Memory
메모리는 컴퓨터에서 수치, 명령, 자료 등을 기억하는 컴퓨터 하드웨어 장치를 가리킨다
Locality
지역성은 프로세서가 짧은 시간동안 동일한 메모리 위치에 반복적으로 접근하는 경향이다
일반적으로 용량이 크고 빠른 메모리는 가격이 비싸기 때문에 메모리의 지역성을 바탕으로 계층화한다. 지역성에는 두 종류가 있다
- Temporal locality : 시간적 지역성. 최근에 접근한 메모리에 접근하는 경향
- Spatial locality : 공간적 지역성. 접근한 메모리의 근처에 접근하는 경향
이를 토대로 메모리의 계층구조를 크게 3단계로 나눌 수 있다.
- SRAM : 캐시 메모리. 가장 빠르고 가장 비싼 메모리. 가장 적은 용량을 가진다
- DRAM : 메인 메모리. SRAM과 Disk의 중간성능, 가격, 용량을 가진다
- Disk : HDD, SDD. 가장 느리고 싸지만 가장 많은 용량을 가진다
즉, 모든 데이터를 디스크에 저장하고, 그 중 자주 사용하는 데이터는 DRAM으로 올리고, 그 중에서도 자주 사용하는 데이터를 SRAM에 올리는 방식으로 메모리를 구성하면 결과적으로 크고 빠른 메모리를 사용하는 것과 비슷한 효과를 낼 수 있다.
- Block : 데이터의 기본 단위
- Hit : 접근한 주소에 원하는 데이터가 있는 경우
- Miss : 접근한 주소에 원하는 데이터가 없는 경우. 하위 메모리에서 데이터를 불러와야 함
Cache
미래의 요청으로인해 데이터를 빠르게 제공하기 위해 데이터를 저장해 놓은 HW혹은 SW요소
즉, 캐시란 데이터를 빠르게 접근하기 위해 마련해 둔 임시 저장소로 CPU의 캐시 메모리 뿐만 아니라 Branch Prediction Buffer, Branch Target Buffer, Browse cache등 여러 종류가 있다.
그 중 캐시 메모리란 CPU에 가장 가까운 메모리로 가장 최근에 사용된 아이템들을 저장해두는 공간이다.
Direct mapped cache
Direct mapped cache란 각각의 메모리 공간에 직접적으로 매핑된 캐시이다. 캐시의 주소는 메모리블럭의 주소에 나머지연산을 취해 계산할 수 있는데, 메모리 주소의 하위비트가 캐시의 주소가 된다.
메모리에서 캐시로 데이터를 올릴 때, 데이터 뿐만 아니라 tag와 valid bits도 같이 저장하여 캐시의 상태를 표시한다.
- tag : 캐시에 저장된 데이터를 식별하기 위한 값으로, 메모리 주소의 상위비트가 저장된다
- ex) cache addr=001 & tag = 01 : 메모리의 01001주소의 데이터가 저장되어 있음
- valid bits : 캐시가 유효한 정보를 담고 있다는 것을 알려주기 위한 비트로, 유효한 정보가 담겨있으면 1, 그렇지 않으면 0으로 설정된다
캐시의 Block size가 miss rate에 미치는 영향은 다음과 같다
- 캐시 블럭의 크기가 커지면 공간적 지역성에 의해 miss rate를 줄일 수 있다.
- 하지만 캐시 블럭이 커지면 캐시에 저장되는 블럭의 수가 줄어들게 되어 경쟁이 심해지고, 결과적으로 miss rate가 증가할 수 있으며, miss 발생시 불러와야 할 블럭의 크기가 크기 때문에 miss penalty도 증가한다.
CPU에서 캐시에 데이터를 접근하는 과정은 다음과 같다.
- Cache hit : 1 clock cycle이 소모되고, 정상적으로 작동한다.
- Cache miss : 1회 이상의 clock cycle이 소모되고, CPU의 Control unit이 동작한다
- CPU pipeline 정지
- 하위 계층의 메모리에서 블럭을 복사
- 정지된 작업을 재개
- IF stage : fetch instruction
- MEM stage : access data
Cache Write
프로세서에서 메모리에 데이터를 새롭게 쓸 때, 하위 메모리에 데이터가 저장되는 시점에 따라 방법이 달라진다.
