10장 MLlib을 사용한 머신러닝
머신러닝 작업을 위해 데이터를 준비하는 작업을 배우는 장이다.
머신러닝이란 무엇인가?
통계, 선형 대수 및 수치 최적화를 사용하여 데이터에서 패턴을 추출하는 프로세스!
종류로는 지도 학습, 반지도 학습, 비지도 학습, 강황 학습 등을 포함한 여러가지가 있다.
지도 학습
지도 학습에서 가장 대표적인 유형이 있는데, 분류와 회귀이다.
인기있는 분류 및 회귀 알고리즘을 보자
회귀 알고리즘
- 선형 회귀, linear regression
분류 알고리즘
- 로지스틱 회귀, logistic regression
- 나이브 베이즈, Naive Bayes
- 서포트 벡터 머신, support vector machine, SVM
둘 다 사용될 수 있는 알고리즘
- 의사결정트리, Desition Tree
- 그래디언트 부스트 트리, gradient boosted tree
- 랜덤 포레스트, random forest
비지도 학습
필요한 레이블이 없고, 만드는데 많은 비용이 들 때 유용한 학습 방법.
스파크 MLlib에 있는 대표적인 비지도 알고리즘들은 K-means, 잠재 디리클래 할당(LDA), 가우시안 혼합 모델(GMM)
왜 머신러닝을 위한 스파크인가?
스파크는 머신러닝에 필요한 에코시스템(데이터 수집, 피처 엔지니어링, 모델 교육 및 배포)을 모두 제공해주는 통합 분석 엔진이다.
그래서 스파크를 사용하면 데이터 과학자는 단일 시스템에 맞게 데이터를 다운샘플링할 필요 없이 데이터 준비 및 모델 구축을 하나의 에코시스템으로 사용할 수 있다는 장점이 생긴다.
spark.ml는 모델이 보유한 데이터 포인트 수에 따라 선형으로 확장되는 확장에 중점을 두어 방대한 양의 데이터로 확장할 수 있다.
- spark.mllib : RDD API를 기반으로 하는 기존의 머신러닝 API
- spark.ml : 데이터 프레임을 기반으로 하는 최신 API
MLlib으로 통칭해서 부른다.
머신러닝 파이프라인 설계
MLlib에서 파이프라인 API는 머신러닝 워크플로를 구성하기 위해 데이터 프레임 위에 구축된 고급 API를 제공한다.
파이프라인 API는 일련의 변환기, 추정기로 구성된다.
-
변환기(Transformer) : DF을 입력으로 받아들이고, 하나 이상의 열이 추가된 새 데이터 프레임을 반환. 변환기는 데이터에서 매개변수를 학습하지 않고, 단순히 규칙 기반 변환을 적용하여 모델 훈련을 위한 데이터를 준비하거나 훈련된 MLlib 모델을 사용하여 예측을 생성한다. (.transform())
-
추정기(Estimator) : .fir() 메서드를 통해 DF에서 매개변수를 학습하고 변환기인 Model을 반환한다.
-
파이프라인 : 일련의 변환기와 추정기를 단일 모델로 구성한다. 파이프라인 자체가 추정기인 반면, pipeline.fit()의 출력은 변환기인 PipelineModel을 반환한다.
데이터 수집 및 탐색
작가가 미리 전처리한 데이터셋을 업로드 해 놓았다.
데이터셋과 해당 스키마를 살펴보자
import pyspark
from pyspark.sql import SparkSession
#Create SparkSession
spark = SparkSession.builder.master("local[1]").appName("SparkByExamples.com").getOrCreate()
filePath = """/content/drive/MyDrive/BOAZ/엔지/Spark Study/databricks-datasets/learning-spark-v2/sf-airbnb/sf-airbnb-clean.parquet/"""
airbnbDF = spark.read.parquet(filePath)
airbnbDF.select("neighbourhood_cleansed", "room_type", "bedrooms", "bathrooms", "number_of_reviews", "price").show(5)학습 및 테스트 데이터세트 생성
학습 데이터 테스트 데이터 나눠서 생성해보자.
trainDF, testDF = airbnbDF.randomSplit([.8, .2], seed=32)
print(f"""There are {trainDF.count()} rows in the training set, and {testDF.count()} in the test set""")변환기를 사용하여 기능 준비
스파크 선형 회귀에서는 모든 입력 기능이 df의 단일 벡터 내에 포함되어야 한다. 따라서 데이터를 변환해야 한다.
변환기는 df를 입력으로 받고, 하나 이상의 열이 추가된 새 df를 반환한다.
변환기는 학습하지 않지만 transform() 메서드를 사용하여 규칙 기반 변환을 적용한다.
