[Paper Review] PointPainting: Sequential Fusion for 3D Object Detection
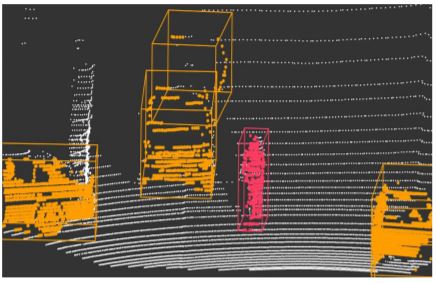
오늘 소개할 논문은 CVPR2020에 나온 "PointPainting: Sequential Fusion for 3D Object Detection"입니다.
image와 LiDAR를 함께 이용하는 sensor fusion 기반의 3D object detection에 관한 논문인데요, object detection을 위한 딥러닝 아키텍처 전체가 아닌,
기존의 모든 LiDAR 기반 3D object detection 아키텍처에 붙일 수 있는 PointPainting이라는 모듈을 제안한 논문입니다.
컨셉은 정말 간단합니다. 다음 논문 그림을 함께 보시죠.
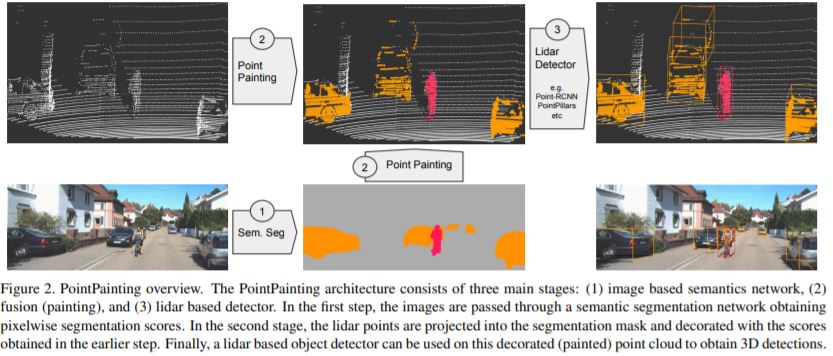
1. image에 대해서 먼저 semantic segmentation을 수행합니다.
2. LiDAR를 image에 projection하고, projection된 pixel의 segmentation 정보를 LiDAR 정보에 concat합니다.
3. segmentation 정보를 붙인 LiDAR point cloud를 기존의 LiDAR 기반 3D object detection 아키텍처에 넣어줍니다.
이게 전부입니다. 기존의 아키텍처에서 바꿔야 하는 부분은 입력 차원뿐입니다.
LiDAR 정보가 로 구성되었다고 한다면, LiDAR 기반 3D object detector는 입력 차원이 3차원이었을 것입니다.
이 때, segmentation class가 10개라고 한다면, segmentation의 결과로 각 pixel에 존재하는 segmentation score는 길이가 인 벡터가 될 것이고,
LiDAR point에 concat시키면 차원이 되어, 입력 차원만 차원으로 바꾸어주면 기존의 아키텍처를 그대로 사용할 수 있습니다.
PointPainting이라는 제목이 딱 와닿지 않으시나요?
image의 semantic segmentation 정보로 LiDAR point를 painting한다!
이 논문이 무엇을 하려는 것인지 알고자 하셨던 분들은 여기서 이 포스팅을 그만 읽으셔도 무방하실 것 같습니다.
여기서부터는 논문 내용을 좀 더 자세히 정리하는 것으로 이어가도록 하겠습니다.
Introduction
상식적으로 생각했을 때, LiDAR만 이용하는 것보다, image를 함께 이용하는 sensor fusion 기반의 방법이 성능이 좋아야 합니다.
LiDAR는 정확한 거리 정보를 제공해주고, image는 기하적인 정보나 semantic한 정보를 제공해주니까 함께 이용하면 당연히 더 잘 되지 않을까요?
하지만 KITTI 3D object detection leaderboard를 보면,
LiDAR만 이용하는 detector가 대부분의 순위를 차지하고 있습니다.
2020년 7월 22일 기준, Car 기준 상위 15위까지를 가져왔습니다.
