[Paper Review] Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
Paper Review
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
SNS 피드를 보다가 I-JEPA 관련 뉴스를 봤다. 제목 자체가 굉장히 intriguing 했는데 https://ai.facebook.com/blog/yann-lecun-ai-model-i-jepa/ 'I-JEPA: The first AI model based on Yann LeCun's vision for more human-like AI' 였다.. 게재된지는 꽤 되었지만 이번 CVPR 2023 발표와 함께 다시 한번 수면으로 올라왔다. paper 의 핵심 architecture 를 이해하면서 human-like AI 라는 term 에 대해 공감이 갔는데, 이유는 다음과 같다. 기존 generative approach for SSL 방식에서는 reconstruction 을 한 후에 loss 를 계산했는데, I-JEPA 에서는 representation space 에서 reconstruction (?) 및 loss 계산이 이루어진다. augmentation 이 따로 필요없다는 점도 포함될 수 있다.
Introduction
computer vision field 에서 two common families of approches for self-supervised learning 방식을 소개한다.
- Invariance-based pretraining methods (MoCo, SimSiam, VICReg, BarlowTwins...)
- Generative methods (MAE, language models)
먼저 1번 방식의 문제점을 언급한다. pretraining methods can produce high semantic representations but introduce strong biases that may be detremental for certain downstream tasks. unclear how to generalize these biases for tasks requiring different levels of abstraction. (ex, segmentation & classification do not require the same invariances.) (끄덕끄덕)
또한 필자는 Cognitive learning 이론에서는 biological system 에서의 representation learning 의 핵심은 "the adaptation of an internal model to predict sensory input responses" 이다. 라고 하며 core of generative SSL model 의 핵심인 "remove or corrupt portions of the input and learn to predict the corrupted content" 와 같은 선상에 있다고 주장한다.
이어서 이 방식의 문제점도 함께 언급한다. lower sementic level 의 representation 을 도출하고, 종종 underperform invariance-based pretraining inf off-the-shelf evaluation (ex linear probing) 하다고 지적한다.
본 논문에서는 SSL representation 의 semantic level 을 prior knowledge (encoded through augmentatino) 없이 개선할 수 있는가에 대한 고민을 담고 있고, 이를 "predict missing information in ab abstract representation space" 하는 것으로 좋은 성능을 만들었다고 한다.
다음은 introduction 맨 마지막에 있는 we demonstrate that ~ 이다.
- I-JEPA learns strong off-the-shelf representation without the use of hand-crafted view augmentations.
- I-JEPA outperforms pixel-reconstruction methods (like MAE) on ImageNet01K linear probing, etc
- I-JEPA 는 view-invariant pretraining model 과 semantic task 에서 competitive 했고, low-level vision task 를 outperform 함. (applicable to a wider set of tasks)
- I-JEPA is also scalable and efficient
Background
보통 background 는 간단히 하고 넘어가는데 읽는 것만으로 도움이 많이 되는 내용들이라 자세히 작성하려 한다.
Self-supervised learning 은 "inputs 들 간의 relationship 을 capture" 하는 학습 방식이다. 이는 framework of Energy-Based Models (EBM) 으로 접근할 수 있다. incompatible input 에 대해서는 high energy를, compatible inputs 에 대해서는 low energy 를 할당하는 것이다. 현존하는 generative 및 non-generative model 에서는 아래 세가지 framework 로 설명할 수 있다.
