[Paper Review] LaserNet: An Efficient Probabilistic 3D Object Detector for Autonomous Driving - Part. 1
LiDAR 3D object detection

오늘 정리해볼 논문은 CVPR 2019에 나왔던 LaserNet입니다. Uber에서 나온 논문이고, 앞서 분석했던 VoxelNet, PointRCNN에 비해 인용수는 상대적으로 적은 논문이지만, 대표적인 Range Image 기반 방법론이라는 점에서 정리할 필요성이 있다고 생각하여 선정하게 되었습니다. 제목에 Probabilistic이라는 단어가 있는 것에서 유추할 수 있듯이, Uncertainty의 개념을 LiDAR object detection의 성능 향상을 위해 사용했다는 점도 주목할 만 합니다.
이번 논문은 정리하다보니 너무 길어지는 것 같아 파트 1, 2로 나누어 정리하고자 합니다.
파트 1에서는 range image의 개념과 range image에 뉴럴넷을 어떻게 적용했는지를 중심으로 살펴보고, 파트2에서는 uncertainty의 개념 소개와 함께 Probabilistic 3D object detector로서의 contribution을 중심으로 정리하고, 실험 파트를 소개하는 것으로 마무리 짓고자 합니다.
Range Image Representation
LaserNet을 이해하기 위해서는 Range Image의 개념을 알아야만 합니다. LiDAR 관련 분야를 공부하신 분들이라면 대부분 아실텐데요, LiDAR 데이터를 표현하는 방법 중 하나입니다.
쉽게 말씀 드리자면 LiDAR로 얻은 360도 공간에 대한 데이터를 파노라마 이미지처럼 나타낸 것입니다. 아래 그림은 Range Image 기반의 다른 object detection 논문(RangeRCNN)에서 가져온 LiDAR 데이터 representation 비교 그림입니다.
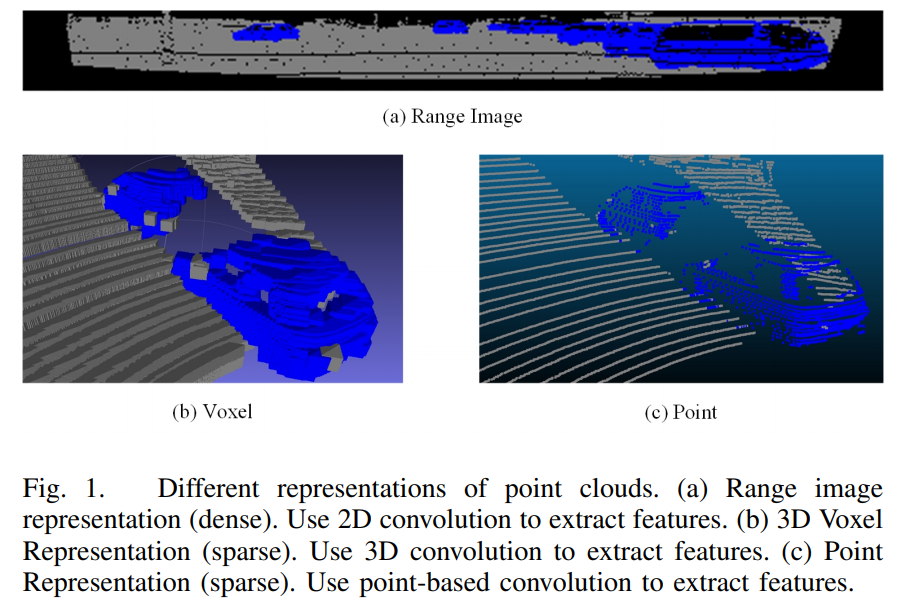
(a)가 Range Image에 해당되고, (b)가 VoxelNet 등에서 사용하고 있는 Voxel 기반 representation, (c)가 PointRCNN 등에서 사용하고 있는 point 기반 representation입니다.
KITTI 데이터셋 등과 같은 오픈 데이터셋만을 다루신 분들은 LiDAR(Velodyne 등의 rotating LiDAR)로 데이터를 얻으면 의 형태로 데이터가 나온다고 생각하실 수 있는데요, 이는 사실 LiDAR 데이터를 한 번 가공한 형태입니다. 실제로 LiDAR 데이터는 360도 데이터를 한 번에 내놓는 것이 아니라, 360도를 잘게 쪼갠 피자 조각 단위로 데이터를 얻게 됩니다. 이는 LiDAR의 동작 방식을 생각하면 매우 자연스럽습니다.
