자료구조 dequeue, priority queue,Defaultdict, Count, namedtuple
#stack 자료구조 #first in last out 구조를 가지고 있음
a = [1,10]
a.append(4)
a.append(20)
a.pop()
print(a)
a.pop()
print(a)
#Queue 구조
b = [1,10]
b.insert(0,20)
print(b)
b.insert(2,15)
print(b)
#특정 값 제거
del b[0] # -> 0번 위치에 있는 값 제거 Linked List 자료구조 ( Queue 구조 구현을 위해선 연결 리스트 자료 구조가 필요)
- 양쪽으로 자유로운 입출력
- 중간 참조는 오래 걸리나, 큐 구조에선 상관 없음
파이썬 Collection Library의 deque를 사용
from collections import deque
queue = deque([10,5,12])
queue.appendleft(16) #왼쪽 삽입 - 시간복잡도 O(1)
queue.pop() #오른쪽 삭제 - 시간복잡도 O(1)
print(queue)
queue.append(5) #오른쪽 삽입 - 시간복잡도 O(1)
queue.popleft() #왼쪽 삭제 - 시간복잡도 O(1)
print(queue)최소 / 최대값을 빠르게 구할 수 있을까?
min/max 함수 → 시간 복잡도 O(N)이 나오게된다.
조건) 이진 검색을 위해선 내부가 정렬되어 있어야함.
sorted 사용 → O(NlogN) ⇒ 매우 비효율적
리스트 정렬 후 값을 중간에 삼입/삭제 → O(N)
그러므로 →
Priority Queue가 필요한 순간 ⇒ 파이썬 heapq Library의 heapq 사용!
import heapq
queue2 = [5,2,8,4]
heapq.heapify(queue2) #Heap 초기화 , O( N log N)
print(queue2) #Heap[k] <= heap[2*k+1], heap[2*k+2]
print(queue2[0]) #Heap top : 가장 작은 값 위치, Min Heap
heapq.heappush(queue2, 3) #Heap Push, O(log N)
heapq.heappush(queue2, 6)
print(queue2)
item = heapq.heappop(queue2) #Heap pop, O(log N)
print(item, queue2)
item = heapq.heappushpop(queue2, 7) # push 하고 pop 하는 것 보다 빠름
print(item, queue2)
이진 트리 방식으로 일반적인 코테에서 O(N^2) 이 나올 때 O(NlogN)으로 낮출 수 있음
Defaultdict
파이썬 기본 dictionary는 키가 없을 경우 에러가 나온다.
→ 에러 발생을 막기 위해선 get 메소드의 default 값 지정 필요하다.
d = {"first": 0}
d["second"] # 에러 발생
d.get("second" : "없어요") # 이런 형식이 필요함text = "유구한 역사와 전통에 빛나는 우리 대한국민은 3·1운동으로 건립된 대한민국임시정부의 법통과 불의에 항거한 4·19민주이념을 계승하고, 조국의 민주개혁과 평화적 통일의 사명에 입각하여 정의·인도와 동포애로써 민족의 단결을 공고히 하고, 모든 사회적 폐습과 불의를 타파하며, 자율과 조화를 바탕으로 자유민주적 기본질서를 더욱 확고히 하여 정치·경제·사회·문화의 모든 영역에 있어서 각인의 기회를 균등히 하고, 능력을 최고도로 발휘하게 하며, 자유와 권리에 따르는 책임과 의무를 완수하게 하여, 안으로는 국민생활의 균등한 향상을 기하고 밖으로는 항구적인 세계평화와 인류공영에 이바지함으로써 우리들과 우리들의 자손의 안전과 자유와 행복을 영원히 확보할 것을 다짐하면서 1948년 7월 12일에 제정되고 8차에 걸쳐 개정된 헌법을 이제 국회의 의결을 거쳐 국민투표에 의하여 개정한다"
characters = {}
for char in text:
count = characters.get(char, None)
if count is None:
characters[char] = 0
characters[char] += 1
print(characters)더 효율적인 방법은 defaultdict이라는 방법이다.
from collections import defaultdict
characters = {}
characters = defaultdict(int) # 기본값 int()
# characters = defaultdict(lambda : 0)
for char in text:
characters[char] += 1
print(characters)더 깔끔하게 코딩하는 방법 Counter 뭔가는 세는데(객체, 수 등등) 최적화된 데이터 구조이다.
from collections import Counter
characters = Counter(char for char in text) # print(Counter(text)) 바로 넣어도 가능
print(characters)print(Counter([1,2,1,2,1,2,3]))
print(Counter(["test","test","text"]))
print(Counter("test"))각각의 아래의 출력 형태

from collections from Counter
c = Counter({"korean": 2, "english" : 3})
print(c)
print(c.keys()) #일반적인 dict과 차이 없음
print(c.values())
c["korean"]
list(c.elements()) #모든 요소 반환
일반적인 dict형태와 출력형태의 차이가 없음.
from collections from Counter
c = Counter(korean = 2, english = 3) #kwqargs로 생성가능
print(c)
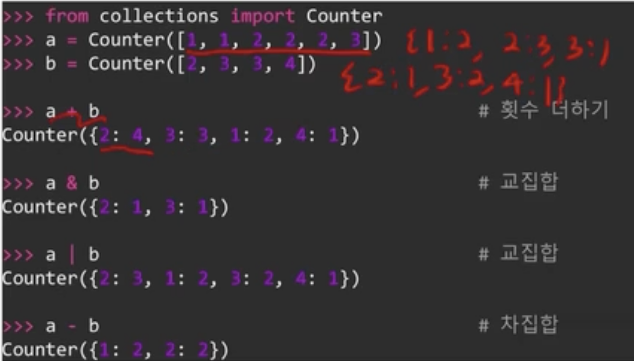
+) Counter는 집합 연산을 지원한다.
namedtuple
from collections import namedtuple
Coords3D = namedtuple("Coords3D", ['x','y','z'])
point = Coords3D(10,20,30)
print(point.x) # Attribute(속성) 이름으로 참조
print(point[1]) #index로 참조하는 방법
print(*point) #tuple unpackingprint(point[1] += 1) 안에 있는 값을 변경하려면 오류가 발생한다.
class Coord3D:
def __init__(self, x,y,z):
self.x = x
self.y = y
sllf.z = z
@property
def x(self):
return self._x
#이렇게 y,z, 까지 선언해야 하는 불편함을 없애기 위해 namedtuple을 사용한다.
