📌11주차 학습내용 요약
1. 인공지능
-
인간의 지능을 모방한 인공적인 지능
-
인간의 학습능력과 추론능력, 지각능력, 자연어의 이해능력 등을 컴퓨터 프로그램으로 실현한 기술

머신러닝
-
명시적으로 프로그래밍하지 않고도 컴퓨터에 학습할 수 있는 능력을 부여하는 것
-
컴퓨터가 데이터를 분석하고 스스로 학습하는 과정을 통해 인공적인 지능을 갖도록 하는 학습방법
딥러닝
- 인공신경망(Artificial Neural Network, ANN)를 여러개 사용하는 머신러닝의 학습방법
머신러닝과 딥러닝
- 원래 딥러닝은 머신러닝에 포함되는 관계이지만, 현업에서도 분리되어 뜻하기도 함

2. DecisionTree
- 직관적인 분류방식(True or False)
- 단순하고 효과적인 방식
- 앙상블 계열의 기초
1) Decision Tree의 분할 기준
- 엔트로피
- 지니계수
- 두 기준은 낮을수록 좋음
엔트로피(entropy)
-
열역학의 용어로 물질의 열적 상태를 나타내는 물리량
-
무질서도, 불확실성을 의미함
-
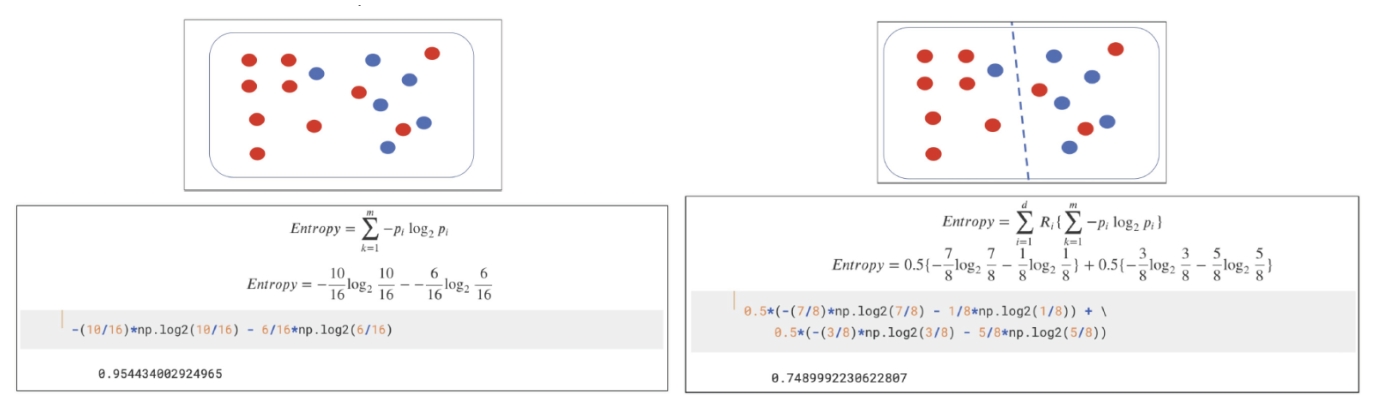
지니 계수(Gini index)
-
불순도율을 의미함
-
엔트로피와 동일하게 수치가 낮을수록 좋은 결과를 얻음
-
log를 사용하는 엔트로피와 다르게 지니계수는 단순 산술이므로 처리부하가 적음
-

2) DecionsTree 학습과 평가
학습
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier()
feature = iris.data[:, 2:] # 학습데이터(petal만 사용)
