
📕 1교시
📜 이전 JDBC 리뷰
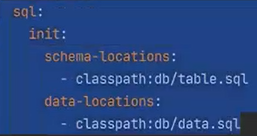
작성한 이유: 기초데이터 더미를 넣을려고
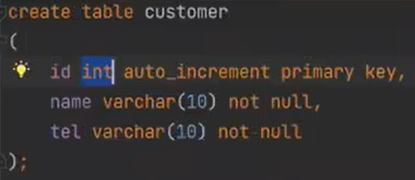
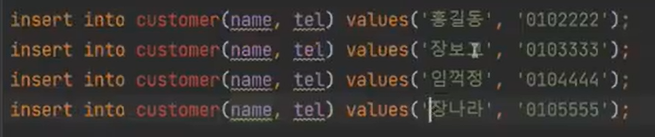
데이터 4건이 있는 상태에서 Model을 만들었다.
테이블을 그대로 자바세상에 모델링을 한다. 지금 중요한 것은 모델링을 하는 것이다. 자바 세상은 데이터 타입이 다르니까 유의 하자
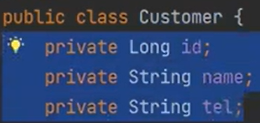
다음 CustomerRepo는 DataSource를 직접 만들었다.
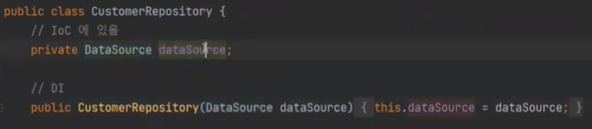
가장 먼저 데이터 소스에 커넥션을 연결한다. 이미 커넥션 풀링은 데이터 소스에 있으니까


sql을 버퍼에 담고 ?의 개수 만큼 완성 시킨다.
그리고 excuteUpdate를 한다. save, detele, update는 모두 excuteUpdate다.
excuteUpdate는 리턴값이 int다. 리턴값은 DML(조작한 행의 갯수)를 리턴한다.

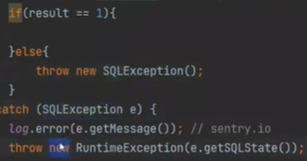
하지만 지금은 이렇게 작성하지 않았다.
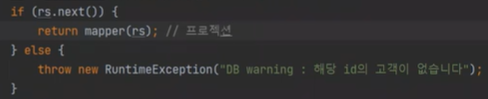
만약 CutomerRepo에서 return 값을 int로 받고 해당 메소드를 사용하는 컨트롤러에서 받아서, 처리를 하면 너무 지저분해지고 깔끔하지가 않다.
그래서 그냥 CutomerRepo에서 RuntimeEx 을 터트리는 것이다. try - catch 로 감싸서
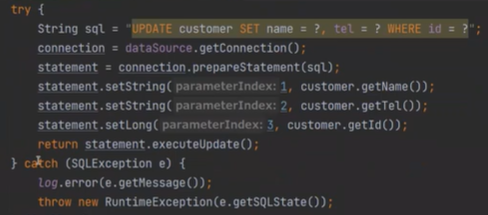
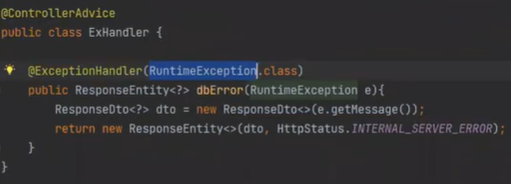
그리고
select를 보면 result set을 이용한다. 매우 중요하다
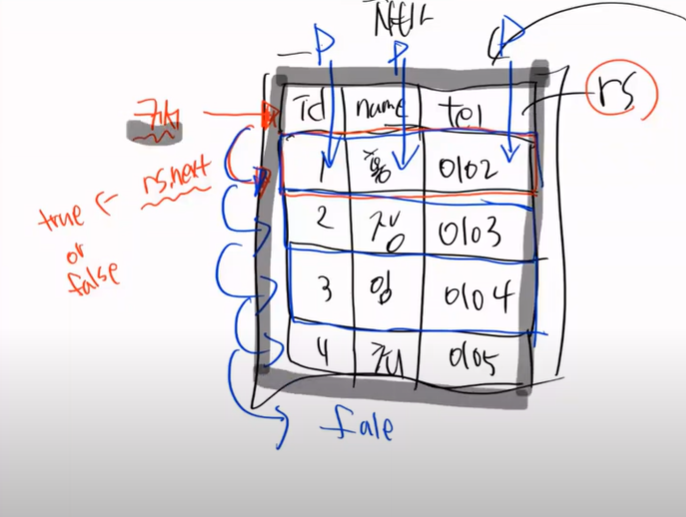
최초의 커서는 컬럼을 가리키고 있다.

이게 실행되면

0 또는 1이 나오게 된다. 찾거나 못 찾거나

이것 하나를 로우 또는 레코드라고 하는데, rs.next를 하면 밑으로 한칸을 내린다.
다음에는 mapper 가 발동하는데, 프로젝션이 발동하게 된다.
프로젝션은 세로행의 컬럼을 하나씩 꺼내는 것이다.
프로젝션을 할때는 내가 하고싶은 부분만골라서 할 수 있다. 하이버네이트에서는 이것을 FETCH라고 한다.
프로젝션을 할떄 mapper가 발동한다.
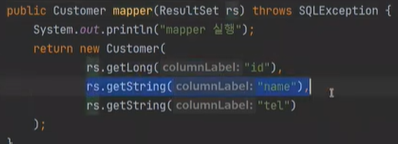
obeject mapping 이다. 내가 tel이 필요없으면 안하면된다.
이떄는 빌더 패턴을 사용해야한다. 빌더패턴은 내가 사용하고 싶은 것만 사용할 수 있게 한다.
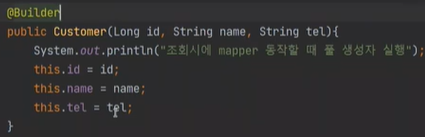

