
인덱스(Index)란?
인덱스는 어떤 대상을 식별하는 값이다.
인덱스라는 단어를 들으면 가장 먼저 사전의 색인이 떠오른다.
수많은 페이지 중 원하는 내용을 빠르게 찾기 위해 색인을 사용한다.
이처럼 대용량 데이터에서 원하는 데이터를 빠르게 조회하기 위해 인덱스를 사용한다.
참고로 인덱스는 주 메모리에 존재하며 실제 데이터는 보조 메모리에 존재한다.
따라서 데이터 I/O 과정을 최소화 하는 것이 성능 최적화에 도움이 된다.
인덱스가 필요한 이유
선형 자료구조는 탐색 시간이 오래 걸린다. 비선형 구조로 변경하면 탐색 시간을 줄일 수 있다.
데이터베이스 데이터는 선형으로 보관된다. 선형 자료구조는 원하는 데이터를 찾기 위해 기본적으로 풀스캔(Full Scan)하여 탐색해야 한다.
이러한 선형 구조를 트리와 같은 비선형 구조로 변경하면 탐색 횟수가 적어지고, 탐색 속도는 빨라진다. 이는 데이터가 존재하지 않음을 확인할 때에도 유리하다.
이 때문에 인덱스는 B-Tree와 같은 자료구조 형태를 갖는다.
인덱스의 종류
Clustered Index
- 인덱스와 데이터가 함께 저장되는 구조이다.
- 기본적으로 PK 제약조건을 설정하면 생성된다.
- 이 인덱스 컬럼을 기준으로 데이터를 정렬하기 때문에 테이블당 하나만 가질 수 있다.
- 정렬된 형태로 데이터가 저장되기 때문에 데이터가 많을수록 INSERT, UPDATE, DELETE 시 많은 부하가 발생한다.
Non-Clustered Index
- 인덱스와 데이터가 따로 저장된다.
- 정렬되지 않은 상태로 데이터를 저장한다.
- 메모리 주소를 간접적으로 참조하는 형태
인덱스 자료구조
B-Tree(Balanced Tree)
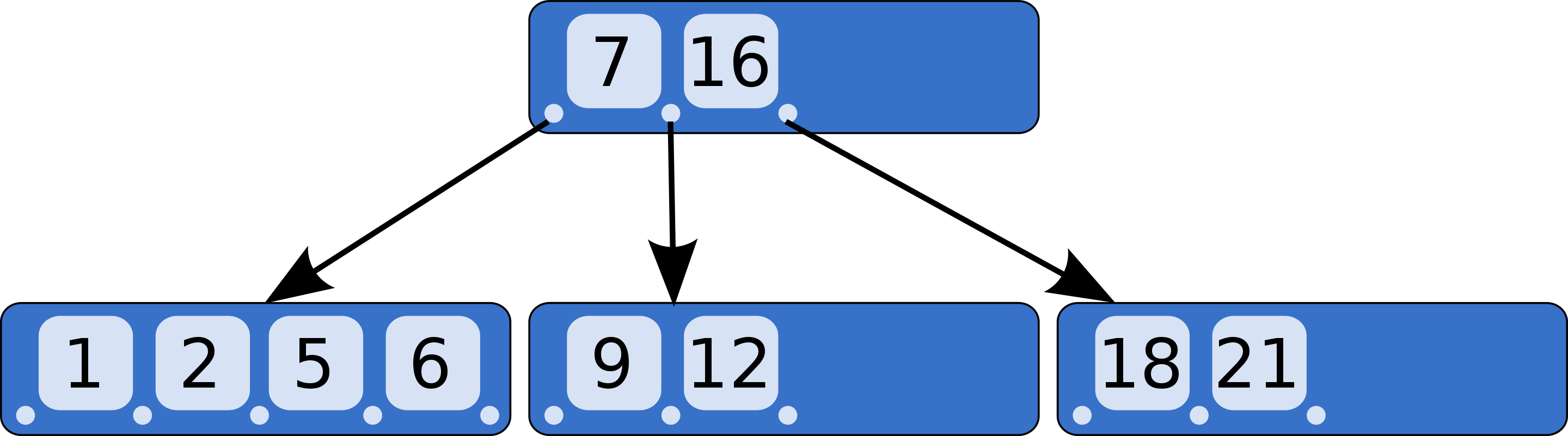
이진 트리에서 변화된 트리 구조로 두 개 이상의 자식 노드를 가질 수 있으며, 높이가 같다는 것이 특징이다.
인덱스를 지정할 때 기준
- 카디널리티가 높은 컬럼을 지정한다.
카디널리티는 그룹의 고유한 요소 수인데, 이 값이 높을 수록 유일한 값들이 많다는 것이고, 그만큼 데이터를 식별하기가 수월하다는 의미이다.
ex) 성별 < 이름 < 주민등록번호 - 수정이 빈번하지 않은 컬럼이 좋다.
이메일이 PK가 되면 어떤 문제가 있을까?
Primary Key는 Clustered Index이기 때문에 인덱스를 기준으로 데이터가 정렬된다. 이메일이 PK가 된다면 데이터는 이메일을 기준으로 정렬되는 것이다. 그렇다면 새로운 데이터가 삽입될 경우 데이터의 중간에 들어 갈 가능성이 높다. 데이터가 중간에 삽입된다면 뒤에 있는 데이터들이 하나씩 뒤로 밀려나야 하며, 이는 성능에 부하를 줄 수 있다.
이러한 이유 때문에도 기본키(PK)는 비즈니스적인 의미가 없는 자동 증가 숫자(Auto Increment)로 지정하는 경우가 많다.
참고 자료