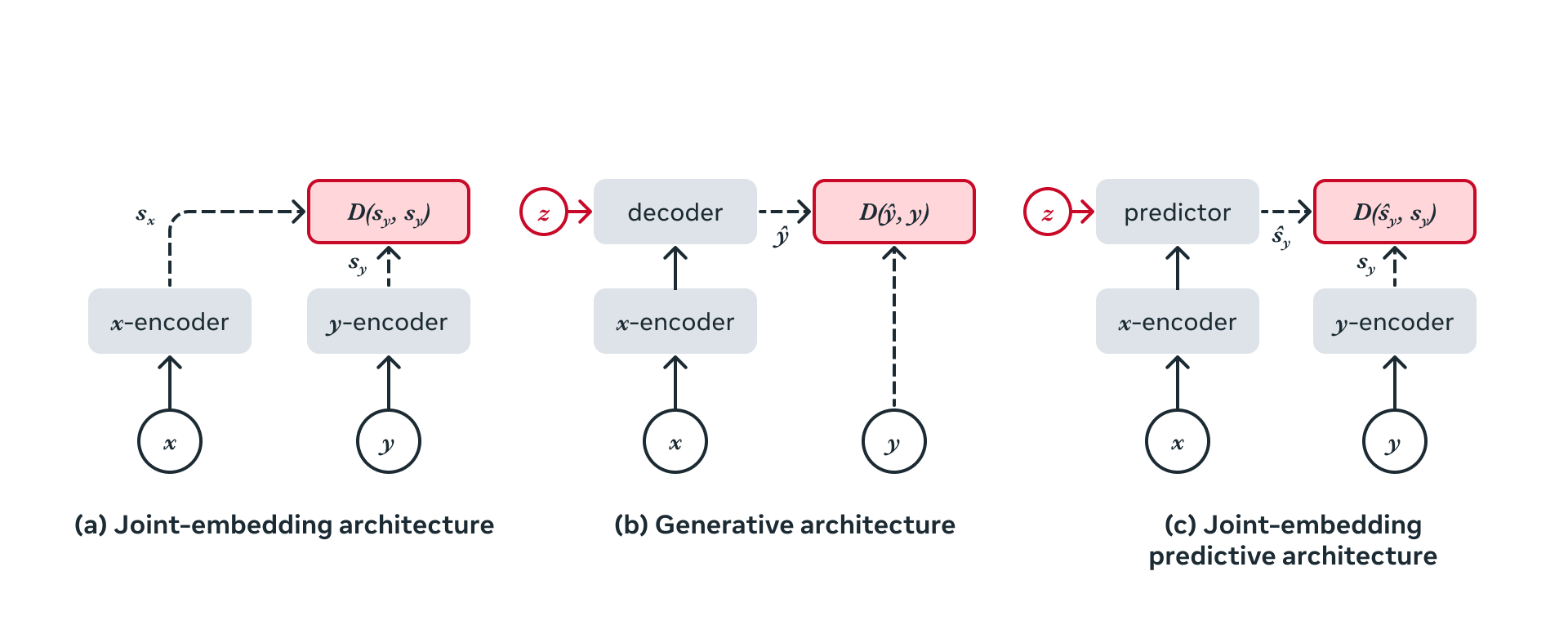
Joint Embedding Architectures
JEA 는 비슷한 input 에 대해 비슷한 embedding, 다른 input 에 대해 서로 다른 embedding 을 만들도록 학습한다. Main Challenge with JEA 는 "representaion collapse" (aka dimensional collapse) 이다. energy landscape 가 flat 한 경우, 즉 encoder 가 trivial embedding 을 만드는 현상이다. 이러한 dimensional collapse 를 막기 위해 다음과 같은 loss 들이 연구되었었다.
- contrastive losses : push apart embeddings of negative examples
- non-contrastive losses : minimize informational redundancy
- clustering-based approches : maximize the entropy of the average embedding
그림의 (a)에 해당하는 구조이다. representation space 에서 보통 loss가 계산된다. (전에도 리뷰한 적이 있는 내용인데) dimensional collapse 를 피하는 가장 핵심은 leverage an assymmetric architectural design between x-encoder and y-encoder 하는 것이었다.
Generative Architectures
여태 리뷰했던 논문들은 대부분 JEA 였고 생성 기반 구조를 가진 논문은 MAE 정도만 읽어본 것 같다. (b) 내용인데, 이 구조는 additional variable z (cGAN (SSL은 아니지만) 에서의 condition에 해당할 수도 있고 MAE 의 mask 에 해당하는 부분 또는 position token 일 수도 있다) condition 위에서, directly reconstruct a signal y from a compatible signal x 이고, loss 는 reconstructed signal 과 원래 있던 기존 signal 사이에서 계산된다.
Joint-Embedding Predictive Architectures
I-JEPA 에서 제안하는 구조이다. (c) 내용이고, (b) 구조와 상당히 닮아 있으면서, loss function is applied in embedding space (not input space) 라는 점이 key difference 이다. 또한 hand-crafted augmentation 을 없애는 대신, representation 상에서의 "mask", 즉 additional information "z" 를 달리하여 condition된 representation 을 predict 한다. 물론 representation space 상에서의 작업이기 때문에 dimensional collapse 를 염두에 두고 asymmetric architecture 를 설정하는 것도 중요함을 강조했다.