선택적으로 넣을 수 있다.
빌더의 원리를 알아보자
클래스 Person을 만들자
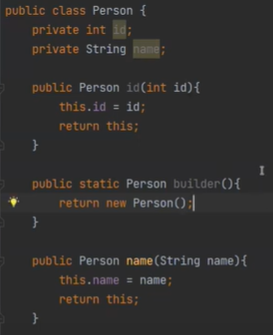
빌더 패턴 메소드는 자기자신을 리턴해야 한다.
빌더를 때리면 뉴 빌더가 된다.
따라서 main 메소드에서
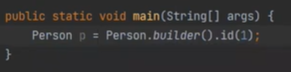
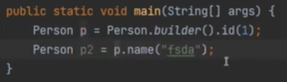
이렇게 이어서 붙일 수 있다.
빌더는 선택적 매개변수라고 한다.(넣고싶은 것만 넣을 수 있어서)
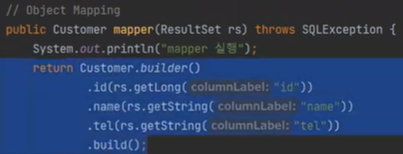
지금 내가 rs.getString 하는 것이 프로젝션이다. 프로젝션해서 오브젝트에 멥핑을 하는 것이다.
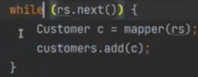
findAll은 1건이 아니라 여러개를 찾는 다 그래서 rs.next를 할 때 반드시 while 문을 돌아야 한다.
이제 2개의 컨트롤러 메소드를 테스트 코드를 작성해보자
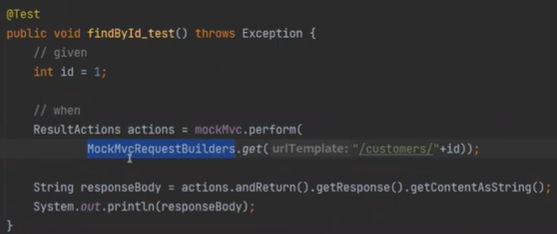
실행하면


이 부분이 String으로 바꿔준다.
눈으로 검증이 됬다. 이제는 검증을 하자
jsonpath를 사용하자

만약 내가 구조가 잘 보이지 않으면, jsonviwer의 text에다가 위의 string을 넣고 viwer로 바꾸면 된다.
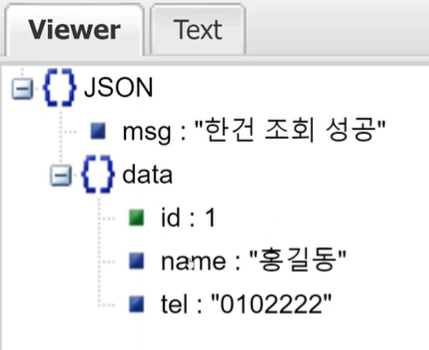
그래서 $.data.name 이 되는 것이다.
실행을 해보자
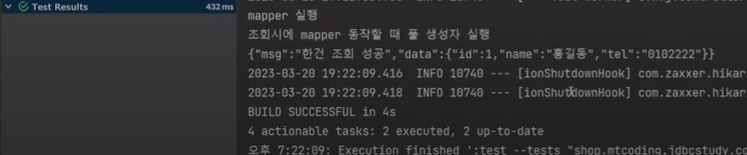
검증 완료
findAll을 테스트해보자
테스트를 할 때 항상 given, when, then을 적어두자
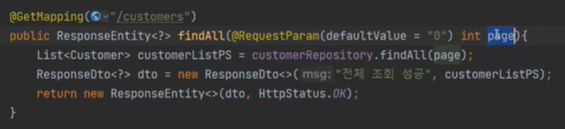
보니까 안넣어도 디폴트가 0이다.
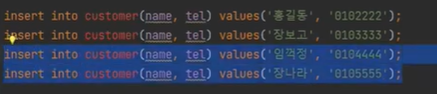
임꺽정과 장나라를 뽑아보겠다
어차피 페이징은 2건이 되있기 때문이다.
페이지는 0부터 시작하기 때문에 1은 2번째 페이지를 의미한다. 따라서 0과 1 2개의 페이지를 가져온다.
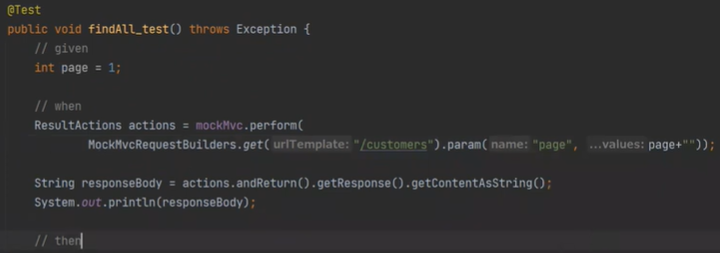
일단 눈으로 검증을 해보자


📜 하이버네이트

하이버네이트 오브젝트 릴레이션 맵핑 기술로 DB와 상호작용 하게한다.
하이버네이트를 사용하면 자바와 DB를 쉽게 설정가능, 객체를 DB에 저장, 검색, 수정, 삭제 가능하다.
결론은 SQL 세상을 몰라도 자바로 다룰 수 있다는 것이다.
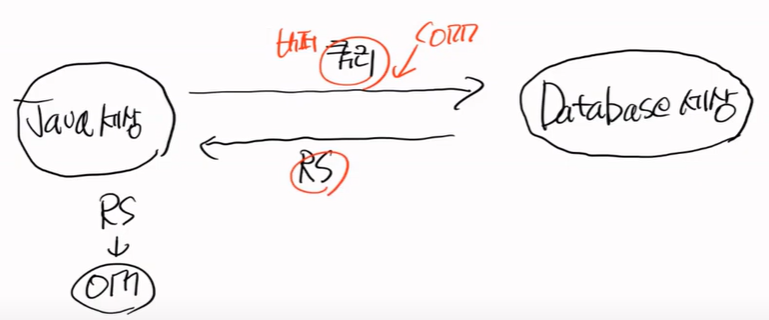
이전에는
자바 세상이 있고, DB 세상이 있다. 기존에는 쿼리를 날렸고, 쿼리에 대한 결과를 Result Set으로 받고, 자바가 오브젝트 맵핑을 했다.
이때 쿼리를 전송하기 위해서 버퍼를 달고, connection을 연결했다.

