1. label_encoder
import pandas as pd
df = pd.DataFrame({
'A' : ['a', 'b', 'c', 'a', 'b'],
'B' : [1,2,3,1,0]
})
df1) fit ~ transform (문자 -> 숫자
from sklearn.preprocessing import LabelEncoder
# 변수 설정
le = LabelEncoder()
# (1) 학습(df의 A컬럼을 기준으로)
le.fit(df['A'])# (2) 잘 학습되었는지 확인
le.classes_array(['a', 'b', 'c'], dtype=object)
# (3) transformation (fit 이후 해야 함)
le.transform(df['A'])array([0, 1, 2, 0, 1])
# (4) transformation 값, 컬럼에 넣기
df['le_A'] = le.transform(df['A'])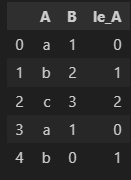
2) fit+transform
le.fit_transform(df['A'])array([0, 1, 2, 0, 1])
3) 답 물어보기
le.transform(['a'])array([0])
4) 역변환 (문자 -> 숫자)
le.inverse_transform(df['le_A'])array(['a', 'b', 'c', 'a', 'b'], dtype=object)
2. min-max scaling (정규화)
(min)은 0으로, (max)는 1로 만들어 줌
df = pd.DataFrame({
'A' : [10,20,-10,0,25],
'B' : [1,2,3,1,0]
})
df
1) fit
# MinMaxScaler 모듈
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
mms.fit(df)2) 데이터 확인
# data_range_ : 분모 역할(전체 길이)
mms.data_max_, mms.data_min_, mms.data_range_(array([25., 3.]), array([-10., 0.]), array([35., 3.]))
3) transform
- (min)은 0으로, (max)는 1로 만들어 줌
df_mms = mms.transform(df)
df_mms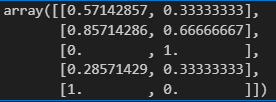
4) 역변환
mms.inverse_transform(df_mms)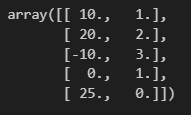
5) 한번에~
mms.fit_transform(df)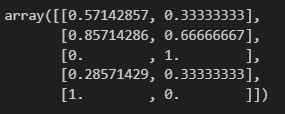
3. Standard Scaler (표준화)
표준정규분포 (표준을 빼고 편차로 나눠주는~)
1) fit
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(df)2) 표준편차 작동 인자
- (분모) 표준편차
- (분자) 평균
# 평균, 표준편차
ss.mean_, ss.scale_(array([9. , 1.4]), array([12.80624847, 1.0198039 ]))
3) transform
df_ss = ss.transform(df)
df_ss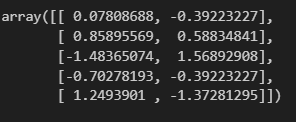
4) 한번에~
ss.fit_transform(df)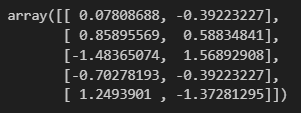
4. Robust Scaler
df = pd.DataFrame({
'A' : [-0.1,0.,0.1,0.2,0.3,0.4,1.0,1.1,5]
})
df1) 3가지 모듈을 한번에 적용
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
mm = MinMaxScaler()
ss = StandardScaler()
rs = RobustScaler()2) fit_transform + 컬럼 추가
df_scaler = df.copy()
df_scaler['MinMax'] = mm.fit_transform(df)
df_scaler['Standard'] = ss.fit_transform(df)
df_scaler['Robust'] = rs.fit_transform(df)
df_scaler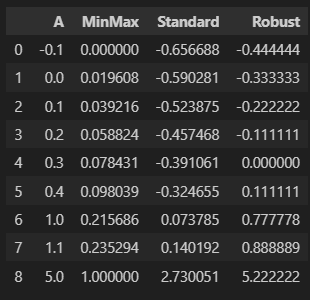
3) 이해를 위해 Boxplot
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(16,6))
sns.set_theme(style='whitegrid')
sns.boxplot(data=df_scaler, orient='h') #orient='h':수평bar-
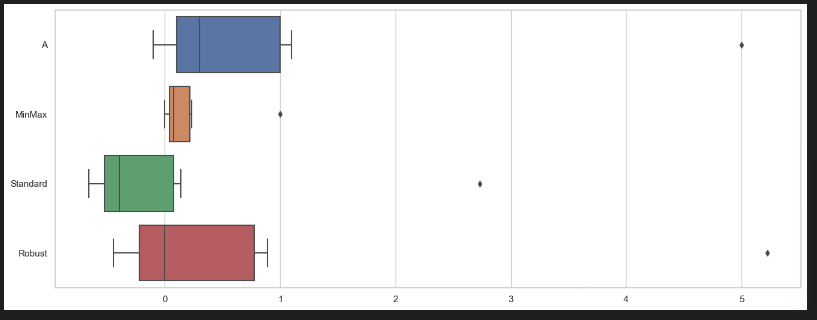
-
A 안에는 0.1 기준으로 증감하는 데이터들 사이에 5라는 아웃라이어가 있음
-
5라는 아웃라이어 때문에 MinMaxScaler 결과 한쪽으로 치우치게 됨
-
MinMaxScaler는 아웃라이어의 영향을 받으면 데이터가 이상해질 수 있음
-
평균과 중앙값을 쓸때, 평균 이상치를 반영하고, 중앙값은 이상치 영향을 덜 받게 됨
-
StandardSCaler를 확인했을 때, 평균이 반영되어 대다수의 데이터가 왼쪽으로 치우침
-
RobustSCaler는 median이 0이 되고, 아웃라이어는 그대로 유지되며 데이터에 영향을 크게 주지 않음

비전공자의 데이터 공부법