ElasticSearch란
루씬(Lucene) 기반의 오픈소스 검색 엔진. JSON 기반의 문서를 저장하고 검색할 수 있으며 분석 작업이 가능하다.
특징
1. 준실시간 검색 시스템
실시간이라고 생각될 만큼 색인된 데이터가 빠르게 검색된다.
2. 고가용성을 위한 클러스터 구성
한 대 이상의 노드로 클러스터를 구성하여 높은 수준의 안정성을 달성하고 부하 분산이 가능
3. 동적 스키마 생성
입력될 데이터들에 대해 미리 스키마를 정의하지 않아도 동적으로 스키마 생성이 가능
4. Rest API 기반이 인터페이스
단점
- Document간 조인 수행이 불가능하다 (두 번 쿼리를 해야한다)
- 트랜잭션이 제공되지 않는다.
클러스터와 노드
노드의 종류
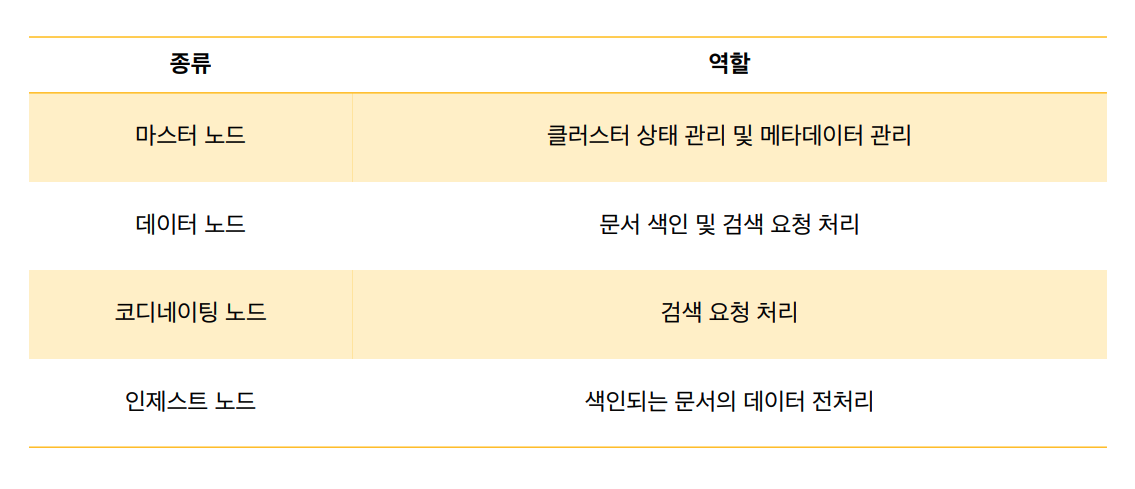
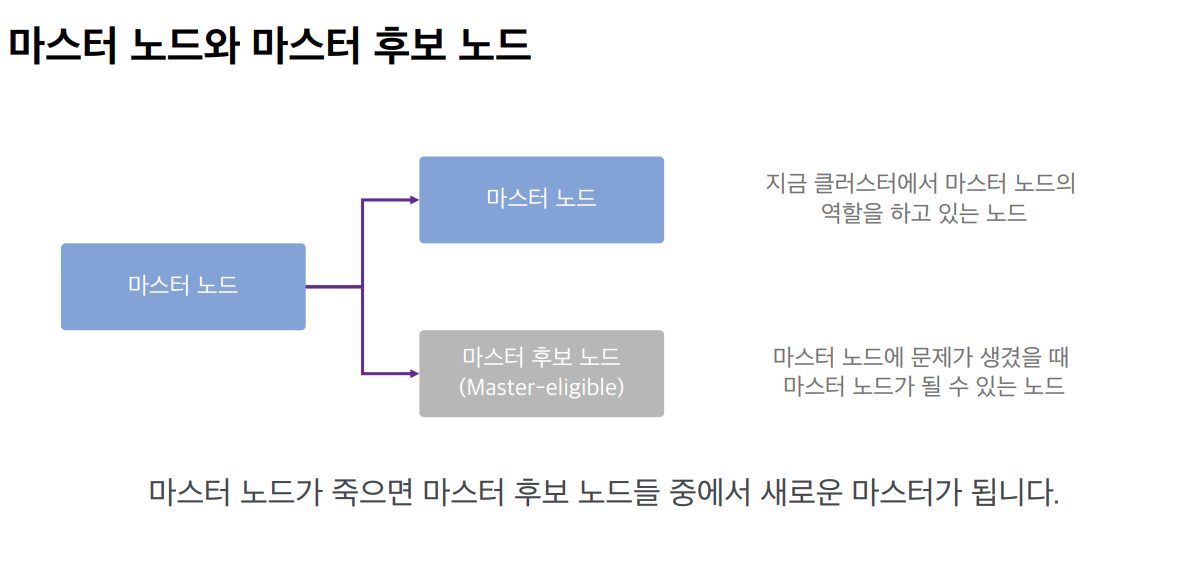
ElasticSearch도 여러 대의 노드들이 각자의 역할을 바탕으로 연결되어 하나의 시스템처럼 동작하게 되어 있습니다. 그래서 어떤 노드에 어떤 요청을 해도 동일한 응답을 준다.