하이버네이트 세상은 똑같이 자바와 DB 세상이 있는데 중간에 있다. 이것을 미들웨어라고 하고, 자바는 미들웨어에게 자바 명령을 하고 DB에게는 SQL을 날린다.
DB는 미들웨어에게 RS를 날리고, 자바에게는 자바 오브젝트를 보낸다.
이게 하이버 네이트다, 중간에 다리역할을 하는 것이다.
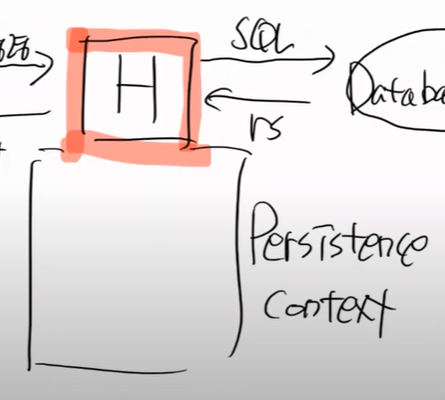
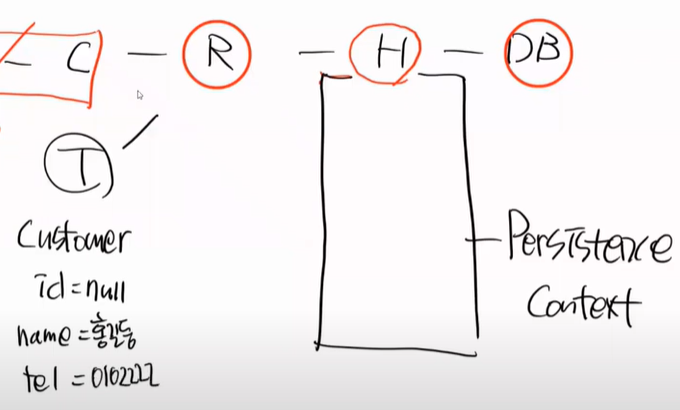
하이버네이트를 공부하는 것은 persistance context를 공부하는 것이다.
영속성이라는 의미이고, 영구히 저장한다는 것이다. 영구히 저장하기 위해서는 HDD에 기록하는 것이다.
따라서 HDD에 기록하는 것은 Persistance라고 한다.
사용을 위해서는 의존성을 추가해야 한다.

ORM에 관해서 알아보자

OM은 프로젝션해서 오브젝트에 옮겨 담는 것이다.
하지만 매번 하는 것이 매우매우 귀찮다.
만약 테이블 양이 많으면, OM 하는 것도 매우 귀찮다.

따라서 ORM을 해야한다. OOP와 관계형 DB 사이에서 데이터를 변환하는 기술이다. 모든 것을 다해준다.
객체와 테이블 간의 매핑을 해준다.
간단하게 코드로 보자.
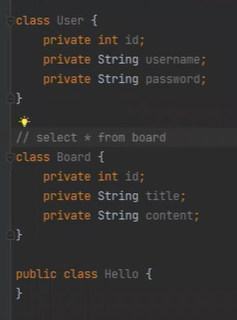

만약 쿼리를 다음과 같이 날린다면, JDBC 에서는 Result set을 받는다 그러면 내가 직접 OM을 해야한다.
ORM은 OM을 대신해주고 join 까지 해준다.
Board는 누가 적었는지 모르니까 Forign key를 달아준다
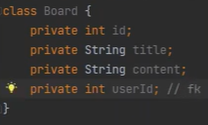
FK를 통해서 relation mapping이 되는 것이다.
따라서 User class의 내용까지 전부 넣어준다. 이것을 ORM이라고 한다. 매우매우 편하다.
코드로 가자
가장 먼저 의존성을 넣어야한다.
h2 database 인메모리 데이터베이스 또한 넣어줘야한다.
2번째로는 application.yml을 설정해주면 된다.
@Entity를 달아주면 hibernate가 관리를 하는 객체가 된다.
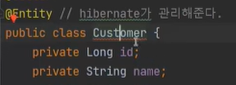
에러가 나오는데, Cutomer는 PK를 필요로 한다고 한다.
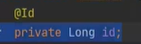
이런식으로 하면 id 는 PK가 된다.
application.yml로 돌아와서 다음과 같이 적으면, 자기가 관리하는 entity의 테이블을 모두 자동 생성한다.
h2-console 로 접속을 하면
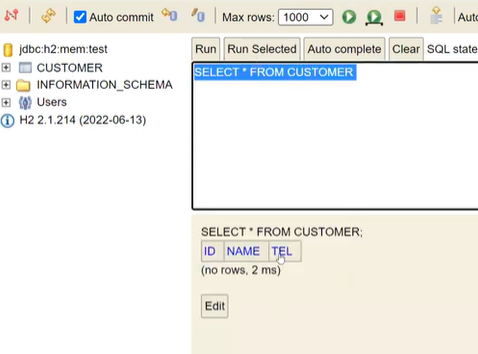
만약
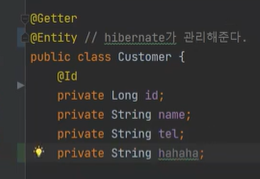
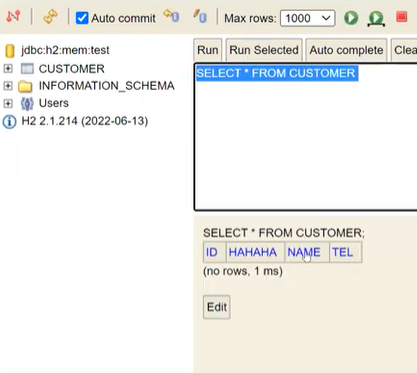
즉, 하이버네이트가 자바세상의 @Entity를 가지고 있는 객체들을 관리하는 것이다.
그리고 로그를 담기기 위해서 application.yml에 다음과 같이 적는다.


또 추가를 하고 실행하면, 다음과 같이 이쁘게 나오게 된다.
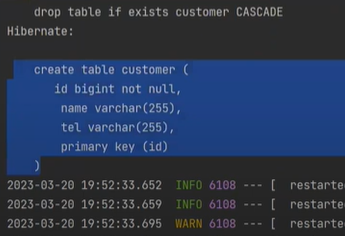
근데 지금 상태의 h2-console은 auto_increment가 안되어 있다.
따라서 Customer에 1개를 더 추가한다.
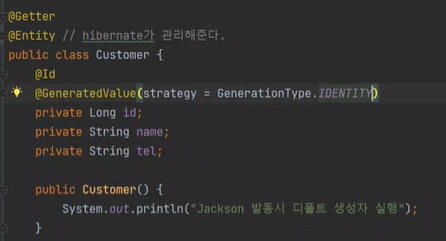
id에 auto_increment 전략을 한다.

