
2022.07.14 Thu
Batch Normalization and Dropout
Batch Normalization(배치 정규화)
-배치란 데이터셋의 전체 데이터 내에서 모델 학습 한번에 적용하기 위해 뽑아낸 데이터의 일부
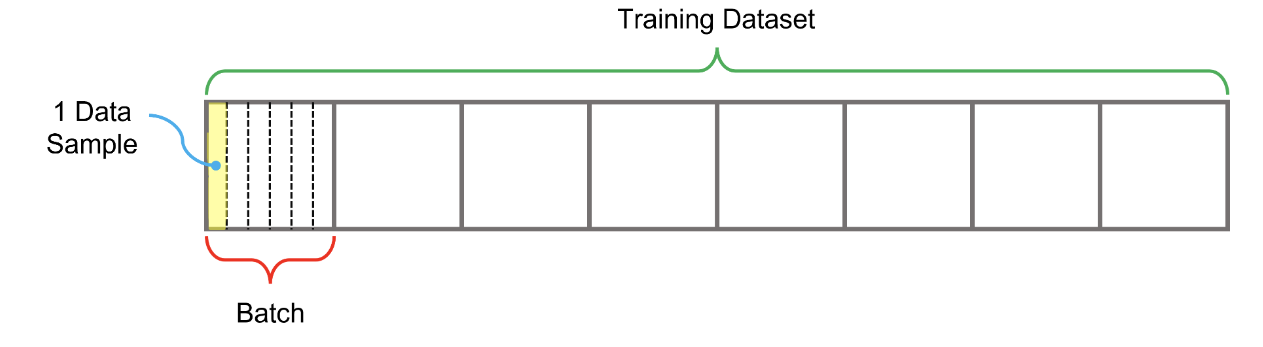
-정규화란 입력하는 데이터가 가지는 feature들의 값을 모두 같은 범위 내로 변경하는 작업(일반화, 학습의 안정성을 높인다, local optimum에 빠질 가능성이 줄어들어 더 높은 성능의 모델을 학습할 수 있음)
-
Min-Max Normalizaton(최소-최대 정규화)
각 feature의 최소와 최대값의 차이를 구한 다음에 feature 내 모든 값들을 이 차이로 나누는 것, 정규화된 값은 모두 0과 1 사이에 존재하게 됨

-
Standardization(표준화)
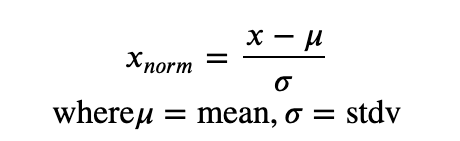
- Batch Normalization 알고리즘
배치에 정규화를 적용하는 기법
배치 정규화를 위해 구하는 평균과 표준편차 : 하나의 배치 전체에서 각 차원별로 구함(d차원이면 평균과 표준편차는 d개) - Why Batch Normalization?(왜 배치정규화를 적용하는 것인가)
기존 모델의 구조에 영향을 주지 않은 채 추가 layer 삽입 만으로 적용 가능. 즉, 새로운 component를 적용함에 있어 기존 시스템의 변경이 필요 없음. 범용성이 훌륭함 - 배치 정규화의 장점