클러스터의 특징
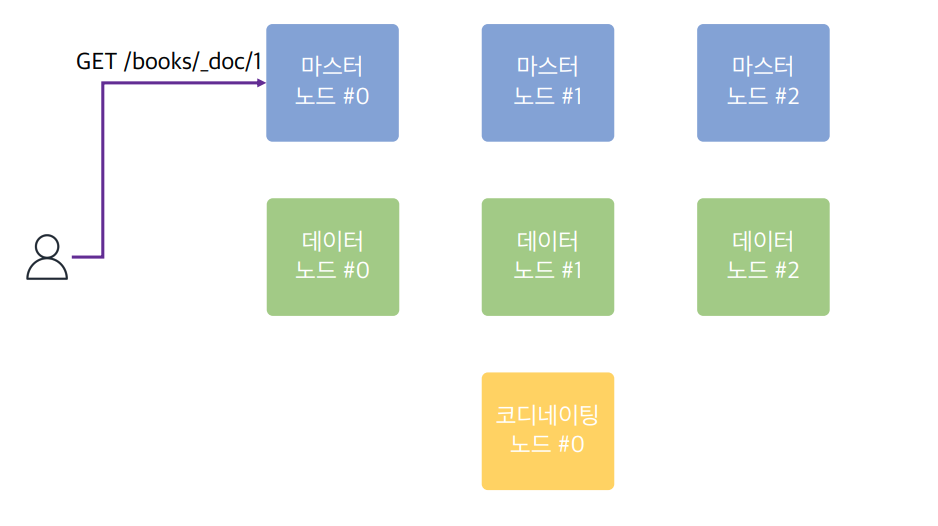
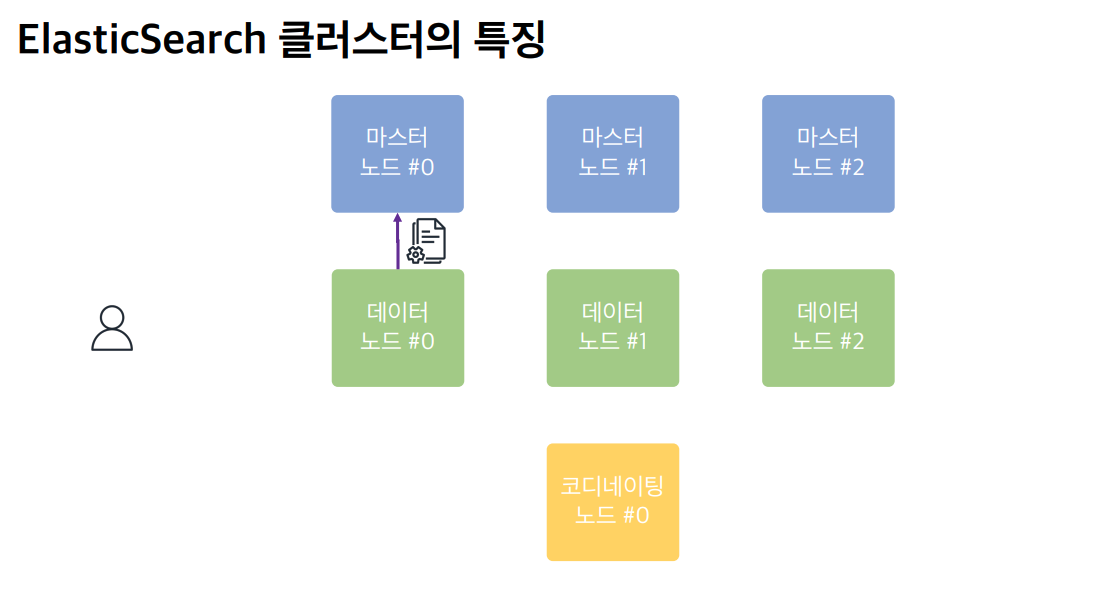
시나리오 1
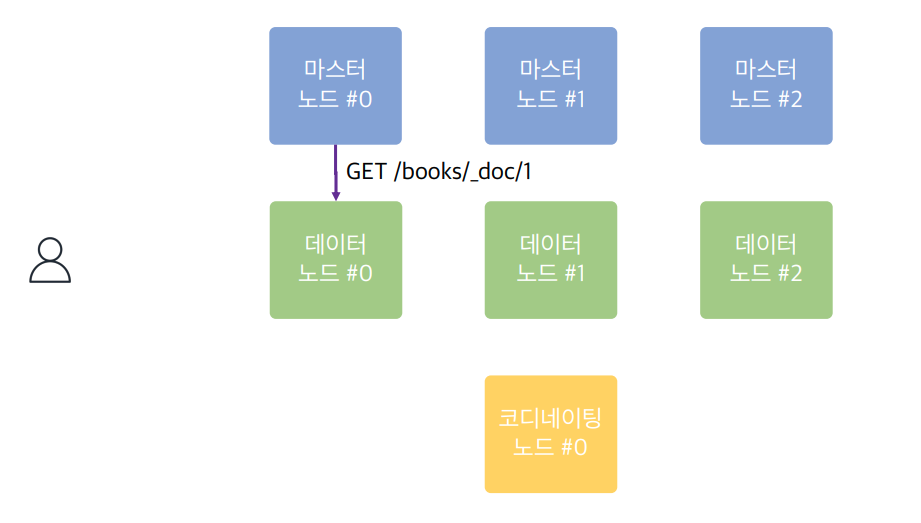