KITTI 데이터셋을 만드는 데 사용된 Velodyne 사의 HDL-64E을 예로 들면, 64개의 laser 모듈이 수직으로 쌓여있고, 이것이 360도로 회전하면서 주변을 스캔하는 방식으로 데이터를 얻게 됩니다.
그러면 각 laser module이 쏜 빔이 반사되어 돌아오는 데 걸린 시간을 통해 거리값을 알 수 있게 되겠죠?
이렇게 각 laser마다 거리값과 방향(각도)를 측정하게 되고, 하나의 피자조각에는 64개의 laser module의 ID와 그에 대응되는 거리값(range), 각도(azimuth angle), 반사강도(intensity)가 존재하게 됩니다. 이 laser module들이 360도를 돌면 우리가 아는 360도 point cloud가 완성되는 것이죠!
실제 데이터 패킷은 이보다 더 복잡합니다. 데이터 취득 방식을 자세히 알고 싶으신 분은 LiDAR 제조사의 manual을 참고하시는 걸 추천드립니다. 이 글에서는 ID가 존재하는 64개의 laser가 돌면서 거리 데이터와 반사 강도 데이터를 얻게 되고, 각 laser module이 laser를 쏘는 각도와 laser module 자체의 높이 정보 등을 함게 활용하면 point cloud의 3차원 좌표 정보를 얻을 수 있게 된다는 정도로 이해하시면 될 듯합니다.)
그러면 Range Image는 어떻게 만들까요? 먼저 Range Image는 이름대로 Image의 형태를 가집니다.
즉 grid 형태를 갖는다는 것입니다. 그러면 는 어떻게 결정될까요?
먼저 는 수직 해상도에 따라 결정될텐데, 수직 해상도는 LiDAR layer 갯수에 따라 결정됩니다.
HDL-64E, VLS-64같은 64개의 layer(laser module)을 갖는 LiDAR라면 는 64가 됩니다.
는 LiDAR의 수평 방향 resolution에 따라 결정됩니다. 이는 LiDAR의 데이터시트를 참고해야하는데요,
예를 들어 HDL-64E의 경우, 10Hz 동작 기준 0.2도(정확히는 0.1728도)이니 으로 는 1800으로 정할 수 있겠습니다.
수직으로 쌓인 64개의 laser module이 0.2도 간격으로 돌면서 laser를 쏘아 반사되어 돌아오는 값(거리값, 각도, 강도)을 저장해나가고, 그 값들을 크기의 grid에 채워나가면 Range Image가 완성이 되는 것입니다! 아래 그림은 LaserNet 논문에서 가져온 그림입니다.
가운데가 (Camera에 보이는 영역만큼만 자른) Range Image이고, 거리를 색으로 표현했습니다.
(가까울수록 파란색, 멀수록 노란색)

참고로, 논문의 실험에서는 KITTI dataset이 도의 FOV를 갖는 것을 고려, 의 크기를 갖는 Range Image를 만들었다고 합니다. 이 정확히 512는 아닌데요, 일반적인 Image의 해상도 형태로 적당히 맞춘 것으로 생각이 됩니다.
Range Image를 어떻게 만드는지 알아보았으니, Range Image가 voxel이나 point representation에 비해 갖는 장점, 단점을 알아보도록 하겠습니다.
가장 큰 장점은 dense하다는 것입니다. 3차원 공간 상에 point를 표현하면 대부분의 공간은 point없이 비어있고, 이 때문에 LiDAR object detection 논문에서는 LiDAR 데이터는 sparse하다는 말이 항상 나오게 됩니다.
하지만 Range Image는 LiDAR가 데이터를 얻는 방식을 그대로 이용, 즉 laser가 돌면서 측정한 거리값을 그대로 grid 상에 채운 것이므로 (일부 laser가 돌아오지않아 값이 없는 곳을 제외하고) 비어있는 곳이 없게 됩니다. 즉 3차원 기반 표현 방식보다 매우 효율적인 연산이 가능해지고, 자연스럽게 아주 빠른 속도를 갖게 됩니다. 그리고 2D image와 같은 형식을 갖고 있으므로, image에서 사용하는 다양한 CNN 기반 네트워크를 활용할 수 있다는 것도 큰 장점으로 볼 수 있겠습니다.