#데이터 구조인데 굳이 클래스를 만들 필요가 없다. pythonic 한 데이터 클래스를 위해선 dataclasses 의 dataclass데코레이터 활용 가능
from dataclasses import dataclass
@dataclass
class Coords3D:
x : float
y : float
z : float = 0
def norm(self):
return (self.x**2 +self.y**2+ self.z**2)** .5
point = Coords3D(10,20,30)
print(point)
print(point.norm())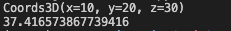
append() - list에서 사용
a = [1,2,3,4]
a.append(5) # 저장할 필요 없이 추가되는 개념
print(a)
-> 1,2,3,4,5문자열
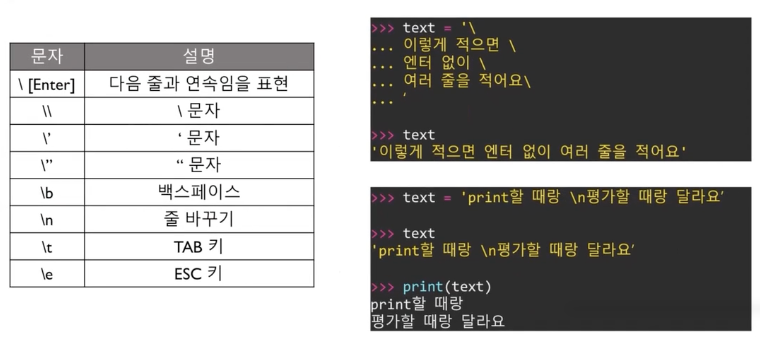
"a" in "asdf" => True
text = """
여려줄
작성가능
"""indexing, slicing 사용이 가능하다 ex) text[3:]
len(\n) #=> 결과 값이 1이 나온다
#콘솔창에서 실행 시
text = "asdf\nasdf"
text
=> asdf\nasdf
repr(text)
=> asdf\\nasdf
print(repr(text))
=> asdf\nasdfrepr 은 원본객체를 복원하기 위한 도구이다.
r”” 형태로 \를 무시하고 문자 그대로 취급 가능 (raw string)
⇒ 파일 형태 보여줄 때 사용 많이 한다. 주로 정규 표현식에서 사용
locate = "C:\\Users\\ingeol"
print(locate) => C:\Users\ingeol
locate2 = r"C:\Users\ingeol"
print(locate2) =>C:\Users\ingeolString fuctions
-
len(string) ⇒ 문자 개수 반환
-
string.upper() ⇒ 대문자로 변환
-
string.lower() ⇒ 소문자로 변환
-
string.capitalize() ⇒ 문자열 시작을 대문자로 변환
-
string.title() ⇒ 단어 시작을 대문자로 변환
-
string.strip() ⇒ 좌우 공백 제거
-
string.lstrip() ⇒ 왼쪽 공백 제거
-
string.rstrip() ⇒ 오른쪽 공백 제거
-
string.isdigit() ⇒ 숫자 형태인지 확인 T/F
-
string.isupper() ⇒ 대문자로만 이루어져 있는지 확인 T/F
-
string.islower() ⇒ 소문자로만 이루어져 있는지 확인 T/F

text = 'abc_text_abc_ee'
pattern = 'abc'
text.count(pattern). 2
text.find(pattern). 0
text.rfind(pattern). 9
text.startswith(pattern) => True
text.endswith(pattern) => False- string.count(pattern) ⇒ 문자열 string내에 pattern 등장 획수 반환
- string.find(pattern) ⇒ 문자열 string내에 pattern 첫 등장 위치 반환 (앞에서 부터)
- string.rfind(pattern) ⇒ 문자열 string내에 pattern 첫 등장 위치 반환 (뒤에서 부터)
- string.startswith(pattern) ⇒ 문자열 string이 pattern으로 시작하는지 확인
- string.endwith(pattern) ⇒ 문자열 string이 pattern으로 끝나는지 확인
string Split & Join
- string.split() ⇒ 공백을 기준으로 문자열 나누기
- string.split(pattern) ⇒ pattern을 기준으로 문자열 나누기
- string.join(iterable) ⇒ string을 중간에 두고 iterable 원소들 합치기

String Formatting
print등을 할 때 보기 좋게 값들을 확인하고 싶음
- 일정한 형태로 변수들을 문자열로 출력
- 써서 구현할 수 있지만 .. (하드코딩)

아래의 % formatting, .format 함수, f-string을 써서 표현하는 것이 좋음.