- Write-through : 캐시와 하위 메모리에 동시에 데이터를 저장한다.
- 장점 : 구현이 쉽고, 캐시와 메모리의 일관성이 보장된다
- 단점 : 느리다
- Write-back : 캐시에만 데이터를 저장하고, 캐시 블럭이 교체될 때 하위 메모리에 저장한다.
- 장점 : 캐시블럭의 교체가 없는 경우 빠르다
- 단점 : 일관성이 보장되지 않고, 구현이 어렵다
- Write-through with write buffer : write buffer를 도입하여 Write-through방식을 개선한 것
- 프로세서는 캐시와 write buffer에 데이터를 저장한다
- 프로세서는 작업을 계속 진행한다
- 메모리는 write buffer로부터 데이터를 업데이트 한다
- 단, 버퍼가 가득 찬 경우 프로세서는 버퍼에 공간이 생길때까지 작업을 중지해야 한다
또한, 이미 존재하는 메모리 주소에 데이터를 쓰려고 할 때, 캐시에 그 메모리의 주소가 없으면 Cache write miss가 발생한다
- Write-allocate : 메모리 블럭을 캐시로 불러온 뒤 write연산을 진행
- Write-around : 하위 메모리의 블럭에 데이터를 저장하기만 하고 캐시로 불러오지 않음
Cache Performance
프로그램의 성능에서 CPU time은 clock cycle과 clock period의 곱으로 나타낼 수 있다. clock cycle의 종류는 CPU가 소비하는 CPU execution clock cycle과 CPU가 Memory access를 기다리는 Memory-stall clock cycle로 나눌 수 있는데, 이 중 Memory-stall clock cycle은 주로 cache miss에 의해 발생한다. 따라서 cache miss를 줄이면 프로그램의 성능을 향상할 수 있다.
Associative cache
cache miss rate를 줄이기 위해 도입된 방법으로, direct mapped cache와 다르게 하나의 캐시에 여러 메모리 블럭이 저장될 수 있는 캐시이다.
- Fully associative cache : 원하는 위치에 메모리 블럭을 배치할 수 있는 캐시
- N-way set associative cache : 하나의 캐시에 N개의 블럭을 배치할 수 있는 캐시
- Direct mapped cache = 1-way set associative cache
- 추가적인 비교연산이 들어가기 때문에 더 비싸다
- N이 증가할 수록 miss rate가 줄어들지만 가격이 증가한다
associative cache에서 캐시 블럭을 교체해야하는 상황이 오면 여러 블럭들 중 하나를 선택해야 하는데, 먼저 유효하지 않은 블럭이 있다면 우선적으로 교체하고, 모든 블럭이 유효하다면 아래 두 방법중 하나를 선택한다.
- LRU(Least-Recently Used) : 가장 오래 사용되지 않은 블럭을 교체
- Random : 무작위로 블럭을 선택하여 교체
Multi-level cache
캐시 또한 계층을 나누어 좀 더 효율적으로 사용할 수 있다.
- L-1 Cache : CPU에 가깝게 배치. 가장 빠르지만 용량이 작음
- clock period를 줄이기 위해 hit time을 최소화 하도록 설계
- cache size와 block size를 줄여 hit time 과 miss penalty를 최소화
- L-2 Cache : CPU에 조금 멀게 배치. L-1 Cache miss발생시 접근. 메모리와 L-1캐시의 중간단계
- 메인 메모리에 접근하는 것을 방지하기 위해 miss rate를 최소화 하도록 설계
- cache size를 늘려 miss rate를 최소화
Virtual Memory
캐시의 도입으로 대용량의 빠른 메모리를 사용하는 효과를 낼 수 있지만 완벽한 캐시를 구현하는 것은 불가능하기 때문에 결국 메인 메모리에 접근할 수 밖에 없고, 모든 데이터는 디스크에 저장되기 때문에 메인 메모리의 용량은 충분하지 않다. 따라서 메인 메모리는 디스크의 캐시로서 작동하게 된다.