단점으로는 물체의 scale variation과 occlusion입니다. 3차원 point로 표현했을 경우, 같은 차라면 가까이 있든, 멀리 있든 같은 크기로 나타나는 데 반해, Range Image에서는 Camera Image에서와 동일하게 멀리 있는 물체가 작게 나오는 현상이 발생합니다. 이러한 scale variation은 네트워크가 물체에 대해 학습하기 어렵게 만듭니다.
또한 Range Image의 한 pixel에 대응되는 point가 2개 이상일 경우, 제일 가까운 값을 채우므로, 상대적으로 멀리 있는 가려진(occluded) point들은 처리할수 없게 되는 문제가 생긴다는 것입니다.
위와 같은 단점들 때문에 Range Image 기반의 방법론들은 voxel이나 point 기반의 방법론보다 좋은 성능을 보여주지 못했고, 이 논문에서도 그 문제에 대해 논하고 있습니다. LaserNet에서는 이 문제들을 어떻게 극복하려했는지 하나씩 살펴보도록 하겠습니다.
Proposed Method
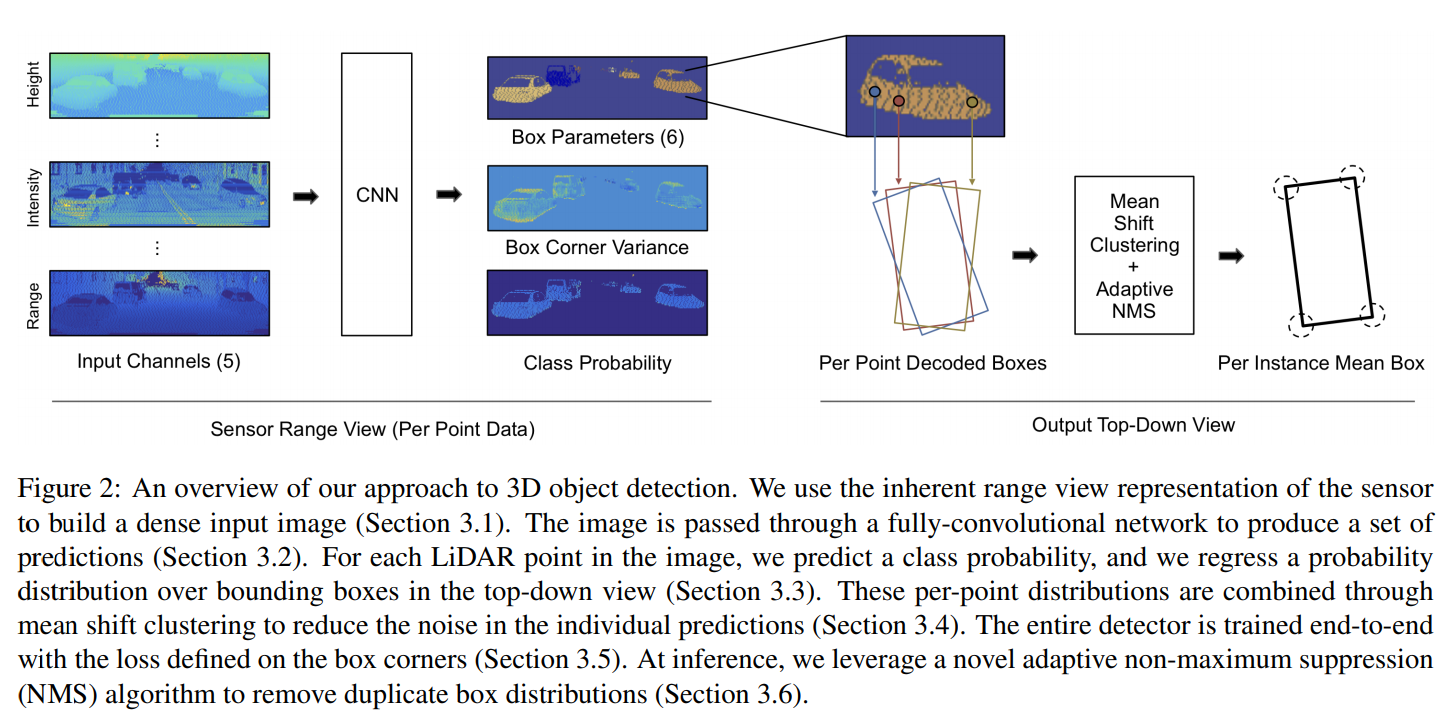
위 그림은 LaserNet에서 가져온 전체적인 네트워크 아키텍처입니다. 하나씩 정리해나가보도록 하겠습니다.