Method
now describe the proposed Image-based Joint-Embedding Predictive Architecture (I-JEPA)
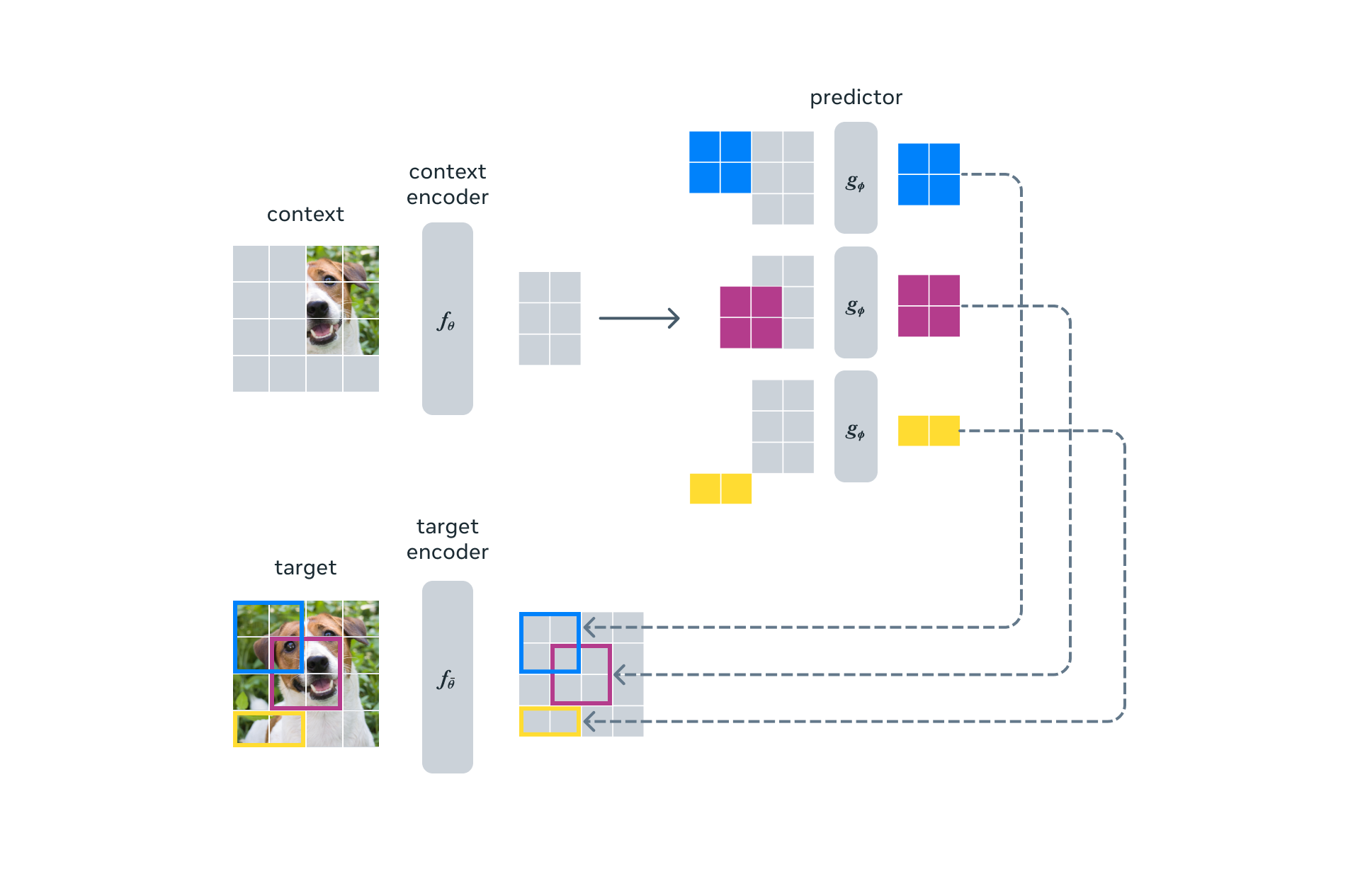
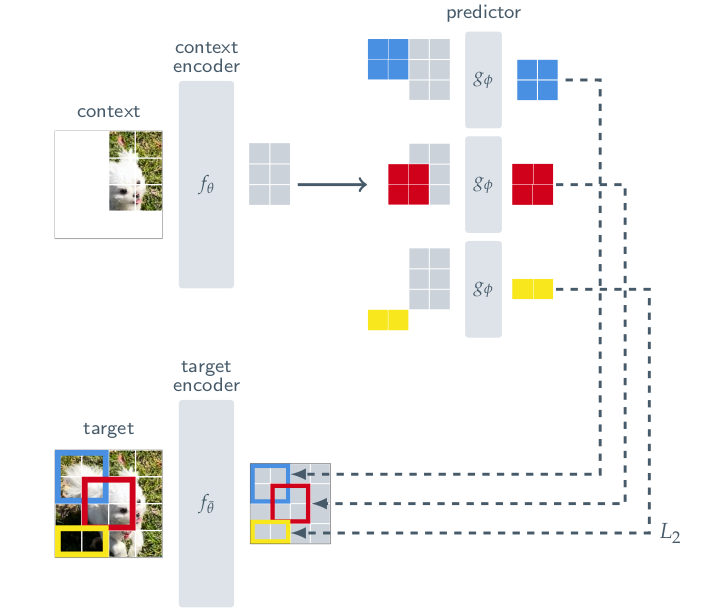
context-encoder 와 target-encoder, 그리고 predictor (가 아직 뭔지 모르지만) 에서 ViT architecture 를 사용했다. 아래 두 줄로 Overall objective 를 설명할 수 있다.
- given a context block
- predict the representations of various target blocks
(in the same image)
뭔가 MAE 와 비슷해보인다. 그럼 context block 과 target block 은 뭘까 라는 질문이 든다. 그 전에 target 이 뭔지부터 규명한다.
Targets
how we produce the targets? 우선 y 라는 image 를, N non-overlapping patches 를 생성한다. 이후 이를 target-encoder 에 집어넣고, patch-level representation = {} 을 얻는다. 그리고 여기서 loss 에 사용할 M 개의 block 을 뽑는데, 1 개의 block 마다 여러개의 patch 가 들어있고 이는 overlap 이 가능하다. 이 block 을 지칭하는 "mask" 하나를 라고 부르고, 그에 해당하는 i번째 block 의 patch set 을 라고 부른다. 보통 M 은 4고 aspect ratio 는 (아마 너비&높이) (0.75, 1.5) 이고, random scale (아마 크기) 는 (0.15,0.2) 이다. 