▷ 오늘 학습 계획: 머신러닝 강의(1~2)
📖 Chapter 01_머신러닝이란?
명시적으로 프로그래밍하지 않고도 컴퓨터에 학습할 수 있는 능력을 부여하는 학문(Arthur Samuel)
Iris Classification
데이터관찰 (python) → '알고리즘'(정량적 수치 제시)
Decision Tree의 분할 기준(Split Criterion)
- 엔트로피: 열역학에서 처음 등장하는 개념으로 무질서(disorder), 불확실성(uncertainty)의 정도를 나타낸다. 정보의 종류가 적을 수록 낮은 값을 가진다. (p: 해당 데이터가 해당 클래스에 속할 확률)
어떤 확률 분포로 일어나는 사건을 표현하는 데 필요한 정보의 양이며 이 값이 커질수록 확률 분포의 불확실성이 커지고 결과 예측이 어려워짐
이 확률들의 합을 엔트로피라고 함
- 지니계수
- 엔트로피, 지니계수: 결정나무에서 분할 기준
Scikit Learn: 현재 파이썬에서 가장 유명한 기계 학습 오픈 소스 라이브러리
- sklearn을 이용한 결정나무의 구현
from sklearn.tree import DecisionTreeClassifier iris_tree = DecisionTreeClassifier() iris_tree.fit(iris.data[:, 2:], iris.target)
- Accuracy 확인
accuracy score: 참값 대비 예측값의 비율from sklearn.metrics import accuracy_score y_pred_tr = iris_tree.predict(iris.data[:, 2:]) accuracy_score(iris.target, y_pred_tr)
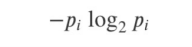
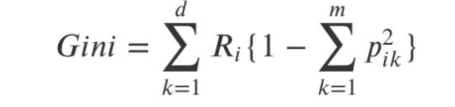
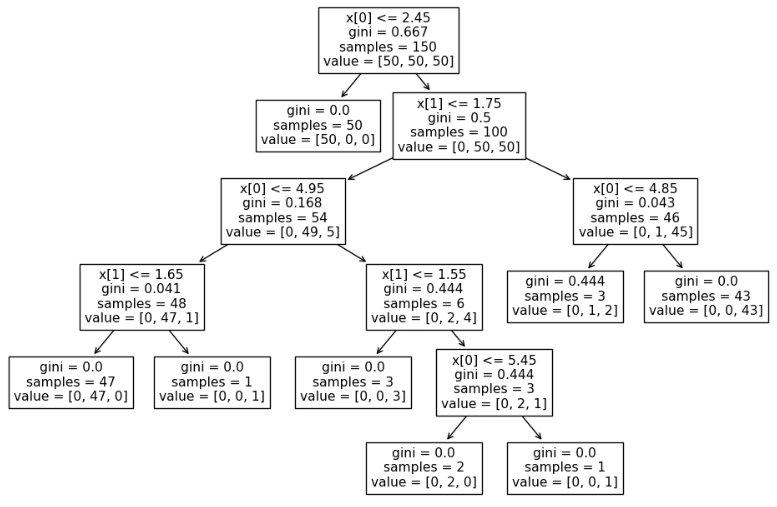
Decision Tree를 이용한 Iris 분류
과적합
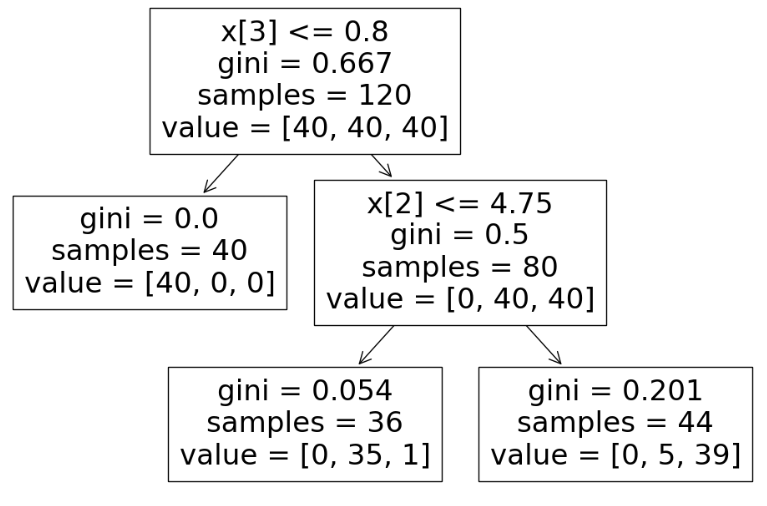
from sklearn.tree import plot_tree plt.figure(figsize=(12,8)) plot_tree(iris_tree);
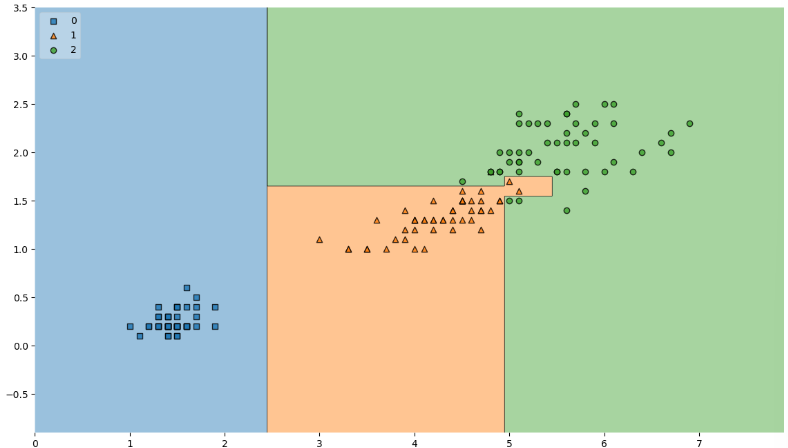
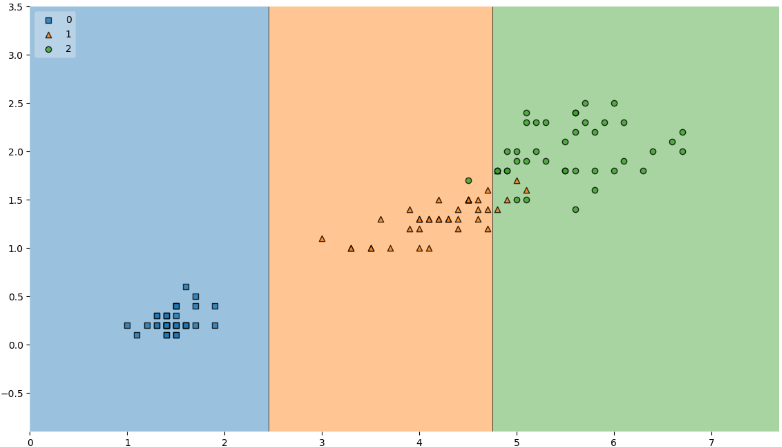
