
Redis
Redis(REmote Dictionary Server)는 이름에서 알 수 있듯, 인메모리 데이터 구조 저장소다.
DB 서버에서 데이터를 읽으면 디스크에서 데이터를 읽기 때문에 시간이 많이 걸릴 수 있는데, 레디스는 기본적으로 메모리에 데이터를 저장하고 있기 때문에 훨씬 빠르게 데이터를 읽을 수 있다. 레디스는 캐시, 데이터베이스, 메시지 브로커 등 다양한 용도로 활용되기도 한다.
key-value 형태로 데이터가 저장되기 때문에 키를 이용해 결과를 빠르게 가져올 수 있다.
Redis vs Memcached
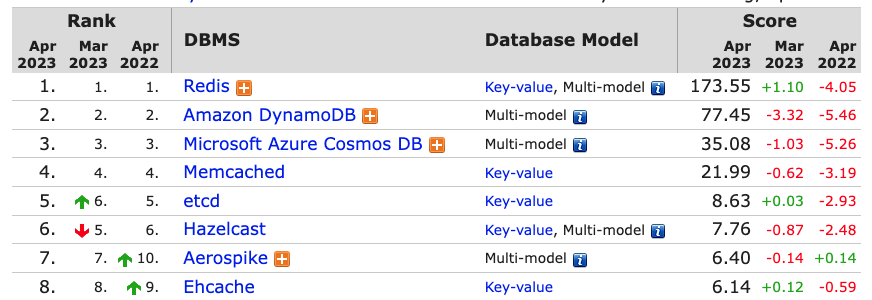
https://db-engines.com/en/ranking/key-value+store
레디스는 key-value 저장소에서 중에서 가장 인기가 많다.
Redis
- 많은 자료구조(문자열, 리스트, 해시, set)를 기본적으로 제공하고, Replication이나 클러스터 모드를 제공한다.
Memcached
- 레디스는 메모리 파편화 문제가 일어날 수 있는데 Memcached는 메모리 파편화 문제를 비교적 잘 다룬다. 내부 구현 차이가 있기 때문인데 레디스는 jmalloc으로 메모리 관리를 하고, memcached는 직접 다 하게 구현되어있다.
데이터 저장
레디스는 주 저장 장치로 메인 메모리를 사용하지만, 데이터를 잃어버리지 않게 디스크에 저장하는 기능도 제공한다. 이때 크게 두 가지 방법이 있다.
1. RDB
특정 시점에 메모리에 있는 모든 데이터를 디스크에 스냅샷을 저장하듯 binary 형태로 저장한다. 이때 파일 확장자 명이 rdb여서 rdb라 한다.
이때 자식 프로세스를 생성(fork)해서 디스크 쓰기를 하기 때문에 부모 프로세스에 명령을 처리하는데 지장을 주지는 않는다. 하지만 디스크 IO가 많이 발생하고 CPU IOWait이 올라간다.
2. AOF
AOF(Append Only File)은 조회 명령을 제외하고 입력/수정/삭제 명령을 디스크에 기록하는거다. 이때 저장 주기에 따라 세 가지로 구분 가능하다.
- always: 명령마다 디스크에 기록하는데, 그럼 메모리 db 를 쓰는 의미가 없을정도로 성능이 떨어진다.
- everysec: 1초마다 디스크에 저장한다. 디스크 기록은 별도 쓰레드가 수행하고, 가장 많이 사용되는 방식이다.
- no: OS가 디스크에 기록하는데, 간격은 30초다.
이 두 작업은 자식 프로세스를 생성해서 작업한다. 이때 프로세스 리스트를 보면 분명 레디스 서버는 하나만 실행 중인데 프로세스가 2개로보인다.
레디스 스레드
'레디스는 싱글 스레드여서 레디스를 이용한 분산락이 가능하다' 라는 말을 레디스에 대해 공부하기 전에도 들어봤었다. 정확히 말하면 레디스 서버는 멀티 스레드다. 버전 3.2까지는 스레드 3개, 4.0부터는 4개 스레드가 동작한다. 3.2 버전까지는 AOF 처리만 sub 스레드에서 했기 때문에 레디스가 싱글 스레드로 알려졌고, 그렇게 생각해도 큰 무리가 없었다. 하지만 4.0부터 UNLINK 명령을 sub 스레드에서 처리하면서 이제는 멀티스레드라고 해야 한다.
참고로 레디스는 메인 스레드와 sub 스레드가 있다.
sub 스레드는
- RDB 백업
- AOF 파일 작성
- 블로킹 작업 처리
등을 담당한다. 이 때문에 쓰기 작업이 있어도 메인 스레드의 성능에 영향을 미치지 않는 것이다.