저자는 "target block" 은 masking the "output of the target-encoder" 이지 not "input" 이라고 강조한다. 즉 input 에 바로 mask 씌우는 것이 아니라 embedding 된 것에 씌우는 것이라고 강조한다.
Contexts
Recall, the goal behind I-JEPA is to predict the target block representations from single context block. image 에서 random scale (0.85, 1.0) 으로 그리고 unit aspect ratio 로 a single block x 를 뽑고 이 mask 를 라고 부른다. target block 과 context block 모두 random 하게 뽑았으니 당연히 겹칠 수 있다.

위 그림은 target block 과 context block 의 예시이다. 마찬가지로 context block 역시 context encoder 에 넣어 를 만든다. 위의 target encoder 와는 독립된 네트워크이다.
Prediction
이제 도 뽑았고 M개의 target block 에 해당하는 patch representation set인 도 뽑았다. 이 때, 주어진 각 에 대해, predictor 는 context encoder 의 output 인 와 mask token for each patch 를 받아서 를 만든다.
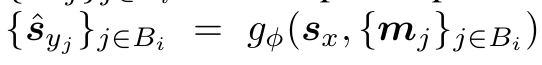
mask token is parameterized by a shared learnable vector with an added positional embedding. 즉, mask 는 constant 가 아니라 parameter 이다. 처음에는 이 부분이 굉장히 헷갈렸다.