%-formating → c나 java에서 많이 사용하는 형태

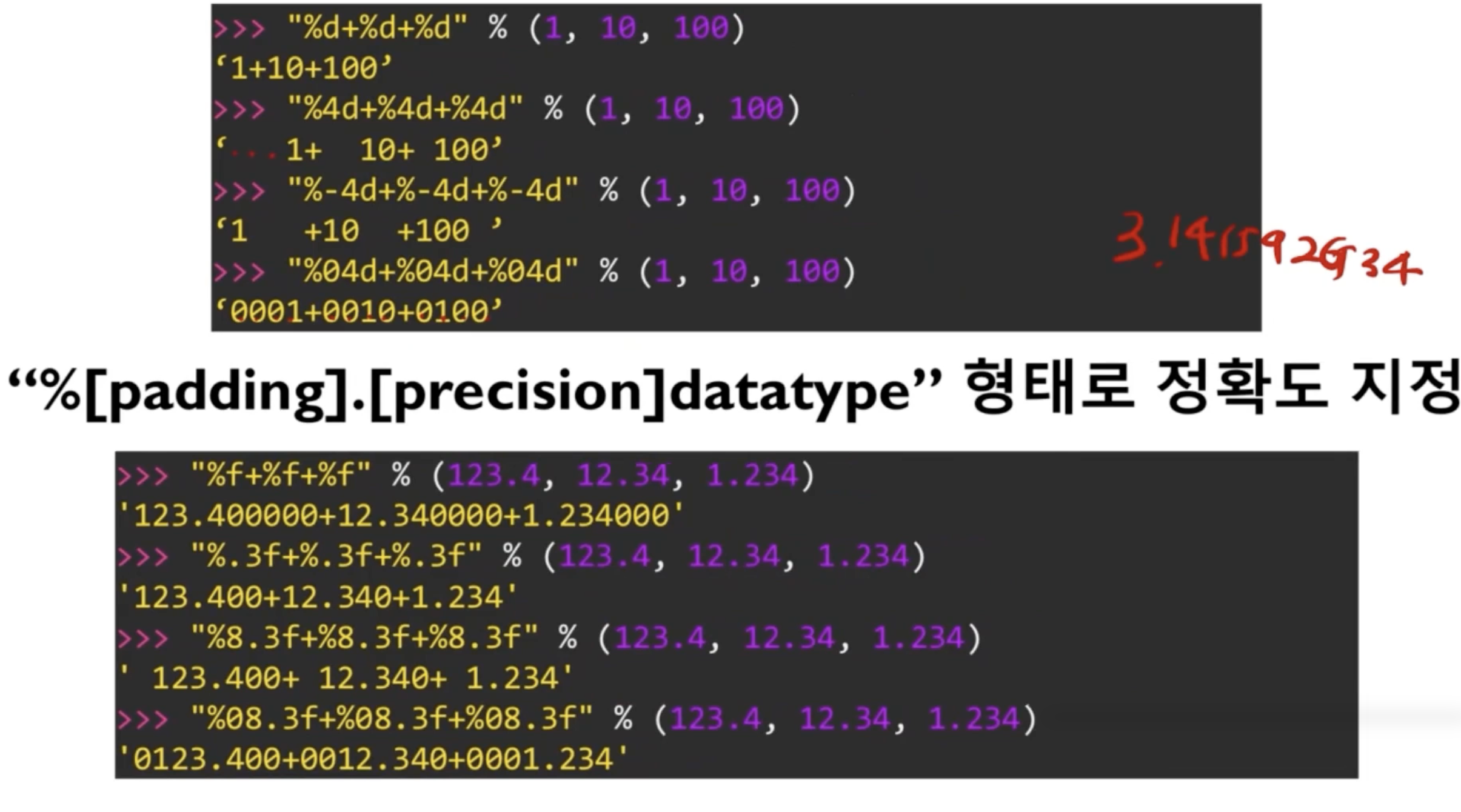
.format 함수 → 순서대로 들어간다는 특징, 순서 지정이 가능하다.
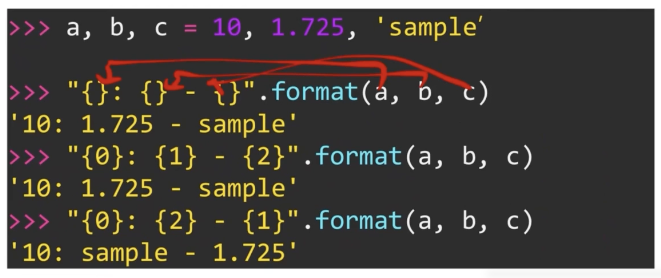
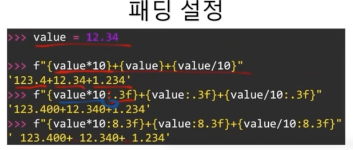
{0: 8.4f} : 8글자 들어가는 자리를 만드는데 소숫점 4글자까지 넣어라 라는 뜻

Naming도 가능하다.
print('%(first)5.2f - %(second)5.2f' %{"first": 10.2, "second": 5.62})
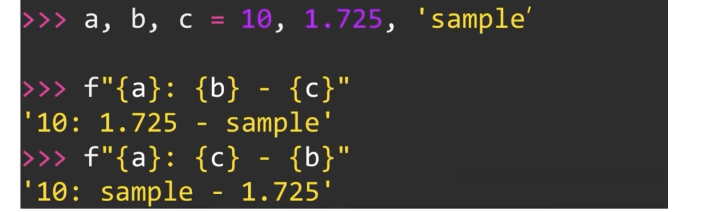
print('{first : 5.2f} - {second : 5.2f}'.format(first = 10.2, second = 5.62)F-string - f”{variable} 형태의 표현 : 파이썬 3.6부터 지원한다.
Finding Patterns
Dictionary
딕셔너리 = { 키 : 값 }
주의)
- 키 값에 list, set이 올 수 없다. (immutable - 불변) 객체 타입이 와야한다.
- 키 값은 중복 될 수 없다.
