
📕 1교시
연관관계은 DB 끼리 Relation을 맺는 것이다.
우리는 hibernate롤 relation을 연결할 것이다. 자바입장에서


ORM -> 귀찮은 것을 매우 편하게 해준다.

공식이 있다 FK 는 무조건 N에 붙는다.
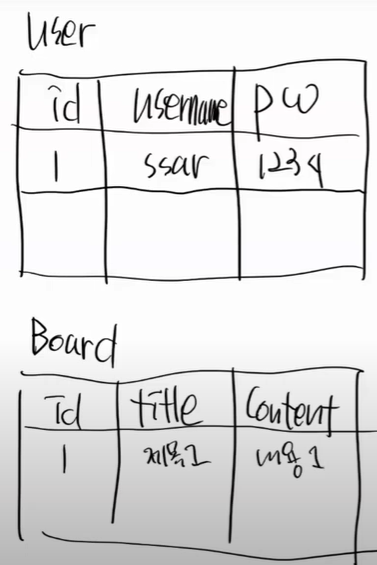
그림을 보자

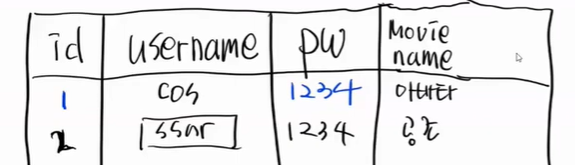
처음에는 고객관리만 하는 테이블이였다.
갑자기 영화 예메 프로그램이 추가된다.

지금까지는 문제가 없다. 1번 유저가 다른 영화를 보고싶다.

이렇게 넣으면 조회를 할 떄 문제가 생긴다.
아바타를 본 사람을 찾는 조회쿼리를 보내면, 조회가 되지 않는다.

여기서 배우는 것은 하나의 column에는 2개를 넣으면 안된다.
근데 선임이 이렇게 다음과 같이 바꾸어도 가능하다고 한다.

근데 시스템이 느려진다. 왜느려질까?
이렇게 검색을 하면 풀 스캔을 한다. 처음부터 끝까지 읽고 moivename을 projection을 한다.
그 다음에 문자열을 비교까지 하기 떄문에 수행 속도가 느려진다.

따라서 이 시스템을 갈아 엎어야 한다. 다음과 같이 바꾸면 아바타가 조회가 될 것이다.

하지만 또 문제가 생긴다. 무슨 문제가 생길까?
시스템관리가 어려워진다. 하나의 데이터가 변경되면 전부 변경을 해야하기 때문이다.
갑자기 회원수정을 하는 경우이다.
즉, 회원 수정 또는 삭제하는 경우는 지금 시스템과 맞이 않는다.
이런 방법은 insert와 select 방법이 가장 좋다, 즉 수정 삭제가 없으면 추가만 하고 골라오는 것만 가능하다.
이러한 방법이 NoSQL이다. 예로는 MongoDB가 있다.
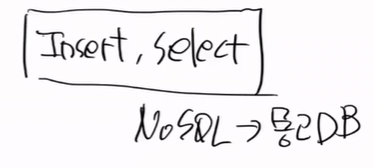
이 시스템은 보통 빅데이터에서 사용을 많이 한다.
따라서 update를 할 떄는 매우 힘들다. 그래서 쪼개는 것이다.
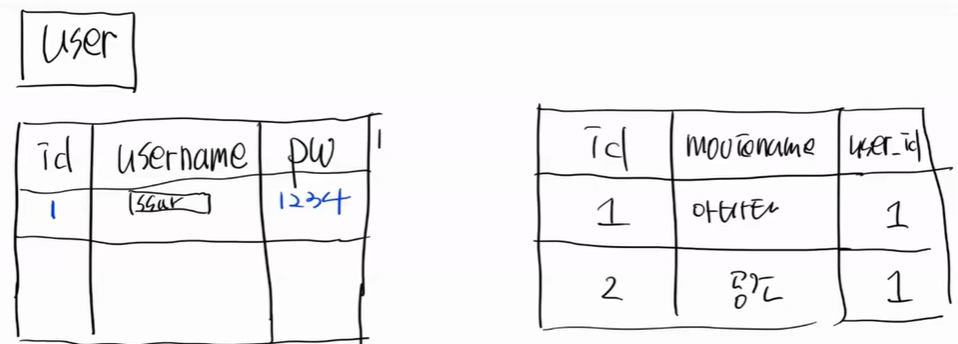
user_id 는 FK이다. 이 상태는 user 정보를 수정해도 아무런 상관이 없다.
수정시 우리는 1개만 하면 된다. 이게 relation이다.

user1명은 movie를 N개를 볼수 있다.
또 반대로도 봐야하기 때문에, Movie 1개는 user 1명이 볼 수 있다고 하자.
그러면 이러한 관계가 나온다. 가장 큰 걸로 잡고 1 : N

근데 만약 영화를 여러명이 볼 수 있다고 하면 N : N이 된다.

FK는 반드시 N쪽에 붙어야한다. 이것을 우리는 연관관계의 주인이라고 한다.
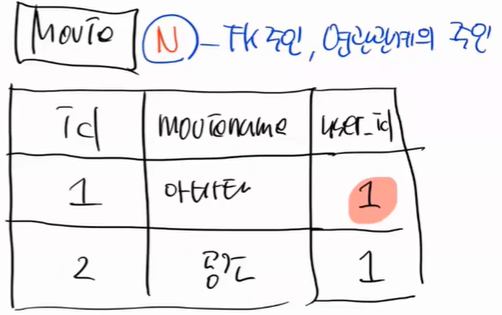
내가 이제 게시글을 작성한다고 해보자. 게시글을 여러개를 작성해야한다.
여기서 DB에서 1개의 Column은 1개의 타입을 넣울 수있지, 오브젝트는 넣지 못한다.
여기서 스칼라의 개념을 알고가자.
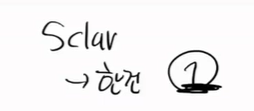
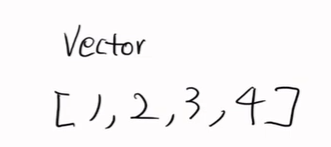
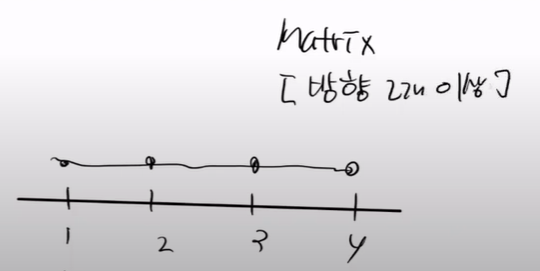
스칼라는 1건, 백터는 리스트(방향)이 있는 것이다. 그럼 메트릭스는 무엇일까? 2차원 배열이라고 생각하면 편하다.
2차원 배열은 평면을 만들 수 있다. 다음과 같은 것을 만들 수 이싿.
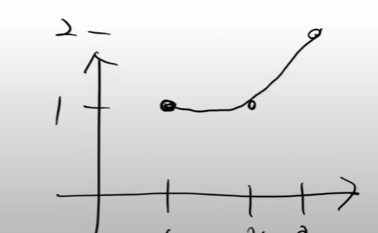
즉, 스칼라는 방향이 없고, 벡터부터 방향이 있는 것이다.
만약 스칼라 데이터가 아니고 1건이 아니면 무조건 쪼개면 된다.
관계를 보자, user 1명은 n개의 게시글을 사용할 수 있고, 게시글 1개는 1명이 작성할 수 있다.


따라서 관계는 1 : N 이 되고, FK는 N 쪽에 붙어야 하므로
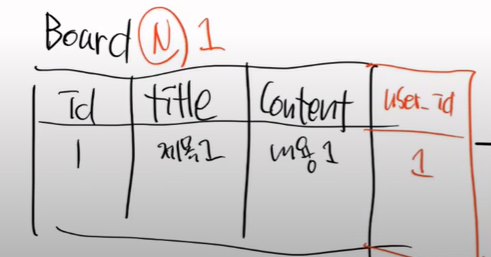
다음과 같이 만들어 진다.
결구 스칼라면 일단 붙여보고 판단을 하고, 스칼라가 아니면 처음부터 쪼개서 N인 쪽에다가 FK를 붙여주면 된다.
따라서 항상 그림을 그리면서 판단을 해보자
이제 개념은 어느정도 이해가 되었으니까 코드를 보자
📕 2교시
구조
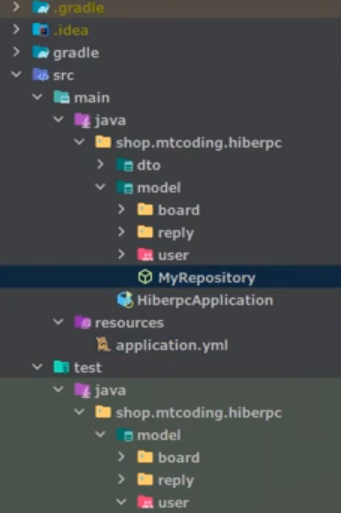
먼저 application.yml 해당 부분을 주석 처리를 하자