레디스 무중단 서비스 구성
만약 실제로 이렇게 되어있다면 레디스가 장애가 났을 경우 모든 요청이 DB에 몰리게 된다. (물론 기본적으로 DB는 만일의 경우를 대비해 모든 요청을 받을 수 있게 스펙을 설정해놔야 한다). 그러면 레디스가 SPOF 가 될 확률이 높다. 이 경우 레디스 서버가 다운시 AOF 또는 RDB 파일을 이용해서 복구를 해야 한다.
이런 경우를 대비하는 방법은 이중화(마스터-슬레이브), 레디스 클러스터가 있다.
레디스 이중화
이중화는 RDB에서 Replication과 거의 유사하다.
레디스는 비동기(asynchronous)로 복제를 한다. 데이터를 복제 서버로 보내는 작업은 자식 프로세스가 처리하기 때문이다. 복제 서버에 조회 요청을 처리하도록 하는건 부하를 분산시키는 좋은 방법이다.
레디스 클러스터
위에서 레디스는 기본적으로 싱글 프로세스라고 했지만, 멀티 프로세스를 지원하는 Redis Cluster 모드도 제공한다. 레디스 클러스터는 여러 대의 레디스 서버를 사용하여 고가용성 및 확장성을 제공하는 레디스 분산 시스템이다. 각 서버는 별도의 프로세스로 동작하게 된다. 클러스터를 통해 데이터를 분산 처리할 수 있고 고가용성과 확장성을 제공한다.
레디스 클러스터는 레디스 3.0 이상부터 사용 가능하다.
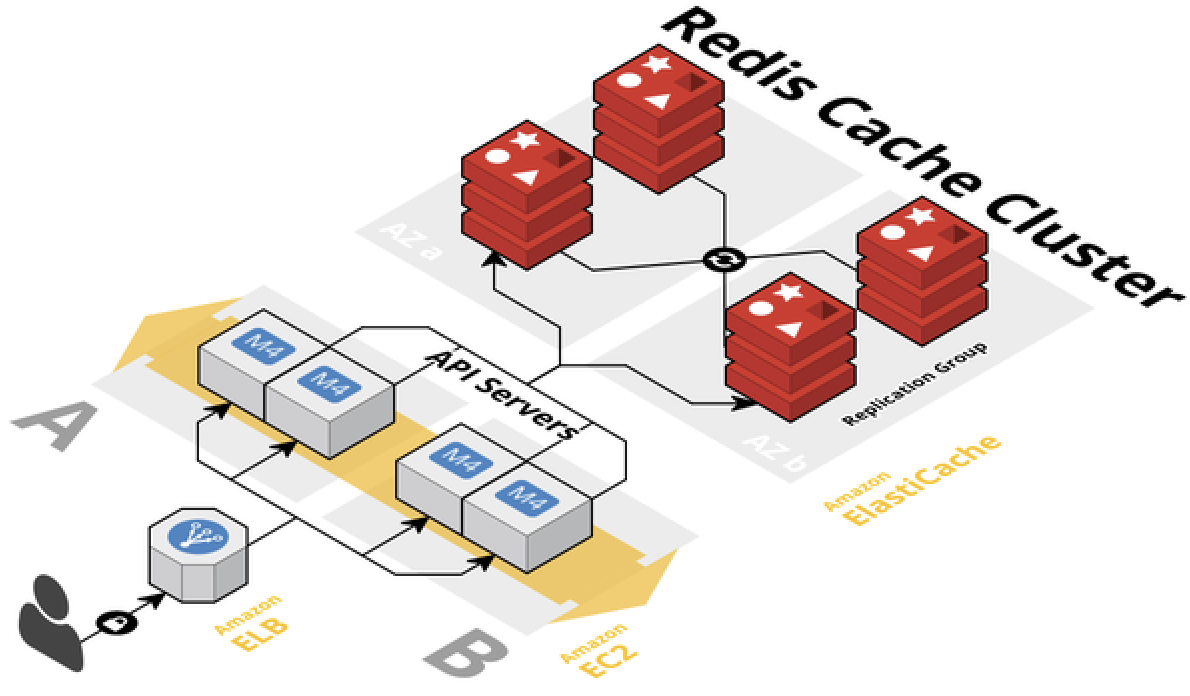
레디스 클러스터는 데이터를 자동으로 샤딩(Sharding)하여 여러 대의 서버에 분산한다. 이때 데이터를 나누는 방법은 키에 hash 함수를 적용해서 값을 추출하고, 이 값을 할당하는 방식이다. 참고로 레디스에서 hash 값의 개수는 16384(0~16383)이고 이걸 슬롯이라 부른다.