target = iris.target # 정답 데이터
iris_tree.fit(feature, target)
결과 확인
# 학습 결과 확인
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(feature)
accuracy_score(iris.target, y_pred_tr)
---------------------------------------
0.9933333333333333DecionsTree 시각화
from sklearn.tree import plot_tree
plt.figure(figsize=(10,10))
plot_tree(iris_tree, filled=True)
plt.show()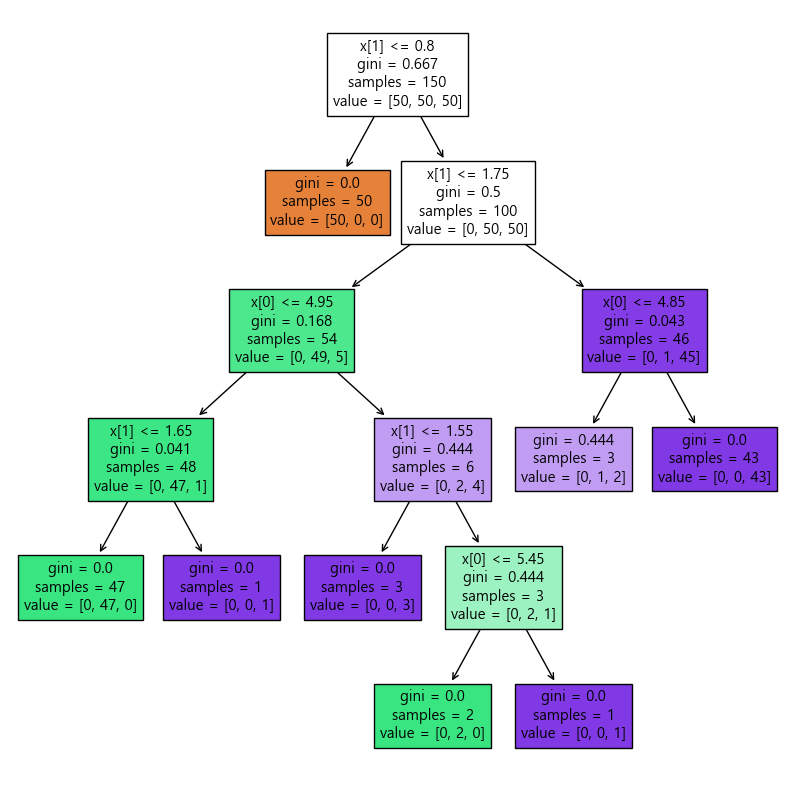
3) 과적합(Overfitting)
- 학습데이터에 과도하게 적합하게 되어 다른 데이터의 정답률(예측)이 감소하는 것
결정 경계
from mlxtend.plotting import plot_decision_regions
import matplotlib
matplotlib.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(14,8))
plot_decision_regions(X=feature, y=target, clf=iris_tree, legend=2)
plt.title('결정 경계')
plt.show()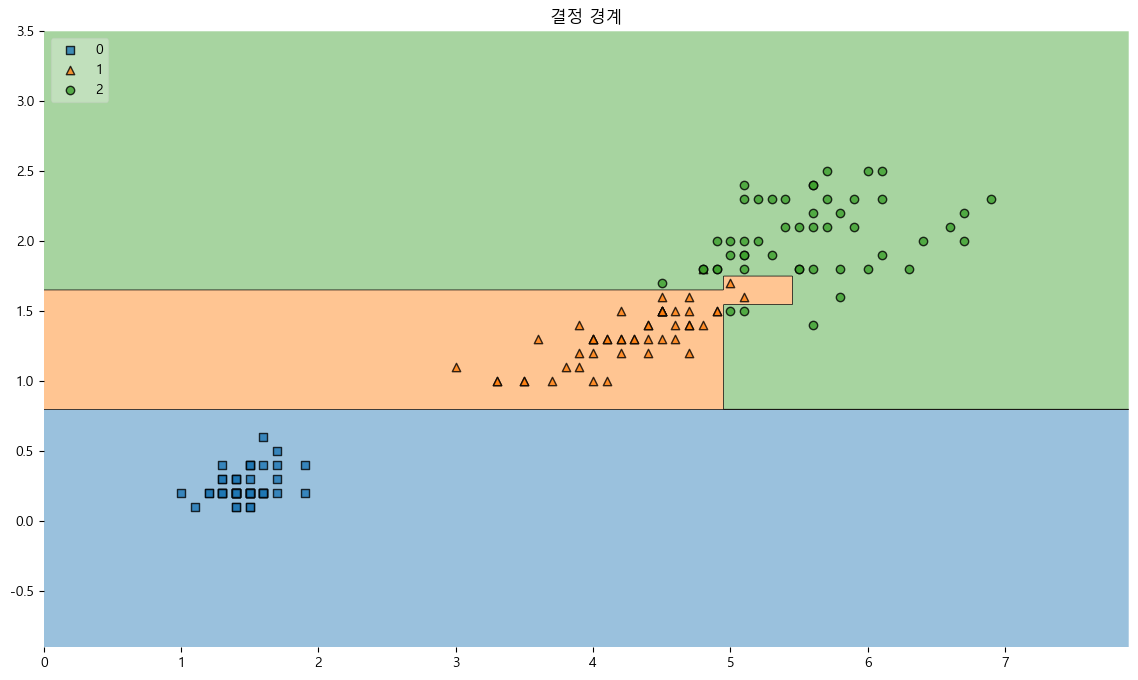
-
1,2번 사이의 경계선이 복잡하고, 위에서 정확도를 구했을 때, 99%가 나왔는데 이것은 과적합된 것이다.