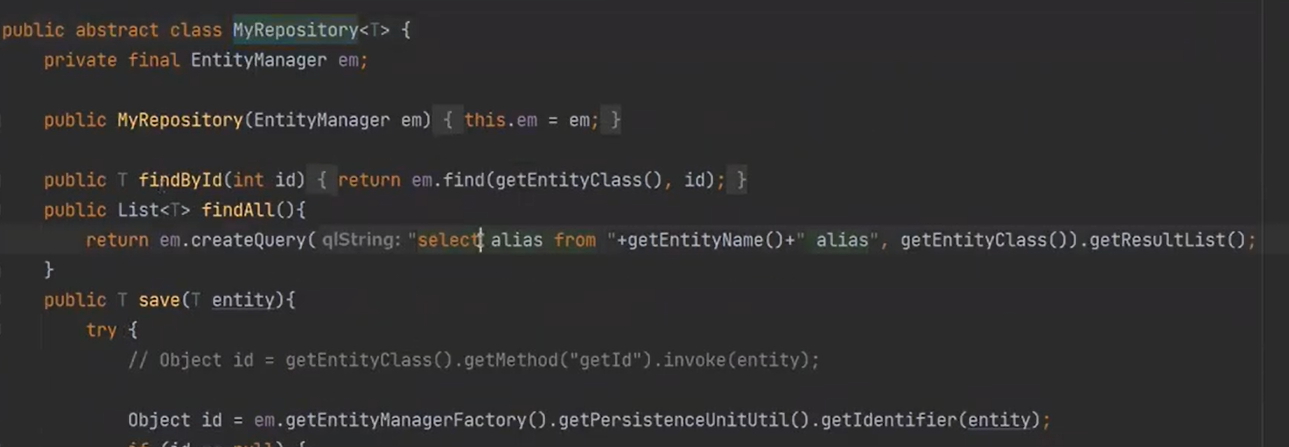
MyRepository는 이전에 한 것을 그대로 가져왔다.
컨트롤러가 없다, 우리는 컨트롤러를 공부할 것이 아니기때문에
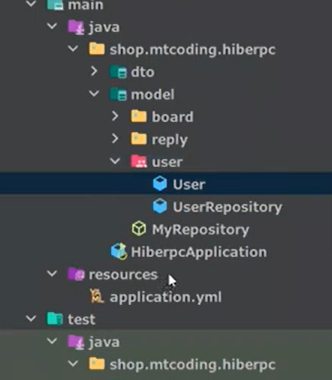
Entity를 붙인다고 테이블이 만들어지는 것은 아니고, 하이버네이트가 관리를 시작한 것이다.
테이블이 만들어지는 것은 application.yml의 해당 부분이다.

PK 와 auto-increment를 설정한다.

그리고 table은 user_tb로 한다. User 경우 특정한 DB의 경우 고유 식별자가 될 수 있기 떄문이다.
table의 컨벤션은 언더스코어를 많이 붙인다. _
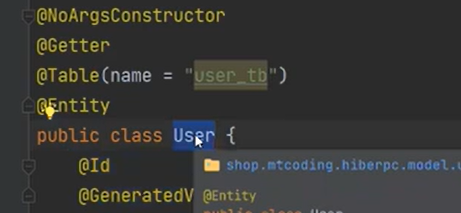
그리고 jsonignore 은 OM가 파싱하지 않는다. 해당 PW는 절대로 주지 않기 위해서이다.
그리고 Noargconstructor -> 하이버네이트 떄문이다.
그리고 setter가 없는 경우, 리플렉션으로 private 변수에 접근하기 떄문이다.

그리고 의미있는 setter를 만들었따.

그리고 어노테이션 toString은 영원히 추천하지 않는다. 항상 다음과 같이 적자
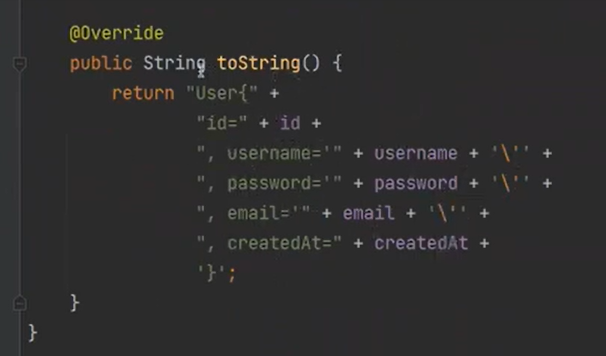
테스트 부분을 보자
DataJpa를 하면 전부 뜨지만, 단 UserRepository는 뜨지 않기 떄문에 강제로 Import 를 해줘야한다.

하지만 만약 이렇게 해주면 Import는 필요가 없다.


초기화 하는 코드

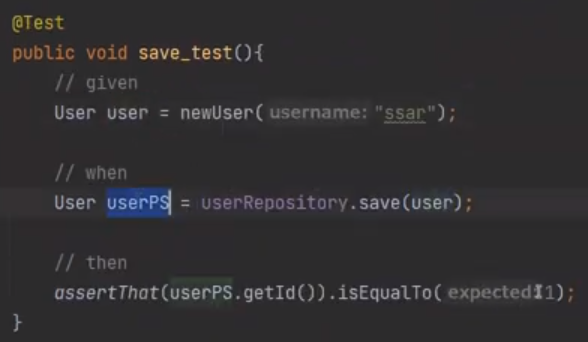
save하는 테스트 부분
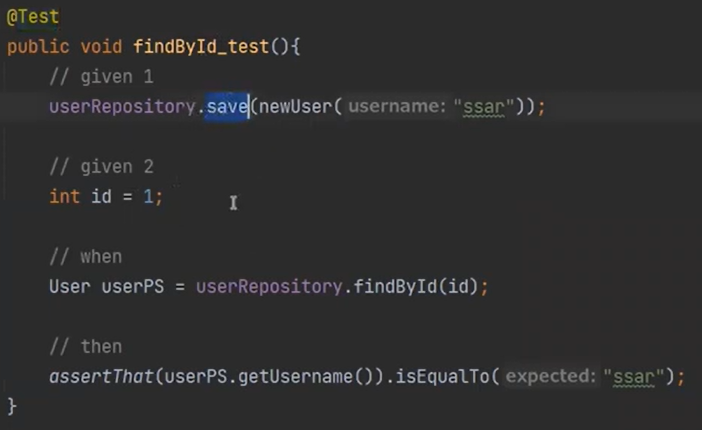
findById 부분
만약에 쿼리를 보고 싶으면 추가를 해준다.
update부분
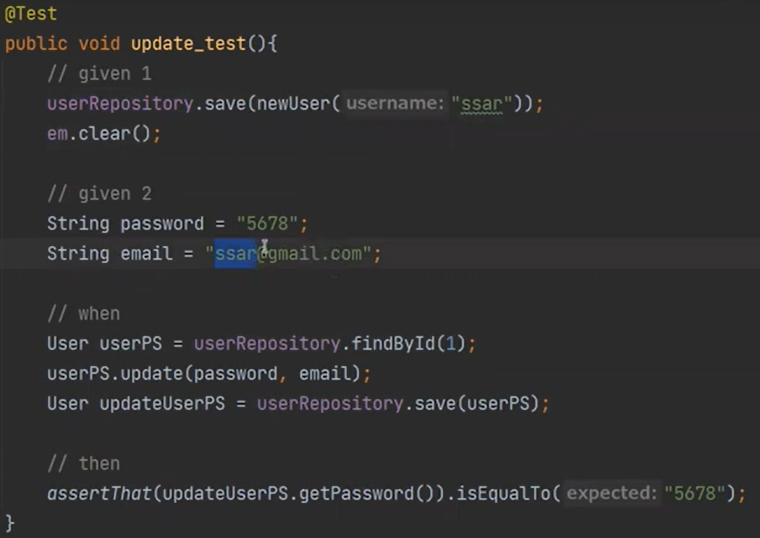
update를 하는 법은 1) 영속화를 시키고, 2) 변경하고, 3) 트렌잭션이 종료한다.(변경감지, flush)

원래는 flush()만 해도 된다.

save를 들어가보면, merge를 한다.
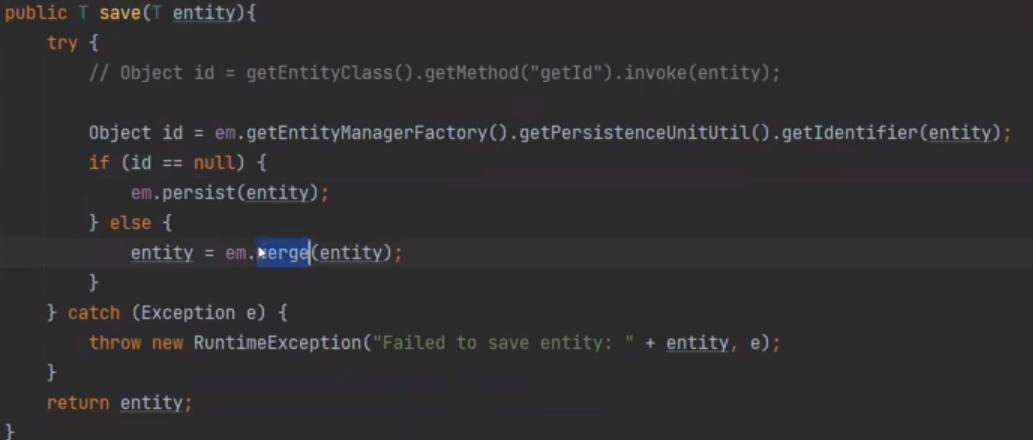
하지만 test를 실행시키면 update쿼리가 날라가지 않는다. 왜냐하면 test가 끝날떄 rollback이 되기 때문이다.
따라서 update 쿼리를 볼려면 em.flush()를 추가하자

