는 스피드 레이어와 배치 레이어는 모두 똑같은 처리를 구현하고 있으므로 번거로운 문제점이 있는데, 이를 극복하고자 람다 아키텍처를 단순화한 구조가 카파 아키텍처이다.
-
카파 아키텍처는 배치 레이어나 서빙 레이어를 완전히 제거하고, 스피드 레이어만 남긴다.
-
대신 메시지 브로커의 데이터 보관 기간을 충분히 길게 하여 오류 발생 시 메시지 배송 시간을 과거로 다시 설정한다.
-
이러면 과거의 데이터가 다시 스트림 처리로 흘러 들어 실질적으로 재실행이 이루어진다.
-
카파 아키텍처의 문제점은 부하가 높아지는 것이다.
아웃 오브 오더의 데이터 처리
아웃 오브 오더의 데이터 문제 : 늦게 도달하는 메시지, 즉 프로세스 시간과 이벤트 시간의 차이가 생기면서 발생하는 문제
이벤트 시간
스트림 처리 중에 지연이 생겨 밀려있던 데이터가 급격히 밀려들면 데이터 순서에 있어 신뢰성이 떨어진다. 이를 위해 데이터가 처음에 생성된 시간, 이벤트 시간으로 집계해야 올바른 결과를 얻을 수 있다.
윈도우
스트림 처리에서 시간을 일정 간격으로 나누어 그 안에서 데이터 집계를 하는데 이 나누어진 단위를 윈도우라고 한다.
이벤트 시간 윈도윙
이벤트 시간에 의해 윈도우를 나누는 것을 이벤트 시간 윈도윙이라고 한다.
메시지가 배송된 데이터는 무작위 순으로 나열된, 즉 '아웃 오브 오더' 상태이기 때문에, 이것을 적절히 바꿔 집계 결과를 업데이트 해야 한다.
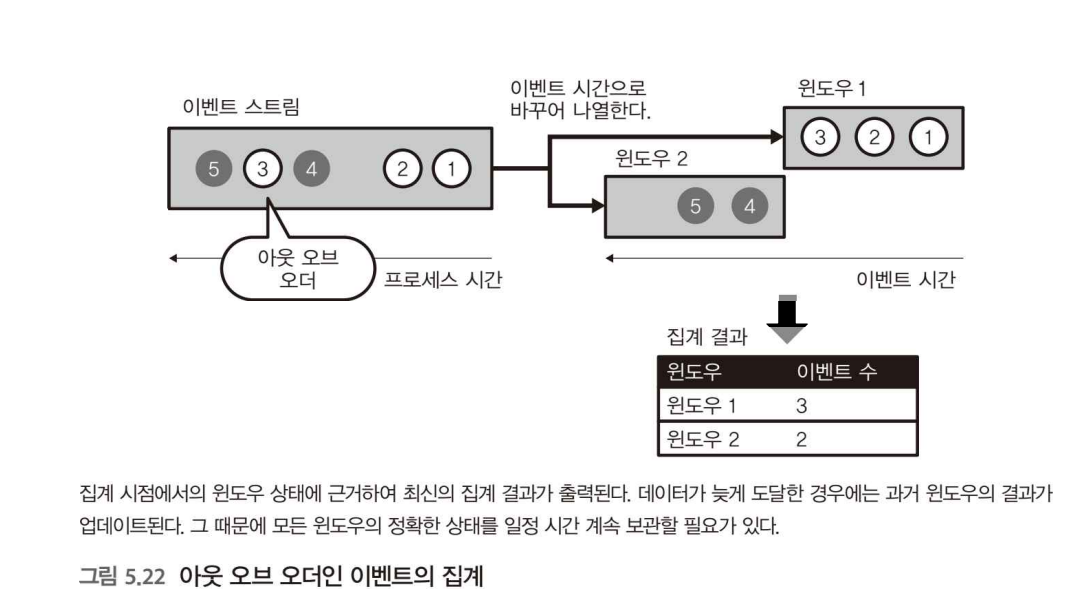
이 때문에 과거 이벤트의 상태를 보관하면서, 데이터가 도달할 때마다 해당하는 윈도우를 재집계할 필요하가 있다.
정리
여러 종류에 데이터 파이프라인과 이에 대한 특징과 문제점을 알아보는 장이었다!