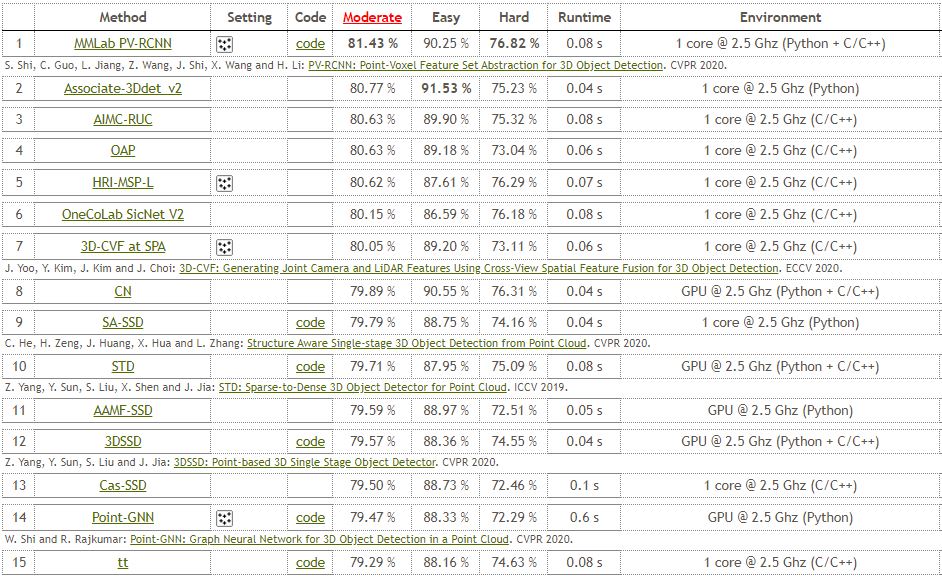
관련 논문이 있는 것만 보았을 때(1, 7, 9, 10, 12, 14),
7위를 제외하고는 전부 LiDAR만 사용한 detector입니다.
(여담으로 현재 sensor fusion 기반 방법 중 최고 순위인 7위 논문은 한양대 최준원 교수님 연구실에서 나온 논문인데요, 저자 중 1명이 중학교 때 친구인 것을 알고 정말 반가웠습니다. ECCV 2020에 accept되었고, 논문도 읽어보았는데요, 추후 포스팅해보겠습니다.)
이렇게 상식(?)과는 다르게 두 데이터를 잘 fusion하는 게 쉽지 않은 것을 알 수 있습니다.
이 논문에서는 그 이유 중 하나로 viewpoint misalignment를 들고 있습니다.
LiDAR와 image모두 데이터 수집은 앞에서 본 형태로 수집이 되죠.
차량에 센서를 장착해 측정을 하니까요. 하지만 최근의 많은 방법들이, LiDAR 데이터에 대해 convolution을 수행할 때 bird's-eye view(이하 BEV)를 이용합니다.
BEV는 다들 아시겠지만, 아래 그림처럼 하늘에서 내려다 본 형태로 나타내는 것을 말합니다.

왜 BEV를 이용할까요?
근본적으로 CNN은 2D image 처리를 잘 하기 위한 형태로 발전해왔고,
image는 기본적으로 모든 위치에 pixel 값이 존재하는, dense한 특성을 갖는 반면,
LiDAR point는 3D 공간의 극히 일부분에만 존재하는, sparse한 특성을 갖기 때문에 CNN을 단순히 3차원으로 확장해서 LiDAR에 적용한다고 잘 작동하지 않습니다.
실제로 LiDAR 기반의 3D object detection 논문에서 비중있게 다루는 부분이, '어떻게 LiDAR point에 convolution을 잘 수행할 것인가'가 되고, 그 방법으로는 3차원 공간 상에서 sparse한 특성에 맞추어 변형된 3D CNN을 적용하는 방법(Voxelnet, SECOND 등), 2차원으로 projection시켜서 전형적인 2D CNN을 적용하는 방법(pointpillar, STD 등) 등이 있습니다.
BEV도 결국 지면 방향으로 projection 시킨 것으로 생각할 수 있으니까 2번째 방법에 속한다고 볼 수 있겠죠? 2D CNN이 3D CNN보다 훨씬 빠르게 동작한다는 장점이 있기에, sensor fusion 기반의 object detection 방법론에서도 이를 많이 이용해왔습니다.