# 1. 딕셔너리 생성
d = {'a' : 123123}
# 2. 값 추가
d[999] = 10 # 숫차 키, 숫자 값
d['99'] = 111 # 문자 키, 숫자 값
d['BloackDMask'] = 'blog' #문자 키 , 문자 값
d['wow'] = [1,2,3,4,5] # 문자 키, 리스트 값
d[(1,2)] = "this is value" # 튜플 키, 문자 값
d[1] = (3,'a',5) # 숫자 키, 튜플 값
# 3. 값 접근
print(f"d["a"] = {d["a"]}")
# -> d["a"] = 123123튜플은 불변하는 타입이기 때문에 딕셔너리의 key가 될 수 있음. 리스트는 key는 될 수 없지만 value가 될 수 있음.
딕셔너리 관련 함수
1) in - 딕셔너리에 해당 키가 있는 가?
d = {'a' : 123123, 'b': "blog", 'c': 3333}
if 'b' in d:
print("있음")
else:
print("없음")2) keys - 딕셔너리 키 뽑기
d = {'a' : 123123, 'b': "blog", 'c': 3333}
print(d.keys())
# -> dict_keys(['a','kim','b','c',123])
for k in d.keys():
print(f'key: {k}')
# -> key : a \n key : b \n key : c3) values - 딕셔너리의 값 뽑기
d = {'a' : 123123, 'b': "blog", 'c': 3333}
print(d.values())
# -> dict_values([123123,'blog',333])
for v in d.values():
print(f'value : {v}')
# -> value : 123123 \n value : "blog" \n value : 33334) items - 딕셔너리 키, 값 합쳐서 전부 뽑기
d = {'a' : 123123, 'b': "blog", 'c': 3333}
print(d.items())
# -> dict_keys([('a' : 123123), ('b': "blog"), ('c': 3333)])
for m in d.items():
print(f'한쌍 씩 : {m}')
print(f'한쌍 씩 : {m[0]}')
print(f'한쌍 씩 : {m[1]}')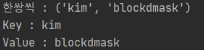
5) get - 딕셔너리 키로 값 얻기
d = {'a' : 123123, 'b': "blog", 'c': 3333}
r1 = d.get('ccc')
print(r1)
# -> None
r3 = d.get('a')
print(r3)
# -> 123123참고 !) 딕셔너리.get() 함수는 이렇게 값이 없을때는 None을 반환
그런데 딕셔너리[]로 접근할때 값이 없으면 에러남
6) del - 딕셔너리에서 키, 값 한 쌍 지우기
d = {'a' : 123123, 'b': "blog", 'c': 3333}
print(d)
# -> {'a' : 123123, 'b': "blog", 'c': 3333}
del d['a']
del d['b']
# del d['ga']
# -> 없는 키를 지우라고 하면 error
print(d)
# -> {'c': 3333}7) clear - 딕셔너리 키, 값 모두 지우기
d = {'a' : 123123, 'b': "blog", 'c': 3333}
print(d)
d.clear()
print(d)
class Contact:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def print_info(self):
print(f"이름 : {self.name}, 나이 : {self.age}, 성별 : {self.gender}")
d = {'kim' : Contact('kim', 29, 'man')}
p1 = Contact('park',43, 'woman')
d[p1.name] = p1
p2 = Contact('blockmask', 20, 'man')
d['blockmask'] = p2
d['lee'] = Contact('lee', 35, 'woman')
print('1. Keys')
print(d.keys())
print()
print('2. Values')
for k in d.keys():
d[k].print_info()
리스트 - list
list_data.insert(a,b) -> 특정 위치에 값 추가
list_data.remove(x) -> 특정 값 제거
list_data.index(max(array))
# -> 가장 큰 수의 인덱스를 반환해준다.
max(list_data), min(list_data)
list_data.append(숫자, 문자)
list_data.reverse()
# -> 리스트 내부 요소를 뒤집는다.
list_data.sort()
# -> 내부 요소 정렬 기본 오름차순 숫자 문자 썪이면 불가능
list_data.count(숫자 or 문자)
# -> 전달 받은 숫자 or 문자 갯수를 카운트해서 반환
list_data.index(x)
# -> x로 전달받은 위치 값 반환
list_data.clear()
#list 중복값 제거하는 방법
list_data = list(set(list_data))정규 표현식 (Regular Expression)
정규표현식 정리 - https://hamait.tistory.com/342
- 특정한 규칙을 가진 문자열의 집합을 표현하는데 사용하는 형식 언어
- 많은 텍스트 편집기와 프로그래밍 언어에서 문자열 검색과 치환에 활용

정규표현식 → 언어 하나 더 배우는 정도 …. 문법이 매우 방대하다.
isinstance
for i in range(len(vecs)):
if (isinstance(alpha, list)):
alpha_i = alpha[i]True, False값으로 반환된다. 함수를 만들때 for loop돌리면서 사용할 수 있음
IO
input() - 표준 입력, string 으로 들어오기 때문에 숫자로 바꾸기 위해서
var = input()
var = int(var) 방식을 사용한다.
a = input("입력을 넣어주세요 : ")
print(f"입력된 값 : {a}") #f스트링 사용해서 표현콘솔창에서 표준 입출력을 이용한다면
python lecture11.py < output.txt # 출력 - 파일이 하나 생김
python lecture11.py > input.txt
python lecture11.py <input.txt> output.txt
| pip 하나의 출력값을 다른 곳에 넣어주는 형태
conda list | grep numpy -> 콘다 리스트에서(출력, 다시입력값) 넘파이 버전 알려달라는 것File Descriptor - open내장 함수 사용
fd = open("<파일이름>", "<접근 모드>", encoding = "utf9")
contents = fd.read() # 파일 전체 읽기
fd.close()
print(contents)
file descriptor 닫는 것을 깜빡할 때가 많음
- context manager 형태로 사용 → 자동으로 닫아줌
- with as 구문
with open("text.txt", "r") as fd: #Context Manager
contents = fd.read() # 파일 전체 읽기
print(contents)- 줄 단위로 잘라서 읽기 \n가 사라지는 건 아니다.
with open("text.txt", "r") as fd:
for sentence in fd: #readline() 활용도 가능하다.
