앙상블기법
- 앙상블은 전통적으로 Voting, Boosting, Bagging, 스태깅 으로 나뉨
- 보팅과 배깅은여러개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식이다
- 둘의 차이점은 보팅은 각각 다른 분류기, 배깅은 같은 분류기를 사용
- 대표적인 Bagging 방식은 landomforest 이다.
- Voting
- 하나의 데이터(전체 데이터)를 다 쓰면서 각각 다른 알고리즘을 적용 시키는 방법
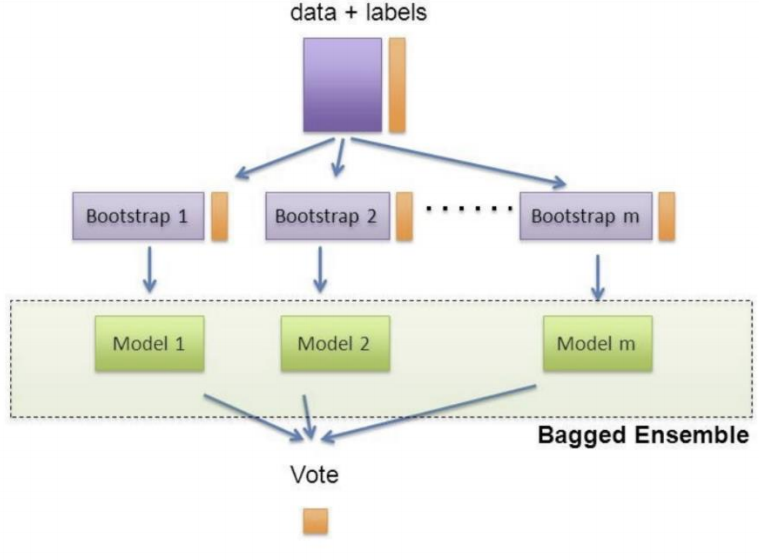
- Bagging
- 하나의 알고리즘을 쓰는데, 전체 데이터를 나눠서 씀
- 나누는 방법 ;
중복을 허락해서 데이터를 수집 한다 (boot strapping)
- Voting
그렇다면, Boosting은 뭘까..?
알아봅시다 😎
Boosting 이란?
- 여러개의
약한(?)분류기(=성능이 떨어지고 겁나 빠른 = DecisionTree, maxdepth=2_낮게 주는 것)가 순차적으로 학습하면서 앞에서 학습한 분류기가 예측이틀린 데이터에 대해다음 분류기가 가중치를 인가해학습을 이어 진행하는 방식
- 예측 성능이 뛰어나 앙상블 학습을 주도함
Boosting 기법 3가지
- GBM (Gradient Boosting Machine)
- AdaBoost 기법과 비슷하지만 가중치를 업데이트 할때
경사하깅법(Gradient Descent)를 사용
- AdaBoost 기법과 비슷하지만 가중치를 업데이트 할때
- XGBoost (eXtra Gradient Boost)
- GBM에서 PC의 파워를 효율적으로 사용하기 위한 다양한 기법에 채택되 빠른 속도와 효율을 가짐
- GBM에서 효율을 극도로 올리고 CPU를 쓸 수 있게 하는 것
- LightGBM (Light Gradient Boost)
- XGBoost 보다 빠른 속도를 가짐
- 속도를 향상시ㅣ기 위한 각종 장치들이 있음
Bagging과 Boosting 의 차이는?