-
주어진 학습데이터 150개에 대해서만 결과가 다음과 같이 나온 것이지, 이것이 모든 iris를 대표한다고 할 수 없기 때문이다.
->성급한 일반화의 오류 가능성 -
복잡한 경계면은 모델의 성능을 결국 나쁘게 만든다.
-
경계면에 복잡한 부근에 있는 데이터들이 이상치일 가능성은 없는것인가? 신뢰할 수 있는가?
-
일반적인 데이터를 기준으로 모델의 성능을 향상시키려면 어느 정도의 오류는 감수해야 한다.
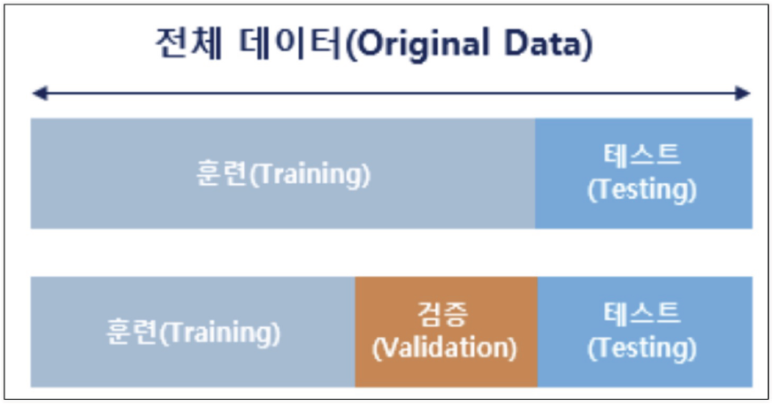
4) 데이터분리
- 데이터를 학습데이터와 검증데이터, 라벨데이터로 분류
- 검증데이터를 따로 준비하여 과적합 최소화
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import pandas as pd
iris = load_iris()
features = iris.data[:, 2:]
labels = iris.target
# 데이터분리
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, stratify=labels, random_state=13)
# 분리 형태 확인
X_train.shape, X_test.shape
-----------------------------------------------------------------------------------------------------
((120, 2), (30, 2))train_test_split() 함수
- 1,2번째 요소 : 특성데이터와 정답데이터
- test_size : test 데이터 크기
- shuffle : 데이터 분할전 섞기
- stratify : 분류데이터 비율 동등
- random_state : 랜덤시드
stratify 적용예시
- 분할된 데이터의 갯수를 같은 비율로 설정함
import numpy as np
np.unique(y_test, return_counts=True)
----------------------------------------------------
(array([0, 1, 2]), array([10, 10, 10], dtype=int64))shuffle 추가설명
- 고정된 훈련데이터와 평가데이터를 사용하지 않고 셔플하는 기능
5) 학습과 평가
DecisionTree 시각화
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)
plt.figure(figsize=(7,7))
plot_tree(iris_tree, filled=True)
plt.show()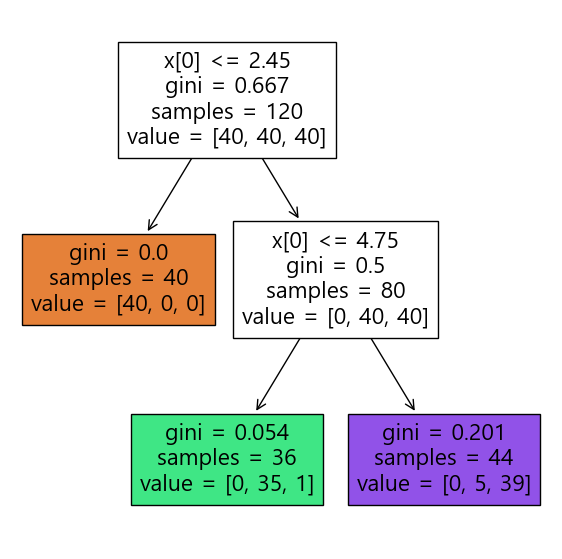
DecisionTreeClassifier() 함수
- criterion : 기준(gini, entropy)
- max_depth : 깊이 설정
- min_samples_split : 노드를 분할하는데 필요한 최소 샘플 수
- min_samples_leaf : 노드에 있어야 하는 최소 샘플 수
- max_features : 최상의 분할을 찾을 때 고려할 최대 기능 수
- random_state : 랜덤시드
- class_weight : 가중치 설정
max_features 추가설명
- 데이터 세트 10개이고 max_features=5인 경우, 의사결정트리를 구성할 때 각 노드에서 임의로 선정한 5개의 데이터 세트를 활용함
평가
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(X_train)
accuracy_score(y_train, y_pred_tr)
-------------------------------------------
0.956) 예측
정답 예측