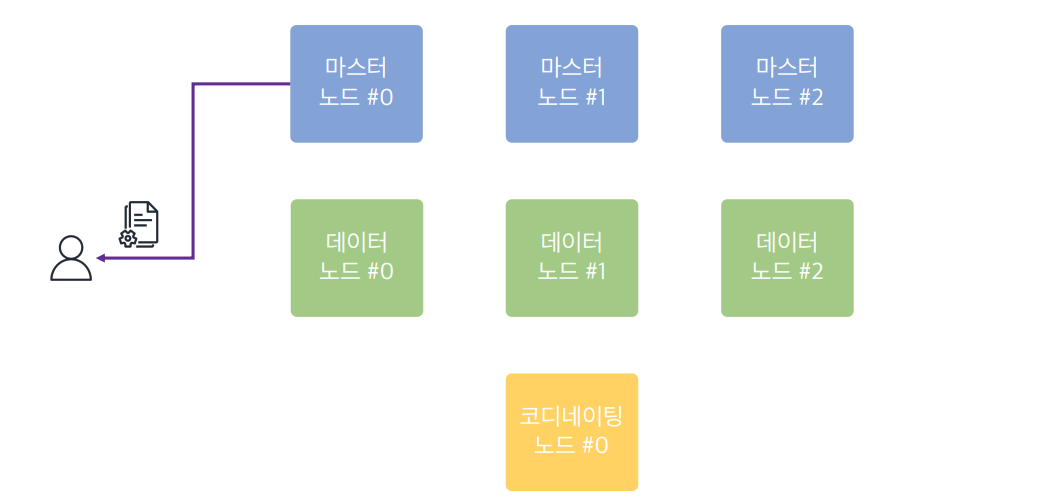
시나리오 2
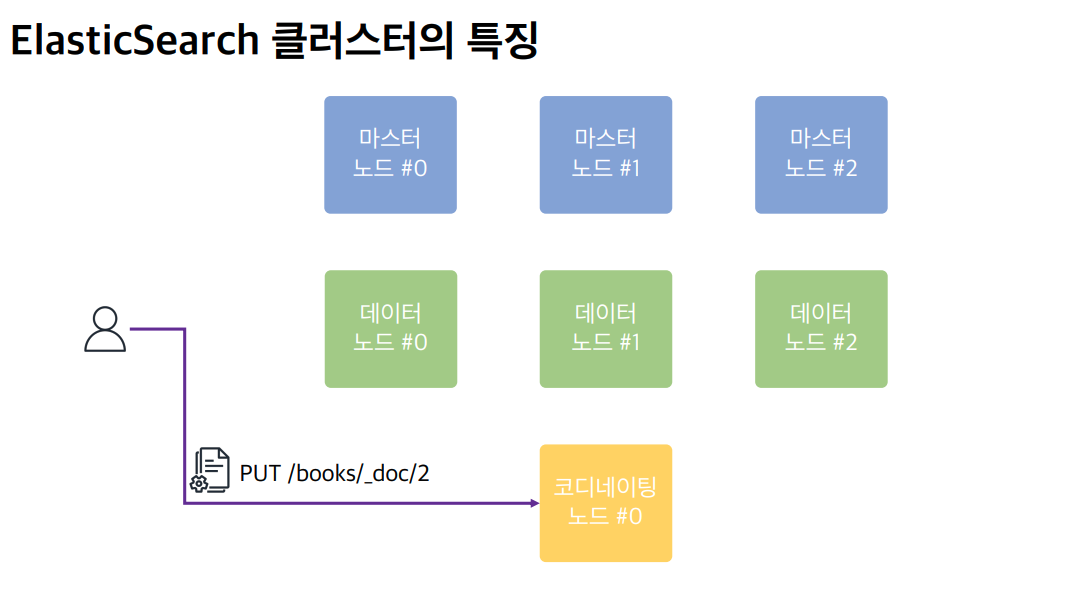

어느 노드에 요청을 보내도 사용자의 요청을 처리하지만, 각각의 노드가 