from mlxtend.plotting import plot_decision_regions plt.figure(figsize=(14,8)) plot_decision_regions(X=iris.data[:, 2:], y=iris.target, clf=iris_tree, legend=2) plt.show()
복잡한 경계면은 모델의 성능을 결국 나쁘게 만든다
데이터 분리
- 지도 학습: 학습 대상이 되는 데이터에 정답(label)을 붙여서 학습 시키고 모델을 얻어서 완전히 새로운 데이터에 모델을 사용해서 “답”을 얻고자 하는 것
- 데이터의 분리(훈련/검증/평가): 확보한 데이터 중에서 모델 학습에 사용하지 않고 빼둔 데이터를 가지고 모델을 테스트
from sklearn.model_selection import train_test_split features = iris.data[:, 2:] labels = iris.target X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, stratify=labels, random_state=13) # 각 클래스(setosa, versicolor, verginica) 별로 동일 비율: stratify # test_size=0.2 → 데이터를 8:2로 훈련용과 테스트용으로 나누기 # features → 원 데이터의 이름 # labels → 지도학습을 위한 라벨
- unique 검사
np.unique(y_test, return_counts=True)
- train 데이터로 결정나무 모델 만들고 accuracy 확인
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13) iris_tree.fit(X_train, y_train) # random_state: 학습할 때 마다 일관성 # max_depth: 모델 단순화 y_pred_tr = iris_tree.predict(iris.data[:, 2:]) accuracy_score(iris.target, y_pred_tr)
결정나무 모델
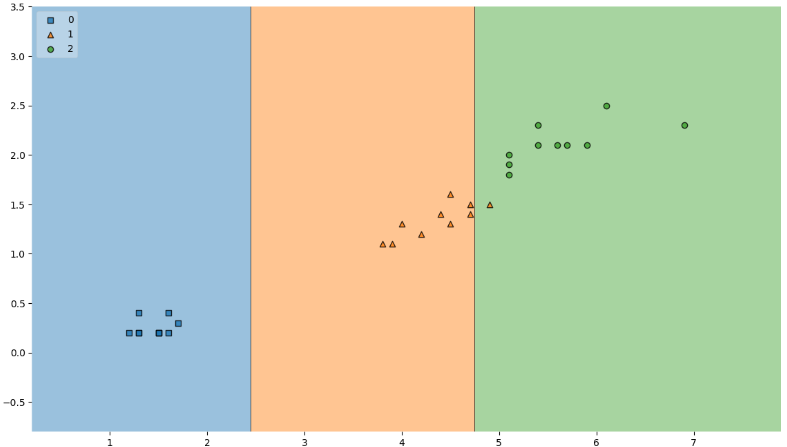
train 데이터 결정경계 확인
plt.figure(figsize=(14,8)) plot_decision_regions(X=X_train, y=y_train, clf=iris_tree, legend=2) plt.show()
- 테스트 데이터 accuracy