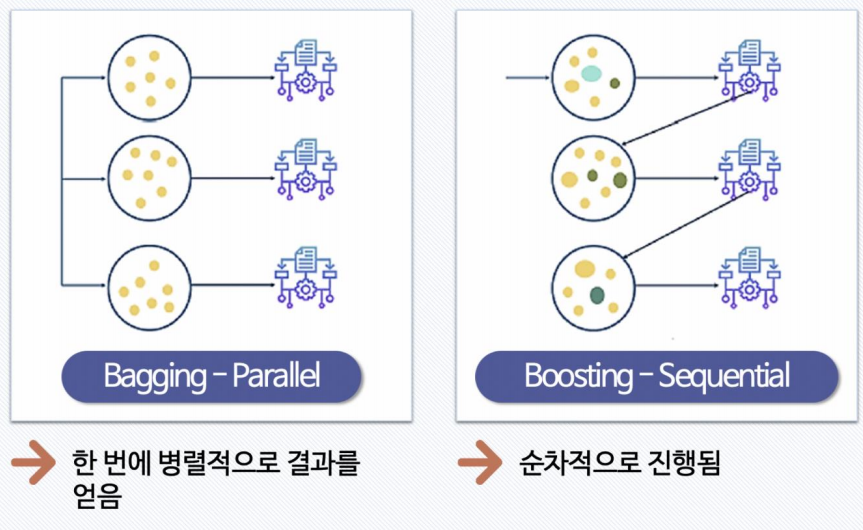
- Bagging
- 데이터를 통 or 잘라서 쓰던지
학습하는 타이밍이동시에 이뤄짐
(= 한번에 병렬적으로 결과를 얻음) - 데이터들이 각각의 분류기에 들어가고 각각의 모델들이 동시에 학습을 해서 결과를 투표
- 데이터를 통 or 잘라서 쓰던지
- Boosting
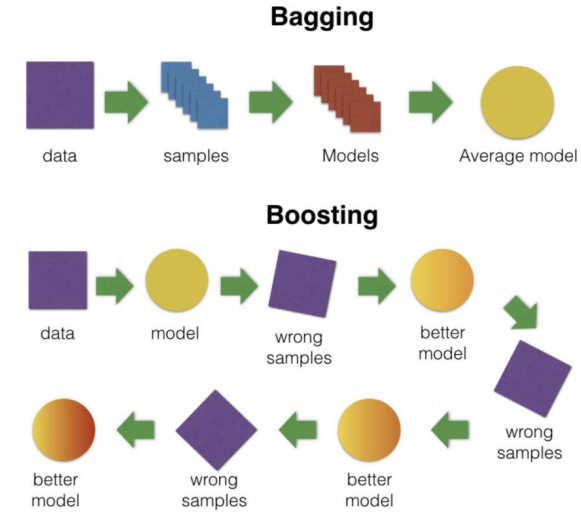
- 데이터를 가지고 학습
- 그 결과(틀린것, 가중치가 필요한 것들)를 가지고 또 학습
- 또 학습
(= 순차적으로 진행됨)
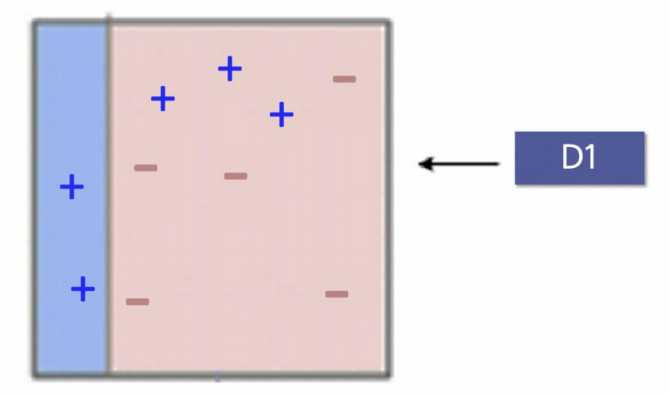
Boosting 계열의 기본적인 그림(AdaBoost)을 통해 알아봅시다~
Boosting 계열 개념 설명
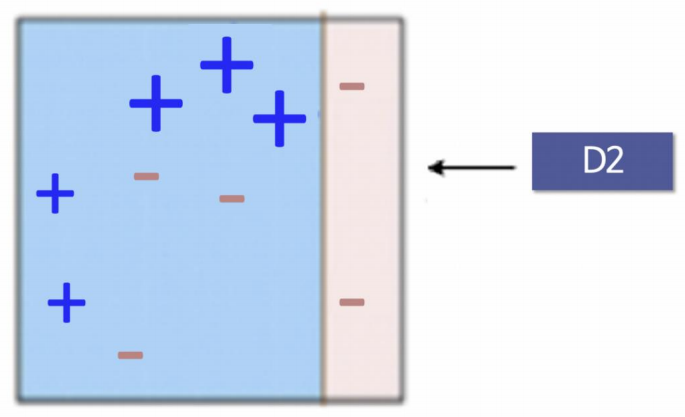
- D1
먼저 +-를 구분해야 하는데, 매우 약한 분류기를 썼기 때문에 성능의 경계면이 말도 안되게 설정됨...