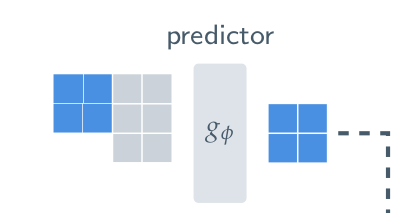
위 그림을 보면, context block 과 target block 이 전혀 겹치지 않고 있는데 어떻게 masking 을 한다는거지? 라는 의문이 들어 헷갈렸다. 하지만 물리적인 masking 을 의미하는 것이 아니라, 하나의 parameter z 즉 condition (너는 이 부분을 예측해야 해 라는 정보) 로 받아 들이고 나니 이해가 수월했다.
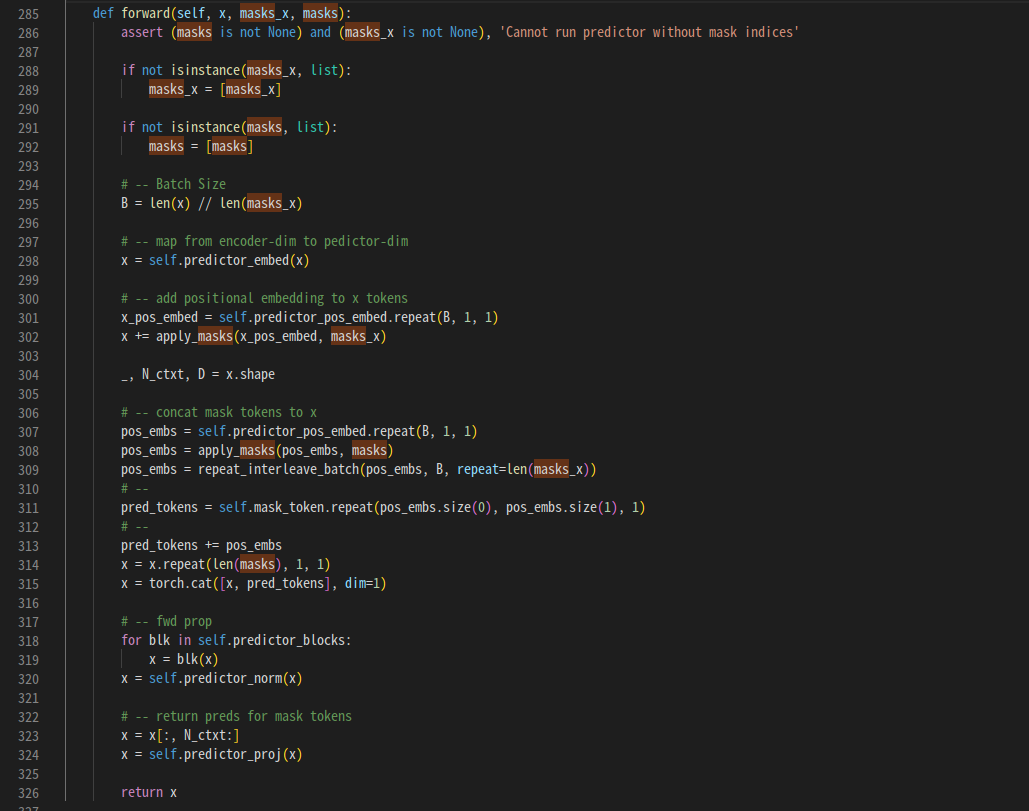
그냥 concat이다. context block patch representation 과 mask token, positional encoding 을 concat, add 해서 predictor network 에 통과시키고, 이를 target block patch representation 과 비교하는 것이다.
Loss
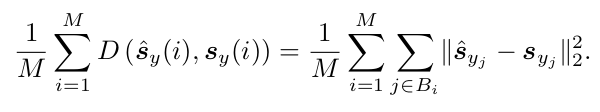
L2 loss 를 사용했다.
Image Classification
I-JEPA 가 좋은 high-level representation 을 augmentation 없이도 잘 학습한다는 것을 보이기 위해, linear probing 과 partial fine-tuning protocol 을 통한 image classificaion task 를 수행하였다. ImageNet-1K dataset 으로부터 pretrained 된 다른 self-supervised model 을 비교군으로 사용했고, 모든 I-JEPA 모델은 resolution 224 x 224 pixels 로 train 되었다.