contents.append(sentence)
print(contents)
#전체 읽어 줄단위로 잘라서 반환 -> readlines
# string List가 반환
with open("text.txt", "r") as fd:
contents = fd.readlines()
print(contents)File write
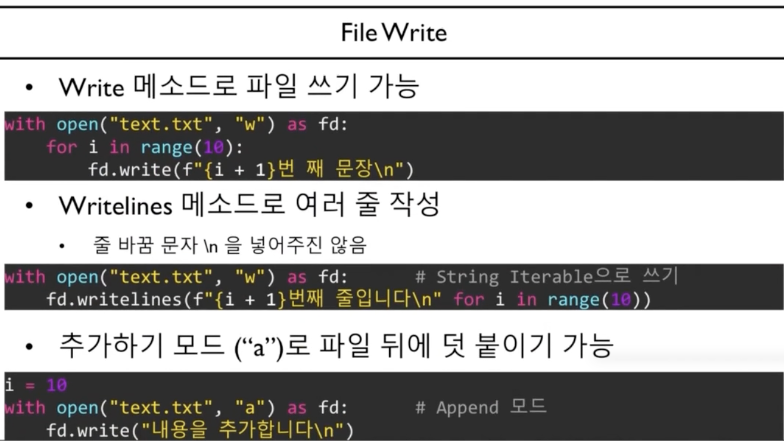
Directory
os 라이브러리로 플랫폼 독립적인 플랫폼 생성 가능
import os
os.mkdir("test") #폴더 하나 만들기, 이미 있으면 에러 발생
if not os.path.isdir("test"): #폴더가 있는지 확인
os.mkdir("test") #폴더가 아니거나 없으면 False
#하위 폴더 한번에 만들기, exist_ok 옵션으로 이미 있으면 무시할지 확인
os.makedirs("test/a/b/c", exist_ok=True)Listing Directory
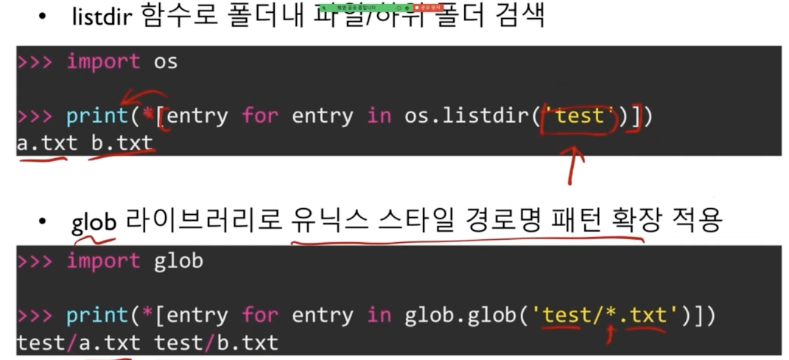
Pickle
파이썬 객체를 그대로 젖아하고 싶다면 → pickle
- 객체를 직렬화(serialize)하여 파일로 저장
CSV - Comma Separate Values
표 데이터를 프로그램에 상관없이 쓰기 위한 데이터 형식
- 필드를 쉼표(,)로 구분한 텍스트 파일
- 탭(TSV), 공백(SSV) 등으로 구분하기도 함
- 통칭하여 Character Separated Values (CSV)라 지칭
readlinees로 읽을 수 있음 ← 구현이 귀찮음

import csv
with open('text.csv', 'r') as fd:
reader = csv.reader(fd, #File Descriptor, 필수
delimiter=',', #구분자, 기본: ,
quotechar='"', #텍스트 감싸기 문자, 기본 : "
quoting= csv.QUOTE_MINIMAL # parsing 방식, 기본: 최소 길이
)
for entry in reader: # 한 줄 씩 순환
print(entry) # Row를 List형태로 출력Writing csv ‘r’ → ‘w’로 변환 및…
Json
웹 언어인 javascript의 데이터 객체 표현 방식
- 자료 구조 양식을 문자열로 표현
- 각광 받는 자료구조 형식
import json
with open('test.json', 'r') as fd:
data = json.load(fd) #json 읽기
XML - 불편함..
Beauriful Soup
가장 많이 쓰는 parser중 하나, 인터넷에서 크롤링할때 많이 사용한다.
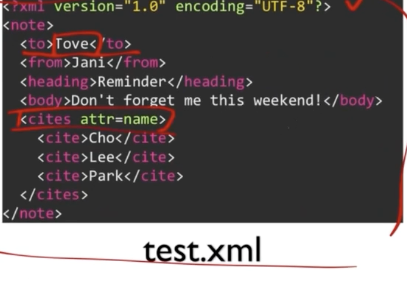
from bs4 import BeautifulSoup
with open("test.xml", 'r') as fd:
soup = BeautifulSoup(
fd.read(), #Parsing할 문자열
'html.parser' #사용할 Parser
)
to_tag = soup.find(name='to') #문서 전체에서 'to'태그 찾기
print(to_tag.string) #"to" 태그 내 문자열 출력
for cite_tag in soup.findAll(name = 'cite'): # "cite" 태그 모두 찾기
print(cite_tag.string)
cites_tag = soup.find(name = 'cites') # "cites" 태그 찾기
print(cites_tag.attrs) # "cites" 태그의 모든 속성
print(cites_tag['attr']) # "attr" 속성 값 참조
cites_tag = soup.fin(attrs = {'attr':'name'}) #속성으로 태그 찾기
for cite_tag in cites_tag.find_all(name='cite'): # 태그 내 검색
print(cite_tag.string)zip
문자열의 길이가 다를때는 주의!!!
