⬇️ Main Note
https://docs.google.com/document/d/1i9yZZgG8eDm5uLsl0wNPbprtEjMj3x0hwjQZHnUZB-c/edit
🌼 Normalization: 정규화
Categorizing overlapping data to reduce the time for calling the data.
If the all data are organized in one row, it gets harder for the computer to read the data.

Multi-valued Attribute
: In one column, multiple same-attribute data existing

Primary Key (= Primary Column)
While categorizing each types of data, there occures a Primary Key.
It's like grouping keys.
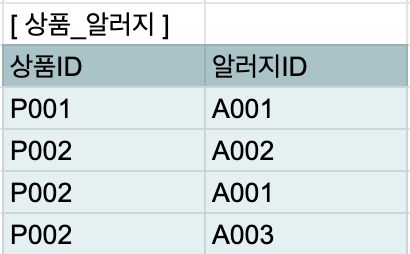
- Here, the productID and AllergyID are primary keys
Normal Form #2 vs. Normal Form #3
If primary key is getting categorized, it's Normal Form #2.
🏁 Overall the result goes like this ↘️

FK: Foreing Key (참조키, 외래키)
--> The only key that can recognize and relate with other table

🌼 ERD: Entity Relation Diagram
--> Showing the data in a form of table relationship.
(For the tool ,I used ERD Cloud)
ERD Cardinality

Overall ERD ↘️