- D2
그리고 틀린 아이들에게가중치를 줌
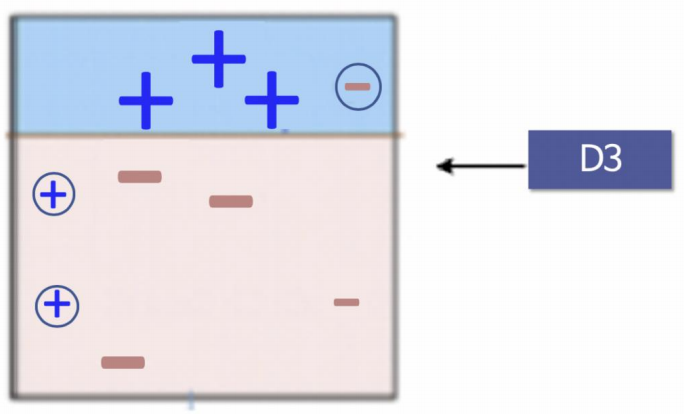
- D3
다시 놓친 -에 가중치를 인가해, 다시 경계를 설정
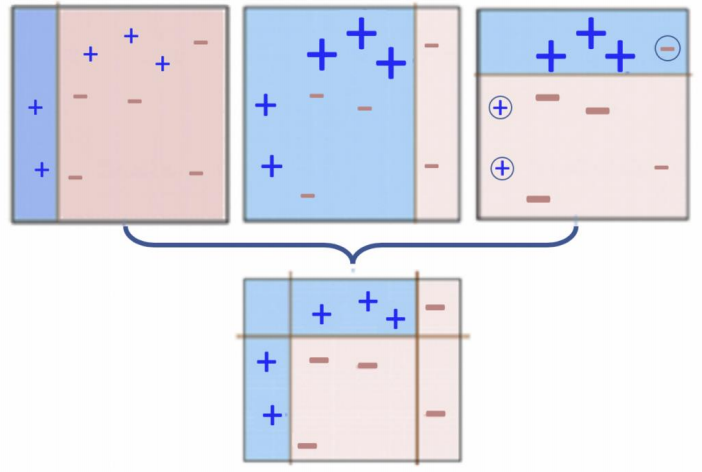
- 마지막 단계
앞서 결정한 경계들을 합침 (이어붙임)
실습 - Wine data
1. 데이터 확인
# 1) 데이터 가져오기
import pandas as pd
wine_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/wine.csv'
wine = pd.read_csv(wine_url,index_col=0)
wine.head()
# 2) 맛 등급 설정
# (1) quality 컬럼 이진화
# wine 데이터의 ['taste'] 컬럼 생성
# wine의 quality column울 grade로 잡고, 5등급 보다 크면 1, 그게 아니라면 0으로 잡음
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
# (2) 모델링
# label인 taste, quality를 drop, 나머지를 X의 특성으로 봄
X = wine.drop(['taste', 'quality'], axis=1)
# 새로만들 y데이터
y = wine['taste']# 3) StandardScaler
from sklearn.preprocessing import StandardScaler
# StandardScaler를 installation
sc = StandardScaler()
# X 데이터를 StandardScaler로 변환
X_sc = sc.fit_transform(X)
# 4) 데이터 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)# 5) 히스토그램
import matplotlib.pyplot as plt
%matplotlib inline
wine.hist(bins=10, figsize=(15,15))
plt.show()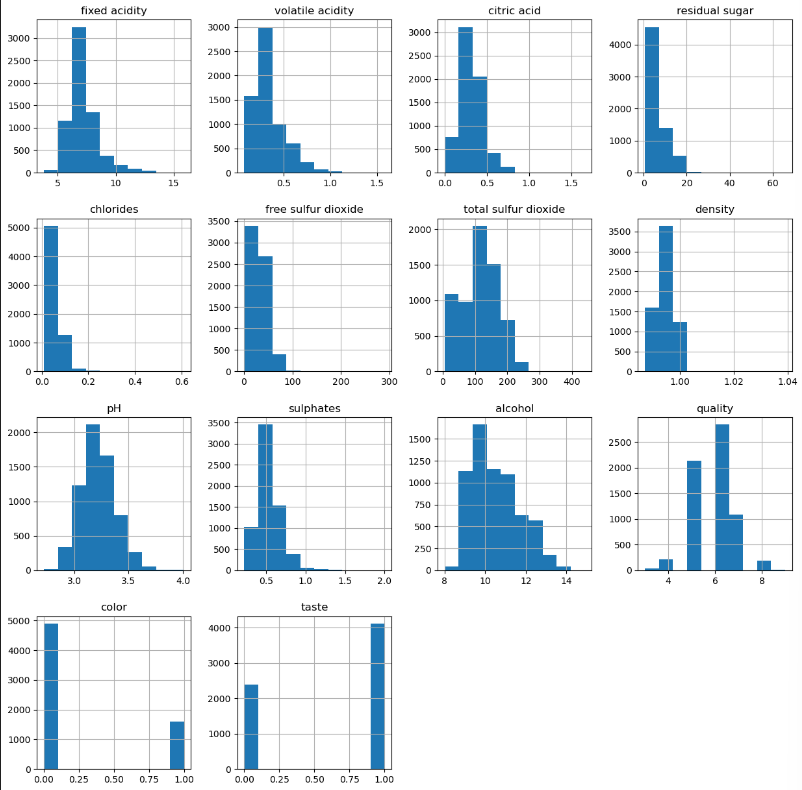
wine.columns.valuesarray(['fixed acidity', 'volatile acidity', 'citric acid',
'residual sugar', 'chlorides', 'free sulfur dioxide',
'total sulfur dioxide', 'density', 'pH', 'sulphates', 'alcohol',
'quality', 'color', 'taste'], dtype=object)
# 6) quality 별 어떤 특성이 있는지 확인
column_names = ['fixed acidity', 'volatile acidity', 'citric acid',
'residual sugar', 'chlorides', 'free sulfur dioxide',
'total sulfur dioxide', 'density', 'pH', 'sulphates', 'alcohol']
df_pivot_table = wine.pivot_table(column_names, ['quality'], aggfunc='median')
