Image Classification pipeline & Liniear classification
Image Classification : A core task in Computer Vision
-
Semantic Gap : represent image to numbers
-
Challenges
- Viewpoint Variation( = The numbers are changed when the camera moves )
- Illumination
- Deformation( = different pose & position )
- Occlusion (in medicine, something that blocks a tube or opening in the body, or when something is blocked or closed)
- Background Clutter ( = look similar to background )
- Intraclass variation
-
An image classifier (API in python)
- no obvious way the algorithm for recognizing a cat, or other classes.
def classify_image(image):
# Write magical Some codes
return class_labelData-Driven Approach (way to make algorithm work)
- Collect a dataset of images and labels
- Use Machie Learning to train a classifier
- Evaluate the classifier on new images
First classifier : Nearest Neighbor
import numpy as np
class NearestNeighbor :
def __init__(self):
pass
# Memorize training data
def train(self, X, y):
self.Xtr = X
self.Ytr = y
def predict(self, X):
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype = self.ytr.dtype) #output data type matches input type
# For each test image: Find closest train image, Predict label of nearest image
for i in xrange(num_test):
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1) #using the L1 distance (sum of absolute value differences)
min_index = np.argmin(distances) #get index with smallest distance
Ypred[i] = self.ytr[min_index]
return Ypred- in this classifier Train process is faster than Predict process (because Train Time complexity function is O(1), Predict is O(N))
- This is bad, we want faster classifier in prediction, slow for training is ok.
- Distance Metric to compare images (method to compare train and test data)
- L1 distance :
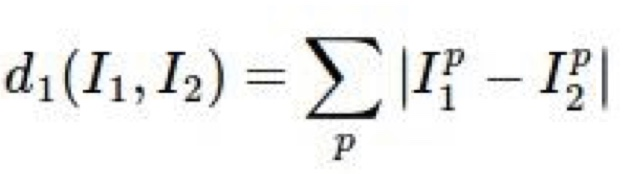 easy idea to compare images ( just compare each fixel values )
easy idea to compare images ( just compare each fixel values )
- L1 distance :
K-Nearest Neighbors
- Instead of copying label from nearest neighbor, take majority vote from K closest points
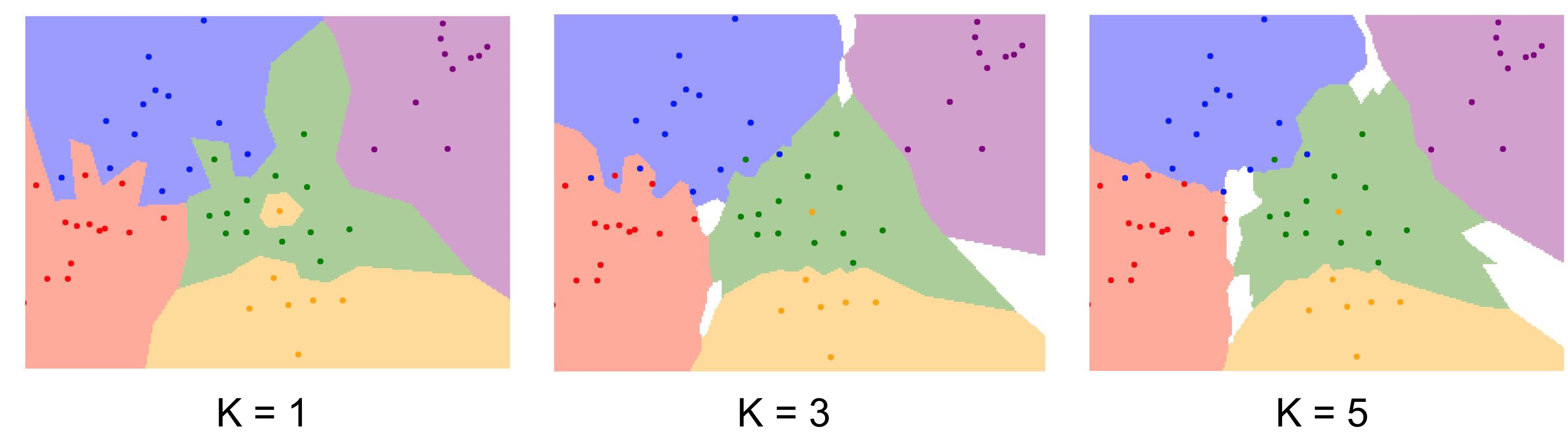
can see that the larger K, the more smooth decision boundary - K-Nearest NEighbors : Distance Metric
- L1(Manhattan) distance vs L2(Euclidean) distance (has more natural boundary)