그리고 test 실행을 하면

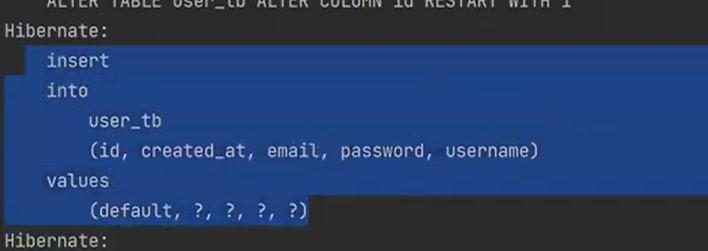

캐싱이 안됬기 때문에

flush 할때 퀄리가 날라간다. 그러면 왜 flush할 떄 쿼리가 날라갈까?
이유는 하이버네이트가 변경감지를 하기 때문이다.
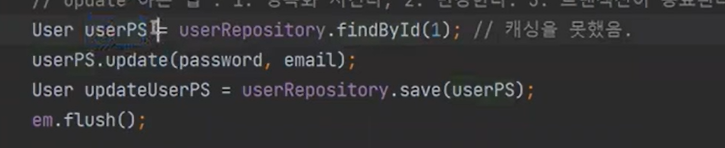
원래 테스트의 코드는 정상적으로 이렇게 만든다.(가장 효육적)

그리고 then에서 어떤 값을 검증할지는 본인이 생각하면 나온다.

지금은 PW와 EMAIL을 검증하는 거니까 PW를 검증하면 된다.
2개의 값이 제대로 변경이 되었는지 확인해야한다.
그다음에 delete를 보자
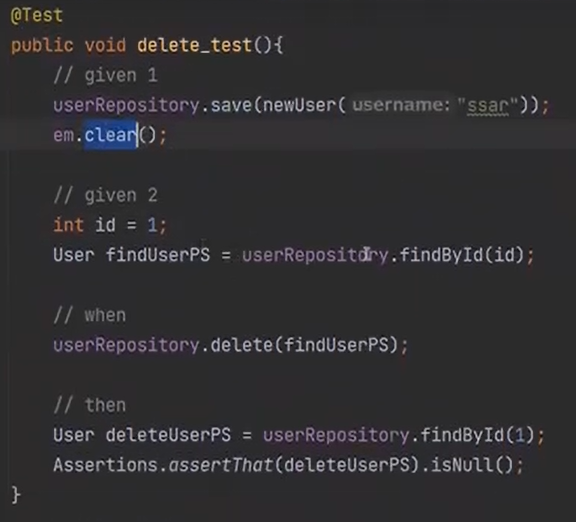
코드를 보면 findById로 찾은 findUserPS를 delete로 삭제한다.
delete 내부로 들어가보면
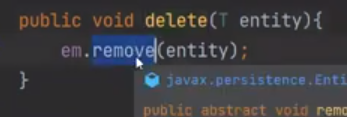
하지만 delete 쿼리는 날라가지 않는다. 이것 또한 roll back이 됐기 떄문이다.
따라서 flush를 추가하고 실행하면
findAll 코드

실행을 하면 insert 2번, 즉 2번 save가 됬다.

그리고 findAll을 하니까, 쿼리는 날라간다.

왜냐하면 전체를 뒤져야하니까 영속성 컨텍스트에 2건이 있다고 해도, 이 2건이 전부일지는 알수 없기 때문이다.
DB에 10건이 있을지 100건이 있을지 우리는 알 수 없기 떄문이다. 단 영속성 컨텍스트에만 2건이 있는 것이다.
그래서 DB로 가서 전체 조회를 하는 것이다.
만약 내가 findById 즉, 조회를 1건만 하면 DB로 가서 전체 조회를 할 필요가 있을까?

할 필요가 없다. 이유는 이미 우리가 찾고자하는 id는 영속성 컨텍스트에 있기 때문이다.
즉, 정리하면 findAll은 우리가 원하는 것이 2건이여도 DB에 2건이 있을지 없을지 모르기 떄문에 반드시 findAll을 통해서 영속화를 시키는데, findById는 이미 영속화가 되어있기 떄문에 해당 쿼리가 날라가지 않는다.
끝!
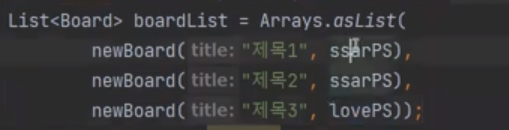
이제 Board를 만들어보자
해당 부분을 주석 처리하자


주석 처리
이부분 은 지워보자
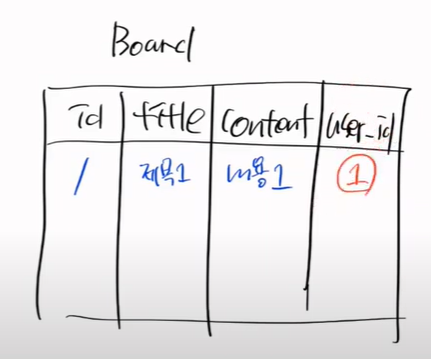
Board는 title, content creatAt를 들고 있다.
누가 적었는지를 알아야한다. 따라서 모델링을 할때 DB세상에 있는 것을 자바세상과 똑같이 만들어야 한다.

이 방식은 OM 방식이다. 우리는 이제 ORM을 배울 것이다.
따라서 하이버네이트 세상으로 바꾸자

하지만 이렇게 짜면, DB에는 User라는 타입이 존재하지 않는다.
DB는 테이블의 모든 데이터가 스칼라이다. 즉, 1건이다.

이것을 원자성이라고 한다.
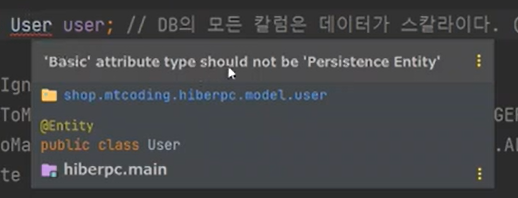
보면 할 수 없다고 한다.
따라서 FK라고 알려줘야한다.

하이버네이트가 이제 Board를 FK로 보고 Many부분이 Board가 되고, One은 User가 된다.
따라서 자바에서는 다음과 같이 적지만
DB에서는 user_id로 적는다.

절대로 User에다가 FK를 걸으면 안된다. 왜냐하면 FK는 N 쪽인 Board에다가 걸어야하기 때문이다.
그래서 Board를 연관관계의 주인이라고 한다.
이 부분을 전체 주석 처리하고 실행을 해보자
Board로 가서 서버를 실행 하면
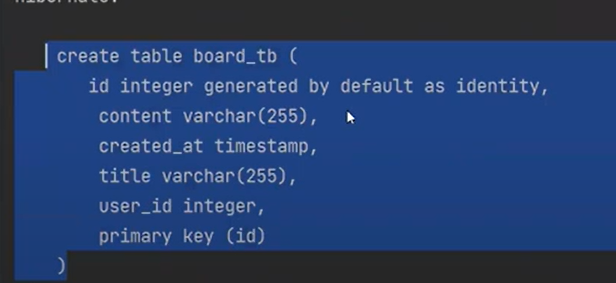

보면 DB에는 user_id로 만들어지는 것을 볼 수 있다.
즉 @ManyToOne만 꼽으면 FK로 만들어준다.

근데 어떻게 user_id를 int로 알고 있을까??
왜냐하면 User에 @Id가 있는 부분이 id이기 때문이다. 간단하다.
이제 Board 테이블을 DB로 부터 모델링을 전부 했으니까, 이제 BoardRepository를 만들어보자
BoardRepository의 해당 부분을 주석처리
이제 Level1TEst를 해보자

DI와 Entity 매니저와 SetUp을 했다.
save를 보면
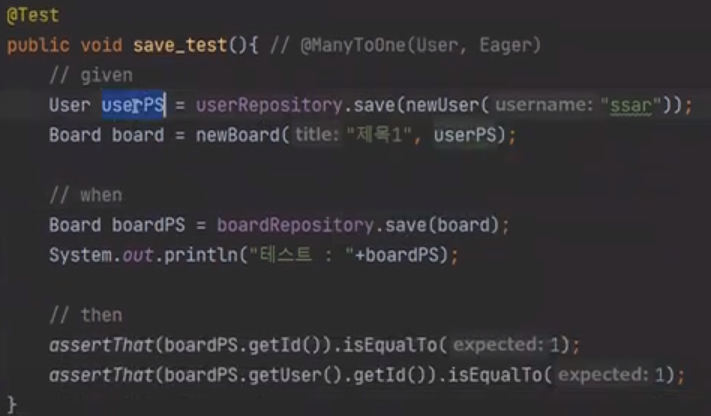
user가 있어야한다.
User를 먼저 save를 하고 영속화를 시킨다.

