Demand Paging

Memory에 없는 Page의 Page Table
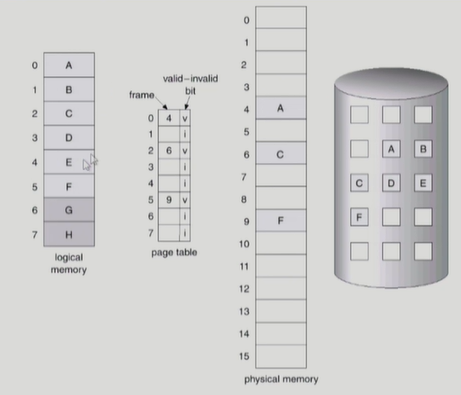
맨 오른쪽 disk는 swap area이다. 당장 필요한 부분은 demand paging에 의해 메모리에 올라가있고 그렇지 않은 부분은 swap area에 내려가 있다.
만약 cpu가 논리주소를 주면 page table에 찾는데 invalid면 메모리에 찾아야한다. 이렇게 메모리에 없는 것을 page fault라고 한다. page fault trap이 걸리면 cpu가 운영체제에 넘어간다.
Page Fault

Steps in Handling a Page Fault
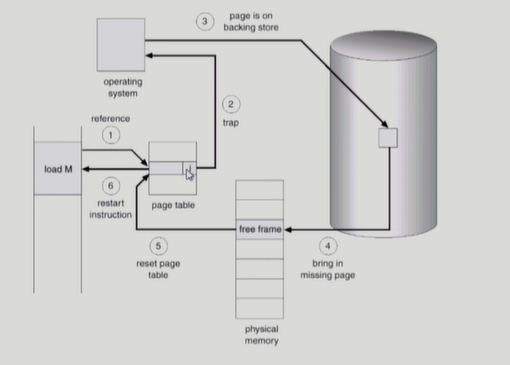
Performance of Demand Paging

page fault가 났을 때 disk에 가는 것은 대단히 비싼 작업이다. 실제는 page fault가 날 확률이 0.02이렇게 나온다.
Free frame이 없는 경우

Page Replacement
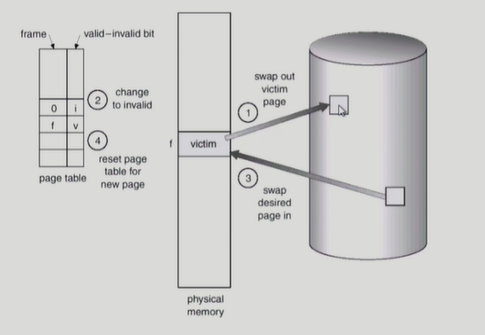
만약 디스크에 올라온 이후에 내용이 변경되었다면, 즉 write가 발생했다면 backing store에 써주기도 해야한다. 쫓겨난거는 invalid라고 바꾸고, 올라온거는 valid로 바꿔줘야한다.
Optimal Algorithm
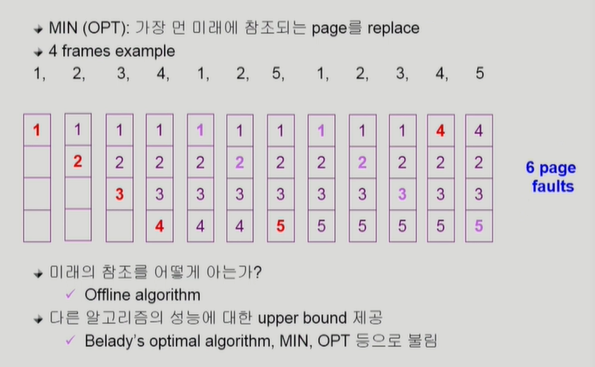
page fault를 가장 적게 하는 알고리즘이다. 하지만 이건 미래에 어떤 page가 쓰일지 미리 다 알고 있다고 가정하는 것이기에 실제로 쓰지는 못한다.
FIFO (First In First Out) Algorithm
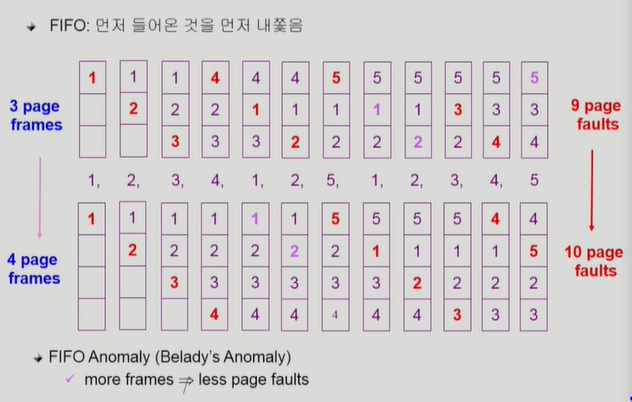
특이한점은 메모리 프레임 크기를 늘려줬는데 성능이 나빠질 수도 있다는 것이다. 이는 FIFO Anomaly라고 한다.
LRU (Least Recently Used) Algorithm
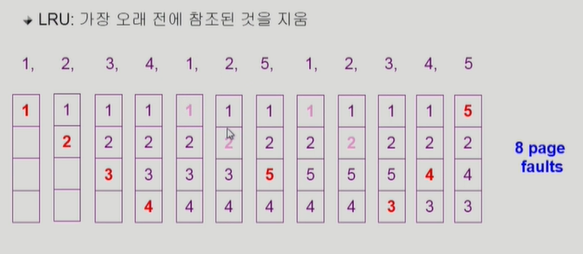
실제로 가장 많이 사용되는 알고리즘이다. 가장 덜 최근에 사용된, 즉 가장 오래전에 사용된 걸 쫓아낸다는 뜻이다. FIFO랑 다른 점은 재사용되면 안나간다는 점이다.
LFU (Least Frequently Used) Algorithm