본연의 역할에 충실할 수 있도록 구성하는 것이 중요하다.
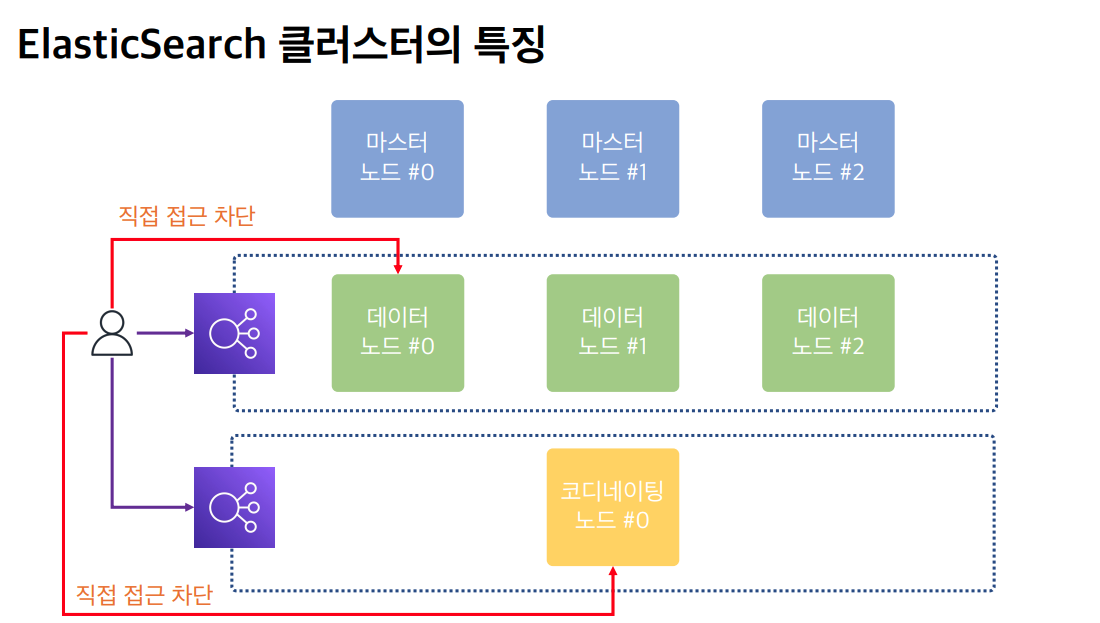
로드밸런서를 앞에 둬서 요청들을 적절한 곳에 보내면 해당 역할을 전담하는 노드에 바로 보내므로 더 효율적이다.
