중복 제거
중복 제거 연산의경우 해싱이나 외부정렬알고리즘을 통해 구현 가능하다. 해싱의 경우 중복된 레코드들이 같은 버킷에 모이고, 정렬의 경우는 인접한 위치에 모이기 때문에 해싱과 정렬 이후 전체를 탐색하면서 중복을 제거할 수 있다. 특히 외부정렬 알고리즘을 사용하는 경우, 런을 만드는 단계나 중간 merge-step에서도 중복제거가 가능하다.
Projection
Projection연산은 테이블에서 특정 컬럼을 추출하는 연산으로, 각 튜플을 순회하면서 특정 컬럼을 추출한 다음 중복을 제거한다.
집계함수
SQL이 지원하는 공식적인 집계함수는 AVG, SUM, MIN, MAX, COUNT 다섯가지이다. 일반적으로 집계함수는 GROUP BY와 함께 쓰이는데, 이때 각 레코드들을 그룹화할 때는 중복제거와 비슷하게 해싱또는 외부정렬알고리즘이 사용된다. 따라서 집계함수는 해싱이나 정렬을 통해 레코드를 그룹화한 뒤 각 그룹에 대해 집계하는 방식으로 동작한다.
중복제거와 마찬가지로 집계함수 또한 외부정렬을 사용하는 경우 런 생성단계 혹은 중간 merge 단계에서 각 런에 대한 집계값들을 유지하면 최적화가 가능하다. count, min, max, sum연산의 경우 각 런별 집계값을 유지하고, avg의 경우 각 런별 sum과 count값을 유지한 뒤 마지막에 avg를 계산하면 최적화가 가능하다.
집합 연산
SQL의 집합연산은 UNION, INTERSECT, EXCEPT가 있다. 기본적으로 집합 연산은 중복이 제거되어야 하므로 역시 해싱이나 외부정렬알고리즘을 사용하여 연산을 수행한다.
정렬을 사용하는 경우는 merge-join과 비슷하게 결과를 one pass scan으로 탐색하면서 각 작업을 수행할 수 있다.
해싱을 사용하는 경우 해시조인과 같이 각 테이블을 파티션으로 나누는데, 이때 해시조인에서 join attribute만을 해시함수에 적용시켰던 것과 다르게 튜플의 모든 원소가 같은지 확인해야 하기 때문에 튜플 전체를 해시함수에 넣어 파티션을 나눈다. 다음으로는 build input에 대해 인 메모리 해시인덱스를 구성하고 작업을 처리한다.
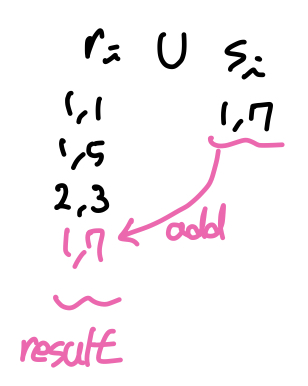
- Union
- probe input의 레코드가 해시 인덱스에 없으면 해싱하여 인덱스에 추가한다.
- probe input의 한 파티션을 모두 탐색했으면 해시 인덱스에 남아있는 레코드들을 결과 페이지에 기록한다
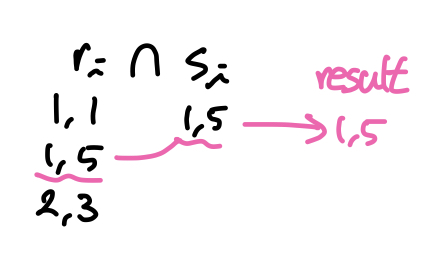
- Intersect
- probe input의 레코드가 해시 인덱스에 있으면 결과 페이지에 기록한다.
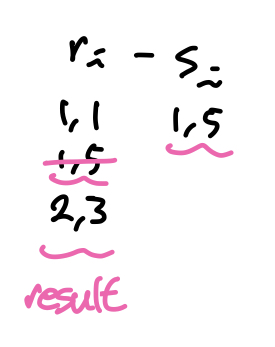
- Except
- probe input의 레코드가 해시 인덱스에 있으면 인덱스에서 해당 레코드를 삭제한다.
- probe input의 한 파티션을 모두 탐색했으면 해시 인덱스에 남아있는 레코드들을 결과 페이지에 기록한다
Evalutaion of Expressions
Expression tree를 evaluation하는 방법은 크게 Materialization과 Pipelining으로 나눌 수 있다. 전자는 각 연산의 결과를 디스크에 기록한 뒤 다음 연산에서 다시 메모리로 올려 사용하는 방법이고, 후자는 연산의 결과를 다음 연산으로 전달하여 디스크에 I/O작업 없이 전체 연산을 수행하는 방법이다.
