▷ 오늘 학습 계획: 머신러닝 강의(12~14)
📖 Chapter 06
Logistic Regression
Linear Regression은 분류 문제에 적용하기 힘들다.
Logistic Regression → '분류' 문제(0 또는 1로 예측)
다변수 데이터에서도 사용가능
- sigmoid함수에 직선의 함수를 넣어서 결과를 한정한다.
Decision Boundary: 결정 경계선
Logistic Regression에서 Cost Function
from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score lr = LogisticRegression(solver='liblinear', random_state=13) # 최적화 알고리즘(solver): 보통 데이터 수가 크지 않으면 liblinear로 설정함 lr.fit(X_train, y_train) y_pred_tr = lr.predict(X_train) y_pred_test = lr.predict(X_test) print('Train Acc : ', accuracy_score(y_train, y_pred_tr)) print('Test Acc : ', accuracy_score(y_test, y_pred_test))
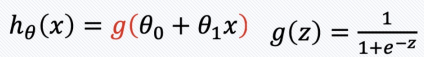
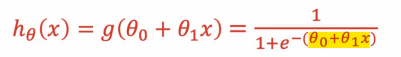

PIMA 인디언 당뇨병 예측
# pipeline 만들기 from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegressionestimators = [('scaler', StandardScaler()), ('clf', LogisticRegression(solver='liblinear', random_state=13))] pipe_lr = Pipeline(estimators) pipe_lr.fit(X_train, y_train) pred = pipe_lr.predict(X_test)from sklearn.metrics import accuracy_score, recall_score, precision_score, roc_auc_score, f1_score print('Accuracy:', accuracy_score(y_test, pred)) print('Recall:', recall_score(y_test, pred)) print('Precision:', precision_score(y_test, pred)) print('AUC score:', roc_auc_score(y_test, pred)) print('f1 score:', f1_score(y_test, pred)) # 상대적 의미를 가질 수 없어서 수치 자체를 평가할 수는 없다.# 다변수 방정식의 각 계수 값 확인 coeff = list(pipe_lr['clf'].coef_[0])
Precision and Recall
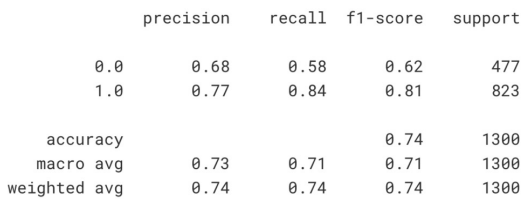
classification_report
from sklearn.metrics import classification_report print(classification_report(y_test, lr.predict(X_test)))
precision(0.77): 1이라고 예측한 것 중에 실제 1인 확률
recall(0.84): 실제 1 중에서 1을 맞춘 확률
support(823): 전체 데이터(477+823)중에 '1' 데이터의 개수
macro avg: 각 클래스 별로 precision의 평균
weighted avg: 클래스별 분포 반영(0.74 = 0.58(477/1300) + 0.84(823/1300))confusion matrix
from sklearn.metrics import confusion_matrix confusion_matrix(y_test, lr.predict(X_test))
전체 0 중에서 275개를 0이라고 했고, 202개를 1이라고 했다.
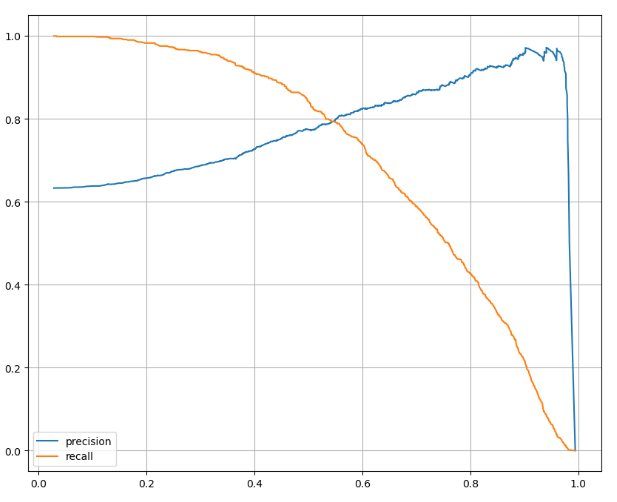
전체 1 중에서 131개를 0이라고 했고, 692개를 1이라고 했다.precision_recall curve
import matplotlib.pyplot as plt from sklearn.metrics import precision_recall_curve %matplotlib inlineplt.figure(figsize=(10,8)) pred = lr.predict_proba(X_test)[:, 1] precisions, recalls, thresholds = precision_recall_curve(y_test, pred) plt.plot(thresholds, precisions[:len(thresholds)], label='precision') plt.plot(thresholds, recalls[:len(thresholds)], label='recall') plt.grid(); plt.legend(); plt.show()
threshold 바꾸기(Binarizer)
from sklearn.preprocessing import Binarizer binarizer = Binarizer(threshold=0.6).fit(pred_proba) pred_bin = binarizer.transform(pred_proba)[:, 1] # print(classification_report(y_test, pred_bin)) # confusion_matrix(y_test, pred_bin)

앙상블 기법
앙상블 학습을 통한 분류: 여러 개의 분류기를 생성하고 그 예측을 결합하여 정확한 최종 예측을 기대하는 기법
앙상블 학습의 목표: 다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측값을 얻는 것
Voting, Bagging, Boosting, 스태깅 등으로 나눈다.