그런데 다중 프로세스 환경에서 여러개의 프로세스들은 동시에 메모리에 접근하기 때문에 어떤 프로세스가 실행되는지에 따라 프로세스가 사용가능한 메모리의 양, 프로세스가 사용중인 데이터의 주소, 데이터의 물리적 위치등이 동적으로 변한다. 또한, 악성 프로세스가 다른 프로세스의 메모리 주소에 접근을 시도할 수 있는데, 이러한 문제들을 방지하기 위해 Virture Memory가 등장하게 되었다.
가상 메모리란 각각의 프로세스에게 대용량의 메모리를 독점적으로 사용하는 것과 같은 효과를 주는 기술로, CPU와 OS에서 가상 메모리와 메인 메모리, 디스크 사이의 매핑관계를 관리한다.
가상 메모리의 도입으로 다음과 같은 효과를 얻을 수 있다.
- 다른 프로세스가 메모리를 사용하는 것에 대한 고려를 하지 않아도 되기 때문에 개발과정이 단순해진다
- 가상 메모리 주소는 물리적 주소와 직접적으로 매핑되어있고, OS만 이 정보를 관리하기 때문에 프로세스가 다른 프로세스의 데이터에 접근하는 것을 막을 수 있다.
가상 메모리 기술과 관련된 용어는 다음과 같다.
- Page : 가상 메모리에 저장되는 정보의 최소단위
- Page fault : 요청한 페이지가 메인 메모리에 없는 경우
- Virtual address : 데이터의 가상 메모리에서의 주소
- Physical address : 데이터의 메인 메모리에서의 주소
- Disk address : 데이터의 디스크에서의 주소
Cache miss와 마찬가지로 가상 메모리에서 Page fault가 발생하면 디스크에서 메모리로 데이터를 불러와야 하는데 이 경우 많은 클락사이클이 소모된다. 따라서 프로그램의 성능 향상을 위해서는 가상 메모리의 Page fault rate를 낮추어야 한다.
Address Translation
가상 메모리에서 page는 virtual address로부터 physical address 혹은 disk address로 매핑되어있다. 이때 Page fault rate를 낮추기 위해 Fully associative placement가 사용된다.
- Fully associative placement : 하나의 page에 메인 메모리 혹은 디스크의 모든 영역이 매핑 가능한 방법
가상 메모리 주소를 물리 메모리 주소로 번역하는 과정에서 매핑정보가 보관되는 테이블을 Page table이라고 한다
- Page table : 가상 메모리 주소와 물리 메모리 주소가 매핑돈 정보가 저장된 테이블
- virtual page number로 인덱싱(virtual page number -> physical page number)
- valid bit : 찾고자 하는 page가 메모리에 존재하는지 표시.
- valid bit == 1 : page가 메모리에 있는 경우 => PTE(Page Table Entry)에 메인 메모리상의 page number가 저장됨
- valid bit == 0 : page fault발생 => PTE에 디스크 상에서의 데이터의 위치 정보가 저장됨
- OS에 의해 관리되기 때문에 CPU는 단순히 메인메모리 혹은 디스크에 접근하기만 함
그런데, Page table 또한 메모리에 올라와있기 때문에, 가상 메모리에 대한 요청을 처리할 때 메모리에 접근할 수 밖에 없고, 성능이 저하될 수 있다. 이 문제를 해결하기 위해 TLB(Translate Lookaside Buffer)라는 추가적인 하드웨어를 도입한다.
- TLB : CPU내에서 PTE에 대한 캐시 역할을 하는 추가적인 하드웨어
TLB
TLB를 도입하여 가상 메모리를 사용하는 전체적인 흐름은 캐시의 종류에 따라 세가지로 나눌 수 있다.
