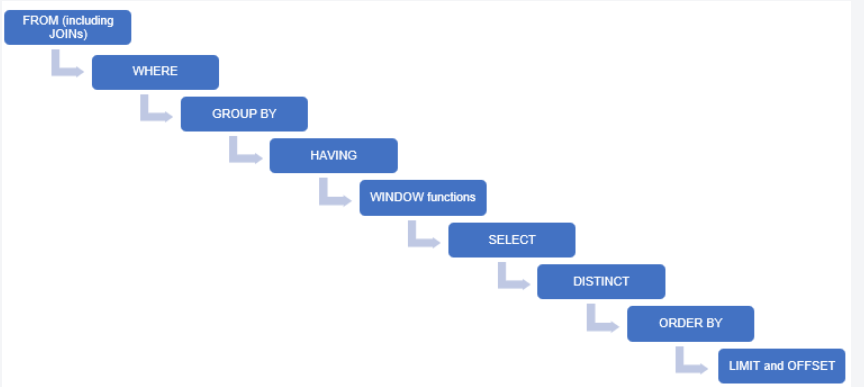
SQL에서 SELECT Query는 아래 순서로 수행된다.
FROM ➡️ WHERE ➡️ GROUP BY ➡️ HAVING ➡️ SELECT ➡️ ORDER BY
1) FROM
FROM절에 명시된 테이블이 실제로 존재하는 테이블인지 확인한다. 그리고 SELECT 권한이 있는지도 체크한다. 만약 권한이 없는데 명령을 요청한 경우 semantic error가 발생한다.
2) WHERE
조건에 해당하는 로우(ROW)를 검색한다.
3) GROUP BY
가져온 로우들을 어떤 방식으로 GROUB BY(압축)할 것인지 체크한다.
💡 SELECT절보다 먼저 실행되기 때문에 SELECT절에서 지정한 Alias를 사용할 수 없다.
4) HAVING
GROUP BY 한 로우 중에 버려야할 데이터들이 있는지 체크한다.
5) SELECT
가져온 로우들 중에 어떤 컬럼들을 출력해야 할지를 체크한다.
💡 일단 로우를 가져오고 난 다음에 SELECT절을 체크하기 때문에 SELECT * FROM 한 것과 컬럼 1개만 SELECT 하는 것과 I/O 비용은 사실상 같다.
6) ORDER BY
SELECT절보다 나중에 실행되기 때문에 SELECT 절에서 지정한 Alias를 사용할 수 있다.
알게된 점
데이터베이스의 데이터는 블록 단위로 저장된다. 블록에는 테이블의 데이터들이 로우 단위로 저장되어 있다. 따라서 데이터를 가져올 때에도 로우 단위로 가져오기 때문에 SELECT 절에 전체 컬럼을 지정하는 것과 일부 컬럼의 지정하는 것은 I/O 비용 측면에서 차이가 없다.
참고 자료
https://qxf2.com/blog/mysql-query-execution/
https://youtu.be/eeq0wDl3bLs