# 예측하기
test_data = [[4.3, 2., 1.2, 1.]]
iris_tree.predict(test_data)
----------------------------------
array([1])iris.target_names[iris_tree.predict(test_data)]
-----------------------------------------------
array(['versicolor'], dtype='<U10')7) LabelEncoder
-
문자를 숫자로, 숫자를 문자로 변환
-
머신러닝에 적용하기 위해서는 문자를 숫자로 변환 필요
-
학습이 끝난 후 얻은 결과를 숫자로 변환해서 확인 가능
문자->숫자
df['le_A'] = le.transform(df['A'])
df
-------------------------------------------------
A B le_A
0 a 1 0
1 b 2 1
2 c 3 2
3 a 1 0
4 b 0 1한번에 fit과 변환
le.fit_transform(df['A'])
--------------------------
array([0, 1, 2, 0, 1])숫자->문자
le.inverse_transform(df['le_A'])
---------------------------------
array(['a', 'b', 'c', 'a', 'b'], dtype=object)3. Scaling
MinMaxScaler
- 0 ~ 1로 스케일 조정
- 이상치의 영향이 큼
StandardScaler
- 기본스케일. 평균과 표준편차로 스케일링
- 이상치의 영향이 큼
RobustScaler
- 중간값과 사분위수 사용
- 이상치 영향 최소화
# 3개의 모델을 선언
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
mm = MinMaxScaler()
ss = StandardScaler()
rs = RobustScaler()
# 하나의 데이터프레임에 저장
df_scaler = df.copy()
df_scaler['MinMax'] = mm.fit_transform(df)
df_scaler['Standard'] = ss.fit_transform(df)
df_scaler['Robust'] = rs.fit_transform(df)
df_scaler
--------------------------------------
A MinMax Standard Robust
0 -0.1 0.000000 -0.656688 -0.444444
1 0.0 0.019608 -0.590281 -0.333333
2 0.1 0.039216 -0.523875 -0.222222
3 0.2 0.058824 -0.457468 -0.111111
4 0.3 0.078431 -0.391061 0.000000
5 0.4 0.098039 -0.324655 0.111111
6 1.0 0.215686 0.073785 0.777778
7 1.1 0.235294 0.140192 0.888889
8 5.0 1.000000 2.730051 5.222222스케일링 시각화
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
plt.figure(figsize=(16,6))
sns.boxplot(data=df_scaler, orient="h")
plt.show()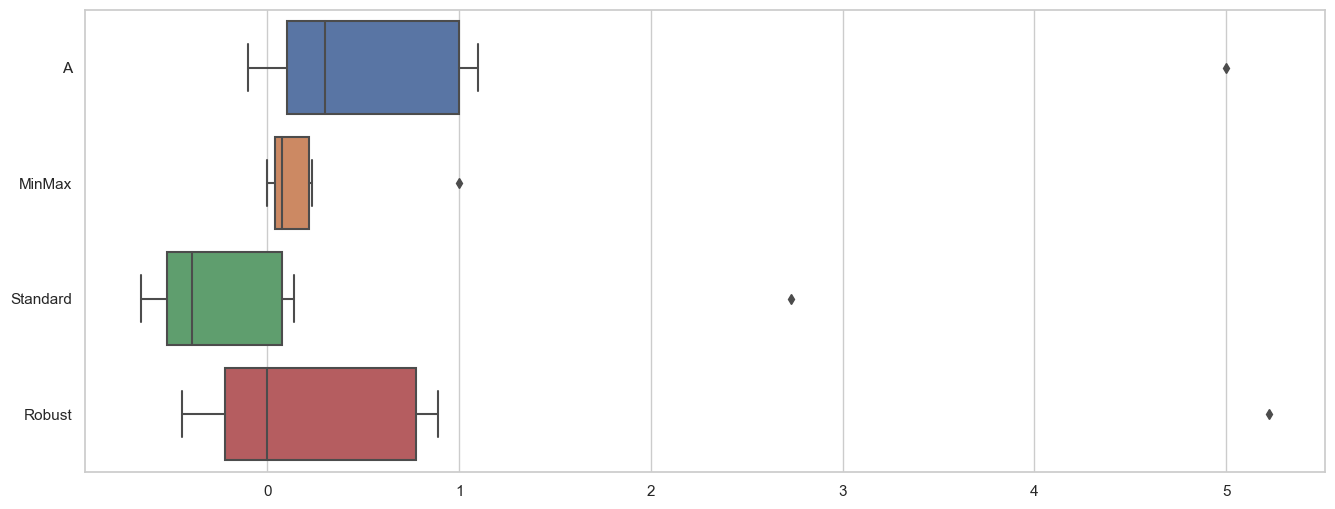
4. PipeLine
- 매번 같은 작업을 반복 수행해야 할 때, 오류가 발생할 수 있다.
- 파이프라인으로 처음 선언해두면 계속해서 사용가능하다.
와인 데이터 가져오기
import pandas as pd