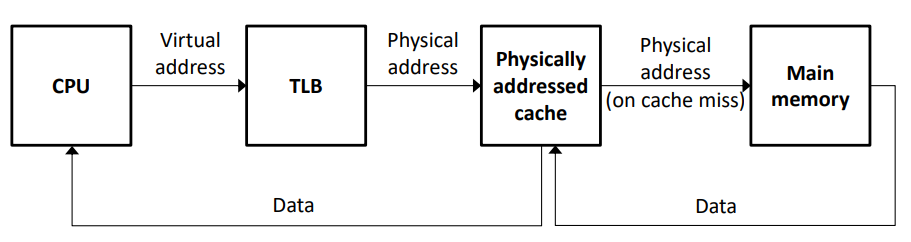
- PIPT(Physically-indexed & Physically-tagged) cache : 캐시의 인덱스와 태그 모두 물리적 주소를 저장함
- CPU는 가상 메모리 주소를 통해 먼저 TLB에 접근하여 물리적 주소를 알아낸 뒤, 캐시(Physically addressed cache)에서 데이터를 가져오고, 캐시에서 데이터를 찾지 못하면(cache miss) 메인 메모리에 접근하여 데이터를 가져와 캐시에 등록한다
- 장점 : 캐시에 물리적 주소가 저장되어 CPU는 어떤 프로세스가 어느 캐시블럭을 사용하는지 쉽게 알 수 있기 때문에 다중 프로세스 환경을 지원하기 쉽다
- 단점 : 모든 메모리 접근 요청에서 TLB를 거쳐야 하기 때문에 속도가 느리다
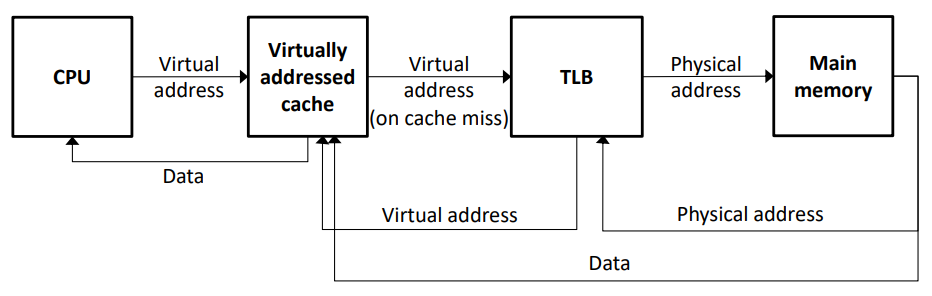
- VIVT(Virtually-indexed & Virtually-tagged) cache : 캐시의 인덱스와 태그 모두 가상 메모리 주소를 저장함
- CPU는 먼저 가상 메모리 주소를 통해 캐시(Virtually addressed cache)에서 데이터를 가져오고, 캐시에서 데이터를 찾지 못하면(cache miss) TLB에 접근하여 메인 메모리에서 데이터를 가져와 가상 메모리 주소와 함께 캐시에 등록한다
- 장점 : Cache miss가 발생한 경우에만 TLB를 사용하기 때문에 속도가 빠르다
- Aliasing으로 인해 다중 프로세스 환경을 지원하기 어렵다.
가상 캐시를 사용하는 경우 다중 프로세스 환경에서 Aliasing문제가 발생할 수 있는데, 구체적인 문제는 다음과 같다.
- Homonym : 서로 다른 프로세스에서 같은 가상 주소가 서로 다른 메모리 공간을 가리키는 경우
- Context switching이후 cache hit가 발생되었을 때, 캐시에 저장된 데이터가 현재 프로세스의 것인지 이전 프로세스의 것인지 구분할 수 없기 때문에 잘못된 Cache hit가 발생할 수 있다
- Virtually tagged방식의 캐시에서 발생
- Context switching : 다중 프로세스 환경에서 여러 프로세스가 하나의 CPU를 공유하기 때문에 CPU에서 주기적으로 프로세스의 상태(Context)를 저장하고 다른 프로세스를 실행하는 것
- Synonym : 서로 다른 프로세스에서 서로 다른 가상 주소가 같은 메모리 공간을 가리키는 경우
- 하나의 물리적 주소가 캐시의 서로 다른 위치에 존재할 수 있기 때문에 일관성이 깨질 수 있다. 즉, 한 프로세스가 메모리를 공유하는 다른 프로세스가 알지 못하는 상태로 캐시를 통해 데이터를 수정할 수 있다
- Virtually indexed방식의 캐시에서 발생
이러한 Aliasing 문제를 해결하기 위해서는 매 Context switching마다 캐시를 비우는 방법이 있는데, 이는 cache miss rate를 지나치게 높이기 때문에 다른 방법으로 위의 두 캐시를 합친 VIPT방식의 캐시가 등장하였다.
