인덱스
-
Index는 데이터베이스에서 table의 검색 속도를 향상 시켜주는 대표적인 방법중 하나이며,
책의 색인(index)과 같은 역할을 하는 B+Tree 형태의 자료구조입니다.
-
이점
- SELECT ~ WHERE query를 통해 특정 조건을 만족하는 데이터를 찾을 때, full table scan할 필요 없이 정렬되어 있는 index에서 훨씬 빠른 속도로 검색을 할 수 있게 됩니다.
Full Table Scan
특정 조건을 만족하는 데이터를 찾고자 WHERE절을 사용한다면 Table의 row(record)를 처음부터 끝까지 모두 접근하여 검색조건과 일치하는지 비교하는 과정
- 구조
- index는 특정 column을 search-key 값으로 설정하여 index를 생성하면, 해당 search-key 값을 기준으로 정렬하여 데이터의 물리적 위치를 저장한 pointer와 함께 별도 파일에 저장합니다.
- Index는 순서대로 정렬된 search-key값과 pointer값만 저장하기 때문에 table보다 적은 공간을 차지
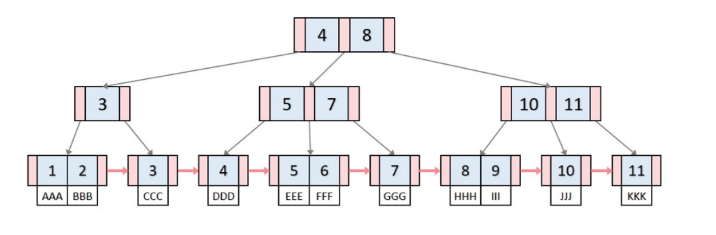
B -트리
- 인덱스는 보통 B-트리 라는 자료구조로 이루어져 있다.
- 루트노드 , 브랜치 노드, 리프노드로 구성
- 트리 탐색은 맨 위 루트 노드부터 탐색이 이러나며 브랜치 노드를 거쳐 리프 노드까지 내려온다.
- 균형잡힌 트리구조와 트리 깊이의 대수 확장성 덕분에 효율적으로 데이터 조회가능
대수 확장성 : 트리깊이가 리프 노두 수에 비해 매우 느리게 성장하는 것. 인덱스가 한 깊이씩 증가 할 때마다 최대 인덱스 항목으 수는 4배씩 증가
인덱스 생성
- MySQL
- 클러스터형 인덱스
- 테이블당 하나를 설정할 수 있다
- 특정 column을 기본키(primary key)로 지정하면 자동으로 클러스터형 인덱스가 생성되며, 해당 column을 기준으로 정렬됩니다. → Table 자체가 정렬된 하나의 index가 된다.
- 세컨더리 인덱스
- 보조인덱스로 여러개의 필드값을 기반으로 쿼리를 많이 보낼때 생성하는 인덱스
- 별도의 공간에 인덱스가 생성된다.
create index명령어로 index를 생성하거나 고유키(unique key)로 지정하면 보조 인덱스가 생성
- 클러스터형 인덱스
- MongoDB
- Document를 만들면 자동으로 ObjectID가 형성되며, 해당 키가 기본키로 설정됨
- 세컨더리키도 추가로 설정해서 기본키와 세컨더리키를 같이 쓰는 복합인덱스 설정 가능
인덱스 최적화
- 인덱스는 두번 탐색하도록 강요한다.
- 테이블이 변경되면 해당 인덱스도 수정되어야 한다. → B 트리 높이를 균형있게 조절하기 위한 비용과 데이터 분산 시키는데 비용이 든다.
- 서비스에서 사용하는 객체의 깊이 , 테이블 양이 다르기 때문에 항상 테스팅해야한다.
- 복함인덱스는 같음, 정렬 , 다중 값, 카디널리티 순으로 생성한다.
-
== | equal 쿼리가 있다면 제일 먼저 인덱스로 설정
-
다음으로 정렬에 쓰는 필드를 인덱스로 설정
-
다중 값을 출력해야하는 필드라면 나중에 인덱스르를 설정
-
카디널리티가 높은 순서를 기반으로 인덱스 생성
카디널리티(cardinality) : 유니크한 값의 정도
-
Index의 장단점
장점
-
검색 속도 향상 (SELECT~WHERE~ ) index를 생성하면 index에는 데이터들이 정렬되어 저장되어 있기 때문에 검색 조건에 일치하는 데이터들을 빠르게 찾아낼 수 있습니다.
단점
-
index를 생성하면 저장 공간이 추가적으로 필요합니다. 보통 table의 크기의 10%정도의 공간을 차지합니다.
-
검색이 아닌 데이터 변경 작업이 자주 발생하면 성능이 나빠질 수 있습니다. 데이터가 변경될 때마다 관련 index를 모두 수정해줘야 되기 때문에 시간이 추가적으로 소요됩니다.
Index 효과적으로 사용하는 방법
- SELECT WHERE절에 자주 사용되는 Column에 대해 index를 생성하는 것이 좋습니다.
- 데이터 수정 빈도가 낮을수록 적합합니다. insert / update / delete 작업 시, 데이터에 변화가 생기기 때문에 index에서는 매번 정렬을 다시 해야합니다. 이에 따른 부하가 발생하기 때문에 수정 빈도가 낮은 column을 index로 설정하면 좋습니다.
- 데이터의 중복이 높은 column은 index 효과가 별로 없습니다. 예를 들어 성별은 종류가 2 가지 밖에 없으므로 index를 생성하지 않는 것이 좋습니다. 즉, 선택도가 낮을 때 유리합니다.(보통 5~10% 이내)
- 데이터의 양이 많을 수록 index로 인한 성능향상이 더 큽니다. 데이터 양이 적다면 index의 혜택보단 손해가 더 클 수 있습니다.
- Join 조건으로 자주 사용되는 column의 경우
- 한 table에 index가 너무 많은면 데이터 수정시 소요되는 시간이 너무 길어질 수 있습니다. (table당 4~5개 정도 권장)
Index는 어느 column에 사용하면 좋을까?
-
index는 where 절에서 자주 조회되고, 수정 빈도가 낮으며, 데이터 중복이 적고, 선택도가 낮은 column을 선택해서 설정하는 것이 가장 좋습니다.
기준 적합성 카디널리티(Cardinality) 높을수록 적합 (데이터 중복이 적을수록 적합) 선택도(Selectivity) 낮을수록 적합 조회 활용도 높을수록 적합 (where 절에서 많이 사용되면 적합) 수정 빈도 낮을수록 적합
-
데이터를 검색을 할 때 hash table의 시간복잡도는 O(1)이고 b+tree는 O(logn)으로 더 느린데 왜 index는 hash table이 아니라 b+tree로 구현될까?
Hash table을 사용하면 하나의 데이터를 탐색하는 시간은 O(1)로 b+tree보 다 빠르지만, 값이 정렬되어 있지 않기 때문에 부등호를 사용하는 query에 대해서는 매우 비효율적이게 되어 데이터를 정렬해서 저장하는 b+tree를 이용합니다.
B+tree
- B+tree가 DB index를 위한 자료구조로 적합한 이유
- 항상 정렬된 상태를 유지하여 부등호 연산에 유리합니다.
- 데이터 탐색뿐 아니라, 저장, 수정, 삭제에도 항상 O(logN)의 시간 복잡도를 갖습니다.