하지만 정면에서 본 형태의 image와 BEV로 projection시킨 LiDAR point는 시점(viewpoint)이 다르기 때문에 fusion이 잘 되지 않는다고 저자는 주장하고 있는 것입니다.(viewpoint misalignment)
PointPainting은, image에 대해 segmentation을 수행하고, 그 segmentation 결과를 대응되는 LiDAR point에 붙여버린 뒤, 이후 과정은 LiDAR object detector에 넣어버립니다.
즉 image와 LiDAR를 따로 parallel하게 처리한 다음 fusion하는 방식이 아니라, LiDAR를 처리하기 전에 image segmentation 정보를 LiDAR에 주입한 후 LiDAR를 처리하는 sequential한 방법입니다.
그래서 BEV 기반의 방법을 적용하더라도 image segmentation 결과들이 이미 LiDAR point들에 잘 붙어있으므로 LiDAR와 따로 놀지 않고 detection에 함께 잘 이용될 수 있다~는 컨셉으로 이해할 수 있겠습니다.
비유를 위해 초콜릿 쿠키를 만들고 싶다고 해봅시다.
카카오(image)와 밀가루 반죽(LiDAR)이 있습니다.
기존의 방법은 카카오로 초콜릿 만들고, 밀가루 반죽을 구워서 쿠키로 만든 다음 합치는 것입니다. 이미 딱딱하게 굳은 쿠키에 초콜릿이 잘 합쳐지지 않겠죠? 초콜릿쿠키가 아니라 그냥 초콜릿 and 쿠키입니다.
하지만 일단 카카오(image)로 초콜릿(segmentation 결과)을 만들고, 밀가루 반죽(LiDAR)에 잘 끼워넣은 다음(PointPainting) 오븐(LiDAR object detector)에 구우면 맛있는 초콜릿 쿠키가 만들어지는 것입니다!
막상 쓰고 보니 괜히 쓸데없는 비유를 한 것 같기도 하네요 ㅎㅎ
다시 돌아와서, sequential한 방법의 치명적인 단점은 속도입니다.
LiDAR object detector가 아~~무리 빨라도 segmentation이 느리면 아무 의미도 없겠죠? 이 논문에서는 해당 문제를 pipelining으로 해결할 수 있다고 말합니다.
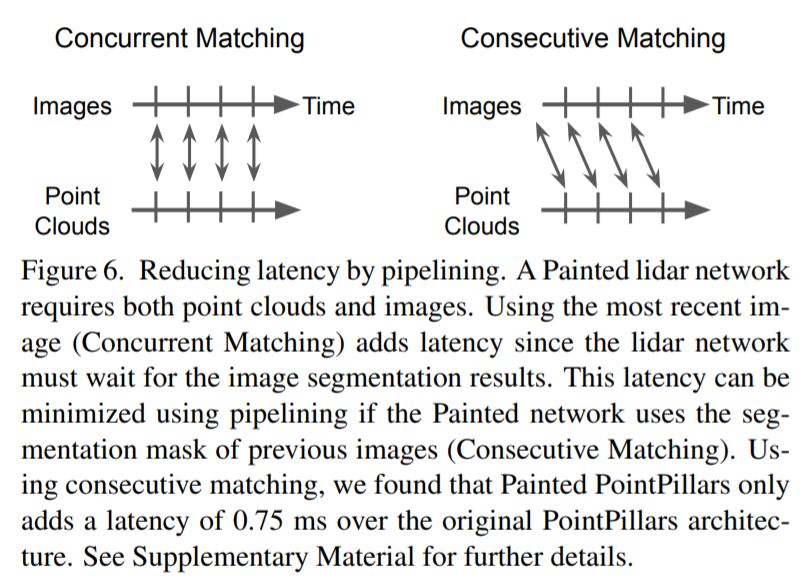
pipelining이 특별한 게 아니고, 그냥 이전 프레임의 segmentation 결과를 현재 프레임으로 가져와서 쓰겠다는 겁니다(consecutive).
현시점의 segmentation 결과를 이용하려면(concurrent) segmentation 완료를 기다려야겠지만, 이전 시점의 segmentation 결과는 이미 갖고 있을테니까요.