인덱스와 샤드
인덱스란

인덱스는 RDBMS에서 database에 해당한다.
문서가 저장되는 논리적인 공간

인덱스 설계에 따라 문서의 구조 및 검색 쿼리가 달라질 수 있다.
시나리오 1



샤드
인덱스에 색인되는 문서가 저장되는 공간. 하나의 인덱스는 반드시 하나 이상의 샤드를 가진다.


인덱스의 프라이머리 샤드 개수는 변경할 수가 없다. 따라서 인덱스를 생성할 때 프라이머리 샤드의 개수를 설정하는 건 매우 중요하다.
매핑

RDBMS에서 schema랑 대응된다.

동적 매핑
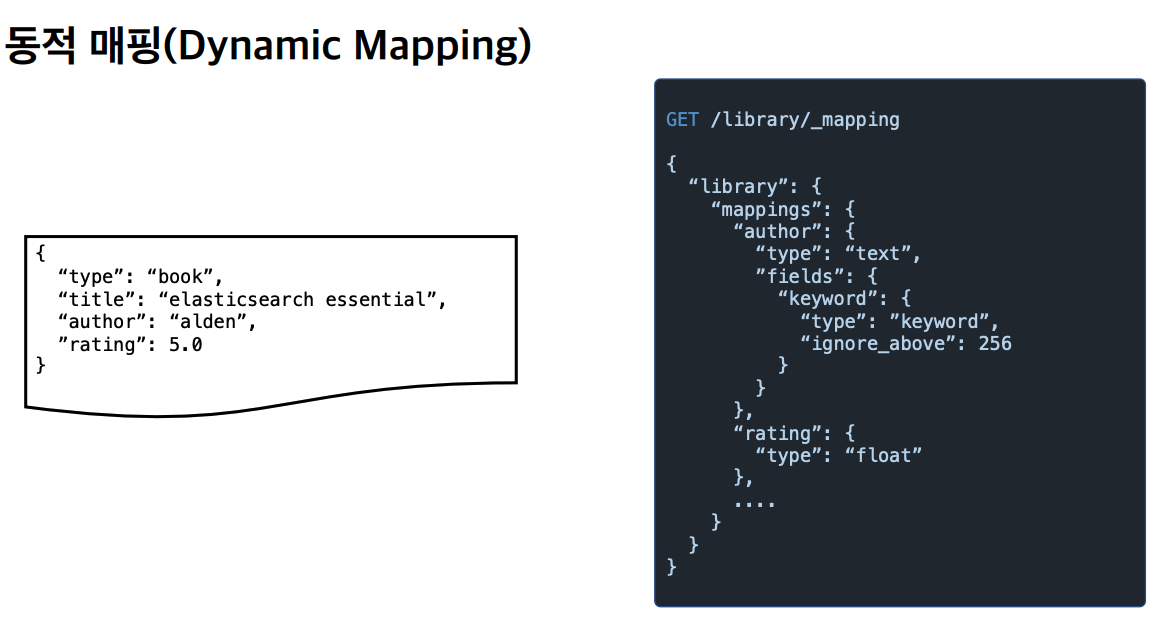
동적 매핑에 의해 매핑 정보가 생성된 후에는 타입이 안맞을 경우 파싱 에러가 발생 합니다.
