

개요
대기업 커머스로 부터 매체별 광고등록 프로세스에 사용하기 위한 상품 EP 데이터를 제공받고 자체 필터링하여 매체별로 피드를 생성하는 프로세스가 기존에 있었다.
대략 1~2억 개의 대용량 상품 ep데이터이다.
기존에는 필터링 해야할 카테고리, 상품이름에 포함된 단어를 config에 하드코딩 하여 정규식을 통해 자바스크립트 필터링을 진행했고
매일 아침 필터링 시간 총 4 시간 이상 소모되었다.
8개 pm2 클러스터링 분산처리를 통해 시간을 단축해서 진행 중이었다.
기존 구조
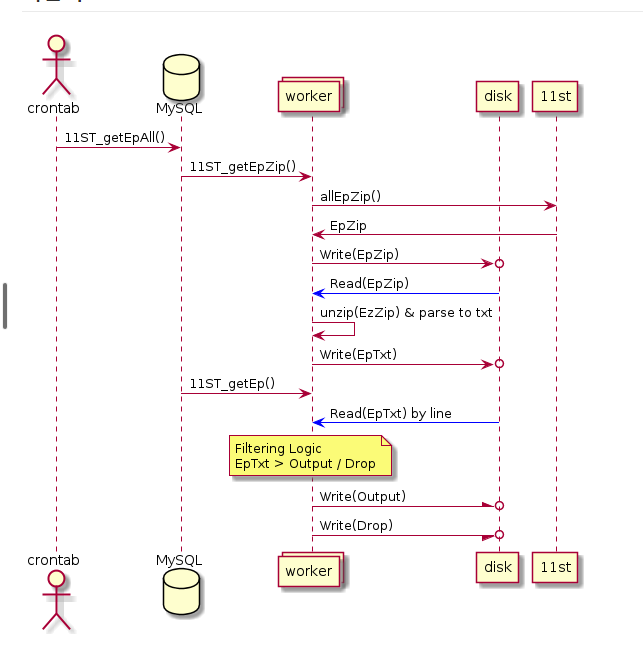
요구사항
- 필터링 정보를 동적으로 입력받아서 상품을 필터링 할 수 있는 화면을 개발
- 속도 개선 (분산 처리 없이)
개발절차
-
API 서버 개발
- 간단한 문자열 데이터들을 다루는 API
- 화면에서의 CRUD 동작, 필터링 모듈에서도 필터링 정보를 GET 하기위해 동시 사용될 rest API
- DB 설계
- express server 개발
-
속도개선
-
기존에 js 필터링은 4시간 이상 소모되어서 8개 분산처리 를 통해 30분 가량 소모.
-
메모리를 많이 사용하면서 정확한 에러핸들링과 누락 데이터 확인이 어려웠음.
-
기존 절차
- ep 데이터 zip 파일 다운로드 후 unzip -> txt
- txt JS 정규식 필터링 -> tsv
- DB Load
문제점: zip 다운로드 / txt unzip 등 디스크 write 과다함. 속도 느림
-
개선 절차
- zip파일 다운로드 -> unzip -> 필터링 -> write 까지 stream으로 디스크 사용없이 처리
- 필터링 이후 tsv 파일 write ( 대용량 DB 업로드는 load file이 더 빠르다고 판단해서 최종 tsv 파일 저장은 불가피 하다고 판단)
- cpp 필터링.
-
cpp 필터링
- jsoncpp, sstreamm, fstream
- 속도가 빠른 cpp를 통한 필터링 로직을 개발
- 카테고리 ID / 상품ID 의경우 정수이기 때문에 이분 탐색 알고리즘 적용
- 문자열 키워드 / 다중검색의 경우 트라이(Trie) 자료구조 사용
결과
-
분산처리 없이 단일 프로세스로 필터링 20분 소모
-
디스크 용량 사용 1/3 로 최소화 (메모리 절감)
-
개인적으로 알고리즘 공부의 실제 적용사례를 대용량 데이터 처리를 위해 사용해보면서 재미도 있고 실제 성능 향상에 대한 보람을 느끼게 되었음.

backend