Static Hashing

Extendible Hashing (EH)

When bucket A overflows, double directory and rehash entries b/w A and A2

Example

여기서 h(r) = 5 = binary 101이면 global depth가 2이니 마지막 뒤 두자리만 봐서 01이 가리키는 bucket B로 간다.
Insert h(r) = 20 (10100) (Causes Doubling)
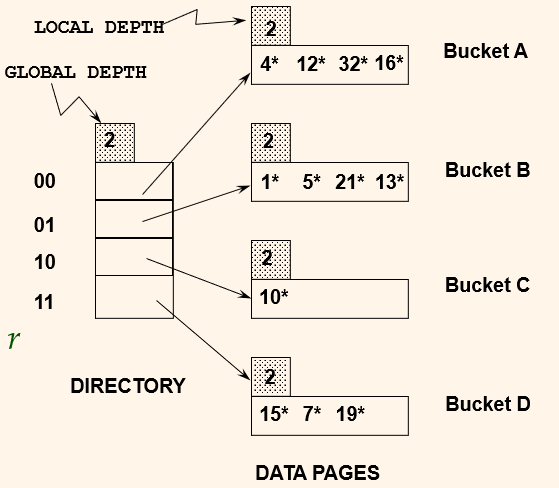
이 상태에서 20을 넣으려면 20은 (10100)이니 끝자리 두개를 보면 00인데 bucket A가 꽉 찼다.
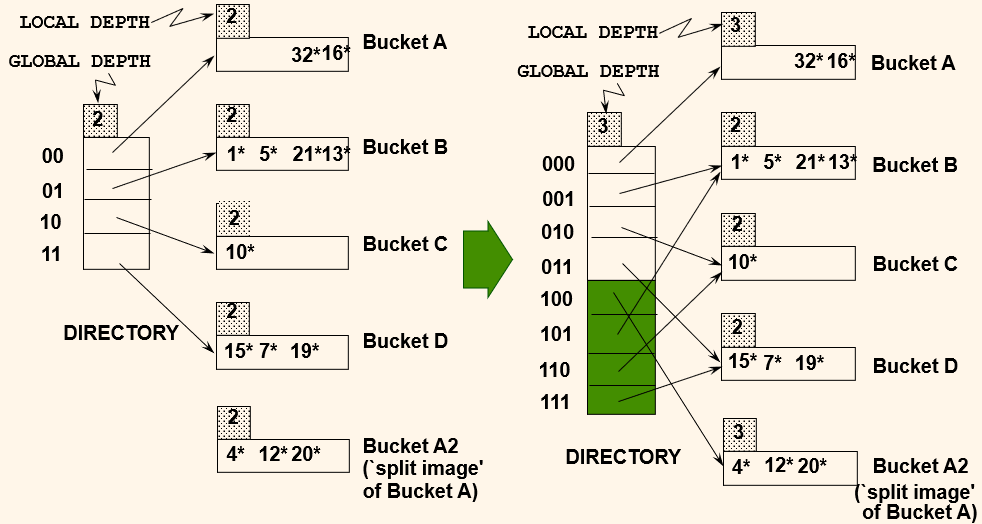
global depth를 1 올려줌으로서 디렉토리가 2배가 되고, 끝 3자리를 구분함으로서 bucket A에서 4 와 12는 구분되서 빠져나온다. 각 bucket의 위에 회색 상자는 몇개의 끝자리 숫자에 의해 구분되고 있는지 알려준다.
만약 bucket B에 뭔가를 추가한다면 directory를 double할 필요가 없다. 101과 분배하면된다. local depth가 global depth보다 커지게될 경우 directory를 double하는 것이다.
Points to Note

