📌EDA 과제1_스타벅스&이디야 매장 분석
개요
- 과거에 이디야는 스타벅스 인근에 점포를 내는 것이 아니냐는 의심을 받은 경험이 있다. 해당 기사는 구글링하면 쉽게 찾을 수 있다. 국내의 1,2위를 다투는 스타벅스와 이디야의 위치를 분석해보고 사실인지 검증해보자.
데이터 출처 : 스타벅스, 이디야
목표
- 이디야가 스타벅스 옆자리 전략을 펼친 것이 사실인지 확인하기
제한사항
- 서울시를 대상으로 한다
- 위치데이터 이외의 데이터는 분석에 활용하지 않는다
(ex. 명성, 매출, 세부 지리적 위치(핫플레이스 인근 등))
절차
- 스타벅스 데이터 수집
- 이디야 데이터 수집
- 데이터 변환
- 데이터 시각화
- 분석
1. 스타벅스 데이터 수집
- 지역검색으로 데이터 수집가능
- 상호, 주소, 구, 위도, 경도 수집
- Selenium으로 데이터 수집을 하려면 각 구를 클릭하여야 한다.
문제 : 스크롤을 내리지 않으면 클릭 수행 불가능
해결 : ActionChains를 활용하여 스크롤을 내린 후 클릭
- 구를 클릭 후 BeautifulSoup으로 원하는 데이터 수집
- 위도, 경도의 데이터형 object -> float 변경
- 상호, 주소, 구, 위도, 경도가 포함된 스타벅스 데이터프레임 생성
2. 이디야 데이터 수집
- 주소 검색으로 데이터 수집가능
- 상호, 주소, 구 수집
- 위도, 경도 데이터가 존재하나 일부 입력되어 있지 않음 -> 전체적으로 googlemaps 활용
- 중복된 구 이름이 존재하므로 "서울 "을 포함하여 검색
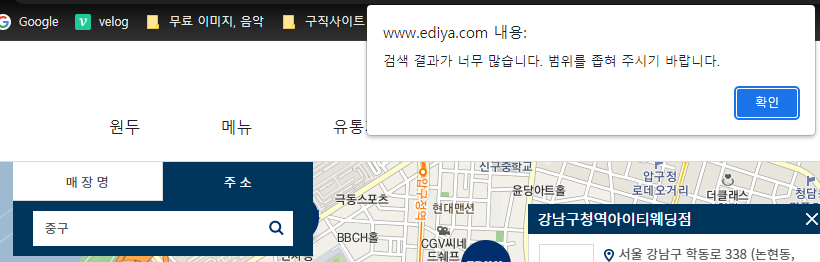
- 구 데이터 오류 발생
- 문제원인 : 소수의 주소 앞부분에 공백 존재
- 해결 : 구 데이터 재지정
txt1 = '서울 강서구 강서로 51'
txt2 = ' 서울 강서구 강서로 51'
print('정상 : ', end='')
print(txt1.split(' '))
print('오류 : ', end='')
print(txt2.split(' '))

3. 데이터 변환
df_starbucks['브랜드'] = '스타벅스'
df_ediya['브랜드'] = '이디야'
df_cafe = pd.concat([df_starbucks, df_ediya])
df_cafe.reset_index(drop=True, inplace=True)
df_cafe

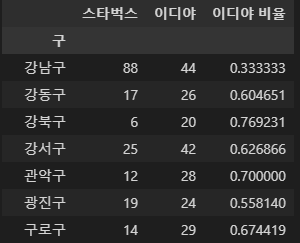
- 구를 기준으로 브랜드별 매장 수와 비율로 구조변경
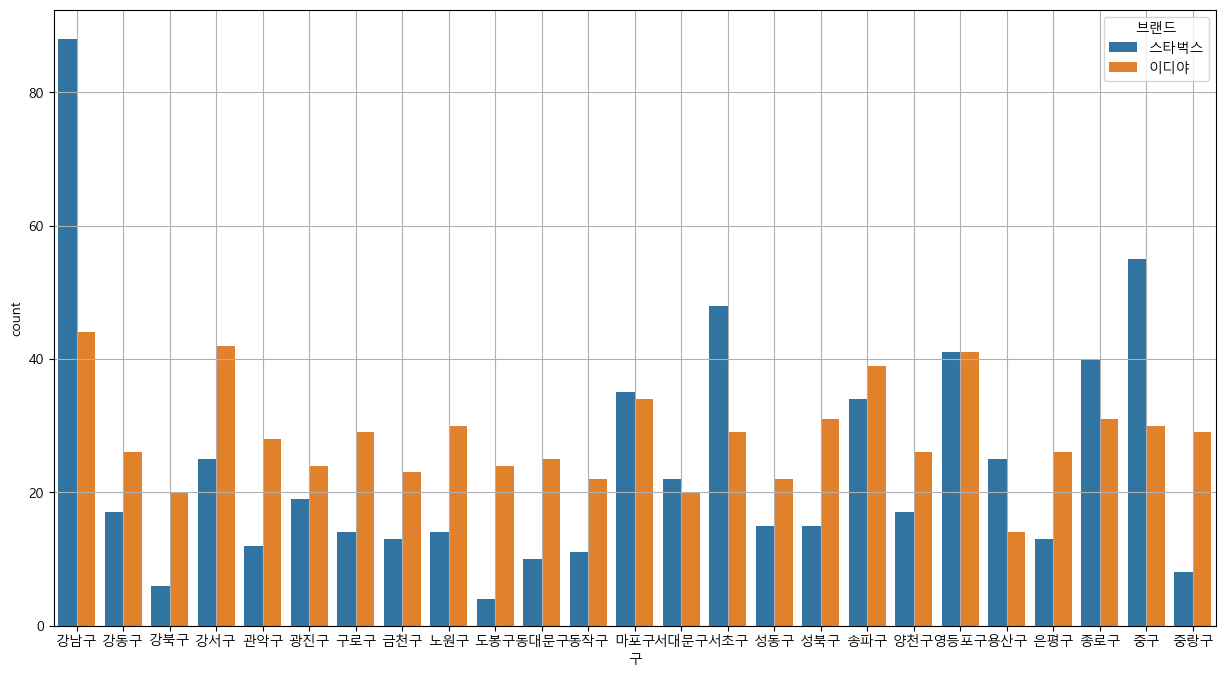
4. 데이터시각화
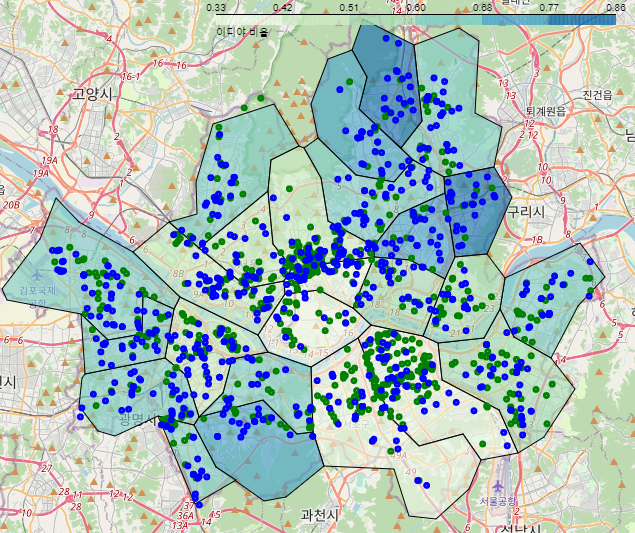
- 파란색 : 이디야
- 초록색 : 스타벅스
5. 분석
- 매장갯수 : 이디야 709개, 스타벅스 599개 (이디야가 100개를 더 소유 중)
- 분포방식 : 이디야-넓게 분포, 스타벅스-집중적으로 분포
- 스타벅스 우세지역 : 강남구, 마포구, 서초구, 종로구, 중구
- 매장끼리 겹치는 구간이 종종 있지만, 스타벅스를 따라서 점포를 냈다고 볼 수 없다.
- 따라서 이디야가 스타벅스 매장 근처에 점포를 낸다는 가설은 옳지 않다
📌7주차 학습내용 요약
Python with MySQL
접속코드
import mysql.connector
mydb = mysql.connector.connect(
host = "<host>",