red_url = 'https://raw.githubusercontent.com/Pinkwink/ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/Pinkwink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color']=1.
white_wine['color']=0.
wine = pd.concat([red_wine, white_wine])
X = wine.drop(['color'], axis=1)
y = wine['color']파이프라인 구성
# 파이프라인 구성
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())
]
pipe = Pipeline(estimators)
pipe.steps
-----------------------------------------------------------------
[('scaler', StandardScaler()), ('clf', DecisionTreeClassifier())]내부 모델 속성 설정
pipe.set_params(clf__max_depth=2)
pipe.set_params(clf__random_state=13)
모델학습과 평가
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13, stratify=y)
pipe.fit(X_train, y_train)
y_pred_tr = pipe.predict(X_train)
y_pred_test = pipe.predict(X_test)
print('Train Acc : ', accuracy_score(y_train, y_pred_tr))
print('Test Acc : ', accuracy_score(y_test, y_pred_test))
---------------------------------------------------------
Train Acc : 0.9657494708485664
Test Acc : 0.95769230769230775. 하이퍼파라미터
- 학습 과정을 제어하는 사용되는 파라미터
1) K-Fold 교차검증
- 과적합을 피하기 위한 교차검증
- 검증데이터를 바꿔가면서 분할 횟수만큼 검증
- 데이터가 편향되어 있는 경우, 학습데이터에 타겟이 포함되지 않을 수 있음
- 학습용데이터를 K개로 분할하여 학습하는 것
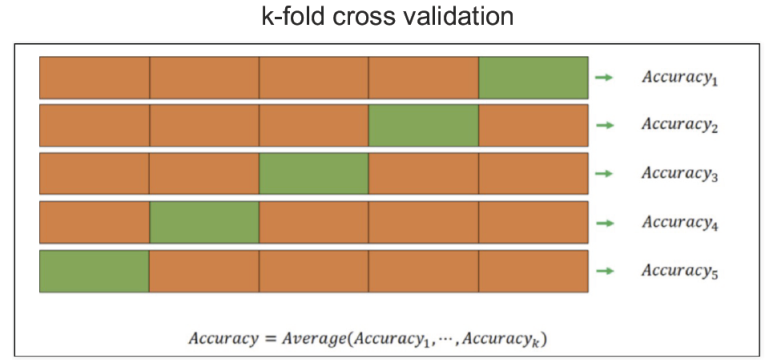
from sklearn.model_selection import KFold
from sklearn.tree import DecisionTreeClassifier
kfold = KFold(n_splits=5) # 분할 갯수 K 결정
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)2) Stratified K-Fold 교차검증
- 각 폴드의 비율을 동일하게 분리한다

# StratifiedKFold
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5) # 분할 갯수 K 결정
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cross_val_score(wine_tree_cv, X, y, scoring=None, cv=skfold)
--------------------------------------------------------------------
array([0.55230769, 0.68846154, 0.71439569, 0.73210162, 0.75673595])3) GridSearchCV
-
하이퍼파라미터의 최적의 값을 도출
-
설정해놓은 값들을 반복해서 넣고 그 결과를 비교하는 방식을 사용하므로 시간이 오래걸린다.