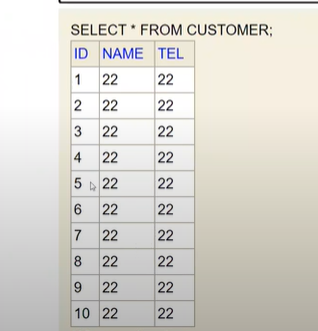
만약 auto_increment 하지 않는다면 id를 매번 적어줘야한다. 불편하다.
📕 2교시
@Entity 깃발이 붙었으니까 서버가 실행될 떄, 리플렉션을 한다. 내부를 분석하면서 이런게 있구나 하느 것이다.
즉, 리플렉션을 해서 테이블이 만들어진다.
이번에는 JDBC를 사용하지 않고 만들어보자
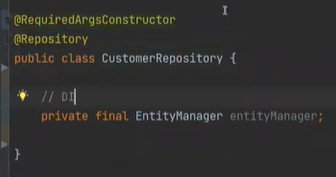
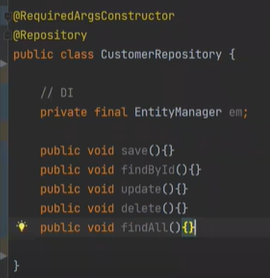
레포지토리 깃발을 놓으면 Ioc Container에 등록이 된다.
하이버네이트가 관리하는 Entity Manager가 있다.
생성자 주입을 위해 @RequiredArgsConstructor를 한다.
그러면 DI가 된다.
저번에 만든 JDBC 5가지 메소드를 만들수 있게 된다. 그것도 매우매우 쉽게
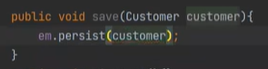
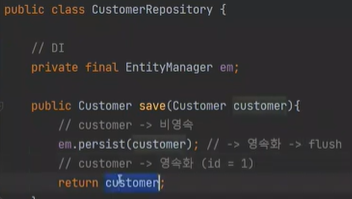
먼저 save는 이렇게 하면 끝이난다.
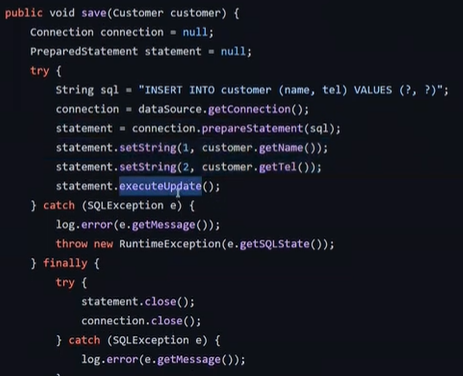
이전 JDBC에서는 이렇게 했었다.
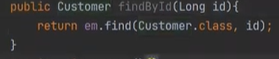
findById를 해보자, 조회하면 result Set으로 주지않고 Customer 객체에 OM을 자동으로 해서 제공을 한다.
update는 merge를 사용해서 한다.
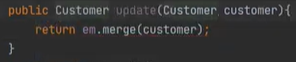
delete
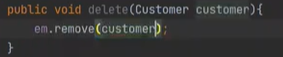
findAll은 제공을 하지 않기 떄문에, 쿼리를 작성해줘야 한다.
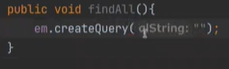
보면 QLString 이라고 한다. 따라서 JPQL이라는 것을 작성할 것이다.

Customer는 자바 객체(객체 지향 쿼리)를 의미하고, customer는 네이티브 쿼리를 의미한다.
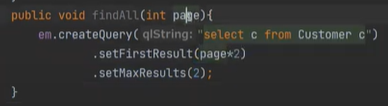
그리고 만약 페이징을 할 거면, page를 받고
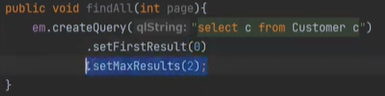
setFirstResult는 n 페이지에서
setMaxResults는 n건씩 들고 온다는 의미이다.
따라서 다음과 같이 작성을 한다.
그리고 Customer.class로 바로 매핑해서 return 값을 받고 리턴은 List 형태로 받는다.

하지만 에러가 나서 마지막에는 리스트로 리턴한다는 것을 명시해야한다.
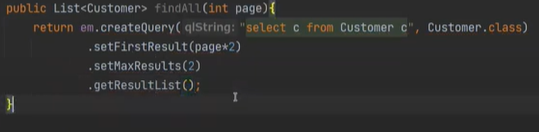
여기서 기억할 것은 테이블 명이 아니라, 자바 객체를 넣는 다는 것이다.

그러면 여기서 c 는 뭘까? c 는 Customer가 들고 있는 변수다.
그래서 다음과 같이 프로젝션도 할 수 있다.

모든게 추상화가 되어있기 때문에, JDBC에서 했던것을 다 해준다.
이제 검증을 해보자, 테스트를 해보자
우리는 메모리에 어떤것을 띄워야 할까?
근데 CustomerRepo는 뜨지 않는다. JPA이기 떄문에 JPA를 상속한 것들만 뜬다

그레서 우리는 강제로 CustomerRepo를 띄울 것이다.

given 데이터는 매개변수로 들어오는 것들을 의미한다.
따라서 Cutomer를 만들어야한다. id는 auto-increment니까 할필요 없다.
그리고 DI가 안되기 때문에


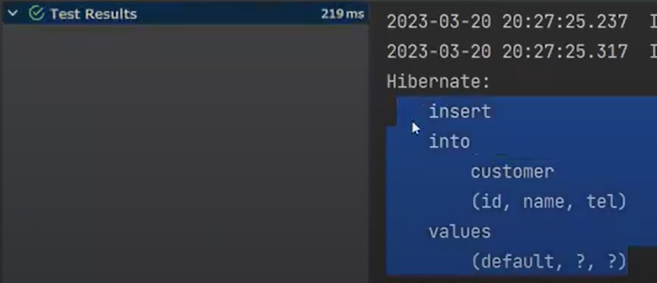
그리고 Test 실행하면
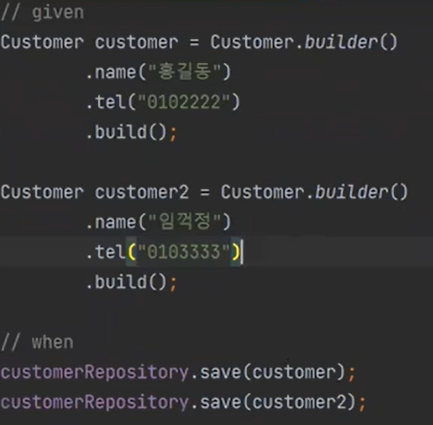
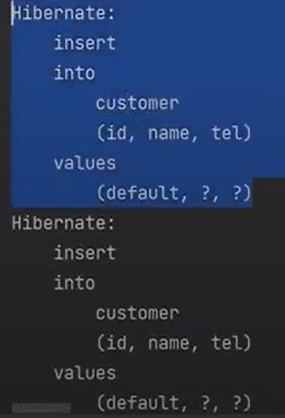
그리고 CustomerRepo에서 다음과 같이 바꿔보자
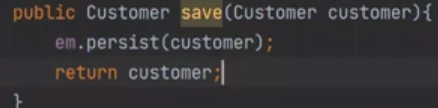
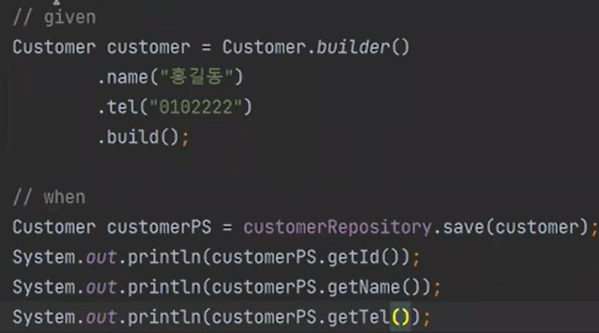