port = "<port>",
user = "<user>",
password = "<password>",
database = "<database>"
)
mydb.close()
커서 생성 및 사용
cur = remote.cursor(buffered=True)
cur.execute("<query>")
SQL 파일 읽고 실행하기
sql = open('<filename>.sql').read()
cur.execute(sql, multi=True)
데이터 확인
cur.execute("select * from sql_file")
result = cur.fetchall()
for result_iterator in result:
print(result_iterator)
CSV 읽고 insert 하기
df = pd.read_csv("<filename>.csv")
sql = 'insert into TABLENAME values (%s, %s)'
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit()
Aggregate Functions
| Function | Description |
|---|
| COUNT | 총 갯수 계산 |
| SUM | 합계 계산 |
| AVG | 평균 계산 |
| MIN | 최소 값 찾기 |
| MAX | 최대 값 찾기 |
| FIRST | 첫번째 결과 리턴 |
| LAST | 마지막 결과 리턴 |
Scalar Functions
| Function | Description |
|---|
| UCASE | 영문->대문자 |
| LCASE | 영문->소문자 |
| MID | 문자열 부분 반환 |
| LENGTH | 문자열 길이 반환 |
| ROUND | 반올림 |
| NOW | 현재 날짜 및 시간 |
| FORMAT | 천단위 콤마 표기 |
Subquery
- 하나의 SQL 문안에 포함되어 있는 또 다른 SQL문
- Subquery는 괄호로 묶어서 사용, order by 사용불가
- 메인쿼리가 서브쿼리를 포함하는 종속적인 관계
- Scalar Subquery - SELECT절 사용
- Inline Subquery - FROM절 사용
- Nested Subquery - WHERE절 사용
Scalar Subquery
- SELECT 절에서 사용하는 서브쿼리
- 결과는 하나의 칼럼
SELECT column1, (SELECT column2 FROM table2 WHERE condition)
FROM table1
WHERE condition;
Inline Subquery
- FROM 절에 사용하는 서브쿼리
- 메인쿼리에서는 인라인 뷰에서 조회한 칼럼만 사용가능
SELECT a.column, b.column
FROM table1 a, (SELECT column1, column2 FROM table2) b
WHERE condition;
Nested Subquery
SELECT columns
FROM tablename a
WHERE (a.column1, a.column2, ...)
IN (SELECT b.column1, b.column2, ...
FROM tablename b
WHERE a.column = b.column)
ORDER BY columns;
📌학습범위
- Part 05. SQL
- Python with MySQL
- Aggregate & Scalar Functions, Subquery