그리고 그것을 newBoard에 넣었다. newBoard를 보자
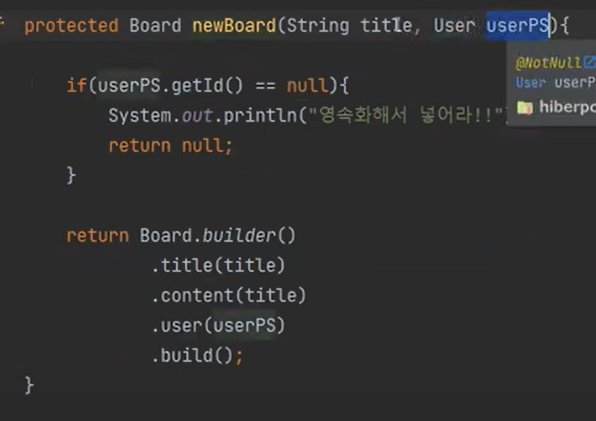
아마 원래는 int형태의 id를 넘겼을 것이다. 하지만 이것은 ORM이 아니다!

그래서 일단 가장 먼저 해야할 것은
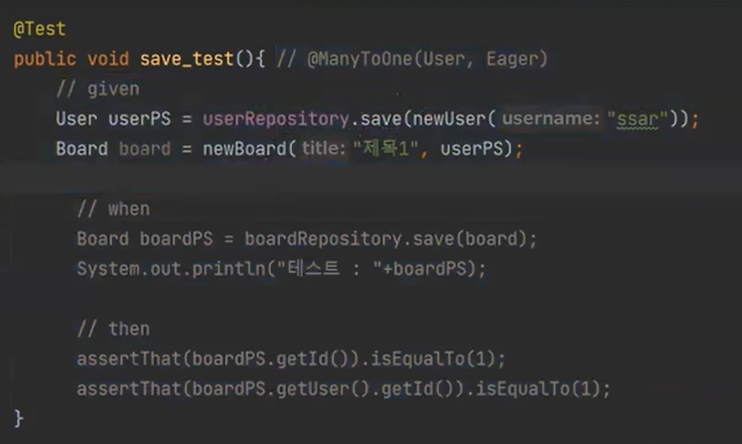
이 부분만 먼저 실행을 해보자
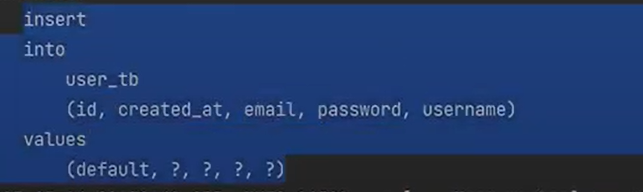
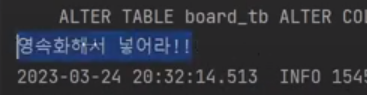
user는 영속화를 했지만 board 객체를 영속화하라는 것은 나오지 않았다.
언제 뜰까? 아마 이렇게 User만 영속화 하지 않으면 나올 것이다.
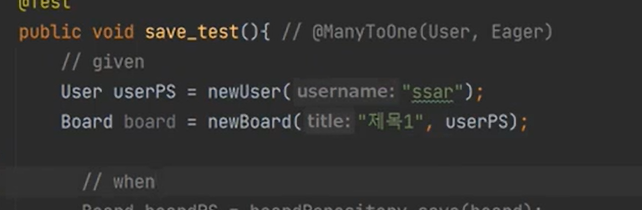
그러면 board는 뭘까? 바로 비영속이다.

영속화 된것은 UserPS이기 때문이다. board는 되지 않았다.
이제 주석을 풀자, 그리고 실행을 하면

가장 먼저 user 가 insert가 되고, board가 insert 된다.

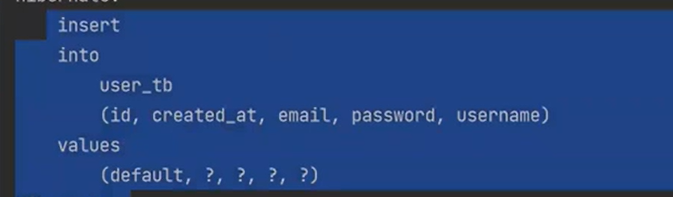



그리고 Board 내부에 영속화된 User 객체가 있다.
만약 save2 를 만들고 다음과 같이 적는다면 "영속화해라" 라는 것이 뜰까?
안뜬다. 왜냐하면 PK를 넣었기 떄문이다. 하지만 user는 비영속 객체이다.
지금 User는 DB에 없는 상태이다.
이렇게 하면?


제약조건을 위배햤다는 에러가 나온다. 무슨 제약조건을 위배했을까?
DB에 없는 값이 참조되어서 들어가니까, insert가 되지 않는 것이다.
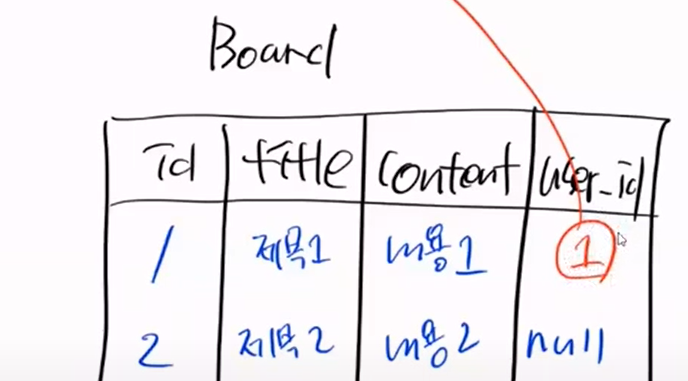
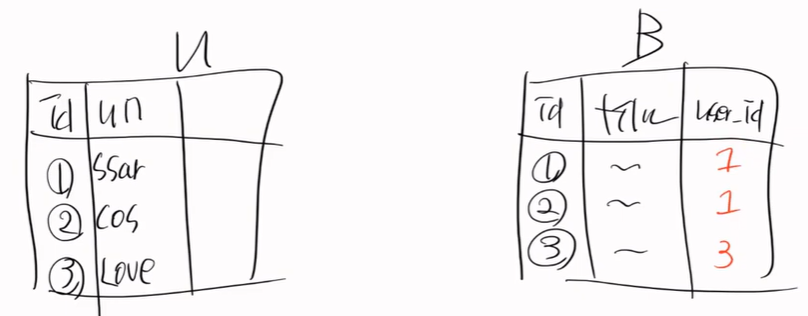
그림으로 한번 보자
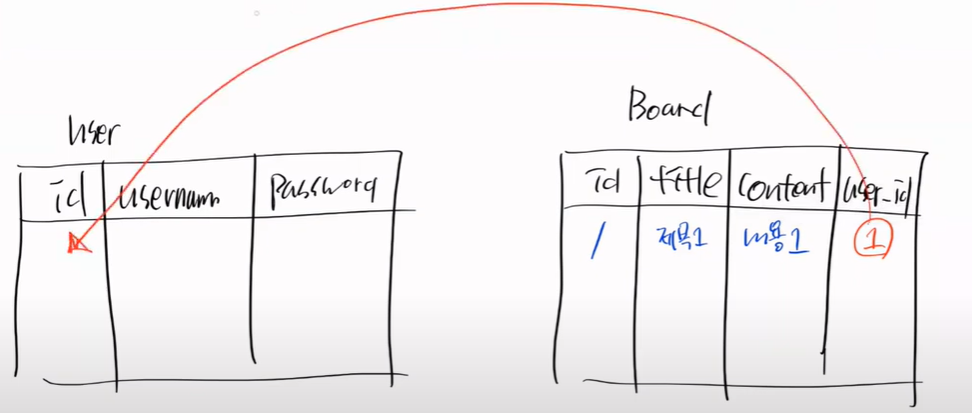
지금 user table이 있고 board talble이 있다.
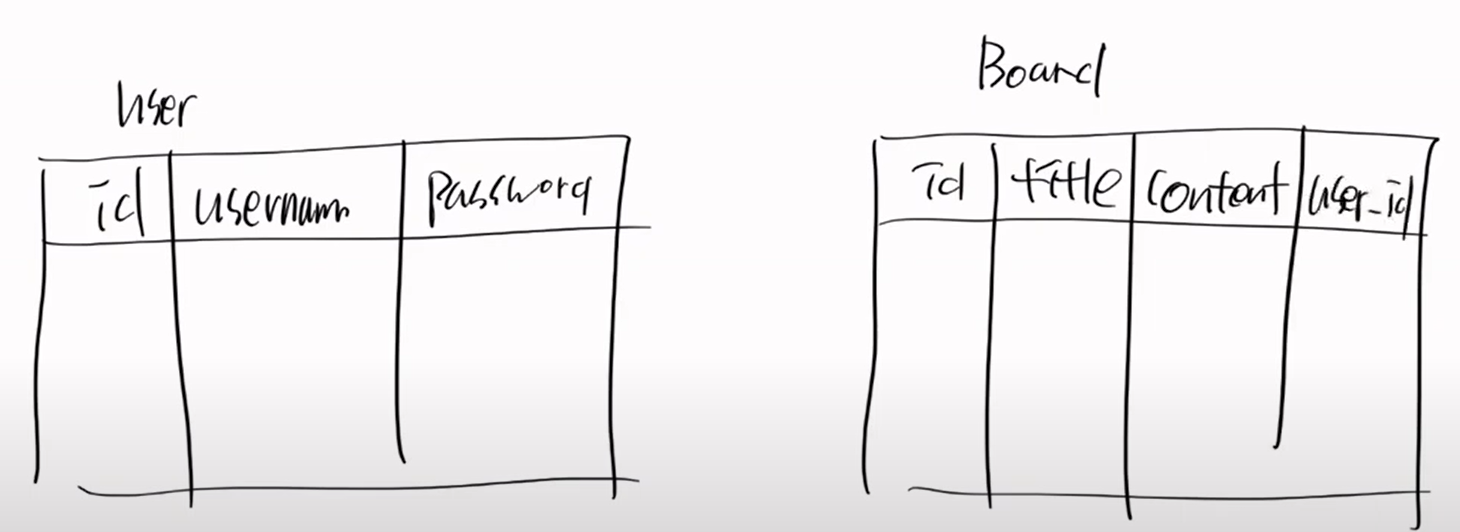
이 상황에서 user는 아무것도 없는 상황이다.
이 상태에서 board는 user_id에 user.setId(1)이라고 강제로 FK 설정을 했다. 불법적인 일이다.
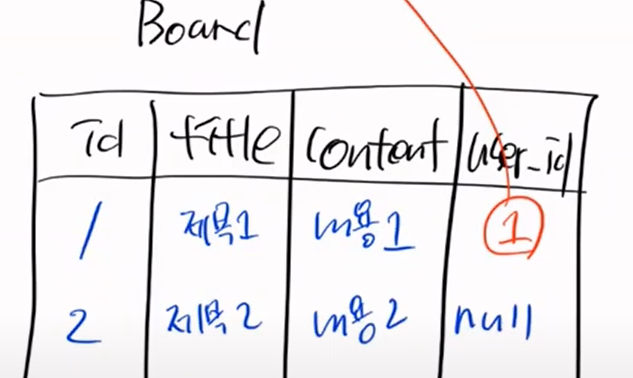
근데 참조할 값이 없다. 제약조건 위배다