모든 기능을 단일 벡터에 넣는 작어블 위해 VectorAssembler 변환기를 사용한다.
from pyspark.ml.feature import VectorAssembler
vecAssembler = VectorAssembler(inputCols=["bedrooms"], outputCol="features")
vecTrainDF = vecAssembler.transform(trainDF)
vecTrainDF.select("bedrooms", "features", "price").show(10)VectorAssembler는 입력 열 목록을 가져와서 기능이라고 부를 추가 열이 있는 새 df를 만든다. 이러한 입력 열의 값을 단일 벡터로 결합한다.
선형 회귀 이해하기
선형 회귀 : 종속 변수(레이블)와 하나 이상의 독립 변수(기능) 간의 선형 관계를 모델링한다.
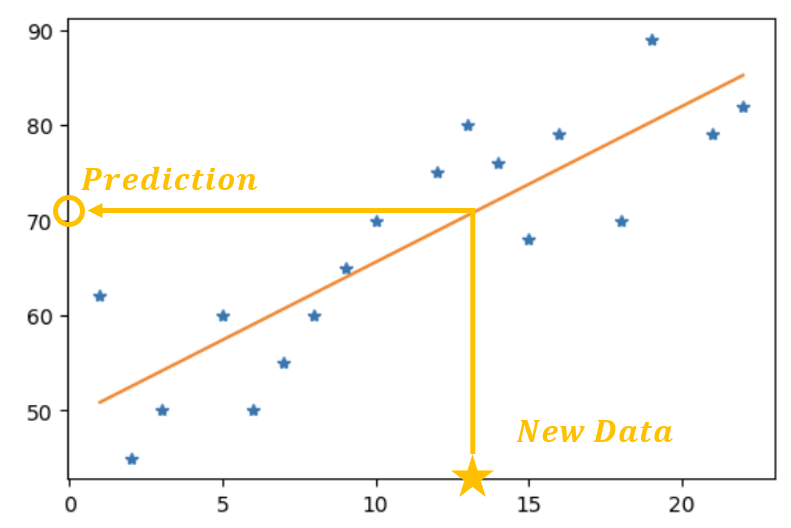
본 예제는 침실 수(독립 변수)를 고려하여 에어비앤비 임대 가격(종속 변수)을 예측하는 선형회귀 모델을 만들어 본다.
추정기를 사용하여 모델 구축
추정기는 모델 알고리즘이 포함되어 있는 API를 포함한다. df를 사용하고 모델을 반환하는 것이 추정기이다.
from pyspark.ml.regression import LinearRegression
lr = LinearRegression(featuresCol='features', labelCol='price')
lrModel = lr.fit(vecTrainDF)m = round(lrModel.coefficients[0], 2)
b = round(lrModel.intercept, 2)
print(f"""The formula for the linear regression line is price = {m}*bedrooms + {b}""")파이프라인 생성
모델을 테스트 세트에 적용하려면 훈련 세트와 동일한 방식(벡터 어셈블러를 통한 전달)으로 데이터를 준비해야 한다.
데이터 준비 파이프라인이 복잡하고 반복적이다 보니 파이프라인 API의 개발 동기가 되었다.
파이프 라인 API는 데이터가 통과할 단계를 순서대로 지정하기만 하면 스파크가 알아서 처리 해준다. (이렇게 더 나은 코드 재사용성과 구성을 제공한다.)
Pipelines는 추정기인 반면, PipelineModels는 변환기이다.
from pyspark.ml import Pipeline
pipeline = Pipeline(stages=[vecAssembler, lr])
pipelineModel = pipeline.fit(trainDF)predDF = pipelineModel.transform(testDF)
predDF.select("bedrooms", "features", "price", "prediction").show(10)모델 평가
분류, 회귀, 클러스터링 및 순위 평가 지표도 spark.ml API에 다 포함되어 있다.
선형 회귀 모델에 가장 잘 맞는 평가 지표인 RMSE(평균 제곱근 오차, root mean square error)를 사용하여 모델을 평가해보자.
RSME =
from pyspark.ml.evaluation import RegressionEvaluator
regressionEvaluator = RegressionEvaluator(
predictionCol="prediction",
labelCol="price",
metricName='rmse'
)
rmse = regressionEvaluator.evaluate(predDF)
print(f"RMSE is {rmse:.1f}")모델 저장 및 로드
model.write().save(path)라는 API로 모델을 영구 저장할 수 있다. overwrite()를 사용해 덮어쓸 수 있다. 가중치도 같이 저장된다. (개꿀) 하지만 가중치 초기화 기능은 없어서 데이터셋이 바뀐다면 다시 학습시켜야 하는 불상사가 생길 수도 있다.
pipelinePath = "/tmp/lr-pipeline-model"
pipelineModel.write().overwrite().save(pipelinePath)# 저장된 모델을 로드할 대 로드할 모델 유형을 다시 지정해야 한다.
from pyspark.ml import PipelineModel
savedPipelineModel = PipelineModel.load(pipelinePath)하이퍼파라미터 튜닝
하이퍼파라미터는 훈련전에 모델에 대해 정의하는 속성이며 훈련과정에서 학습되지 않는다.
spark.ml을 사용하여 하이퍼파라미터 조정을 수행하도록 역학을 설정한 후에 파이프라인 최적화 방법에 대해서도 본다.