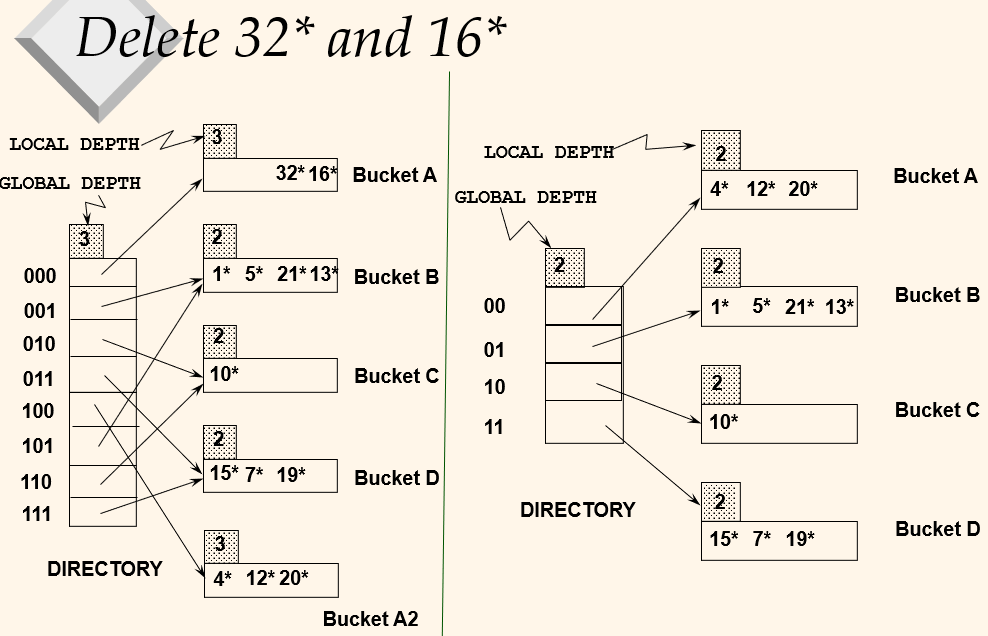
Delete
Delete: If removing data entry leads to empty bucket, the bucket is merged with 'split image', i.e., the pair 0xx and 1xx that differs only in left most bit. If every such pair is merged, the directory can be halved.
Delete 32 and 16
Comments on Extendible Hashing
- Skewed distribution of hash value, where many entries have same hash value, cause problems!
- Directory can grow large and data entries remain unsplit, so overflow chain can develop
- Assume distribution of hash values is uniform.
- If directory fits in memory, equality search answered with one disk access (usually assume 1.2 - considering overflow just in case); else two.
- Additional disk access to get data records for Alternatives (2) and (3)
- Clustered hash index; data records of same k value are stored on same page as much as possible. (good for equality query)
Example (Alternative 1)
- For 100B/rec, 4KB/page, 1,000,000 records (100MB file!), how many data entry pages are needed, how many directory entries are needed?
- Data entry page: 1,000,000 / (4000 / 100) = 25,000
-> 여기서 25,000은 위의 그림에서 bucket의 개수를 나타낸다. 위의 그림에서 4개의 bucket이 있고 각 bucket은 4개의 entry가 있다. - Directory entries: 25,000, one per data entry page; chances are high that directory will fit in memory.
-> directory 용량은 bucket의 개수와 같다.
- Data entry page: 1,000,000 / (4000 / 100) = 25,000
Example (Alternative 2)
- Assume 1,000,000 rec., 100B/rec., 20B/data entry, 10B/directory entry, 4KB page size, bucket 50% full
- # pages for rec.: 1,000,000 / (4,000 / 100) = 25,000
- # pages for buckets: 1,00,000 / (4,000 / 20) = 5,000, half full => 10,000, thus, 10,000 directory entries.
- # pages for directory : 10,000 / (4000/10) = 25 pages
- directory much smaller than buckets, which is much smaller than data file.
Linear Hashing (LH)
- EH splits the bucket that overflows, using directory to keep track of buckets
- LH splits the bucket in round-robin fashion, without using directory.