실험을 해보니 성능은 별 차이가 없고, 속도 이득은 크기 때문에 pipelining이 의미가 있다고 저자는 주장하고 있습니다. 다음 table을 참고해주세요.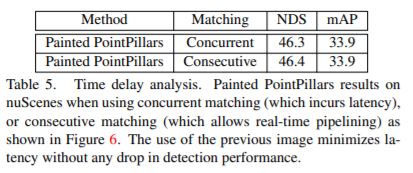
저자는 이렇게 아무 LiDAR 기반 detector에 쉽게 붙일 수 있고, 속도 저하 없이 성능을 높일 수 있다는 점을 PointPainting의 main contribution으로 들고 있습니다.
Related works
논문에 Related works 섹션이 따로 있지 않은데요, introduction에 fusion 기반의 object detection 연구 흐름이 잘 정리되어 있어 Related works로 정리를 해보겠습니다.
기존의 방법은 다음의 4가지로 분류할 수 있다고 합니다.
- Object-centric fusion
- continuous feature fusion
- image를 BEV representation으로 변형한 뒤 fusion
- detection seeding
-
Object-centric fusion
MV3D, AVOD에서 사용한 방법으로,2-stagedetector를 기반으로 합니다. image와 LiDAR가 각각 다른 backbone network로 처리되고, region proposal 단계에서 RoI pooling을 통해 두 센서의 feature를 fusion해서 classification과 bbox regression을 수행하는 방법입니다. -
continuous feature fusion
image와 LiDAR를 각기 다른 backbone으로 쭉 처리하고 fusion하는 것이 아니라, network layer마다 fusion을 수행하는 방식입니다. 하지만 image와 LiDAR BEV의 해상도가 다르기 때문에feature blurring문제가 존재한다고 합니다. 가령 image에서의 여러 pixel이 BEV의 하나의 pixel에 대응된다면 fusion 과정에서 image feature는 blurring 될 수 있다는 의미인 듯 합니다. 대표적인 논문으로는 ContFuse라고 불리는 논문이 있습니다. -
image를 BEV representation으로 변형한 뒤 fusion
image를 BEV representation으로 변형한다는 것은, 정확히는 image로부터 뽑은 depth 정보를 BEV representation으로 변형한다는 것입니다. CVPR 2019에 나왔던 Pseudo-LiDAR 계열 논문이 이쪽에 속합니다. (ICLR 2020에서 Pseudo-LiDAR++도 나왔습니다.)
Pseudo-LiDAR는 정확히는 fusion을 이용한 detection 논문은 아니고, image 기반 3D object detection 논문입니다.
mono 또는 stereo image를 network에 통과시켜 depth map을 얻고, 그 depth map을 LiDAR point cloud 형태로 변형해(그냥 depth map 형태 대신, depth 값대로 3D 공간의 point로 나타낸 것이라고 보시면 됩니다.) LiDAR 기반 object detector에 넣으면 성능이 좋다는 논문입니다. image으로부터 얻은 depth map은 기본적으로 dense하기 때문에(이미지의 모든 pixel마다 depth값이 존재하니까요!) 3D 공간에 나타냈을 때, 보통의 LiDAR point cloud보다 훨씬 많은 수의 point가 존재하겠죠? 아래 그림을 참고해주세요.

후속 논문인 Pseudo-LiDAR++가 fusion 기반의 논문이라고 할 수 있는데요, image로부터 depth map을 뽑아 Pseudo-LiDAR로 표현하는 것까지 동일하고, 이를 적은 수의 진짜 LiDAR point를 이용해 Pseudo-LiDAR를 정확하게 보정한 뒤 LiDAR 기반 detector에 넣겠다는 것입니다. 여기서는 LiDAR도 이용을 한 것이므로 fusion 기반 detector로 볼 수 있겠습니다. 하지만 이 방법도 여러 LiDAR 기반 SOTA들의 성능에 미치지 못했습니다. -
detection seeding
image에서의 2D detection 결과를 seed로 이용해 3D detection을 수행하는 방법론입니다. Frustum PointNet, Frustum ConvNet, IPOD이 이 계열에 속합니다.sequential한 fusion으로 볼 수 있는데요, image를 먼저 처리하고, 그 결과를 이용한다는 점에서 PointPainting과 유사합니다. Frustum PointNet, Convnet은 image에서 2D detection을 수행하고, 2D detection 결과에 projection되는 LiDAR point에 대해서 3D region proposal을 수행합니다. 즉 2D detection 결과를 이용해 search space를 제한하는 것입니다.