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth' : [2,4,7,10]}
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
gridsearch = GridSearchCV(estimator=wine_tree, param_grid=params, cv=5, n_jobs=7) # cv는 분할갯수
gridsearch.fit(X,y)수행내용 출력
import pprint
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(gridsearch.cv_results_)
---------------------------------------------------------------------------------
{ 'mean_fit_time': array([0.01557207, 0.02707362, 0.03694801, 0.0396534 ]),
'mean_score_time': array([0.00433187, 0.00419917, 0.00400963, 0.00239401]),
'mean_test_score': array([0.6888005 , 0.66356523, 0.65340854, 0.64401587]),
'param_max_depth': masked_array(data=[2, 4, 7, 10],
mask=[False, False, False, False],
fill_value='?',
dtype=object),
'params': [ {'max_depth': 2},
{'max_depth': 4},
{'max_depth': 7},
{'max_depth': 10}],
'rank_test_score': array([1, 2, 3, 4]),
'split0_test_score': array([0.55230769, 0.51230769, 0.50846154, 0.51615385]),
'split1_test_score': array([0.68846154, 0.63153846, 0.60307692, 0.60076923]),
'split2_test_score': array([0.71439569, 0.72363356, 0.68360277, 0.66743649]),
'split3_test_score': array([0.73210162, 0.73210162, 0.73672055, 0.71054657]),
'split4_test_score': array([0.75673595, 0.7182448 , 0.73518091, 0.72517321]),
'std_fit_time': array([0.002706 , 0.00254519, 0.00184818, 0.00089921]),
'std_score_time': array([0.00041986, 0.00115462, 0.00166992, 0.00048907]),
'std_test_score': array([0.07179934, 0.08390453, 0.08727223, 0.07717557])}PipeLine에 GridSearch 사용
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())
]
pipe = Pipeline(estimators)
param_grid = [{'clf__max_depth':[2,4,7,10]}]
GridSearch = GridSearchCV(estimator=pipe, param_grid=param_grid, cv=5)
GridSearch.fit(X,y)
GridSearch.cv_results_
----------------------------------------------------------------------------
{'mean_fit_time': array([0.01302018, 0.01525412, 0.02469058, 0.03136926]),
'std_fit_time': array([0.00222836, 0.00111415, 0.00097366, 0.00195921]),