ImageNet-1K
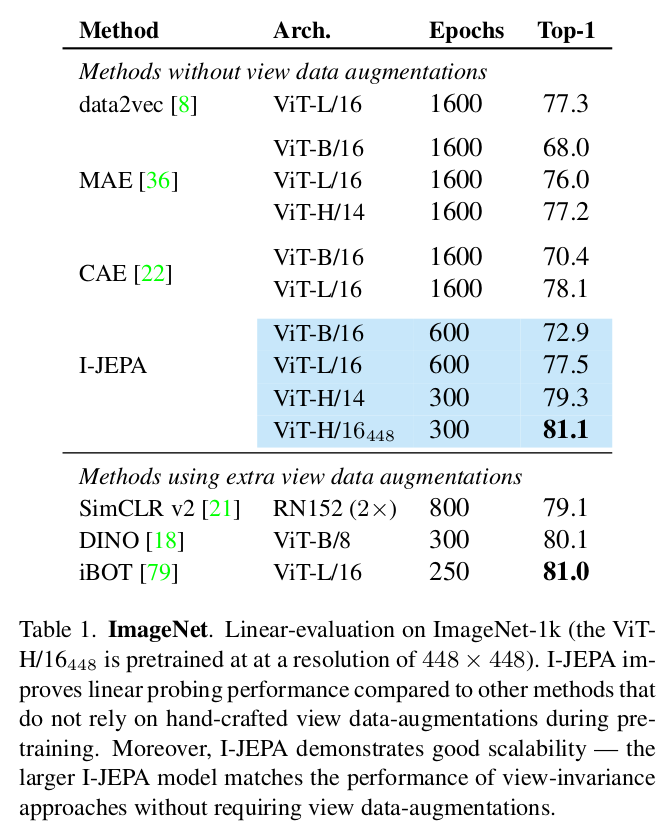
Table1. 은 common ImageNet-1K linear-evaluation benchmark 에 따른 성능 기록이다. SSL 사전학습 후 frozen 된 후 linear classifier 가 학습되었다. data augmentation 없는 MAE와 CAE (context autoencoder), data2vec 이 비교 실험 모델로 사용되었다. augmentation 이 없었음에도 불구하고 invariant approach (like iBOT) 과 competitive 한 성능을 보여주었다.
Low-shot ImageNet-1K
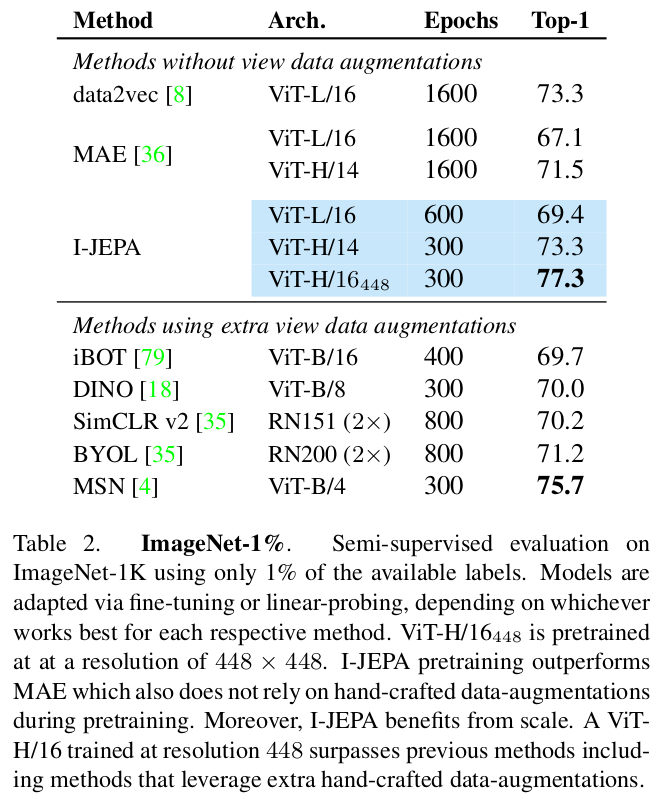
Table2 는 1% ImageNet benchmark performance 이다. 1%의 available ImageNet label 을 사용하였다. I-JEPA 는 MAE 보다 less pretraining epoch 을 사용하여 outperform 하였고, data2vec 보다 더 작은 네트워크를 사용하여 비슷한 성능을 내었다. input resolution 을 높여 (to 448) 학습했을 때 이전 data augmentation 을 사용했어야만 했던 invariance approach SSL 방식들의 결과를 모두 뛰어넘었다. 흠..