Voting, Bagging: 여러개의 분류기가 투표를 통해 최종 예측 결과를 결정
- 정형데이터를 대상으로 하는 분류기에서는 앙상블 기법이 뛰어난 성과를 보여주고 있다.
- 비정형 데이터(이미지, 영상): 딥러닝이 효과가 좋은 편이다.
- 정형 데이터(표로 구성된 데이터): 주로 머신러닝
voting
데이터 전체를 대상으로 여러 알고리즘을 적용해서 결과를 투표로 결정함
(각각 다른 분류기 사용)bagging
중복을 허용해서 데이터 샘플링, 그 각각의 데이터에 같은 알고리즘을 적용해서 결과를 투표로 결정함(같은 분류기 사용)
부트스트래핑(bootstrapping) 분할 방식: 각각의 분류기에 데이터를 각각 샘플링해서 추출하는 방식Random Forest
bagging의 대표적인 방법
앙상블 방법 중에서 비교적 속도가 빠르며 다양한 영역에서 높은 성능
결정 나무를 기본으로 함(부트스트래핑으로 샘플링된 데이터마다 결정나무가 예측한 결과를 소프트보팅으로 최종 예측 결론을 얻는다)최종 결정 방법
- 하드보팅(다수결의 원칙과 비슷함)
- 소프트보팅(확률의 평균을 구해서 비교)
HAR(Human Activity Recognition)
IMU 센서를 활용해서 사람의 행동을 인식하는 실험
시간 영역 데이터를 머신러닝에 적용하기 위해 여러 통계적 데이터로 변환함결정나무
from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score dt_clf = DecisionTreeClassifier(random_state=13, max_depth=4) dt_clf.fit(X_train, y_train)pred = dt_clf.predict(X_test) accuracy_score(y_test, pred) # 0.8096369189005769GridSearchCV
from sklearn.model_selection import GridSearchCV params = {'max_depth': [6, 8, 10, 12, 16, 20, 24]}grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring='accuracy', cv=5, return_train_score=True) grid_cv.fit(X_train, y_train) grid_cv.best_score_ #0.8543335321892183 grid_cv.best_params_ #{'max_depth': 8}best_dt_clf = grid_cv.best_estimator_ pred1 = best_dt_clf.predict(X_test) accuracy_score(y_test, pred1) # 0.8734306073973532랜덤 포레스트
from sklearn.model_selection import GridSearchCV from sklearn.ensemble import RandomForestClassifier params = { 'max_depth':[6,8,10], 'n_estimators':[50, 100, 200], # decision tree 몇 그루 쓸건지 'min_samples_leaf':[8,12], # 가장 끝에 있는 데이터의 개수 'min_samples_split':[8,12] }rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1) # n_jobs -> 사용할 cpu core의 개수(-1은 모두 사용한다는 뜻) grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1) grid_cv.fit(X_train, y_train) grid_cv.best_score_ # 0.9151251360174102rf_clf_best = grid_cv.best_estimator_ rf_clf_best.fit(X_train, y_train) pred1 = rf_clf_best.predict(X_test) accuracy_score(y_test, pred1) # 0.9205972175093315→ 561개의 특성 중에 중요한 특성 20개만 가지고 성능을 다시 확인하면 accuracy는 떨어지지만 연산 속도는 훨씬 빠르다.
▷ 다음주 학습 계획: 머신러닝 강의