단점은 이제 막 참조가 많이 되려는 페이지도 쫓아낼 수도 있다는 것이다.
LRU와 LFU 알고리즘 예제

LRU와 LFU 알고리즘의 구현
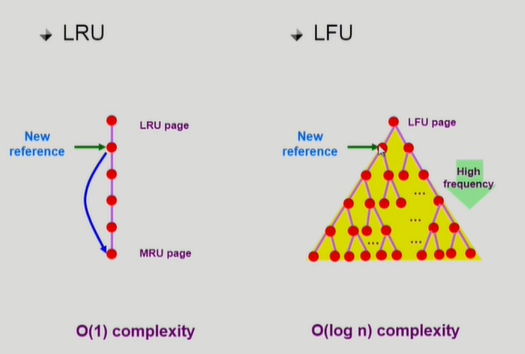
LRU는 참조 시간 순서대로 더블리 링크드 리스트로 관리를 한다. 시간 복잡도가 O(1)인 이유는 쫓아내기 위해서 비교가 필요없다는 것이다. (시간 순서대로 줄 세워 나서). 새로 참조되면 맨 밑으로 보낸다.
LFU는 참조 횟수 순서대로 줄 세워야하는데, 한번 참조되서 횟수가 늘어나면 하나하나 비교를 해야한다. 따라서 힙으로 구현을 한다.
다양한 캐슁 환경

이런 알고리즘은 다양한 곳에서 사용된다. 빠른 공간 자체를 캐쉬라고 부르기도 한다.
하지만 Page system에서는 이러한 알고리즘을 실제로는 사용할 수 없다.
Paging System에서 LRU, LFU 가능한가?
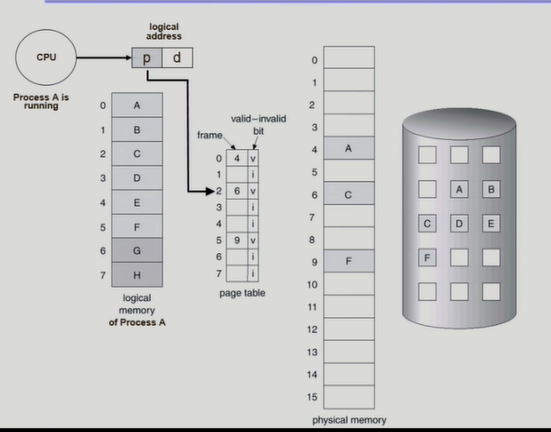
이미 메모리에 올라와있는 페이지에 접근하려하면 운영체제가 개입할 여지가 전혀 없다. 즉 사용되는 시점을 운영체제는 전혀 모르기 때문에 LRU에서 줄세우기가 불가능한 것이다. 다만 메모리에 없는 page fault가 나면 운영체제에게 넘어가므로 알 수 있다. 결론적으로 운영체제는 온전히 정보를 갖고 있지 않다.
Clock Algorithm