왜 id값을 가지고 있을까, 우리는 넣지 않고 save만 했는데 말이다.
즉, 들어갈떄의 Customer와 나올떄의 Customer가 다른 상태이다.
일단 검증을 해보자


테스트할 때는 실패하는 경우를 무조건 해봐야한다.

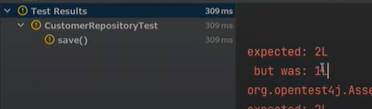
그림 설명을 들어간다.
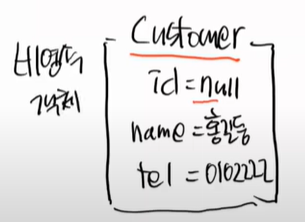
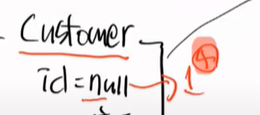
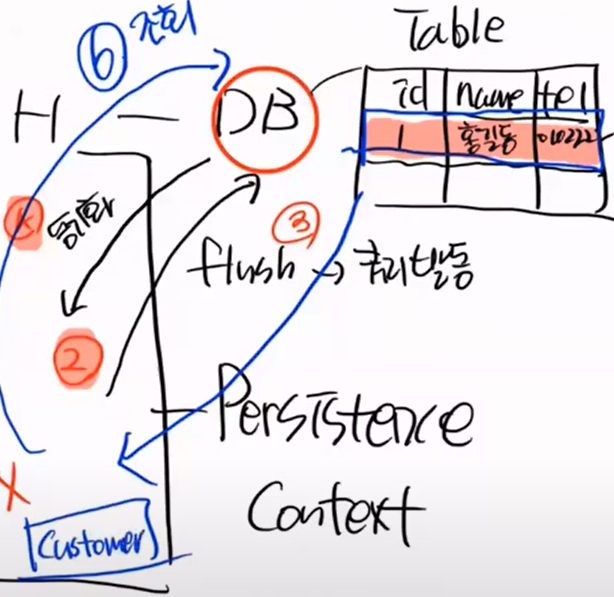
하이버네이트 입장에서는 Entity가 있고, id가 null 이면 비영속 객체라고 한다
save를 한다는 것은 persist를 한다는 것이다. 영속화 하는 것이고, customer를 영속화 한다는 것이다.
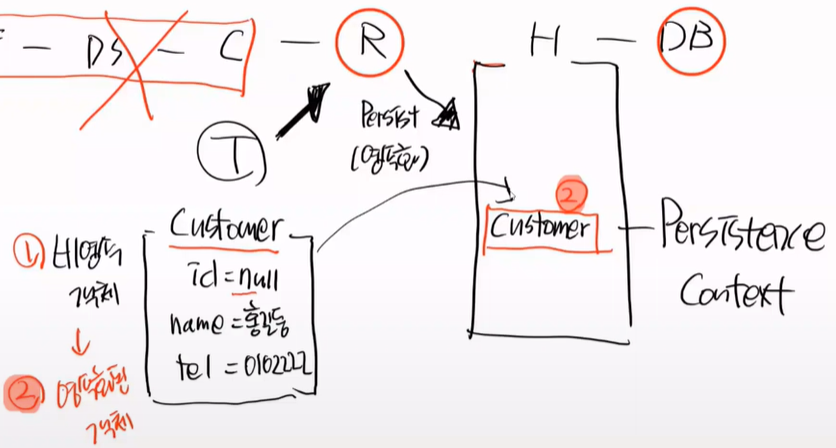
persist를 하면 영속화된 객체를 DB로 flush를 한다. 이때 insert Query가 날라간다.(excuteUpdate가 발동)
그럼 테이블에 해당 정보가 채워진다