이번에는 null을 넣어보자

어떻게 될까? 실행을 하면 null을 넣었기 떄문에 터졌다

이거는 하이버네이트가 문법적으로 막아준 것이다.
보면 RuntimeExceptino일떄 발생했다.

DB 쪽에서 발생한 것이 아니다.
이렇게 나와야 DB쪽에서 잘못 된 것이다. 제약 조건 위배 부분

null을 넣는다는 것은 이렇게 되는 것이다.
이것을 하이버네이트가 막아주는 것이다.
이번에는 이렇게 해보자
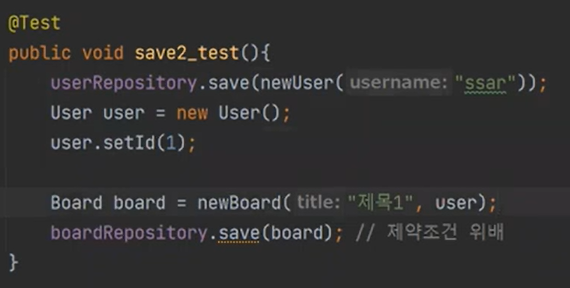
이거는 어떻게 될까? DB에 이미 저장을 했기 떄문에 DB에는 ssar이 존재한다.
User user는 비영속이다. 그리고 1이라고 사기를 쳤다.

그러면 newBoard는 통과 한다, 이유는 ID가 있기 떄문에
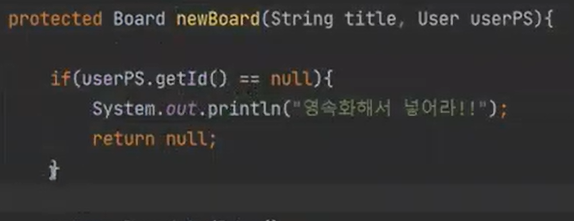
실행을 해보면, insert가 된다.
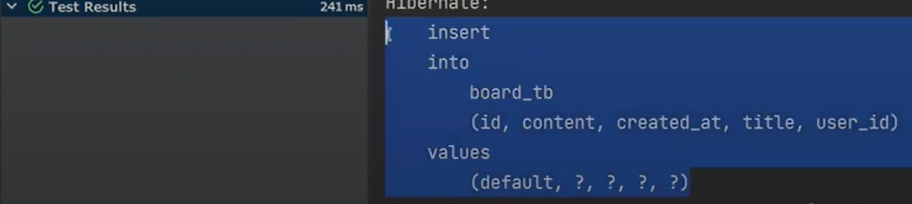
결국은 하이버네이트는 PK가 있는지 없는지를 보는 것이다. 다른일은 중요하게 생각하지 않는다.
만약 PK가 존재하면 DB에서 조회를 해서 있으면, 다음과 같이 save로 미리 insert를 하고 비영속 객체에 id를 할당해서 사기를 칠 수 있는 것이다.
하지만 이런 행동은 하지말고, 반드시 조회를 해서 넣자.
무조건 DB에서 조회를 해서 모든 것을 영속화 시킨뒤에 넣으면 된다.
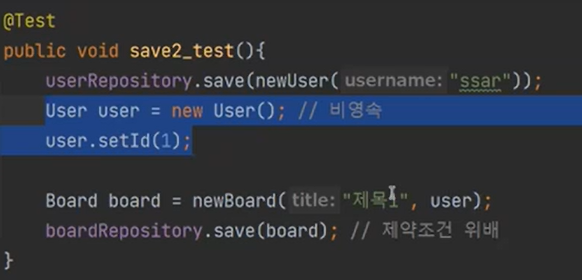
물론 이렇게 하는게 핵심이다. 나는 Board에 user_id에다가 1을 넣고 싶은 것이다.
심지어 영속이든 비영속이든 상과없이 setId(1)을 해서 번호도 부여를 했다.
그리고 save 될때는 board가 save되지 user가 save되지는 않는다. borad는 그냥 user FK만 들고와서 save가 되는 것이다.
핵심은 user의 PK를 들고와서 Board에 넣는 것이 핵심이다.
하이버네이트는 개발자는 DB세상 몰라도 되니까 자바 객체(User user)로 넣으라는 것이다. 이게 ORM이다.
정리하면 하이버네이트는 개발자가 자바 객체를 가져와서 넣으면 알아서 ORM을 해준다.
그래서 save를 보면

이미 user가 있는 상태다. 그리고 1번이 있는지 조회를 하자, 왜냐하면 터질수도 있기 때문이다.
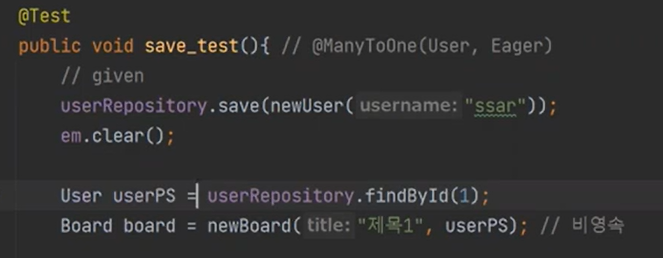
user를 조회를 해서 newBoard에다가 넣고 save를 한 것이다.
그리고 검증을 한것이다.
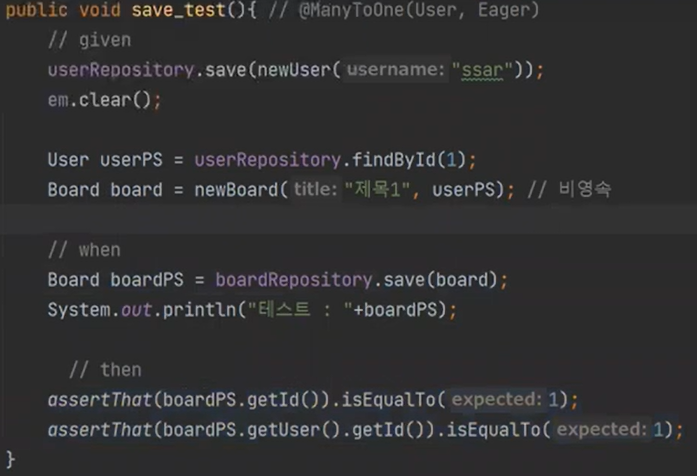
📕 3교시
핵심이 연관관계의 주인을 insert하고 싶으면, 그 연관관계의 주인이 아닌 것을 영속화(조회)시켜서 넣자.
공식이다. 연관관계가 아닌 것을 넣기 위해서는 무조건 조회를 해서 넣어야한다.
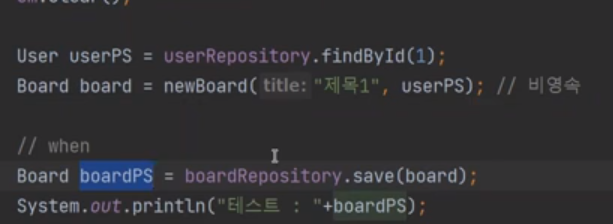
이번에는 findById를 보자
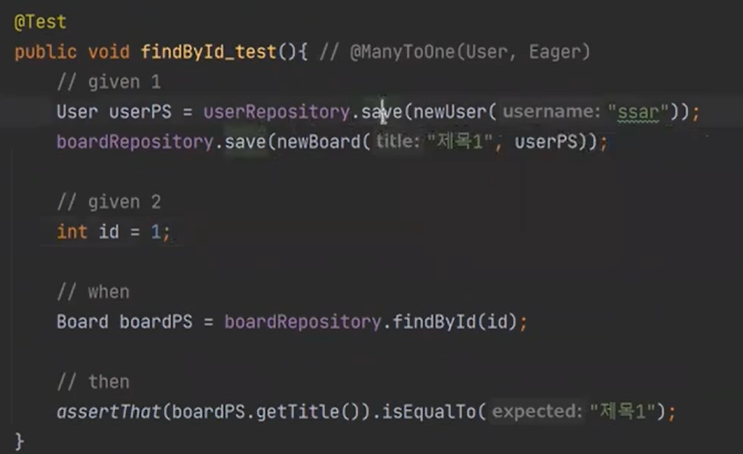