트리 기반 모델
트리 기반 모델 중에서도 의사결정나무 알고리즘을 볼 것이다.
DT는 빌드가 빠르고, 해석 가능성이 높으며, 규모 불변성(숫자 피처를 표준화하거나 확장해도 트리의 성능이 편경되지 않음)이라는 장점이 있다.
사진 예시처럼 DT의 루트 노드에는 가장 유익한 정보를 제공해야 한다. 만약에 노드가 더 이상 분할하지 않는다면 이를 리프 노드라고 한다.
결정 트리의 깊이는 루트 노드에서 주어진 리프 노드까지의 가장 긴 경로인데, 이 깊이가 너무 깊으면 오버피팅, 너무 얕으면 언더피팅의 위험이 있다.
from pyspark.ml.regression import DecisionTreeRegressor
dt = DecisionTreeRegressor(labelCol='price')
numericCols = [field for (field, dataType) in trainDF.dtypes if ((dataType == "double") & (field != "price"))]
assemblerInputs = indexOutputCols + numericCols
vecAssembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages = [StringIndexer, vecAssembler, dt]
pipeline = Pipeline(stages=stages)
dt.setMaxBins(40)
pipelineModel = pipeline.fit(trainDF)어떤 기능이 중요한지 보기 위해 모델에서 기능 중요도 점수를 추출할 수 있다.
import pandas as pd
featureImp = pd.DataFrame(list(zip(vecAssember.getInputCols(), dtModel.featureImportances)),colums=["feature", "importance"])
featureImp.sort_values(by='importance', ascending=False)k-폴드 교차 검증
검증 데이터 세트를 만들어 오버피팅을 막아보자
검증 데이터세트로 분할하여 훈련 데이터셋 손실이 생기는 한계를 k-폴드 교차 검증 기술을 사용한다.
K개로 데이터를 나누어 부터 개 까지 테스트 세트를 순차적으로 바꾸며 검증하는 방법으로 검증성을 올리며 훈련 데이터 손실 줄이는 기법이다.
스파크에서 하이퍼파라미터 검색은 다음 프로세스를 따른다.
- 평가할 추정기 정의
- ParamGridBuilder 사용, 변경하려는 하이퍼파라미터 값을 지정
- 평가기를 정의, 다양한 모델을 비교하는 데 사용할 metric 지정
- CrossValidator를 사용해 다양한 모델 각각을 평가하는 교차 검증 수행
pipeline = Pipline(stages = [stringIndexer, vecAssembler, rf])from pyspark.ml.tuning import ParamGridBuilder
paramGrid = (ParamGridBuilder().addGrid(rf.maxDepth, [2, 4, 6]).addGrid(rf.numTrees, [10, 100]).build())evaluator = RegressionEvaluator(labelCol="price", predictionCol="prediction", metricName="rmse")from pyspark.ml.tuning import CrossValidator
cv = CrossValidator(estimator=pipeline, evaluator=evaluator, estimatorParamMaps=paramGrid, numFolds=3, seed=32)
cvModel = cv.fit(trainDF)# CV 최적의 깊이와 트리수 출력
list(zip(cvModel.getEstimatorParamMaps(), cvModel.avgMetrics))파이프라인 최적화
spark.ml은 사실 병렬이 아닌 순차적으로 모델 컬렉션을 훈련한다.
이를 위해 parallelism 매개변수가 spark 2.3부터 도입되었다. 이를 통해 (파이프라인)성능 최적화 가능! 이 매개변수는 병렬로 훈련할 모델의 수를 결정한다.
cvModel = cv.setParallelism(4).fit(trainDF)또 다른 트릭으로는 교차 검증기를 파이프라인 내부에 배치하는 것이 아닌 파이프라인 내부에 교차 검증기를 배치하면, 각 모델에 대한 파이프라인의 모든 단계를 실행한다. 모든 단계를 재평가하면서 변경되진 않는다.
cv = CrossValidator(estimator=pipeline, evaluator=evaluator, estimatorParamMaps=paramGrid, numFolds=3, parallelism=4, seed=32)
pipeline = Pipeline(stages=[stringIndexer, vecAssembler, cv])
pipelineModel = pipeline.fit(trainDF)