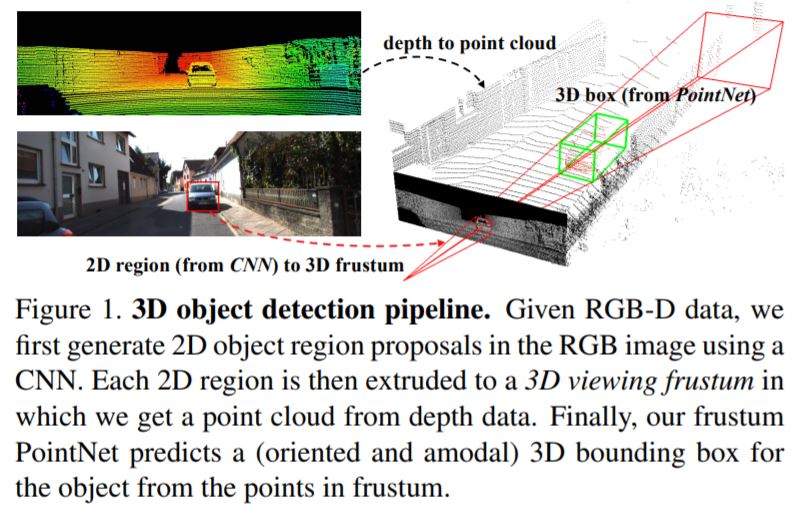
IPOD는 segmentation 결과를 이용한다는 점에서 다릅니다. PointPainting도 image 처리 결과를 이용한다는 점에서는 같지만, search space를 제한하는 것이 아닌, LiDAR에 정보를 더해주는 용도로 사용했다는 점에서 다르다고 볼 수 있겠습니다.
마지막으로 MMF를 언급하고 있는데요, 위 4가지 방법들의 요소들을 잘 합쳐보려 시도했다고 합니다. KITTI의 모든 class에 대해 결과가 공개되어 있진 않지만, 슬프게도 공개되어 있는 car class 결과마저 LiDAR-only detector인 STD에게 밀린다고 하네요.
결론적으로 기존의 fusion 연구들이 LiDAR-only detector에 못 미친다는 것입니다.
Experiments
드디어 실험파트입니다! 글이 너무 길어지네요 ㅠㅠ
이 논문은 KITTI, nuScenes 두 가지 dataset에 대해 실험을 수행했습니다. 둘 다 차량에 여러 가지 센서를 장착하고 주행을 통해 얻은 dataset이긴 하지만, 데이터 양 외에도(nuScenes가 훨씬 많습니다) data format 등에서 차이가 좀 있습니다. 논문에서 언급한 부분을 중심으로 간단히 정리하고 넘어가겠습니다.
KITTI vs Nuscenes
- point cloud format
KITTI는 , Nuscenes는 입니다. Nuscenes의 는 relative timestamp로 여러 frame의 point를 누적해서 사용하고자 할 때 활용할 수 있다고 합니다.- image와 LiDAR의 sync
KITTI에서는 image와 LiDAR가 같은 frequency로 synchronization되어 있는데, Nuscenes는 frequency가 다릅니다. 이 때문에 KITTI에서는 image와 LiDAR 사이의 transformation matrix가 하나로 간단히 표현되는 반면 nuScenes는 로 표현되는 transformation matrix를 이용해야 합니다. LiDAR와 image가 capture되는 타이밍을 보정하기 위해 두 타이밍 사이에서의 ego motion(차량의 움직임)을 이용했다고 보시면 됩니다.- Class 수
KITTI는 car, pedestrian, cyclist, background로 4개 class이고, Nuscenes는 10가지 object class에 background를 더해 11개 class를 갖습니다.- camera coverage
KITTI는 전방을 capture하는 camera들만 존재하고, nuScenes는 6개의 camera가 존재해 360도를 커버합니다.
PointPainting을 구성하기 위해서는 image semantic segmentation을 위한 네트워크와 LiDAR object detection을 위한 네트워크가 필요합니다.
KITTI에 대해서는 segmentation network로 DeepLabv3+를 사용하고, LiDAR network로는 오픈소스 코드가 존재하는 PointPillars, VoxelNet, PointRCNN을 사용하였습니다.
nuScenes에 대해서는 오픈소스 segmentation network가 없어서 nuImage로 학습시킨 custom network(Resnet backbone + FCN segmentation head)를 사용하고, LiDAR network로는 PointPilllars를 CBGS(Class Balanced Grouping and Sampling)를 참고해 개선한 PointPillars+를 사용했다고 합니다. 어떻게 개선했는지는 논문 참고부탁드립니다.