영속화된 것(User)을 넣고, (Board)save를 했다.
실행을 하면 쿼리가 발동하지 않는다. 왜냐하면 캐싱이 되어있기 때문이다.
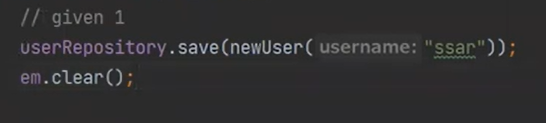
따라서 clear()를 해줘야한다.

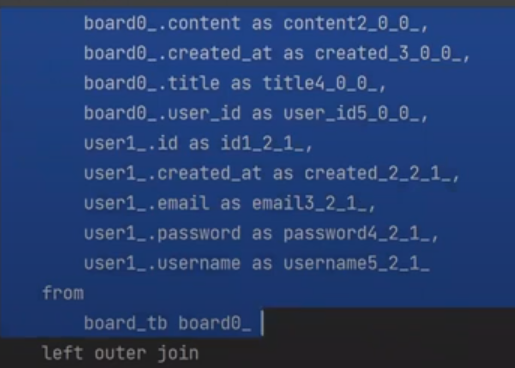
그리고 실행을 하면 신기한 일이 일어난다.

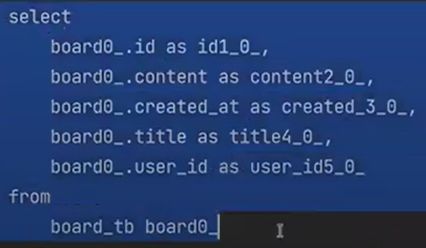
나는 분명 board만 findById(select)를 했다.

근데 user가 left outer join을 해서 나왔다.
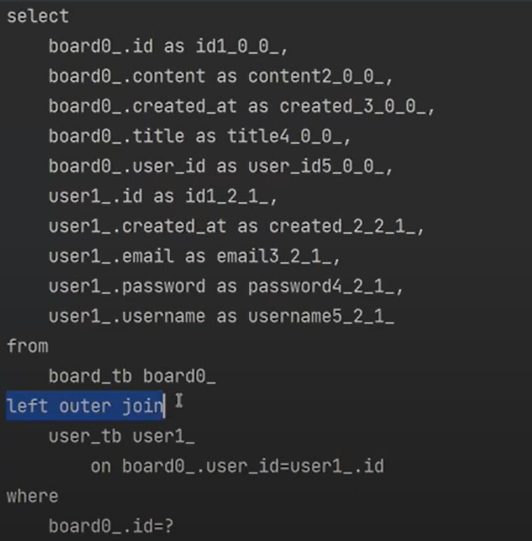
이게 ORM이다. 매우매우 편하다. 원래는 이렇게 할려면
DTO(Data Transfer Object)를 만들어야한다.
위의 결과를 h2-console에 넣으면
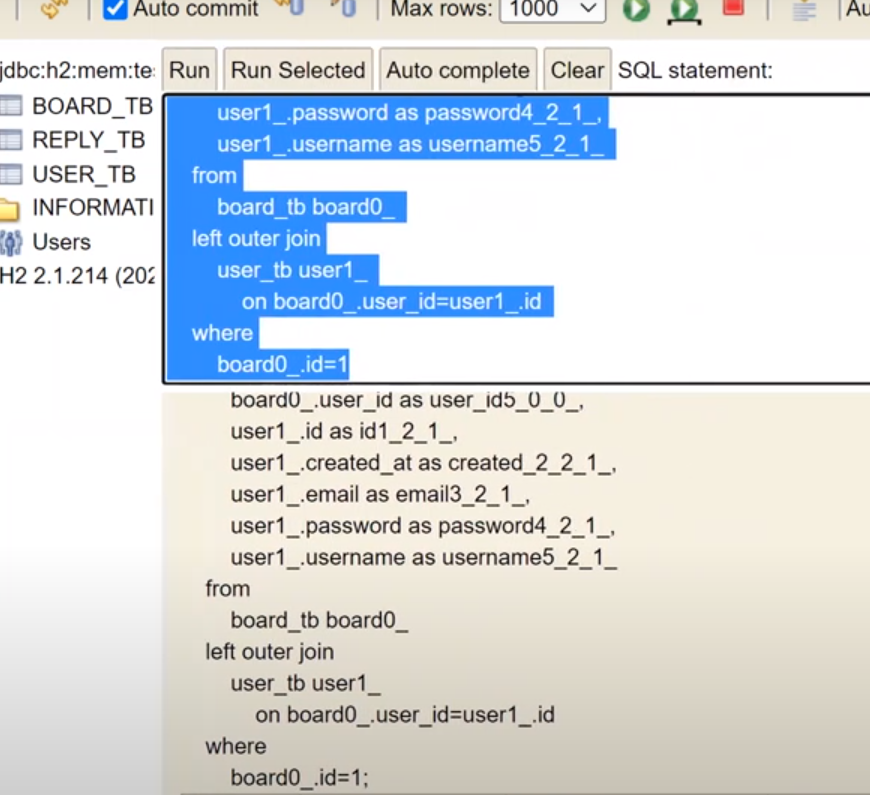
다음과 같이 결과가 나온다

데이터가 Flat하게 나온다. 그러면 이 Flat한 Data를 받을 자바의 Model이 필요하다.
그래서 다음과 같은 코드를 작성햐고, Mapping을 해야한다.
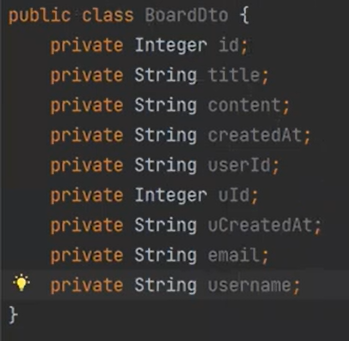
따라서 이런식으로 받으려면 쿼리형태도 달라져야한다.
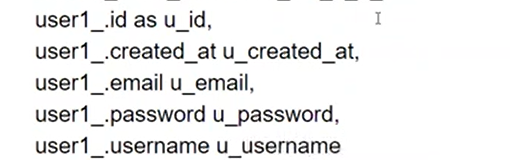

그리고 전부 u를 붙여야한다
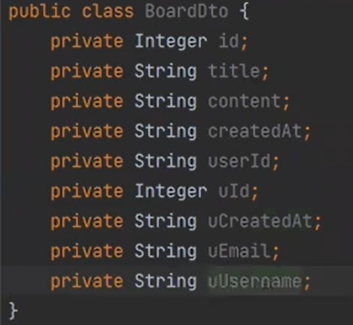
DB에서 _ 로 적으면 하이버네이트 세상에서는 카멜 표기법으로 받을 수 있다.
원래는 이렇게 했지만, ORM을 이용하면 user에 넣어준다.

그래서 다시 findById를 실행하면

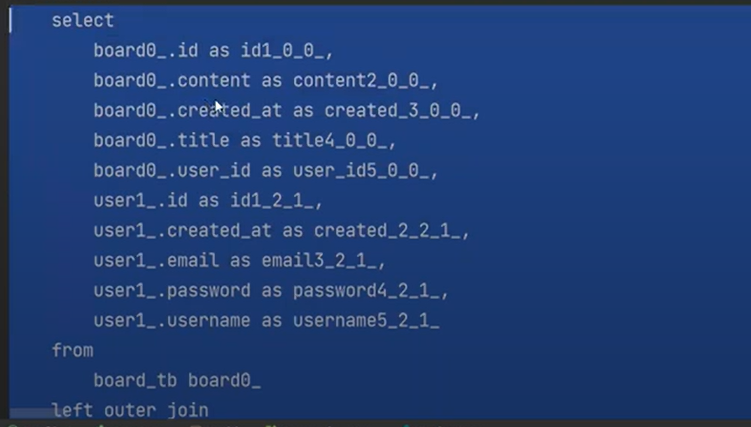
원래는 쿼리에 대한 DTO가 필요했다.
BoardPS의 내부를 한번 봐보자, 코드를 다음과 같이 적자
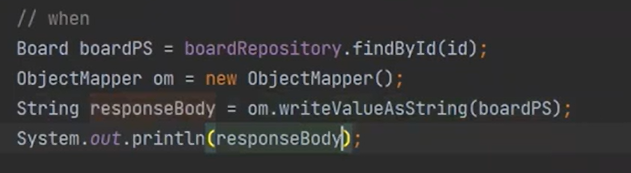
이제 다시 실행하면 JSON 데이터가 있다.