print(df_pivot_table)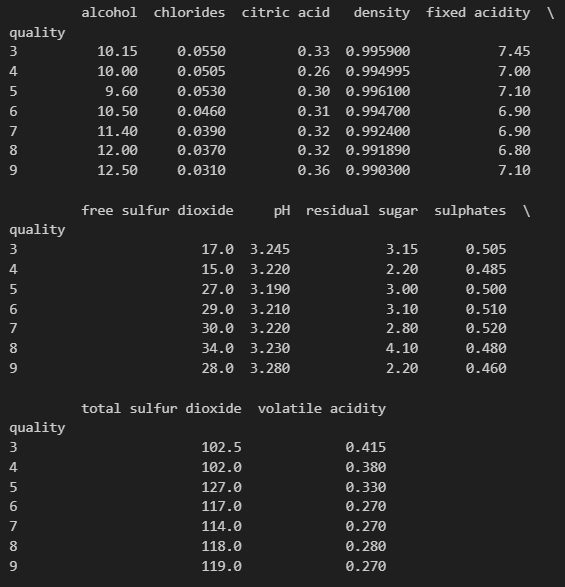
# 7) quality 대한 나머지 특성들의 상관관계
# (주의사항) : 상관관계를 sort_values로 볼때, |절대값|으로 값을 생각해야 함, -라고 안좋은게 아님.
corr_matrix = wine.corr()
corr_matrix['quality'].sort_values(ascending=False)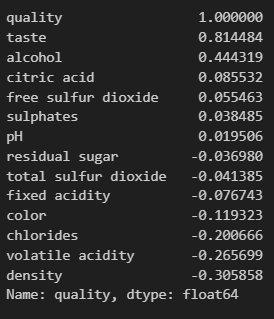
2. train
⭐오늘의 keypoint
# 8) 다양한 모델을 한번에 테스트
# ensemble(앙상블 기법) 에서 3가지 분류기 사용
from sklearn.ensemble import (AdaBoostClassifier, GradientBoostingClassifier,
RandomForestClassifier)
# 각 분류기 import
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
# 빈 리스트 만들고
models = []
# 전부 append 시켜줌 (이름, 분류기 함수()) - 리스트으로 저장(리스트는 뭐든 들어가기 때문)
models.append(('RandomForestClassifier', RandomForestClassifier()))
models.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
models.append(('AdaBoostClassifier', AdaBoostClassifier()))
models.append(('GradientBoostingClassifier', GradientBoostingClassifier()))
models.append(('LogisticRegression', LogisticRegression(solver='liblinear')))models[('RandomForestClassifier', RandomForestClassifier()),
('DecisionTreeClassifier', DecisionTreeClassifier()),
('AdaBoostClassifier', AdaBoostClassifier()),
('GradientBoostingClassifier', GradientBoostingClassifier()),
('LogisticRegression', LogisticRegression(solver='liblinear'))]
# 9) 각 분류기별 models 결과를 저장하기 위한 작업
%time
# 러닝시간 측정
# CPU times: total: 0 ns
# Wall time: 0 ns
from sklearn.model_selection import KFold, cross_val_score
results = []
names = []
# models 는 이미 리스트 안에 튜플로 되어 있음 (위에 쿼리)
# 그렇기 때문에 name 과 model로 받을 수 있음
for name, model in models:
# kfold 선언 = (5겹 폴딩, - , 5개로 나누기 전에 데이터를 썪어라)
kfold = KFold(n_splits=5, random_state=13, shuffle=True)
# 5개의 model 마다 X_train, y_train 데이터로 kfolding(cv=kfold) 시킴
cv_results = cross_val_score(model, X_train, y_train,
cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print(name, cv_results.mean(), cv_results.std())
# 결과 : results 변수에는 5개의 알고리즘 성증들이 저장되어 있음
# cv_results.mean() : training data를 5겹으로 나눈 mean(평균값)
CPU times: total: 0 ns
Wall time: 0 ns
RandomForestClassifier 0.8235476049455839 0.014660814747173595
DecisionTreeClassifier 0.7548571111275635 0.007232581517245795
AdaBoostClassifier 0.7533103205745169 0.02644765901536818
GradientBoostingClassifier 0.7663961279336641 0.02129278386035166
LogisticRegression 0.7423482268453395 0.014274628192480914
results
# 5개 알고리즘 마다 5번 폴딩했을 때 결과값(=성능)[array([0.82019231, 0.85 , 0.80846968, 0.8267565 , 0.81231954]),
array([0.75192308, 0.76538462, 0.74879692, 0.76130895, 0.74687199]),
array([0.74903846, 0.80384615, 0.72666025, 0.74687199, 0.74013474]),
array([0.77019231, 0.80192308, 0.73820982, 0.76900866, 0.75264678]),
array([0.73269231, 0.76826923, 0.74013474, 0.7439846 , 0.72666025])]
names
# results 항목명['RandomForestClassifier',
'DecisionTreeClassifier',
'AdaBoostClassifier',
'GradientBoostingClassifier',
'LogisticRegression']
# 10) croocross-validation 결과를 일목요연하게 확인하기
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(12, 5))
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()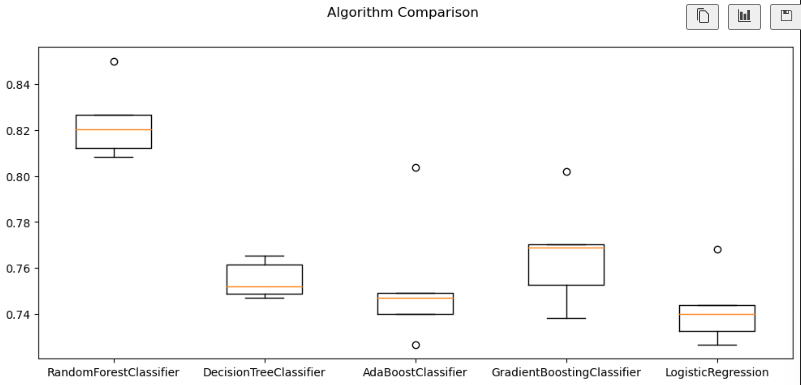
3. test
# 11) 테스트 데이터에 대한 평가 결과
from sklearn.metrics import accuracy_score
for name, model in models:
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(name, accuracy_score(y_test, pred))RandomForestClassifier 0.8392307692307692
DecisionTreeClassifier 0.7838461538461539
AdaBoostClassifier 0.7553846153846154
GradientBoostingClassifier 0.7884615384615384
LogisticRegression 0.7446153846153846