Input Representation
Range Image가 각 laser module이 회전하면서 얻은 값을 grid에 채워서 만든다고 말씀드렸는데요, 크기로 만들었고, 각 cell을 채우는 값을 Range, 즉 거리뿐만 아니라 5가지 값을 사용했습니다. 일반적인 이미지가 R, G, B 3개의 채널을 갖는 것처럼 5개의 채널을 갖는 Range Image를 만들었다고 보시면 되겠습니다.
- range
- height
- azimuth angle
- intensity
- 해당 cell에 point가 존재하는지를 나타내는 flag(point가 존재하면 1, 없으면 0과 같은 형태일 듯 합니다)
Network Architecture
Range Image의 장점을 정리할 때, 이미지 기반 CNN 네트워크를 그대로 적용할 수 있다고 말씀드렸었죠? LaserNet에서는 아래 그림와 같이 Deep Layer Aggregation이라는 논문의 아키텍처를 이용했습니다.
(해당 논문에 대한 내용은 자세히 들어가지 않도록 하겠습니다. 이 글에 정리가 잘 되어 있는 것 같으니 참고하시면 좋을 듯 합니다!)
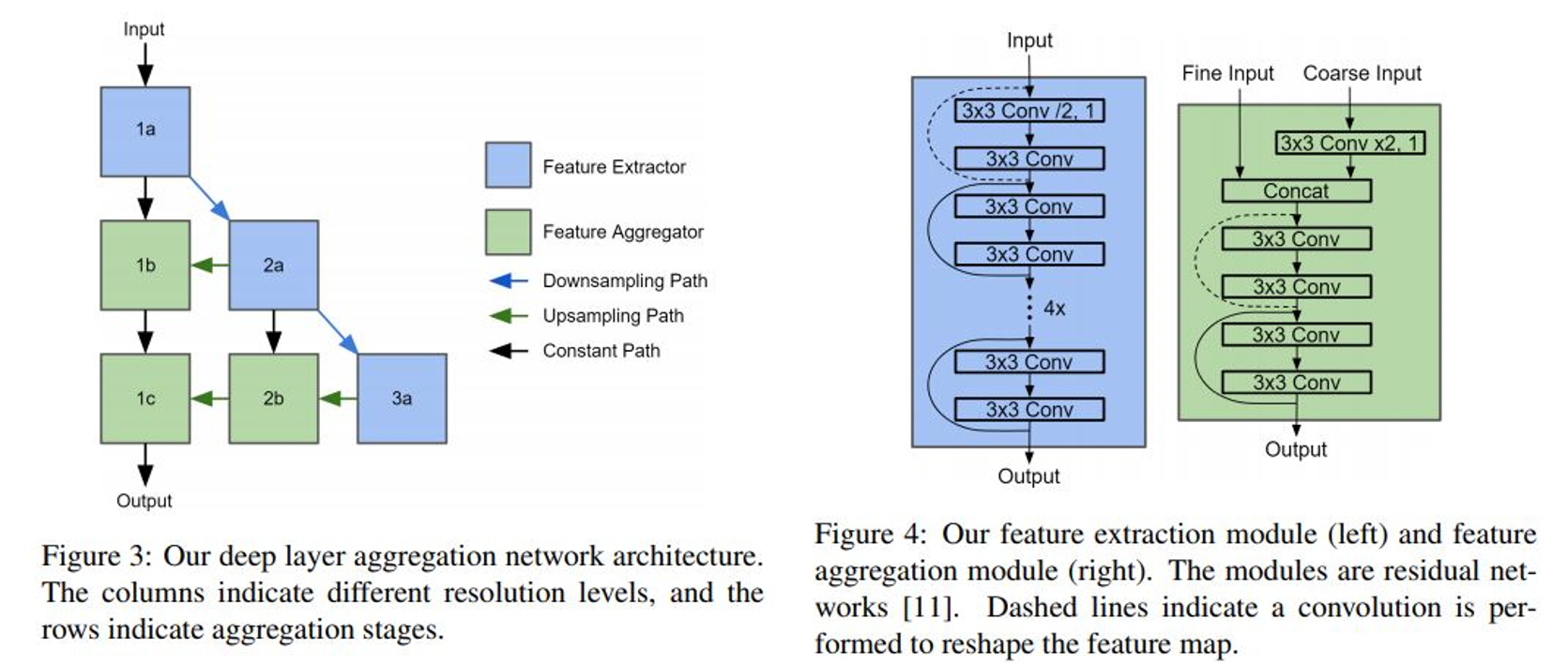
Range Image의 단점 중 하나가 Scale Variation에 따른 학습의 어려움이라고 말씀을 드렸는데요, 따라서 multi-scale feature를 잘 학습하는 것이 중요합니다. 그래서 저자들은 각 level에 feature extractor와 feature aggregator가 존재하여 multi-scale feature를 잘 통합할 수 있는 네트워크를 선택한 것으로 보입니다.