Transfer learning
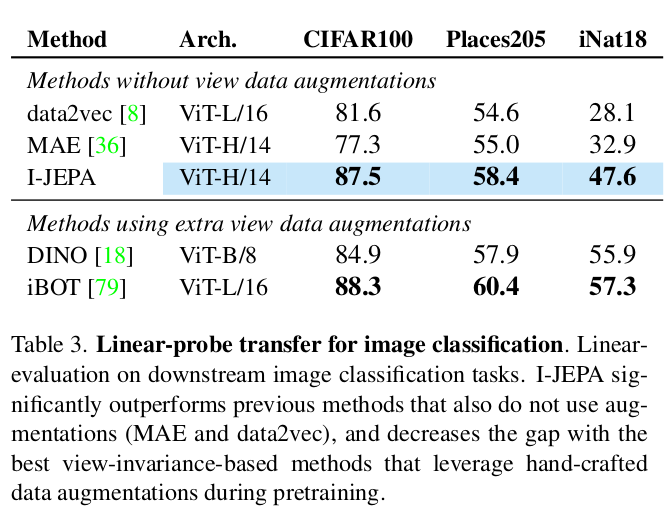
Local Prediction Tasks
위에선 classification task 에 대해 확인했는데, 기존 generative 성능을 뛰어넘을 뿐만 아니라 high semantic task 에 특화된 invariance based method 에도 competitive 한 성능을 기록했다. 이제 local image features 도 잘 학습하는지를 알아보았다.
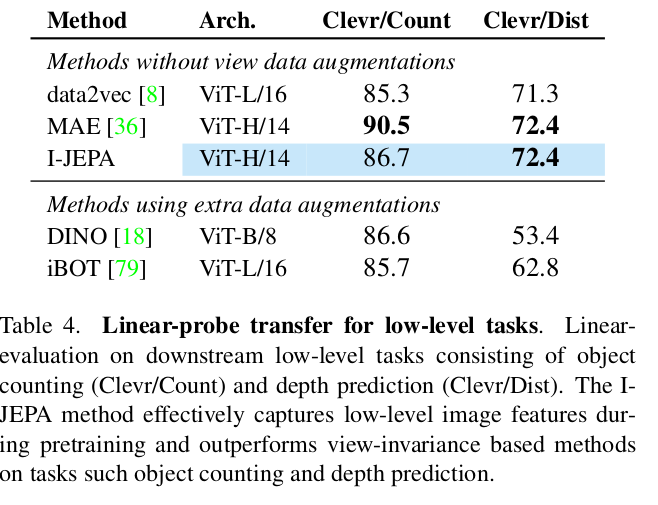
object counting과 depth prediction 에서 view-invariance based method 를 outperform 했다.
Scalability
Model Efficiency
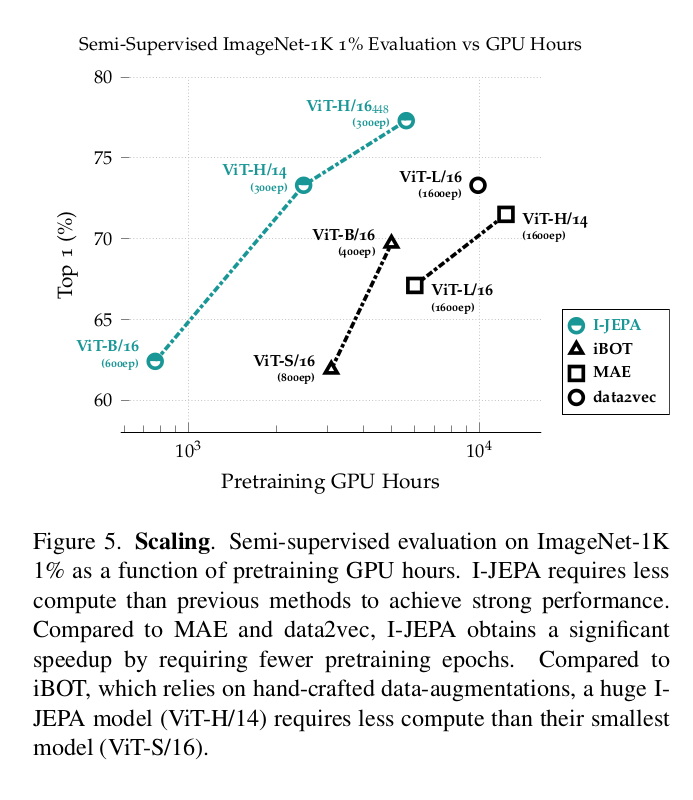
I-JEPA 는 기존 방법보다 highly scalable 함을 보이고 있다. 이전 방식들보다 더 적은 시간으로 더 높은 성능을 기록하고 있다. (task: semi-supervised evaluation on 1% ImageNet-1K)
Scaling data size & model size
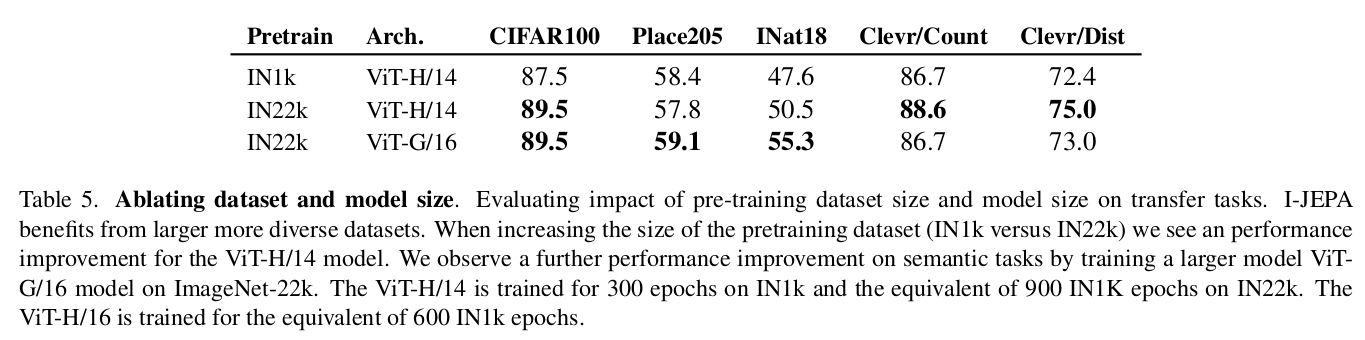