공통적으로 LiDAR object detection network는 semantic segmentation 정보를 LiDAR point에 붙였기 때문에 input 차원을 늘렸는데요, segmentation score vector는 class 수만큼의 길이를 가지므로, KITTI에서는 4만큼, nuScenes에서는 11만큼 input 차원을 늘렸습니다.
먼저 KITTI BEV detection 결과입니다.(test set의 경우, KITTI에서 논문 당 하나의 network만 제출가능해 PointRCNN 결과만 썼다고 합니다.)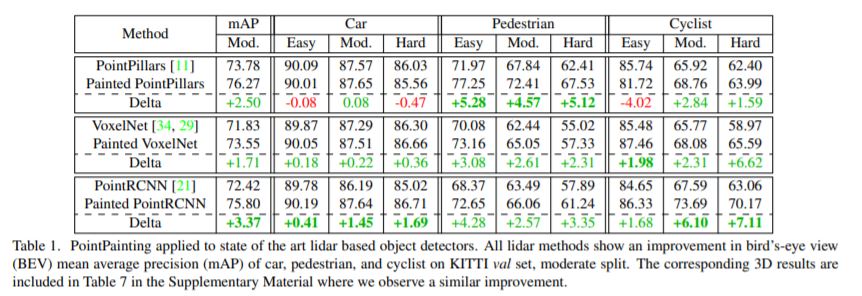
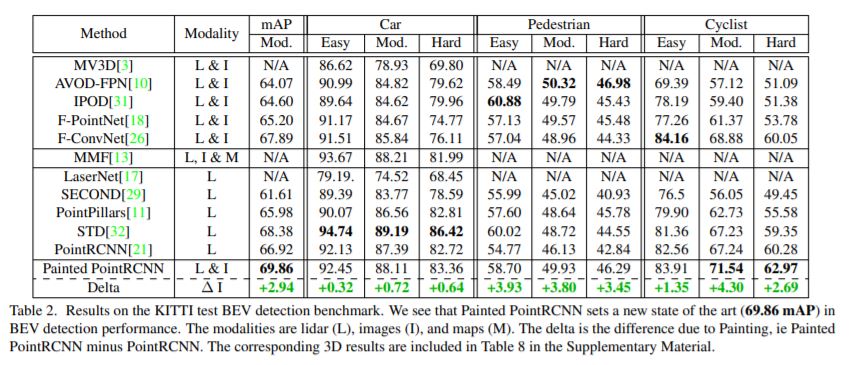 다음은 nuScenes 결과입니다.
다음은 nuScenes 결과입니다.
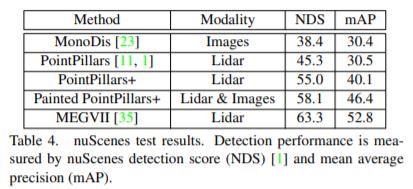 2번째 table에서 MEGVII가 더 성능이 높은 것으로 나타나는데요, 이 network는 너무 커서 realtime에 적합하지 않다고 합니다. 따라서 Painted PointPillars+가 nuScenes에 대해서 가장 성능이 좋은 realtime network라고 저자는 주장하고 있습니다.
2번째 table에서 MEGVII가 더 성능이 높은 것으로 나타나는데요, 이 network는 너무 커서 realtime에 적합하지 않다고 합니다. 따라서 Painted PointPillars+가 nuScenes에 대해서 가장 성능이 좋은 realtime network라고 저자는 주장하고 있습니다.
이 외에 Qualitative Analysis, Ablation study(segmentation quality와 segmentation format에 따른 성능 차이, pipelining에 따른 속도 및 성능 변화)를 수행을 했는데요, 너무 디테일한 부분까지 들어가는 것 같아 논문 참고를 부탁드리면서 마무리하도록 하겠습니다.
첫 포스팅이라 길이 조절도 그렇고 여러 측면에서 많이 부족한 글이 된 듯 합니다.
잘못된 부분에 관한 지적이나, 질문이 있으시면 댓글 부탁드립니다.
감사합니다.

좋은글 잘읽었습니다
혹시 서일중학교나오셨나요??