위에서 Range Image의 크기가 라고 말씀드렸는데, 가로가 세로보다 훨씬 긴 형태를 가집니다. 따라서 저자들은 네트워크를 통과하는 과정에서 세로 는 상수로 유지하고, 가로 방향(horizontal dimension)으로만 downsampling, upsampling을 수행하였다고 합니다. 그리고 마지막 convolution layer는 feature map을 bounding box에 대한 prediction map으로 바꾸어 줍니다.
Predicitons
네트워크는 각 Range Image grid의 각 point에 대해
- 각 class에 대한 확률(Car, Pedestrian, Cyclist)
- object의 bounding box 정보(각 class마다 다음 parameter들을 예측)
- relative center
- relative orientation
- dimensions of the box
을 prediciton 합니다. relative가 여기서 무슨 의미인지 이해가 어려우실텐데요, 이어서 설명하기 전에 쉬운 것부터 말씀드리면 dimension of the box가 높이 없이 만 있는 이유는, bounding box들이 전부 수평인 지면(ground plane)에 있다는 가정을 사용, 는 상수로 고정하고 만 예측하여 3D bounding box를 만들기 위함입니다.
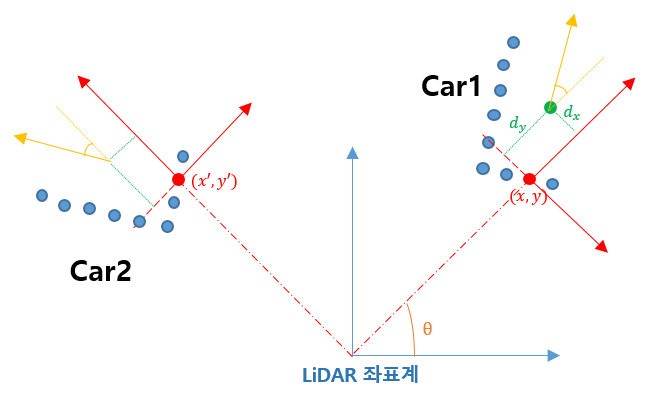
이제 relative에 대한 설명을 이어가도록 하겠습니다. 이는 rotational invariance와 아주 밀접한 관련이 있습니다. 논문에는 강조되어 있지 않은 부분인데요, 개인적으로 중요한 부분이라 생각해서 설명을 하고 넘어가도록 하겠습니다. relative center, relative orientation을 예측한다는 것은 global 좌표계(LiDAR 기준 좌표계)에서의 center 좌표, orientation 각도를 예측하는 것이 아니라, LiDAR 원점과 해당 point를 연결한 축이 축인 좌표계에서의 center 좌표, orientation 각도를 예측한다는 것입니다. 글로 읽으면 헷갈리실 수 있는데요, 그림을 그려 설명드리겠습니다!