y_pred_test = iris_tree.predict(X_test) accuracy_score(y_test, y_pred_test)
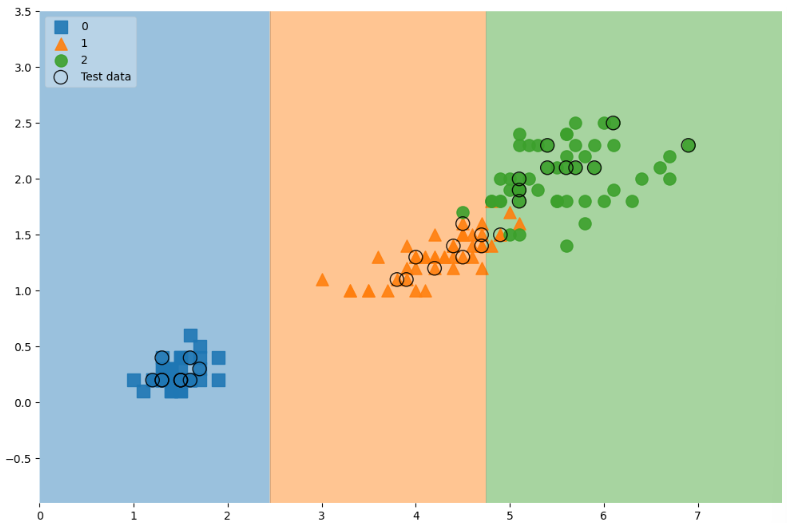
- 전체 데이터에서 관찰
scatter_highlight_kwargs = {'s':150, 'label':'Test data', 'alpha':0.9} scatter_kwargs = {'s':120, 'edgecolor':None, 'alpha':0.9} plt.figure(figsize=(12,8)) plot_decision_regions(X=features, y=labels, X_highlight=X_test, clf=iris_tree, legend=2, scatter_highlight_kwargs=scatter_highlight_kwargs, scatter_kwargs=scatter_kwargs, contour_kwargs={'alpha':0.2})
feature 4개 모두 사용
모델 사용하기
test_data = np.array([[4.3, 2., 1.2, 1.]]) iris_tree.predict(test_data) #array([1]) iris_tree.predict_proba(test_data) # array([[0. , 0.97222222, 0.02777778]]) iris.target_names[iris_tree.predict(test_data)] # array(['versicolor'], dtype='<U10') iris_tree.feature_importances_ # array([0. , 0. , 0.42189781, 0.57810219]) dict(zip(iris.feature_names, iris_tree.feature_importances_))

zip, unpacking
zip: 같은 위치의 데이터끼리 묶기
list1 = ['a', 'b', 'c'] list2 = [1,2,3]pairs=[pair for pair in zip(list1,list2)] pairs # [('a', 1), ('b', 2), ('c', 3)]dict(pairs) # {'a': 1, 'b': 2, 'c': 3}dict(zip(list1,list2)) # {'a': 1, 'b': 2, 'c': 3}x, y = zip(*pairs) print(x) # ('a', 'b', 'c') print(list(y)) # [1, 2, 3]
▷ 내일 학습 계획: 머신러닝 강의(3~4)