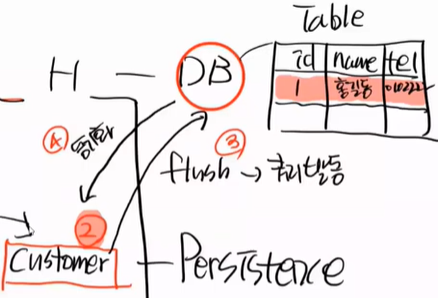
insert 이후 바로 자동 동기화를 한다. 동기화가 되는 4번 시점에 id = null 이 id = 1이 된다.
즉, 영속화(persist) 되면 자동으로 flush가 되고, insert query가 날라가고 table에는 row가 생기고, 자동 동기화를 하며 id = 1로 바뀌게 된다.
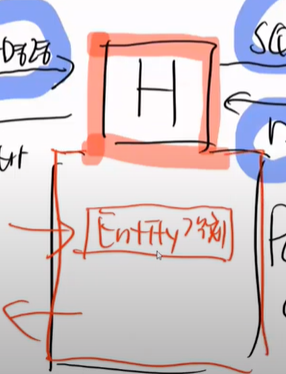
따라서 하이버네이트가 Entity 객체가 나가고 들어오는 것을 다 알기 때문에 context가 된다.(java, DB 포함)
만약, 다음과 같은 상태면 영속화가 됬기 떄문에 찾아질 것이다.
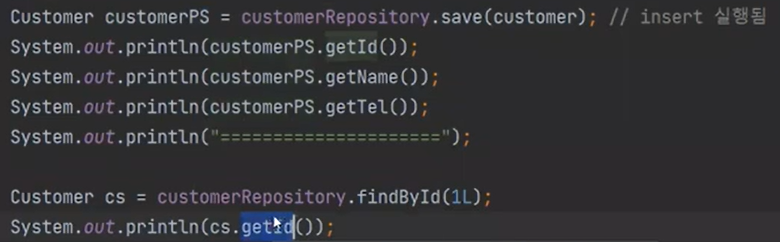
실행하면
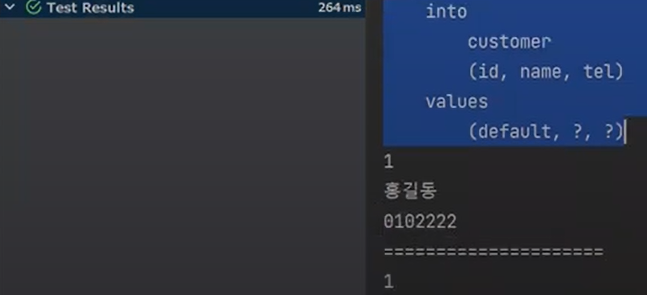
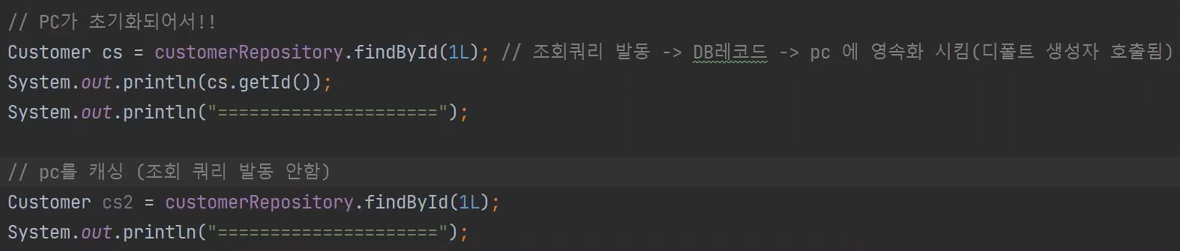
이상한것은 insert 쿼리는 작동했지만, select 쿼리는 작동하지 않았다(findById)
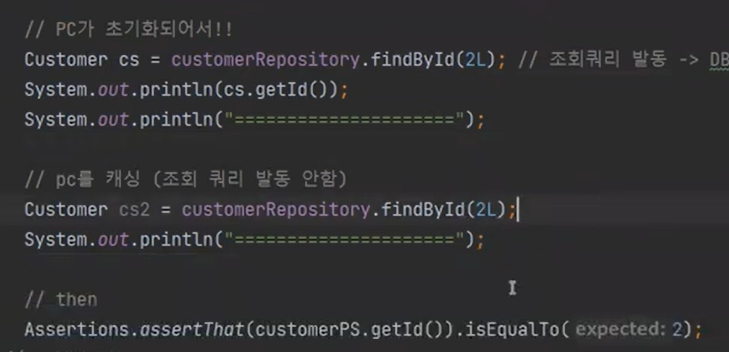
왜냐하면 캐싱 때문이다.
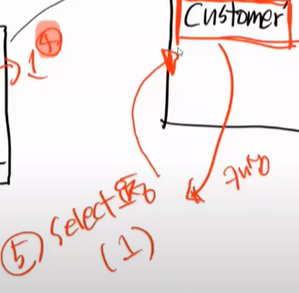
select 1 을 요청하면 영속화된 객체 중에서 먼저 찾아본다. 찾아서 있으면 바로 당겨온다.
만약 영속화된 객체가 없으면 DB로 가서 조회를 한다.
한번 코드로 해보자, 일단 EntityManager 를 만들자

clear는 영속성 객체를 비우는 것이다.
보면 캐싱을 하지못하고, select 쿼리가 발동한다.
캐시미스가 발동하고, 조회 요청을 하고 영속화시키고 데이터를 보낸다.
한번 해보자
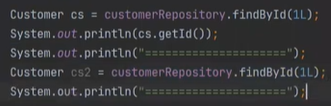

신기한게 있다

이 타이밍에 생기게 된것인데(select 하고 Customer가 영속화 되는 시점)

따라서 @Entity는 디폴트 생성자가 없으면 안된다.
setter가 없는데 어떻게 넣었을까? 리플렉션을 통해서 private변수에 직접 접근해서 값을 할당했기 때문이다.
결론은
📕 3교시
이제 findById를 Test 해보자

PS붙이는 이유는 영속화(Persist)가 된거여서
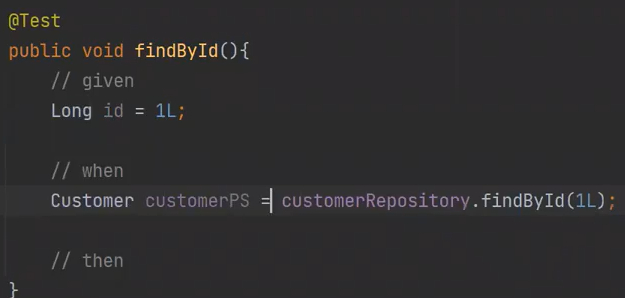
만약 전체 테스트를 하면 Transaction이 붙어있으면 단위 테스트마다 rollback이 된다.
따라서 지금 단위테스트를 실행하면

왜냐하면 roll back이 됬기 때문이다. 테스트는 반드시 격리가 되어야한다.
이 책을 보면 된다.
테스트 코드를 짜고 본코르를 짜라고 하는데, 초보자는 절대로 불가능하다. 많은 경험이 있어야 가능한 부분이다.
클린코드란 책도 읽어봐라
다시 수업으로
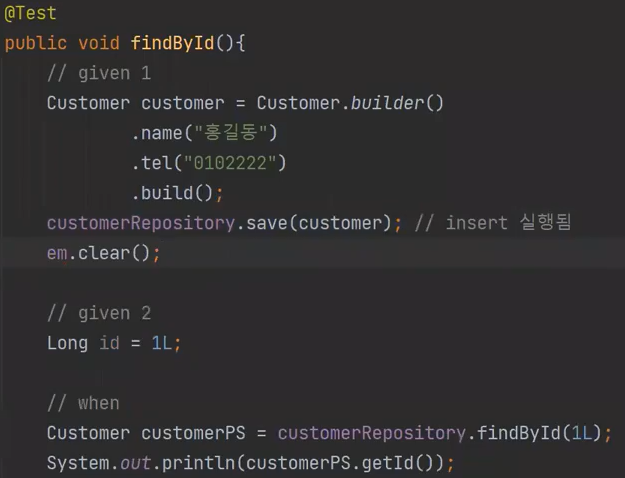
제대로 테스트를 하려면 clear를 해줘야한다. 캐시를 비워야하는 것이다.
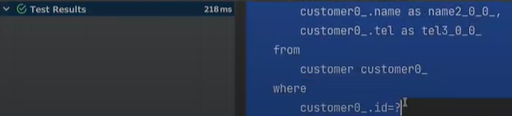
그러면 insert 쿼리가 나오고, 비운뒤에 select 쿼리 발동후 디폴트 문구가 나오게 된다. 성공한 것이다.
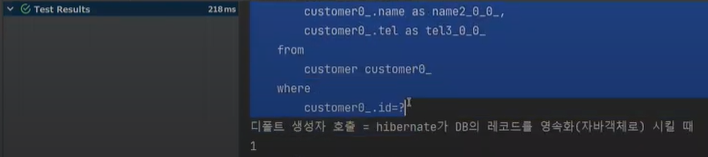
이제 update를 해보자. 미리 데이터가 있어야 하므로
그리고 우리는 name 과 tel 만 업데이트를 하면 된다.