(꼭 동적 매핑이 아니더라도 매핑 정보가 생성된 후)

정적 매핑
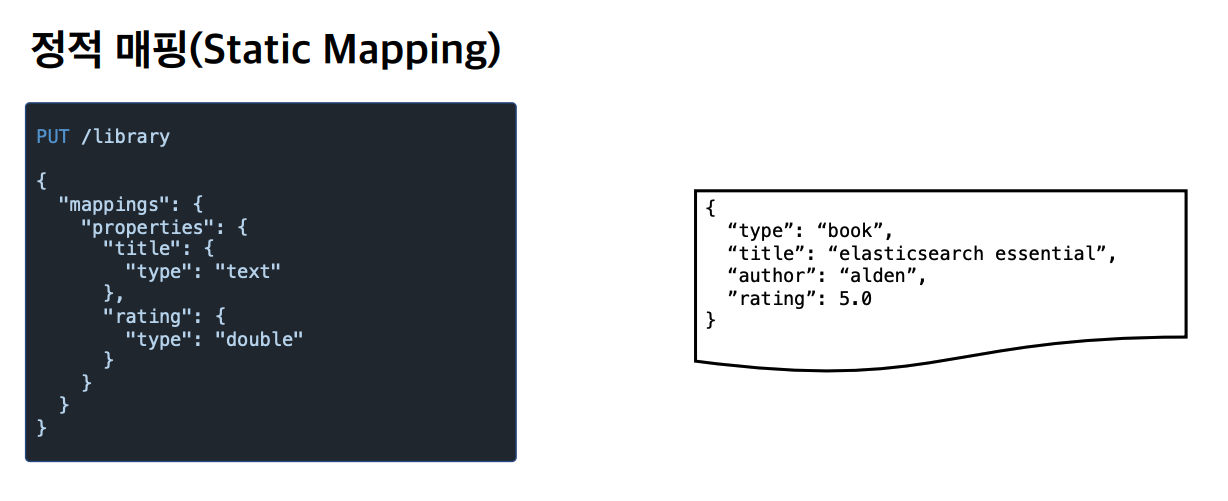
스키마를 넣어준다.
type과 rating은 정의되어있지 않으니 동적 매핑된다. 굉장히 유연한 인터페이스 정의가 가능하다.
정적 매핑은 언제 도움이 될까?
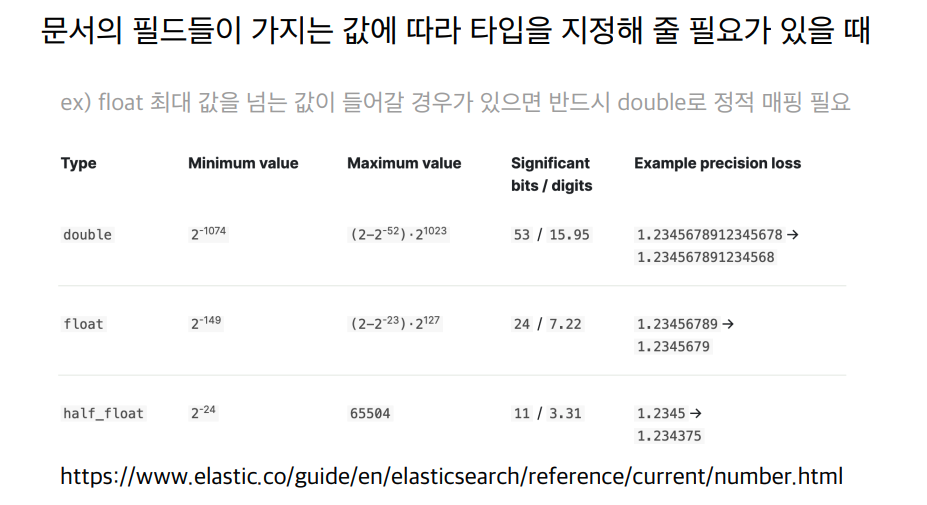
또 불필요한 색인이 발생하지 않는 장점이 있다.