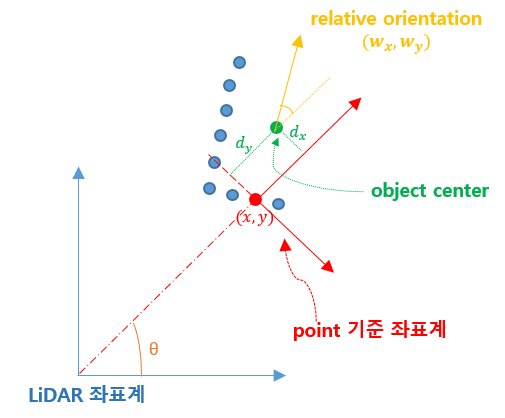
그림 퀄리티는 양해부탁드립니다 ㅎㅎ LiDAR 좌표계는 LiDAR의 위치가 원점인 좌표축이구요, 파란색점들이 자동차에 맞은 LiDAR point들이라고 생각하시면 됩니다. 그중 빨간색으로 표시된 점에 대해서 bounding box prediction을 수행한다고 해봅시다.
relative center 는 초록색으로 표시된 것처럼, LiDAR 원점과 point를 연결한 축이 축인 좌표계에서의 자동차 center 좌표가 됩니다.
relative orientation 는 LiDAR 원점과 point를 연결한 축, 즉 point 좌표계의 y축에 대한 자동차의 orientation을 나타내게 됩니다.
그리고 네트워크가 예측한 relative center 와 relative orientation 는 다음과 같은 수식을 통해 global center, orientation으로 변환이 이루어지게 됩니다.
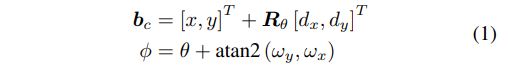
논문에 언급되어 있지 않으나 개인적으로 중요한 부분이라 생각하는 부분을 부연 설명하고자 합니다. relative center, orientation을 예측했을 때, 바로 global center, orientation을 예측하는 것에 비해 어떤 장점이 있을까요? 네트워크의 rotational invariance를 이용할 수 있게 되기 때문임을 유추할 수 있습니다.
이미지를 CNN에 통과시켰을 때, 같은 패턴의 pixel이 이미지 내에서 다른 위치로 translation되더라도 같은 feature를 얻는 것을 CNN의 translation invariance라고 이야기하는 것은 알고 계실 듯 합니다. 아래 그림처럼 LiDAR를 중심축으로 물체가 회전(rotation)했다고 생각해보세요.
Car1, Car2를 비교해보시면 LiDAR point 패턴은 완전히 동일하게 됩니다. 따라서 relative center, relative orientation도 변하지 않습니다. 하지만 global center, orientation은 다르게 되죠. 위와 같은 LiDAR를 중심축으로 한 물체의 rotation은, range image에서 translation으로 나타나게 됩니다. 그리고 range image가 통과할 CNN은 translation invariance를 성질로 갖습니다. 즉, 이는 CNN의 translation invaricance가 LiDAR point의 관점에서는 rotation invariance로 작용한다는 것입니다. 즉, 물체가 LiDAR를 중심축으로 회전하더라도 range image 상에서 같은 feature로 나타날 것이고, 최종적인 prediction도 동일하게 나오는 것이 자연스럽습니다. 이렇게 되려면 네트워크의 prediction이 반드시 relative해야함을 알 수 있습니다. 그리고 이러한 rotational invariance를 이용할 수 있다는 점이 range image를 이용하는 것의 가장 큰 장점이라고 생각합니다.
조금 생각해보시면 voxel이나 point 기반의 방법론에서는 이를 전혀 활용하지 못하고 있음을 아실 수 있습니다.
그리고 다음과 같은 수식을 통해 bounding box의 4개의 corner 좌표를 얻게 됩니다.
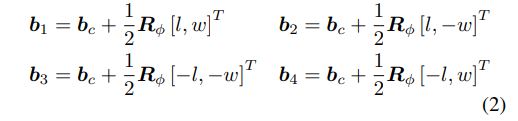
그런데 사실 LaserNet은 위의 bounding box 정보들의 값을 직접적으로 예측하는 것이 아니라, bounding box 정보들의 분포를 예측합니다. 좀 더 구체적으로는 Gaussian mixture model(GMM)을 가정하고, GMM의 parameter(mean, variance, weights)를 예측하게 됩니다. 이 때문에 논문의 제목에 Probabilistic 3D object detector라는 말이 들어가 있는 것이구요! Part1은 여기서 마무리하고, Part2에서 이 부분에 대한 설명으로 이어가도록 하겠습니다.
읽어주셔서 감사드리고, 지적이나 질문은 언제나 환영입니다. 감사합니다!

삭제된 댓글입니다.