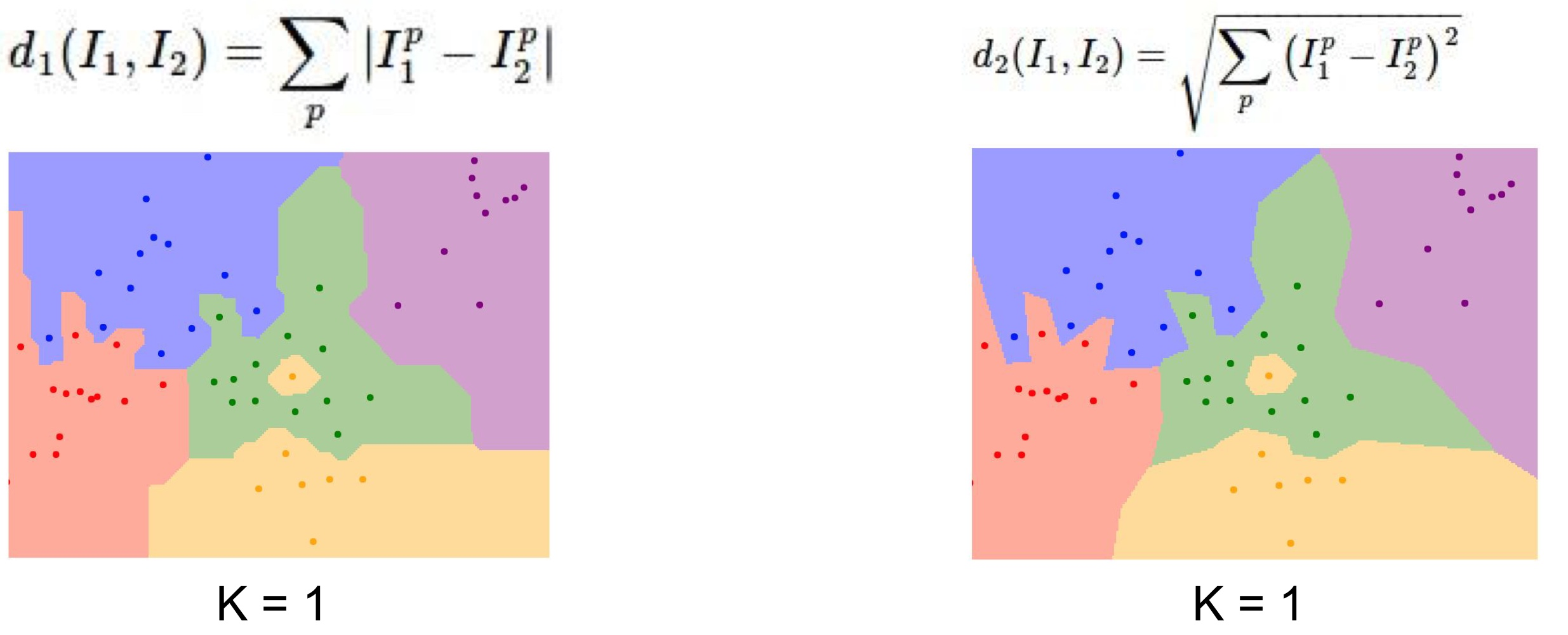
- L1 tends to follow coordinate axis because L1 depends on our choice in coordinate system.
- L2 doesn't care about coordinate axis. It just put decision boundary naturally.
Hyperparameters
What is the best value of k and distance to use?
We call this k and distance hyperparameters.
-
Must try them all out and see what works best.
-
Setting Hyperparameters
- Use all data to train data > K=1 always works perfectly on training data.
- Split data into train and test and choose hyperparameters based on result of test data. > also not good. No idea to perform on new data.
- Split data into train, test and validation data. and choose hyperparameters on validation and evaluate on test. > great idea!
- Cross-Validation : Split data into folds, try each fold as validation and average the results. Often used when quantity of data is small.
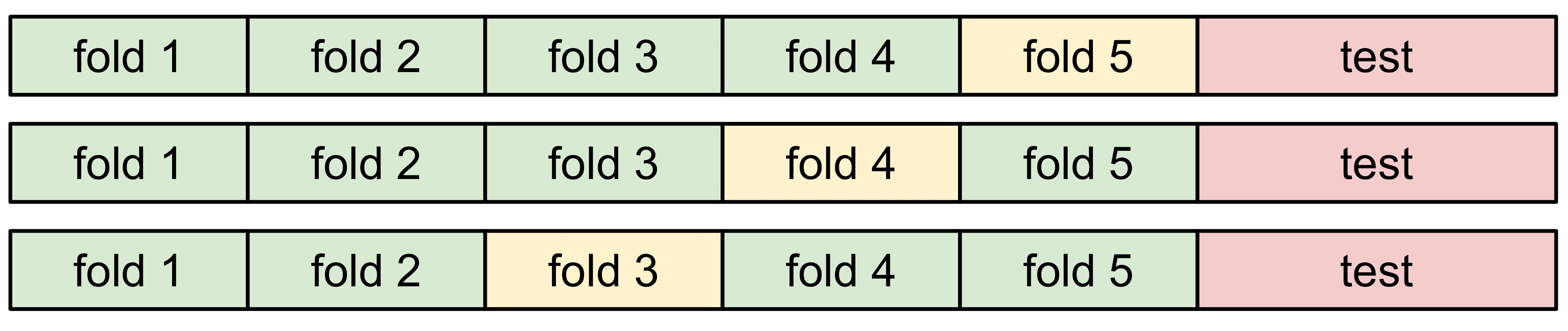
-
K-nearest Neighbor is work quite exactly. However, it can not used on images.
- Very slow at test time & Distance metrics on pixels are not informative.
- Curse of dimensionality
Summary
- In Image classification we start with a training set of images and labes, and must predict labels on the test set.
- K-Nearest Neighbors : predicts labels based on nearest training examples
- Distance matric(L1,L2) and K(in K-Nearest Neighbors) are hyperparameters
- Choose hyperparameters using the validation set; test set is used only once at the end!
Linear Classification : important to build whole NN
Parametric Approach : Linear Classifier by using weights

more detail will be introduced lecture03

Department of Artificial Intelligence, EWHA