LRU를 실제로 사용할 수 없기 때문에 근사해서 사용하는 것이다.
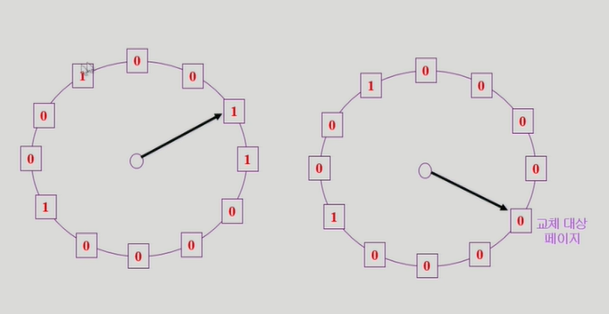
사각형 안에 비트를 reference bit, 또는 access bit이라 한다. 1이면 최근에 사용되었다는 뜻이다. 비트를 1로 바꾸는 것은 hardware가 하고 0으로 만드는 것은 운영체제가 한다. read가 발생했을 때는 reference bit만 1로 만들고, write가 발생하면 reference bit, modified bit 둘 다 1로 만든다. modified bit이 1이면 수정되었다는 뜻이므로, 쫓아낼때 disk에 쓰고 쫓아낸다.
Page Frame의 Allocation

캐쉬에는 각 프로세스의 페이지들이 혼합해서 올라와있을텐데, 쫓아낼때는 그런거를 고려하지 않는다. 그냥 오래된 것을 쫓아낸다.
하지만 Allocation은 프로세스 별로 할당을 해서 구분을 한다는 것이다. 각 프로그램마다 어느정도는 가지고 있어야 프로그램이 원할하게 돌아가기 때문이다.
Global vs. Local Replacement

Global은 allocation을 하지 않고 쓰는 것이다. 큰 프로그램이 많이 차지하고, 작은 프로그램이 작게 차지하나, 잘못하면 독식의 우려가 있다.
local은 프로세스한테 할당해주고 프로세스가 알아서 뭘 쫓아낼지 결정하는 것이다.
Thrashing Diagram
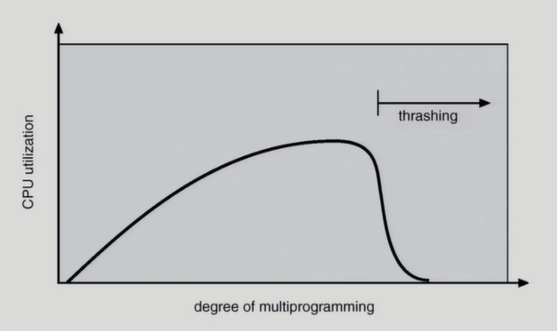
Degree of multiprogramming은 메모리에 올라가있는 프로그램의 개수다.
갑자기 뚝 떨어지는 thrashing이 일어나는 이유는, 각 프로그램이 원할하게 돌아기기 위한 최소한의 메모리도 얻지 못한다. cpu를 줘봤자 page fault가 나고, 다른 프로그램에게 cpu를 줘도 page fault가 나고 page fault의 비중이 더 커지는 것이다.
Thrashing

Working-Set Model

특정 시점에 집중적으로 사용되는 page들을 locaility set이라 부르는데, locality set은 메모리에 올라가게 보장해줘야 한다. 이렇게 특정 지역이 몰려서 사용되는 것을 locality of reference라고 한다.
Working-Set Algorithm

과거의 델타만큼의 과거를 통해서 working set을 유지한다.
PFF (Page-Fault Frequency) Scheme
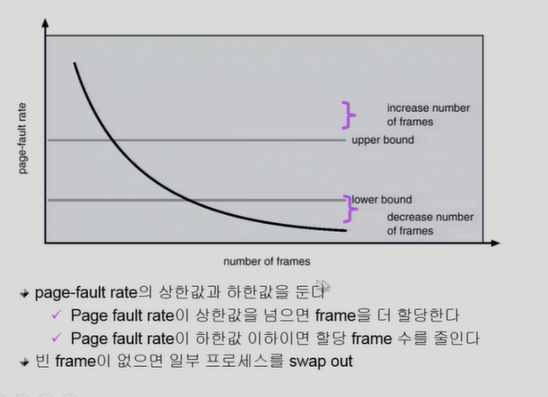
각 프로세스의 page fault 비율을 봐가면서 메모리를 더 줄지 말지 결정한다.
Page Size의 결정

페이지가 작으면 공간을 필요한만큼만 효율적으로 사용할 수도 있지만, 페이지 테이블이 늘어나고, 페이지가 사용될 때 보통 공간 지역성을 띄는데 거기서 손해를 볼 수 있다. 즉 메모리가 사용되면 인접 지역이 같이 사용될 가능성이 높기 때문이다.