색인 과정
색인이란: 문서를 분석하고 저장하는 과정

적절하게 노드 수를 설정하고 샤드 배치를 하는 것이 성능에 아주 중요하다. but, 생략.
검색 과정
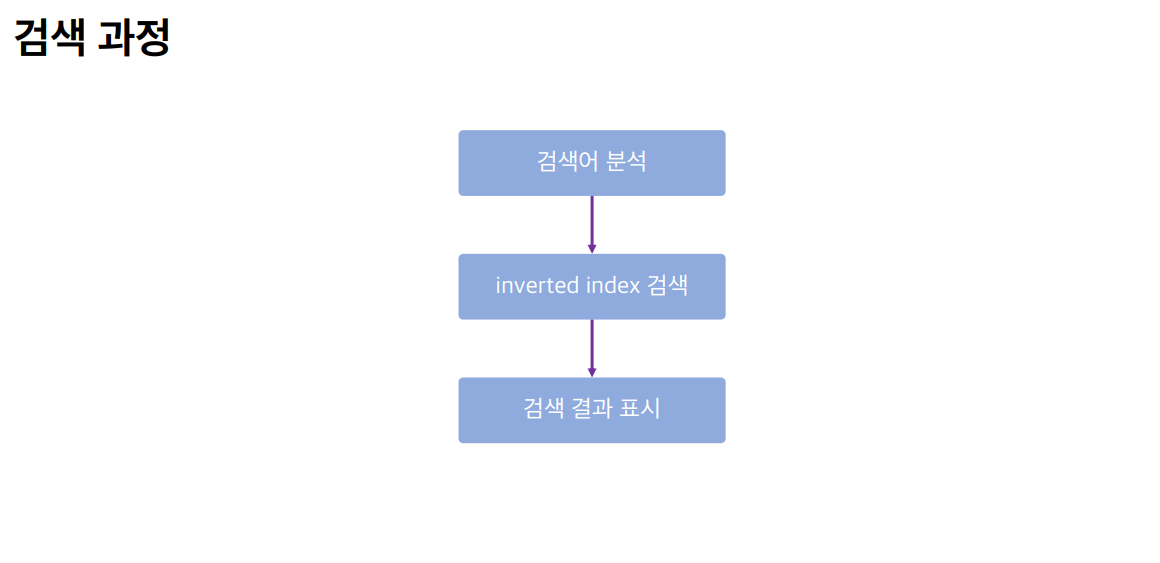
Inverted Index
문자열을 분석한 결과를 저장하고 있는 구조체
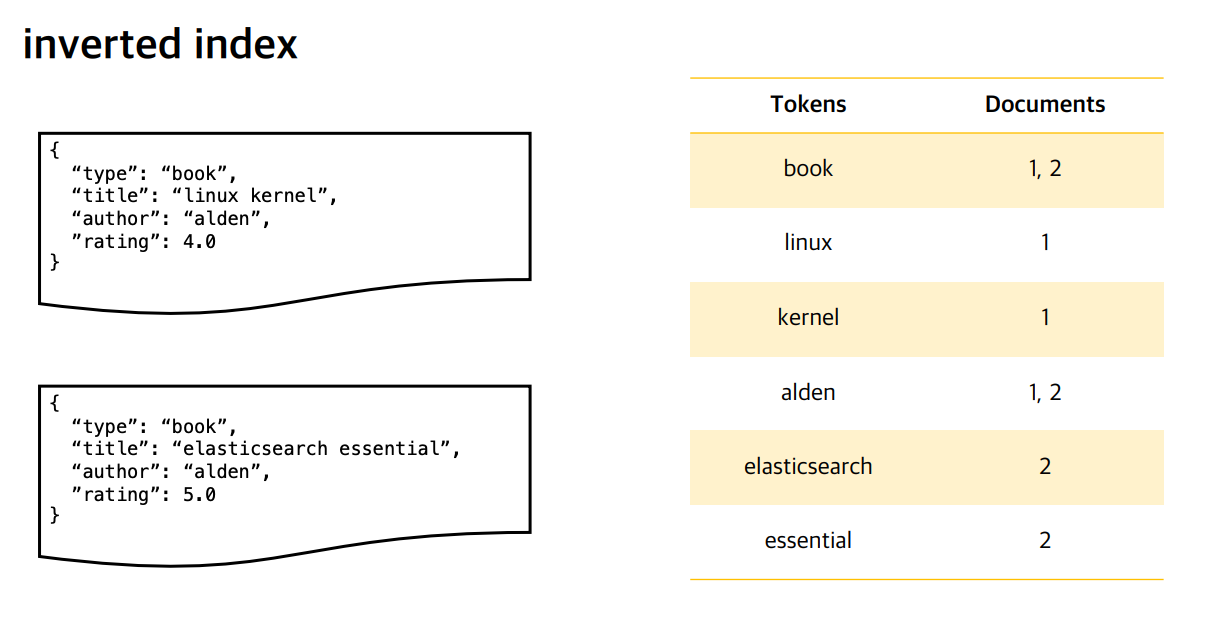