따라서 먼저 update를 할 떄는 해당 데이터가 있는지 없는지 먼저 확인을 해야한다.
그래서 findById를 먼저 해야한다.


test를 실행하면 merge가 되고 끝이난다. 왜냐하면 업데이틀할 데이터가 없기 떄문이다.
따라서 업데이트 변경작업을 해줘야한다.
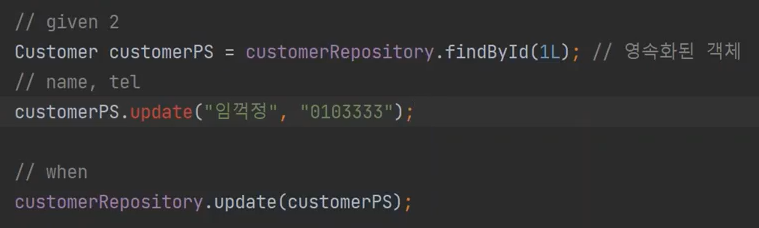
alt + enter 를 해서 메소드를 만든다.

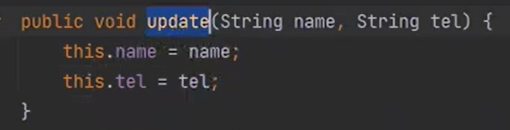
다시 실행을 해보면 아무것도 일어나지 않는다.

일단 다음과 같이 적어보자
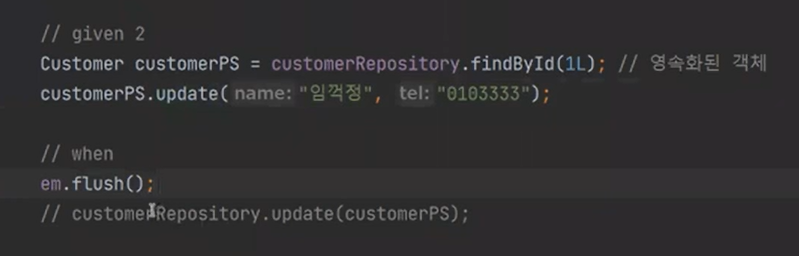
실행을하면 update 쿼리가 나온다
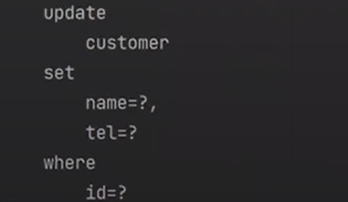
이전에 update에서 무엇을 안했기 떄문에 아무일도 일어나지 않았을까? flush가 안되었기 떄문이다. flush를 해야 insert 쿼리가 날라간다.
일단 업데이트로 가서 다음과 같이 바꿔보자

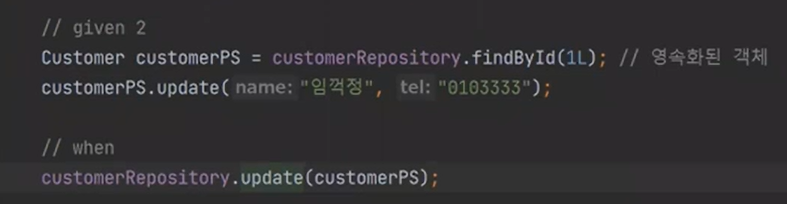
실행이 된다.
그림을 보면서 이해해보자. 현재 이상태이다.
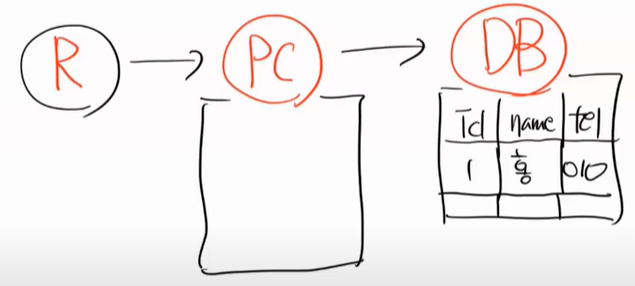
findById를 하면 조회를 했으니까
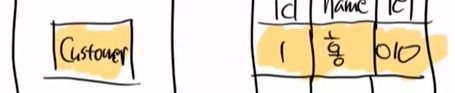
update 객체 이름과 번호를 적으면 변경이 일어난다. 해당 부분은 영속화된 객체를 변경한 것이다.

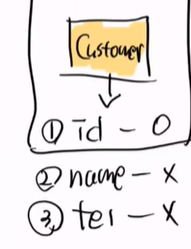
즉, 영속화된 객체를 변경해서 flush만 하면 update 쿼리가 날라가게 된다.
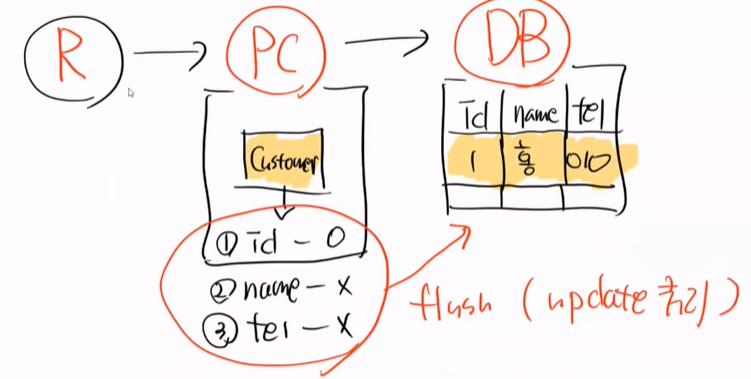
사실 PC 에서는 영속성 컨텍스트 변경 감지를 한다.
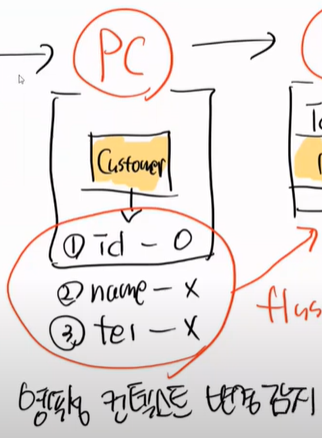
따라서 우리는 merge를 할 필요가 없다. 그래서 update에 있는 merge 코드를 다음과 같이 바꾼다.
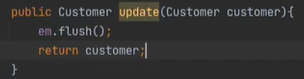
이 코드는 영속화된 객체일까? 아니다. 이상태로 update하고 flush해봤자 아무일도 일어나지 않는다.