-학습률(learning rate)을 높게 설정할 수 있어 학습 속도 향상
-가중치의 초깃값 선택에 대한 의존성 적어짐
-과적합 방지
-활성화함수로 Sigmoid 함수나 tanh 함수를 사용하더라도 경사소실(Gradient Vanishing) 문제를 크게 개선 가능
-Regularization 효과 - 배치 정규화의 단점
-미니 배치의 크기에 의존적
-각 시점에서 통계치가 다른 RNN에서 적용하기 어려움
Dropout
인공 신경망 내에서 일부 뉴런들의 연결을 삭제(drop) 하는 것
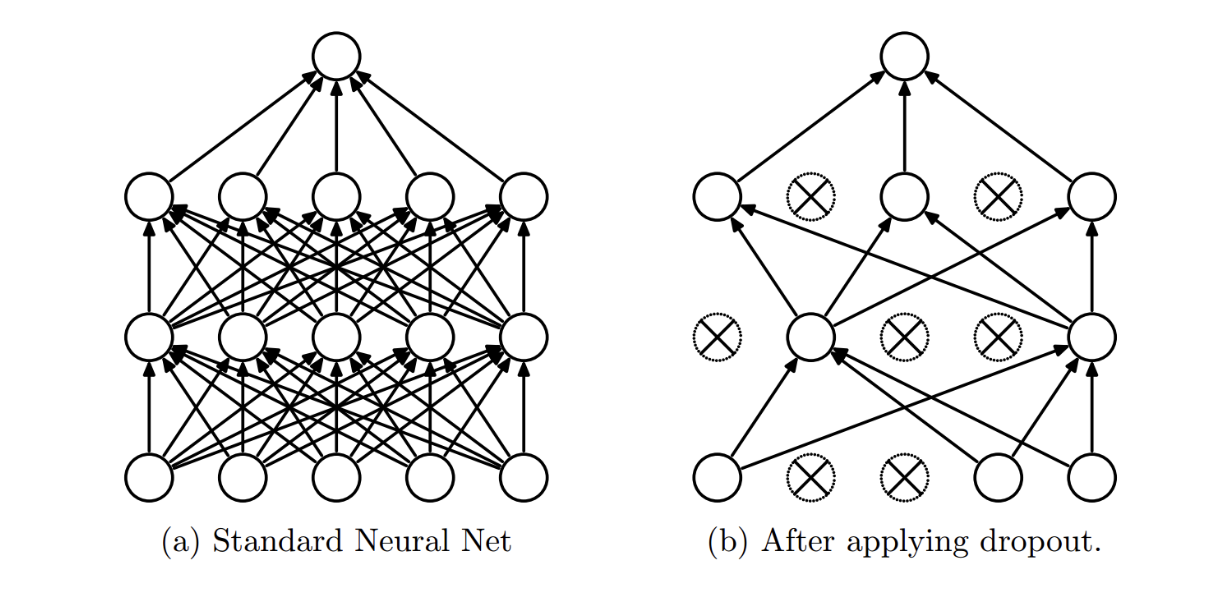
-> 연결이 끊긴 뉴런은 가중치 계산에 관여하지 않게 되면서 파라미터 수가 줄어드는 효과를 얻을 수 있음
- hyperparameter : 각 뉴런이 비활성화 될 확률(p로 표시)
- 뉴런 선택이 매번 랜덤으로 이루어지기 때문에 서로 다른 여러개의 모델들을 합쳐서(Ensemble) 학습하는 듯한 효과를 준다
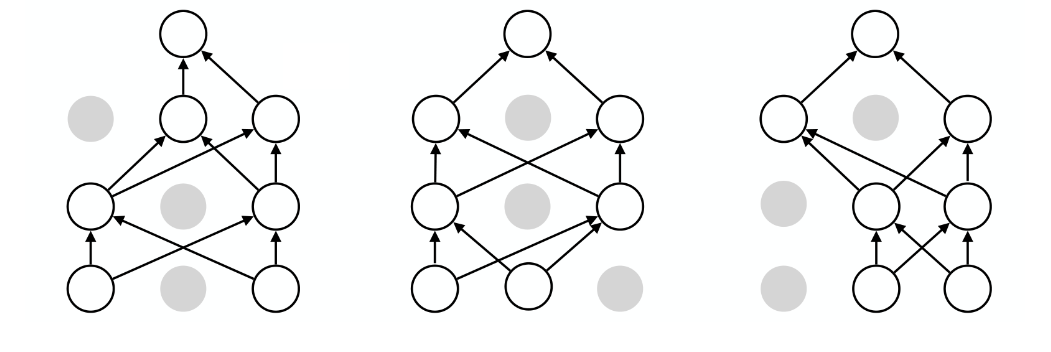
Tensorflow에서 Batch Normalization과 Dropout 사용하기
- 배치 정규화
tf.layers.batch_normalization() - 드롭아웃
tf.keras.layers.Dropout(rate = p)
[실습]
Batch Normalization과 Dropout

SW Engineer