짧은 문자열을 기준으로 나머지 값은 버림
numbers = [1,2,3]
letters = ["A","B","C"]
for pair in zip(numbers, letters):
print(pair)numbers = [1,2,3]
letters = ["A","B","C"]
for pair in zip(numbers, letters):
print(pair)for number, upper, lower in zip("12345","ABCDE","abcde"):
print(number, upper, lower)unzip
numbers = (1,2,3)
letters = ("A","B","C")
pairs = list(zip(numbers, letters))
print(pairs)a,b = zip(*pairs) # unpacking
print(a)
print(b)사전 변환
keys = [1,2,3]
values = ["A","B","C"]
dict(zip(keys, values))range
for i in range(5):
print(i)
-> 0,1,2,3,4
for i in range(1,5):
print(i)
-> 1,2,3,4
for i in range(1,5,2):
print(i)
-> 1,3Map
list(map(함수, 리스트))
tuple(map(함수, 튜플))a = [1.2,2.5,3.7,4.6]
for i in range(len(a)):
a[i] = int(a[i])
print(a)
-> [1,2,3,4]
a = list(map(int,a))백준
#두개를 입력받은 후(10 20) 나누다.
a,b = map(int, input().split())
print(a*b)문자열 뒤집기
# slice
string = 'hello world!'
print(string[::-1])
#reversed()
reversed_str = "".join(reversed(string))
print(reversed_str)
#for loop
reversed_str = ""
for i in string:
reversed_str = i + reversed_str
print(reversed_str)평균, 최빈값, 중앙값, min, max,
import numpy
# 평균
numpy.mean(x)
# 중간 값
numpy.median(x)
# 최빈값
from scipy.stats import mode
mode(x)
#최솟값 - x는 리스트형태
min(x)
#최댓값 - x는 리스트형태
max(x)sort(), sorted()
list 정렬
숫자 리스트.sort() → 오름차순 정렬 (작은수부터 큰 수 방향)
소문자리스트.sort() → a,b,c,d 순서
대소문자.sort() → 대문자부터 나오고 소문자가 나옴 (아스키 코드이기 때문)
내림차순 정렬을 위해서는
list.sort(reverse = True) → 내림차순정렬
reverse 의 default값은 False
절댓값을 넣어줄 수 도 있음
nums.sort(reverse = True, key = abs)
주의) sort의경우 새로운 리스트를 생성하지 않고 기존 리스트 내의 원소 간에 순서를 바꿔서 정렬해준다.
sorted() → list, tuple, set, string 모두 가능함 단, list반환 됨
sorted(리스트)
nums = sorted([3,5,2,1,4])
print(nums)
# -> [1,2,3,4,5]string반환을 하려면 → join() 함수 사용
a = ''.join(sorted("3,5,2,1,4"))
print(a)
# -> '12345'remove(), pop(), del
List에서 사용가능
x = [2,4,6,2,3,4,8,2]
y = [’A’, ’B’, ’V’, ’D’, ’E’]
del x[0]
print(x) # 한개의 요소를 삭제함
del y[3:]
print(y) # 여러개 요소를 삭제함
x.remove(2)
print(x) # 삭제하려는 인덱스가 아닌 값을 직접 입력하는 함수.
#삭제하려는 값이 리스트 내 2개 이상 존재한다면 앞에 있는 값을 삭제한다.
# pop()의 경우 리스트이 인덱스를 받아서 삭제하는 함수
pop_x = x.pop(2)
print(x) # -> [2, 4, 2, 3, 4, 8, 2]
print(pop_x) # -> 6string → list, list → string, int → string, list
# string -> list
my_string = 'laksjdflksj'
answer = []
answer = list(my_string)
print(answer) # -> 리스트 형태로 출력
#list -> string ( list 값이 string 형일 때 )
string_answer = ''.join(answer)
print(string_answer) # -> string형태로 출력
#list -> string (list 값이 int형일 때)
answer = [1,2,3,4,5,6]
print(''.join(str(e) for e in answer))
#int -> string
a = 1234
b = str(a)
c = sum(map(int, b)) # 각 자리 숫자를 더하는 방법
# int -> list
answer = list(map(int, list(str(a))))
replace - 문자열에서 사용
a = 'hello world'
a = a.replace('hello','') # 꼭 다시 저장해줘야 한다.
print(a)globals() → 변수 자동 생성
for i in range(0,10):
globals()["s{}.format(i)] = i
print(s1, s2) # -> 1,2set - 집합연산
s1 = set([1,2,3,4,5])
s2 = set([4,5,6,7,8])
print(s1&s2) #교집합
print(len(s1&s2)) # 집합 길이가 나온다.
print(s1|s2) #합집합
print(s1-s2) #차집합
s3 = list(s1&s2), type(s3) -> 리스트 변환 가능파이썬 집합 add, update, remove, discard, pop, clear, in, len
- add - 요소 추가
s = {1,2,3}
s.add('blockmask')
s.add('blockmask') # 중복값
s.add(4)
-> {1,2,3,'blockmask', 4} => 집합에서 중복 값을 넣어도 무시된다.(오류안남)- set update - 요소 여러개 추가 → 함수안에 집합형태인 {} 가 필요함
s = {1,2,3}
s.update({'a','b','c'})
-> {1,2,3,'a','b','c'}
- set remove - 특정 요소 제거 → set내부에 값이 없으면 오류
s = {'kim', 'lee', 'park', 2, 3, 4}
print(f'집합 : {s}')
s.remove("kim")
print(f'집합 : {s}')
# 에러 발생
# s.remove("kim")
# print(f'집합 : {s}')- set discard - 특정 요소 안전하게 제거. → 집합 내부에 값이 없어도 오류 안남
s = {'kim', 'lee', 'park', 2, 3, 4}
print(f'집합 : {s}')
s.discard("lee")
print(f'집합 : {s}')
s.discard("lee")
print(f'집합 : {s}')- set clear - 모든 요소 제거
s = {'e', 'f', 'g', 11, 12, 13}
s.clear()
print(s) -> set()- set in - 내부에 요소가 있는지 확인 ( in 의경우 문자, 리스트, 튜플, 딕셔너리 에 사용가능)
s = {'a', 'b', 'c', 'd'}
if 'a' in s:
print('집합 s에 내부에 a가 존재한다')- set len - 집합 길이 확인
s = {1, 2, 3, 1, 2, 3}
print(f'집합의 길이 : {len(s)}'[python] 파이썬 set (집합) 자료형 정리 및 예제
dictnionary - items()
car = {"name" : "BMW", "price" : "7000"}
print(car.items()) # -> dict_items([("name" : "BMW"), ("price" : "7000")])
for key, val in car.items():
print("key : {} value : {}".format(key,val))
#-> key : name value : BMW
#-> key : price value : 7000
map(), filter()
- 차이점
map() 메서드는 배열 내의 모든 요소 각각에 대하여 주어진 함수를 호출한 결과를 모아 새로운 배열을 반환합니다. filter () 메서드는 주어진 함수의 테스트를 통과하는 모든 요소를 모아 새로운 배열로 반환합니다.