'mean_score_time': array([0.00239077, 0.00220132, 0.00239601, 0.00274467]),
'std_score_time': array([0.00049056, 0.00041199, 0.00049911, 0.00037043]),
'param_clf__max_depth': masked_array(data=[2, 4, 7, 10],
mask=[False, False, False, False],
fill_value='?',
dtype=object),
'params': [{'clf__max_depth': 2},
{'clf__max_depth': 4},
{'clf__max_depth': 7},
{'clf__max_depth': 10}],
'split0_test_score': array([0.55230769, 0.51230769, 0.50769231, 0.51692308]),
'split1_test_score': array([0.68846154, 0.63153846, 0.60461538, 0.61153846]),
'split2_test_score': array([0.71439569, 0.72363356, 0.67667436, 0.67205543]),
'split3_test_score': array([0.73210162, 0.73210162, 0.73672055, 0.71439569]),
'split4_test_score': array([0.75673595, 0.7182448 , 0.73518091, 0.72286374]),
'mean_test_score': array([0.6888005 , 0.66356523, 0.6521767 , 0.64755528]),
'std_test_score': array([0.07179934, 0.08390453, 0.08691987, 0.07629056]),
'rank_test_score': array([1, 2, 3, 4])}표로 정리
import pandas as pd
score_df = pd.DataFrame(GridSearch.cv_results_)
score_df[['params', 'rank_test_score', 'mean_test_score', 'std_test_score']]
-----------------------------------------------------------------------------
params rank_test_score mean_test_score std_test_score
0 {'clf__max_depth': 2} 1 0.688800 0.071799
1 {'clf__max_depth': 4} 2 0.663565 0.083905
2 {'clf__max_depth': 7} 3 0.652177 0.086920
3 {'clf__max_depth': 10} 4 0.647555 0.0762916. 모델평가
평가항목


Accuracy
- 전체 데이터 중 맞게 예측한 것의 비율
Precision
- 양성이라고 예측한 것 중에서 실제 양성의 비율
Recall(TPR)
- 참인 데이터 중에서 참이라고 예측한 것
Fall-Out(FPR)
- 양성이 아닌데, 양성이라고 잘못 예측한 경우
F1-Score
- Recall과 Precision을 결합한 지표
- 높을수록 좋음
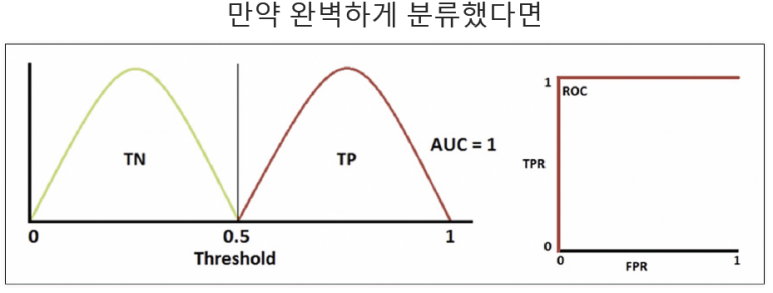
ROC와 AUC
-
ROC(Receiver Operating Characteristic) Curve: FPR과 TPR의 곡선
-
AUC(Area Under the ROC Curve) : ROC 곡선 아래 영역
7. 회귀
OLS(최소자승법)
- 잔차를 제곱하여 최적의 파라미터를 찾는 방법
비용함수(Cost Function)
- 원래의 값과 가장 오차가 작은 최적의 가중치를 도출하는 함수
선형회귀
- OLS를 통해 최적의 회귀선을 찾는 방법

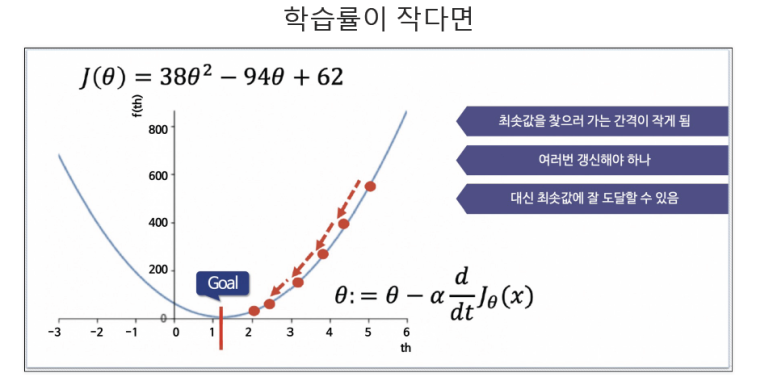
경사하강법
- 손실함수를 최소화하는 방법
- 선 위의 임의의 점에서 미분값을 계산해서 x축으로 내린 후 여기서 직각 위치에 해당하는 선 위로 이동한다
- 이 과정을 반복하여 목표에 도달하는 방법