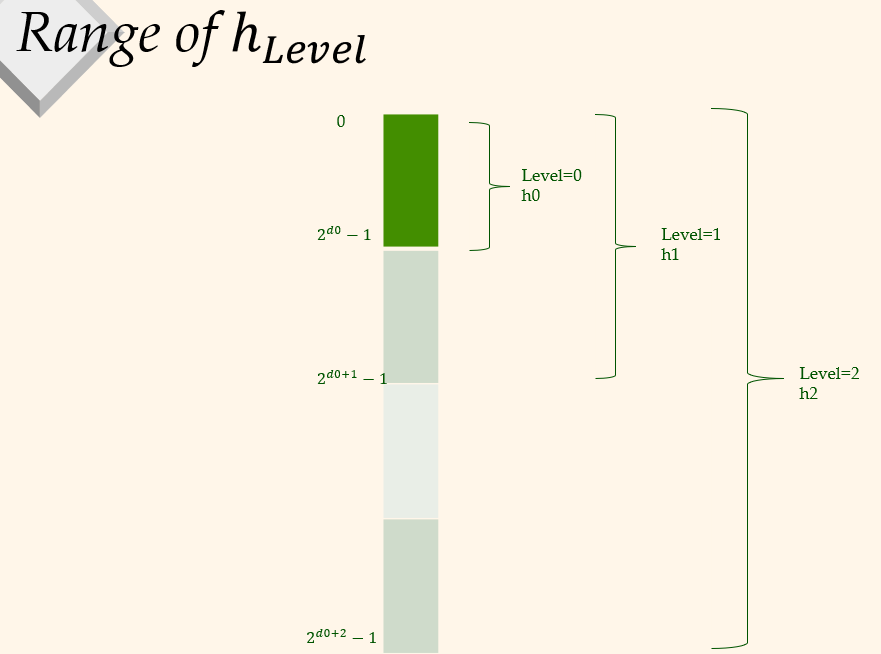
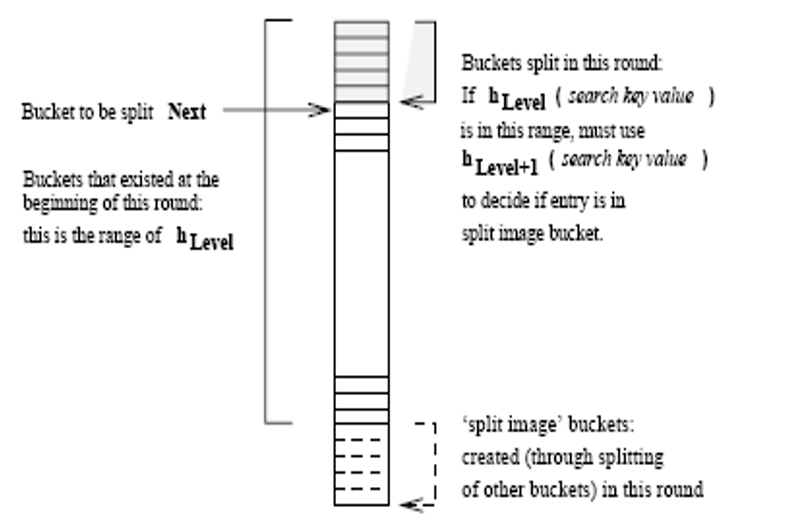
Range of hLevel
Linaer Hashing (Contd.)

Search 25 and 44
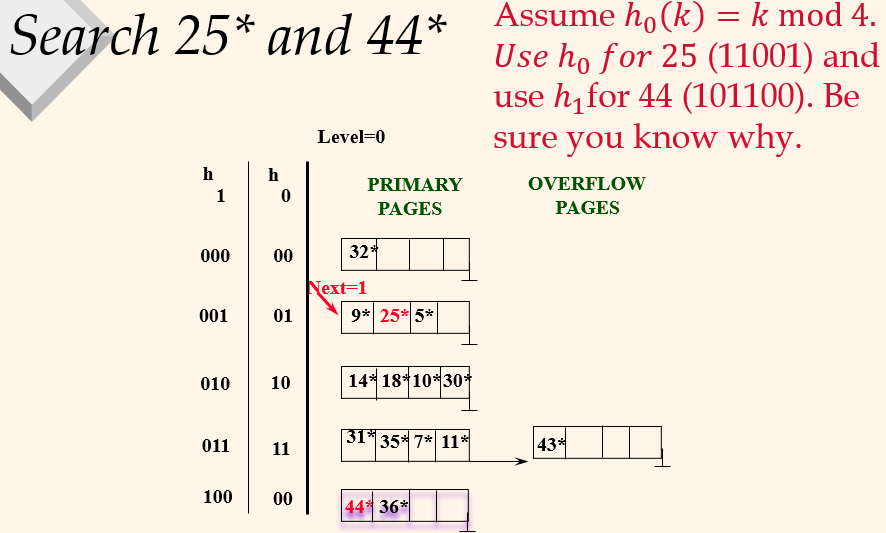
밑에 보라색 색칠 된 것은 split된 것이다. next 포인터 위에 것들은 다 이미 split 됐다. 25를 찾을 때는 끝자리 2개가 01이니 포인터로 찾을 수 있다. 44의 끝자리 두개는 00인데 이미 포인터가 지났으니 스플릿됐고 100을 봐야할 것이다.