map(적용시킬 함수, 적용할 요소들)
def add_1(n):
return n+1
target = [1,2,3,4,5]
result = map(add_1, target)
print(result)
# -> <map object at 0x7f2a91602550>
print(list(result))
# -> [2, 3, 4, 5, 6]
a = map(str, target)
print(list(a))
# -> ['1', '2', '3', '4', '5'] 문자형으로 나온 것
result = map(lambda x : x+1, target) # 함수 재사용 목적이 없을때 lambda 사용
print(list(result))filter(적용시킬 함수, 적용할 요소들)
target = [1,2,3,4,5,6,7,8,9,10]
result = []
def is_even(n):
return True if n % 2 == 0 else False
for value in target :
if is_even(value):
result.append(value)
print(result)
# -> [2, 4, 6, 8, 10]
result = filter(is_even, target)
print(list(result))
# -> [2, 4, 6, 8, 10]
result = filter(lambda x : x%2==0, target)
print(list(result))
# -> [2, 4, 6, 8, 10]
isdigit() - 숫자 판별함수, isalpha() - 문자 판별
문자열.isdigit() 이런식으로 사용하는 메서드
str.isdigit()
# -> 출력값은 true or false
str.idalpha()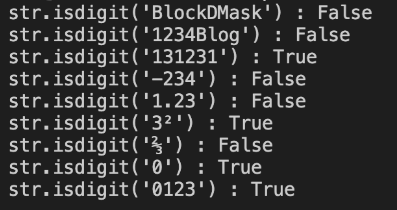
try - except예외 처리
try:
age = in(input('나이를입력하세요 : '))
except:
print('입력이 정확하지 않습니다.')
else:
if age <= 18:
print('미성년자입니다')
else
print('환영합니다')except를 여러개 사용해서 오류처리 할 수도있다.
try:
a = [1,2]
print(a[3])
4/0
except ZeroDivisionError:
print("0으로 나눌 수 없습니다.")
except IndexError:
print("인덱싱 할 수 없습니다.")Raise 구문
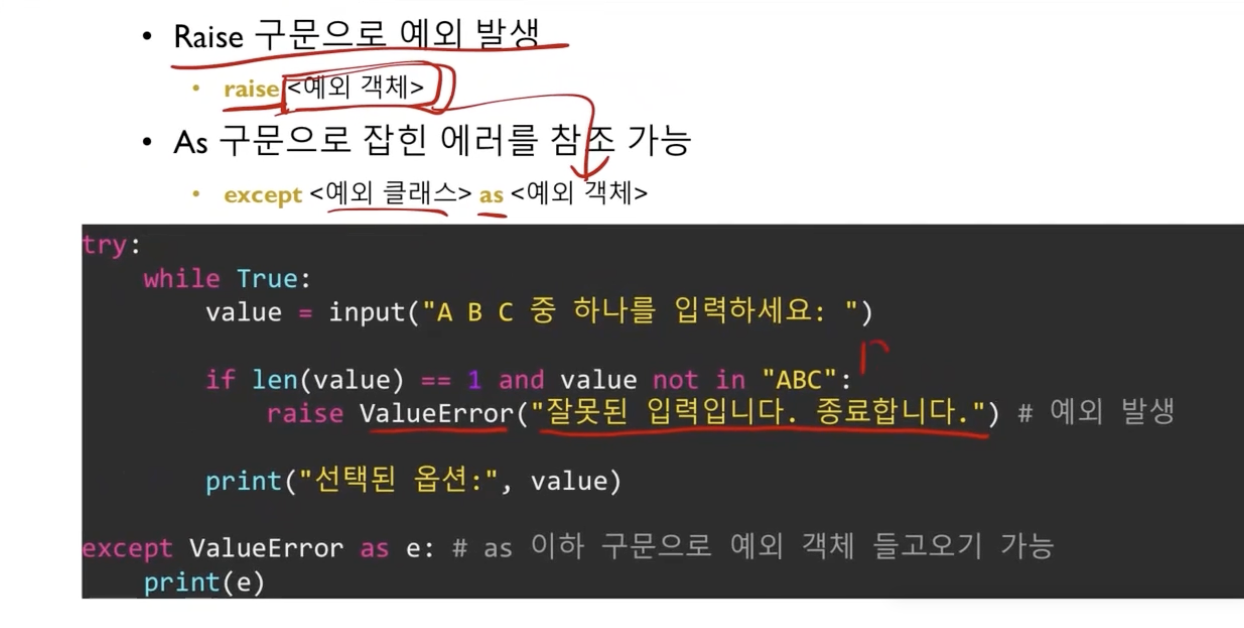
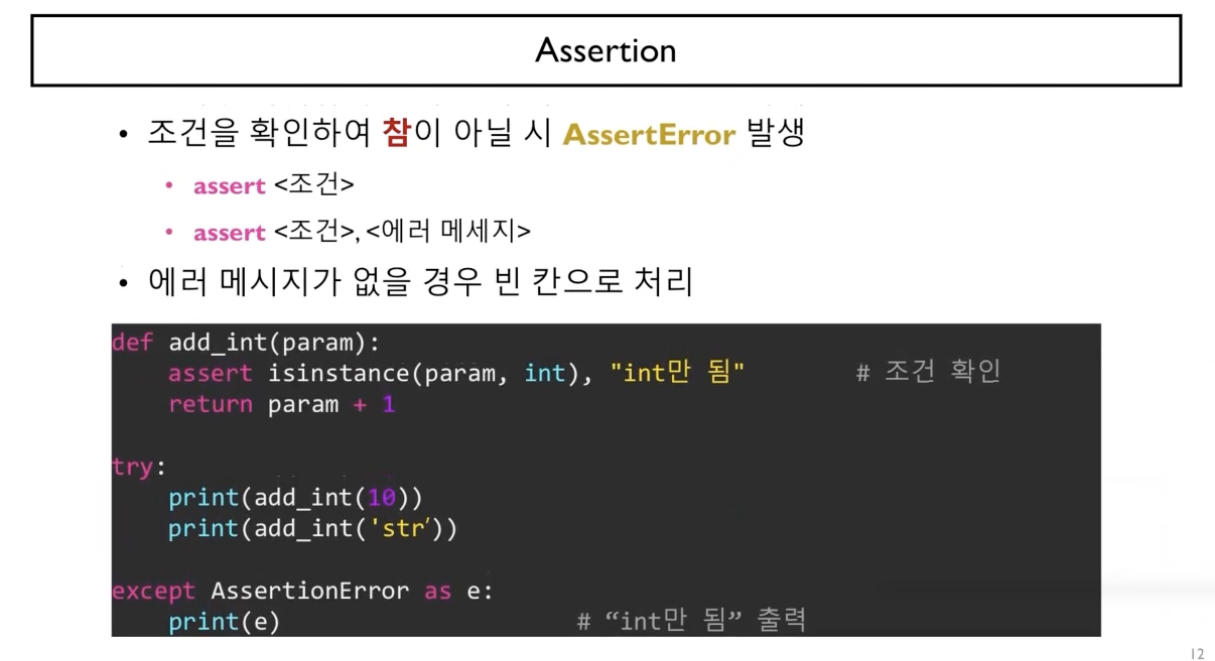
assert
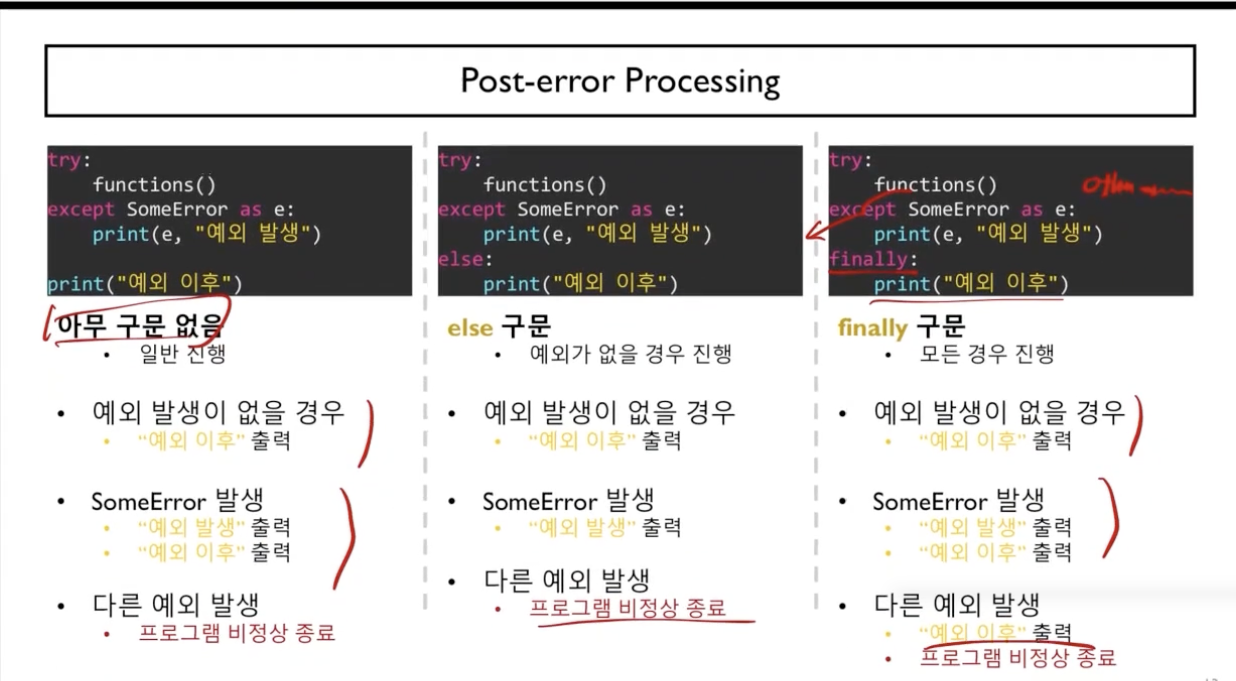
try - except - else - finally
list 중복 정리 방법
- set() 사용 - 순서를 고려하지 않음
- for 문 사용
answer = []
my_string = 'We are the world'
my_string = list(my_string)
for value in my_string:
if value not in answer:
answer.append(value)
print(''.join(answer))- dict.fromkeys() 사용
array = ["F", "D", "A", "C", "A", "C", "F", "B", "C", "E", "D", "C", "F", "A", "B", "E", "F", "E"]
result = list(dict.fromkeys(array))
print("중복 제거 전 : ", array)
print("중복 제거 후 : ", result)
# Output
# 중복 제거 전 : ['F', 'D', 'A', 'C', 'A', 'C', 'F', 'B', 'C', 'E', 'D', 'C', 'F', 'A', 'B', 'E', 'F', 'E']
# 중복 제거 후 : ['F', 'D', 'A', 'C', 'B', 'E']split
# 문자열.split('구분자',분할횟수, )
b = []
a = "1 2 Z 3"
b = a.split(' ')
print(b)
# -> ['1','2','Z','3']enumerate
score = [[80, 70], [70, 80], [30, 50], [90, 100], [100, 90], [100, 100], [10, 30]]
dict, average = {}, [sum(i)/2 for i in score]
for index, avg in enumerate(sorted(average, reverse = True), start = 1):
# -> enumerate index가 1부터 시작하게 된다. sorted(---,reverse = Ture)는 오름차순 정렬