I-JEPA 는 larger dataset 에서 pretraining 될수록 benefit 이 있다는 것을 확인했고, larger model size 로부터 학습했을 때 더 높은 성능을 기록함을 확인하였다. (scalability)
Predictor Visualization
I-JEPA에서 predictor의 역할은, predictor에 context encoder 의 output 과 함께, positional mask token 을 통과시켰을 때 target block representation 을 예측하도록 하는 것이다. 이것이 representation space level 에서 이루어지기 때문에 이를 visualization 해보았다. 캬

너무 멋지다 방법은 RCDM framework 에 따라 decoder 를 학습했다고 하는데, 정확히 이해는 못했다. (논문 reference 를 참고하도록 하자)
Ablations
Predicting in representation space
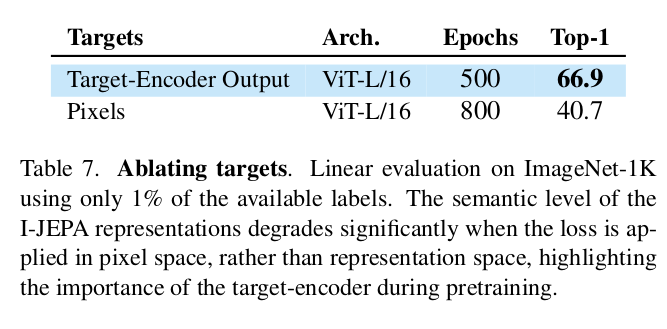
I-JEPA 의 핵심 중 하나는 representation space 에서 loss 를 계산한다는 것이다. 이것이 효용이 있는지 확인하기 위해 pixel-space 와 representation-space 에서 loss 계산해서 성능을 비교하였다.
Masking strategy

mask 방식을 달리하여 실험을 여럿 돌렸다.
Conclusion
재밌구만..

정보가 머릿속에 쏙쏙 들어오네요~~!@ 정말 좋은 글이에요