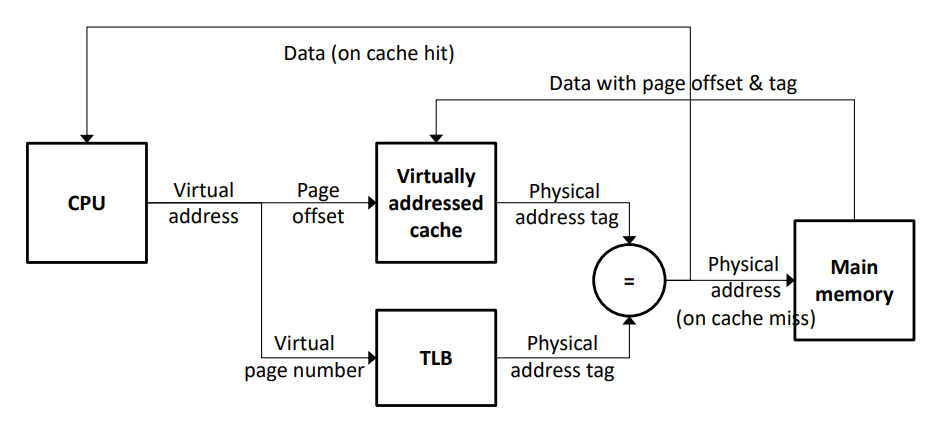
- VIPT(Virtually-indexed & Physically-tagged) cache : 캐시의 인덱스는 가상주소를 사용하고 태그에는 물리주소를 저장하는 방식
- synonym문제는 아직 존재하지만 homonym문제가 존재하지 않기 때문에 context switching마다 캐시를 비우지 않아도 된다
- TLB와 캐시가 동시에 병렬적으로 처리되기 때문에 빠르다
주로 multi-level cache에서 L1캐시는 VIPT방식을, L2캐시는 PIPT방식을 사용한다
TLB miss
TLB miss란 메모리에 요청한 페이지가 존재하는지와는 관계없이 TLB에 PTE가 존재하지 않는 경우 발생한다. TLB miss가 발생한 경우에는 소프트웨어적으로 처리되는데, MIPS에서는 다음과 같은 과정으로 처리된다
- 추가적인 clock cycle이 필요하기 때문에 Exception을 발생시킨다
- TLB miss handler code가 실행된다
- handler는 요청한 PTE를 TLB로 복사한다
- 명령을 재시작한다.
만약 4번에서 페이지가 메모리에 없으면 page fault가 발생하는데 page fault가 발생한 경우 다음과 같은 과정으로 처리된다
- Exception을 발생시킨다
- Page fault handle code가 실행된다
- 디스크에서 요청한 페이지를 찾는다
- 캐시에서 교체될 페이지를 선택한다
- 페이지를 메모리로 불러오고 page table을 업데이트한다
- 프로그램을 다시 실행할 수 있도록 설정한다
또한 page fault rate를 줄이기 위해서 replacement 정책으로 LRU를 채택할 수 있는데, 이를 구현하기 위해서 PTE에 reference bit를 도입한다.
- reference bit : 페이지를 참조하면 reference bit를 1로 바꾸고, OS는 주기적으로 reference bit가 0인 페이지를 캐시에서 지운다
Cache miss
cache miss가 발생하는 원인은 크게 3가지로 나눌 수 있다
- Complusory misses(= cold start misses) : 블록에 처음 접근할 때 발생
- Capacity misses : 캐시의 한정된 용량으로 인해 발생
- Conflict misses(= collision misses) : non-fully associative 캐시에서 각 set별 엔트리간의 경쟁으로 인해 발생
위와 같은 상황에서 cache miss rate를 낮추기 위해 캐시의 구조를 바꿀 수 있는데, 각 상황별 나타나는 효과는 아래와 같다
- 캐시의 크기를 늘린다
- Capacity misses가 줄어든다
- 데이터에 접근하는 시간과 비용이 증가할 수 있다
- Associativity를 늘린다(블럭 묶음의 크기를 늘린다)
- Conflict misses가 줄어든다
- 데이터에 접근하는 시간과 비용이 증가할 수 있다
- 블럭의 크기를 늘린다
- Complusory misses가 줄어든다
- miss penalty가 중가하고, 블럭의 크기가 너무 큰 경우 miss rate가 증가할 수 있다