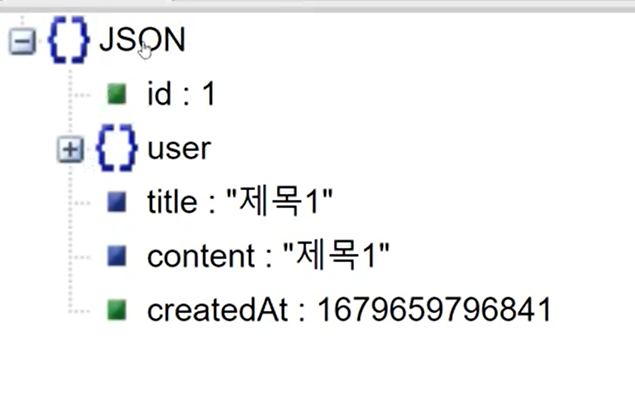
즉, DTO 처럼 Flat하게 나오는 것이 아니라, 굴곡이 있게 나온다. ORM기법을 통해서 Mapping을 전부 해준다.
우리는 레이어를 다음과 같이 배웠다. 해당 부분은 통신이 일어나는 부분이다.
통신이 일어나면 버퍼를 사용한다. 따라서 통신을 위한 DTO를 만들어야한다.
만약 하이버네이트가 없다면, DTO를 만들어야한다.
DB에서 받은 것은 노출이 되면 안되는 중요한 정보가 있을 수 있다.
그래서 앞으로 전달을 할떄 또 변환을 해야한다.
그리고 그것을 Client에게 전달을 하는 것이다.

하지만 우리는 이렇게 할 필요가 없다. 왜냐하면 하이버네이트가 ORM을 해주기 떄문이다.
그래서 실제로 하이버네이트가 DB로 부터 DTO(Flat)을 받는다.
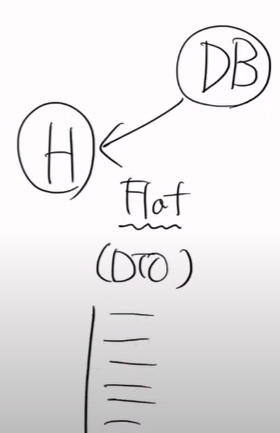
하이버네이트가 Repo에게 전달할 떄는 ORM을 통해서 보낸다.
요게 ORM이다.
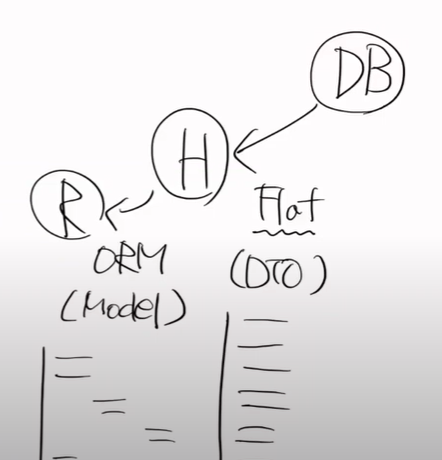
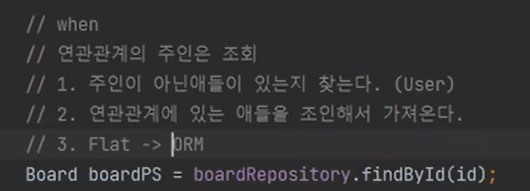
즉 findById에서, 연관관계의 주인을 조회하면 1) 주인이 아닌 애들이 있는지 찾는다(user) 2) 연관관계가 있는 애들을 join해서 가져온다. 3) FLAT -> ORM
그래서 board에서 주인이 아닌 애들 user를 찾고, user를 join해서 가져오고, 가져올때 Flat Data -> ORM을 해서 가져온다.
이게 하이버네이트이다.
delete를 보자

그리고 findById로 board를 조회하고 board를 삭제하고 flush를 한다.
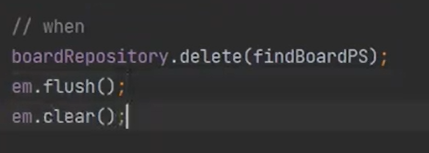
뒤에 findById가 있어서 쿼리를 확인할 수 없으니까 clear를 해주자
실행하면


em.clear()

join을 했다.

삭제가 될때 board만 삭제되었다. user는 삭제되지 않았다.

마지막 then부분은 당연히 null 일 것이다. 왜냐하면 delete를 했기 떄문에

Board에서는 uesr가 있을까? 있다, 통채로 넣었기 떄문에 하지만 delete를 할 때는 board만 삭제되고 user는 삭제되지 않는다.
이제 findAll을 보자


실행하면

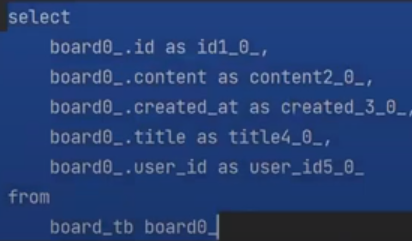
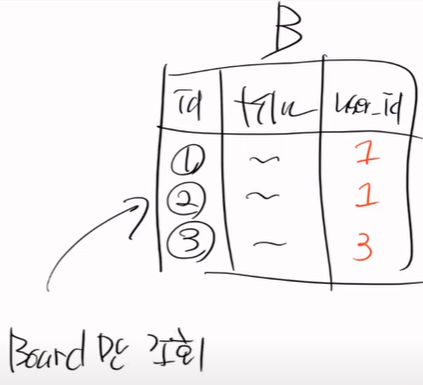
board가 3건인데, 1번 조회를 하고 user table을 3번 select한다.
왜 user select가 3번이 일어났을까? 생각해보자

내가 board를 select하면 user row 1, 2, 3 이렇게 되고 3개의 row 전부 동일한 user가 아니다.
보면 board는 user가 3개 이니까. board row는 user 3건이다. 즉, 3개의 row를 가진다.
첫번쨰 row - user1
두번쨰 row - user2
세번쨰 row - user3
그래서 board를 한번에 select하고 user를 각각 3번 조회를 한것이다.
첫번쨰 row - user1

두번쨰 row - user2

세번쨰 row - user3
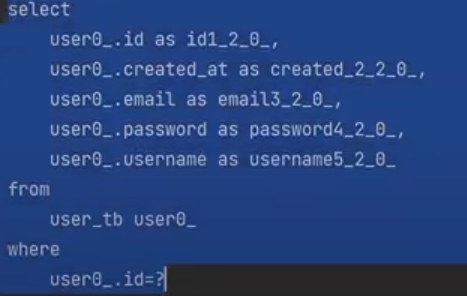
만약 다음과 같이 바꾸면 조회가 몇번 일어날까? 실행을 하면
board select 1번
user select 2번이 일어난다. 왜냐하면 같은 ssarPS가 캐싱이 되기 떄문이다.


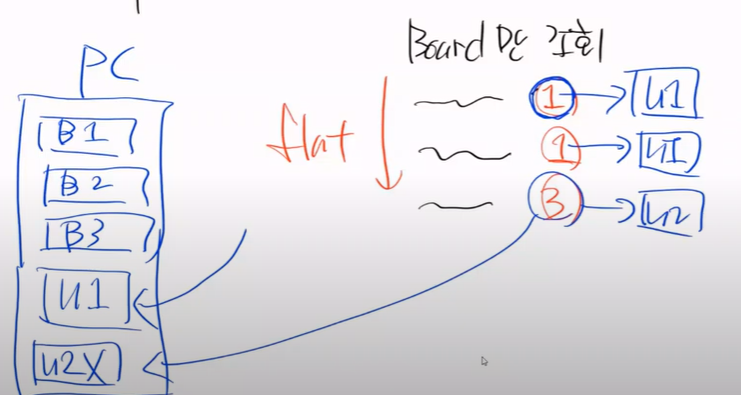
그림으로 이해해보자
내가 findAll 하니까 board만 조회를 했다.
다음과 같이 Flat하게 들고왔다.

하이버네이트는 ORM을 하니까 각각에 대해서 DB에서 조회를 하는 것이다.
지금 PC에는 다음과같이 되어있다.
그리고 user1번을 영속화 해서 조회했다.