애널라이저


"linux kernel"에 대해 검색헀을 때 이렇게 두 개의 토큰으로 이루어진걸 볼 수 있다.
검색
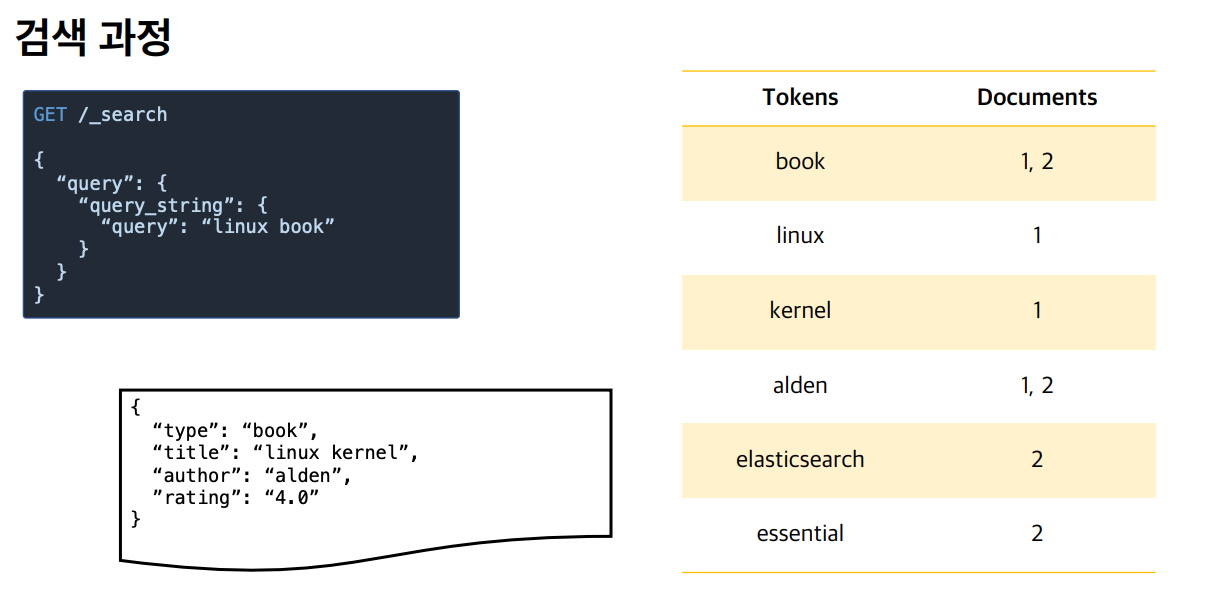
검색 과정을 보면 쿼리 랭기지로 검색을 한다. linux, book으로 분석되고, linux와 book 둘다 가지고 있는 book 이 나오게 된다.