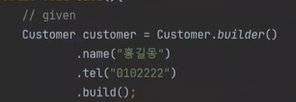
이번에는 아이디까지 넣어서 해보자

이상태로 update하고 flush해봤자 아무일도 일어나지 않는다.
왜냐하면 영속화가 되지 않았기 떄문이다.
정리하면 영속화 시켜서 변경하고 flush하면 update가 되고, 영속화 되지않은 것을 변경하고 flush 하면 update가 되지 않는다.
Junit으로 테스트하면 roll back이 된다.
근데 이런식으로 계속 넣는게 너무 귀찮다..
그래서 위에다가 다음과 같이 적는다.
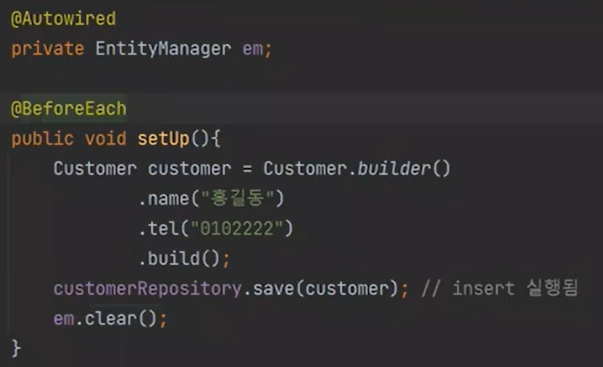
그러면 테스트 메소드 실행 직전 마다 발동이 된다.
따라서 save 테스트 메소드의 id 부분을 다음과 같이 바꿔야 한다. 왜냐하면 이미 1건이 들어있기 떄문이다. 테스트 메소드가 끝나고 전부 roll back 된다.
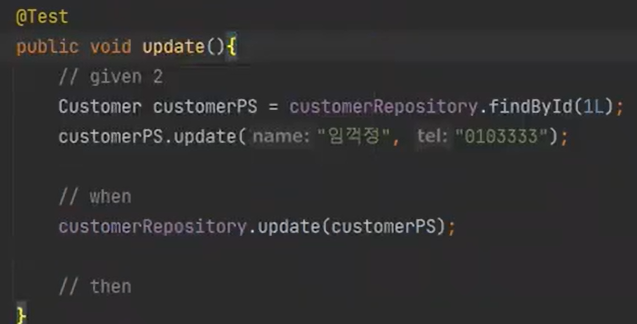
update도 마찬가지로 given1 부분을 지우고 한다. -> 테스트 성공
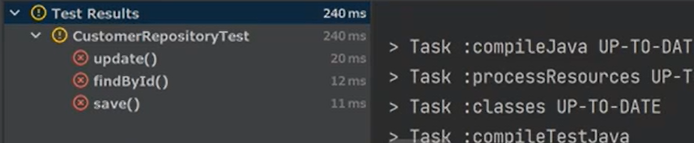
근데 전체 테스트를 하면 터진다. 왜냐하면 @Transactional이 붙으면 roll back을 하지만, auto-increment가 초기화가 되지 않는다. 따라서 @BeforEach 에서 auto-increment가 초기화를 해야한다.
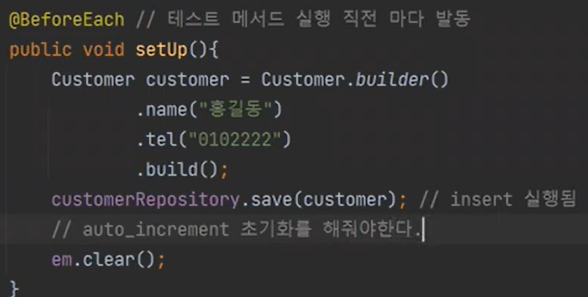
왜냐하면 처음 실행하면 auto-increment는 계속해서 초기화가 안되고 증가하며, 데이터 roll back만 되기 떄문이다. 그럼 매번, id를 바꿔줘야한다. 따라서 테스트가 격리가 되지 않았다.
따라서
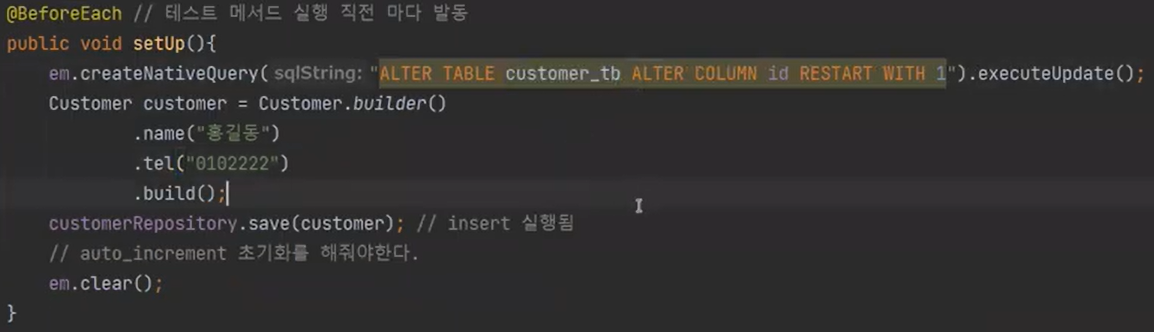
그리고 다음과 같이 추가한다. 만약 테이블 명을 기재하지 않으면 Customer 대문자로 된다.
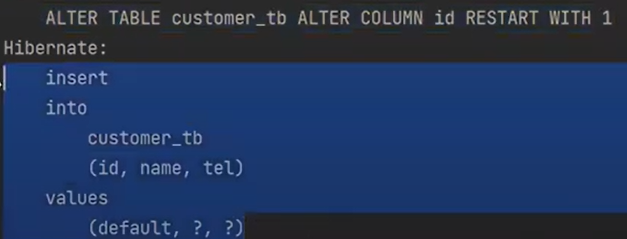
그리고 전체 실행을 하면, auto-increment를 초기화 한다.
수업 끝