그리고 2번째를 캐싱하니까 있으니까 끝
3번쨰는 없으니까 조회
그러면 이 쿼리는 좋을까? 아니다
만약 board데이터가 100건이면, board select 1번 각 user에 대한 select를 진행해서 총 101번이 일어날 것이다.
이거를 쉽게 해결하는 방법이 있다.
주석 해제를 하자
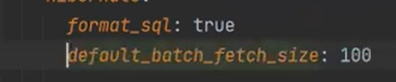
다시 실행을 하면, board select 1번 user select 1번만 한다.(in query를 하기 떄문에)
내가 100까지만 설정했기 떄문에 user 100개 까지만 한번에 처리를 해준다.
만약 10으로 했다면?

board 100개

원래면, board select 1번, user select 100번이 날라간다.
하지만 in query를 10번으로 설정했으니까 board select 1번, user select 10번 날라간다.
따라서 defalut size를 정하면 깔끔하게 이 N + 1문제가 해결된다.
N + 1문제 -> in query 날리기 + defalut size
1) 주인만 select한다.
2) 주인이 아닌 애들을 각각 select한다.
이제 Level2를 해보자, 전부 주석을 제가하자, 그리고 boardRepo에도 있는 2개 메소드 전부 주석 제거
level2 test 에서는 Eager와 Lazy를 알아볼 것이다.
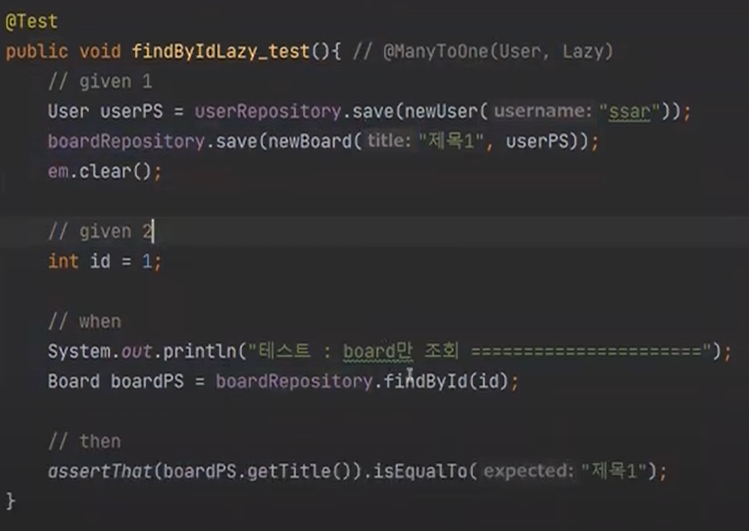
user 조회가 아닌 board만 조회만 해보자
먼저 ManyToOne의 전략을 변경해줘야 한다.
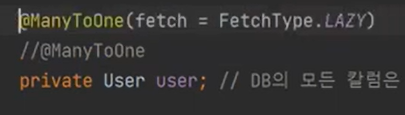
실행을 하면

이게 Lazy 전략이다.
이번에는 Eager로 바꿔보자

다시 테스트하면 join을 한다.
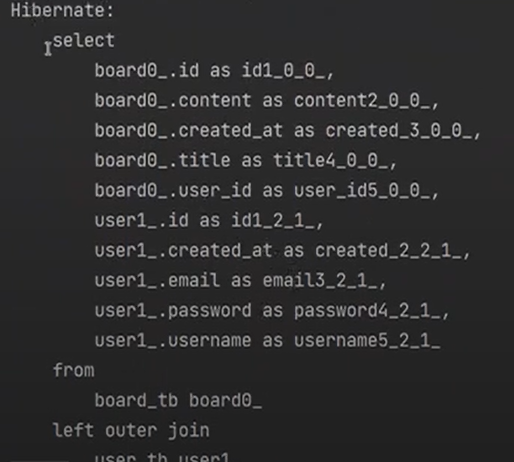
그러면 아까 우리는 Eager를 하지않고도 join을 하는 결과를 얻었다.
즉, @ManyToOne은 디폴트가 Eager이다.

다시 코드를 바꾸자
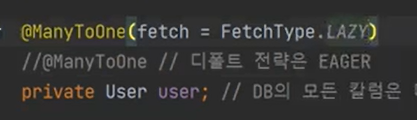
왜 @ManyToOne은 디폴트가 Eager 일까? 왜냐하면 관계된 것이 1건밖에 없으니까 이다. 1건 정도는 join해서 와도 전혀 문제가 되지 않기 떄문이다.
하지만 @ManyToMany면 List 형태가 되기떄문에 답이 없다.
즉, 여기서 알 수 있는 것은 @ManyToOne 기본 전략은 Eager이고 @OneToMany 기본전략은 Lazy이다.
쉽게, 내가 조회를 할 떄 많은 것을 들고와야하면 Lazy이고 적게 들고오면 전략이 Eager이다.
Lazy 전략의 장점을 알기위해서는 LazyLoading Test를 보자

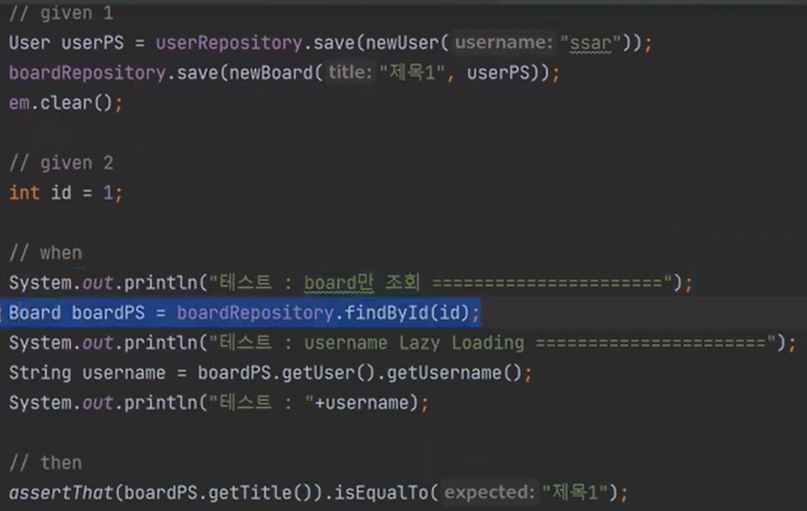
board를 먼저 영속화를 한다.


boardPS에는 user의 값이 없다. 이 상태에서 getUsername()에 접근을 하면 조회쿼리가 날라간다.
실행하면

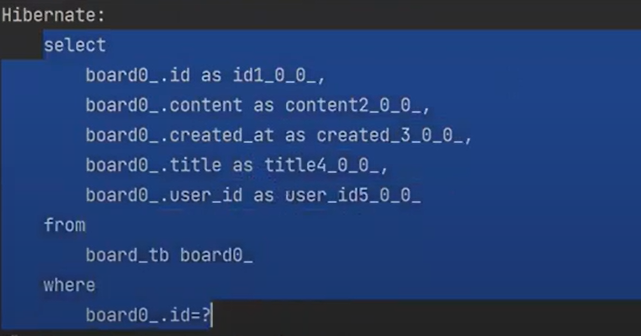
board만 select를 한다. 그리고

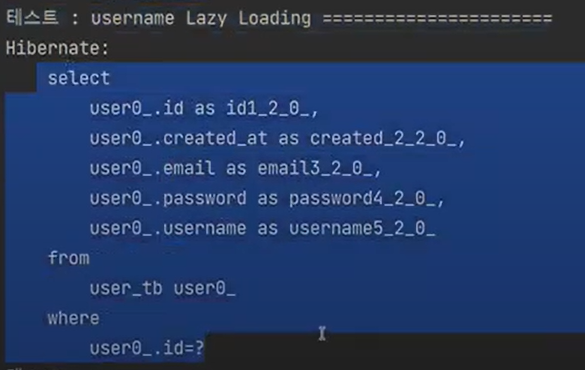
값이 없어도 no session 대신에 lazyLoading 조회쿼리가 날라간다.

만약 boardPS가 하이버네이트로 관리가 되지않으면 무조건 터지게 될 것이다.
한번 터트려보자
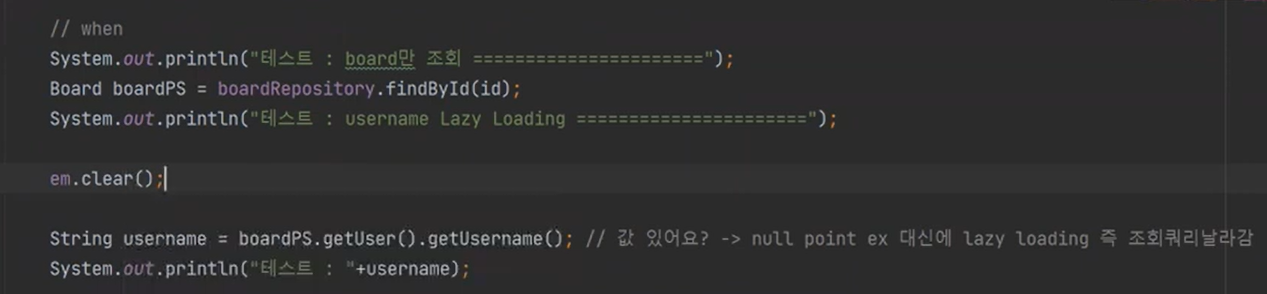

수업 끝
