
서론
웹 스크래핑 서비스를 운영하다 보면 단순한 정적 데이터 수집을 넘어서 로그인이 필요한 사이트의 데이터를 수집해야 하는 경우가 많다. 이때 여러 API 요청이 하나의 로그인 세션을 공유해야 하는 상황이 발생한다.
예를 들어 다음과 같은 시나리오가 있다
- 1차 요청: 특정 사이트에 로그인
- 2차 요청: 로그인된 상태에서 사용자 대시보드 스크래핑
- 3차 요청: 동일 세션에서 추가 상세 정보 수집
단일 서버 환경에서는 이런 요구사항이 문제없이 동작했지만, 비즈니스 확장으로 인해 서버를 스케일 아웃하면서 새로운 도전과제가 생겼다.
분산 환경에서 동일 브라우저로 접근할까?
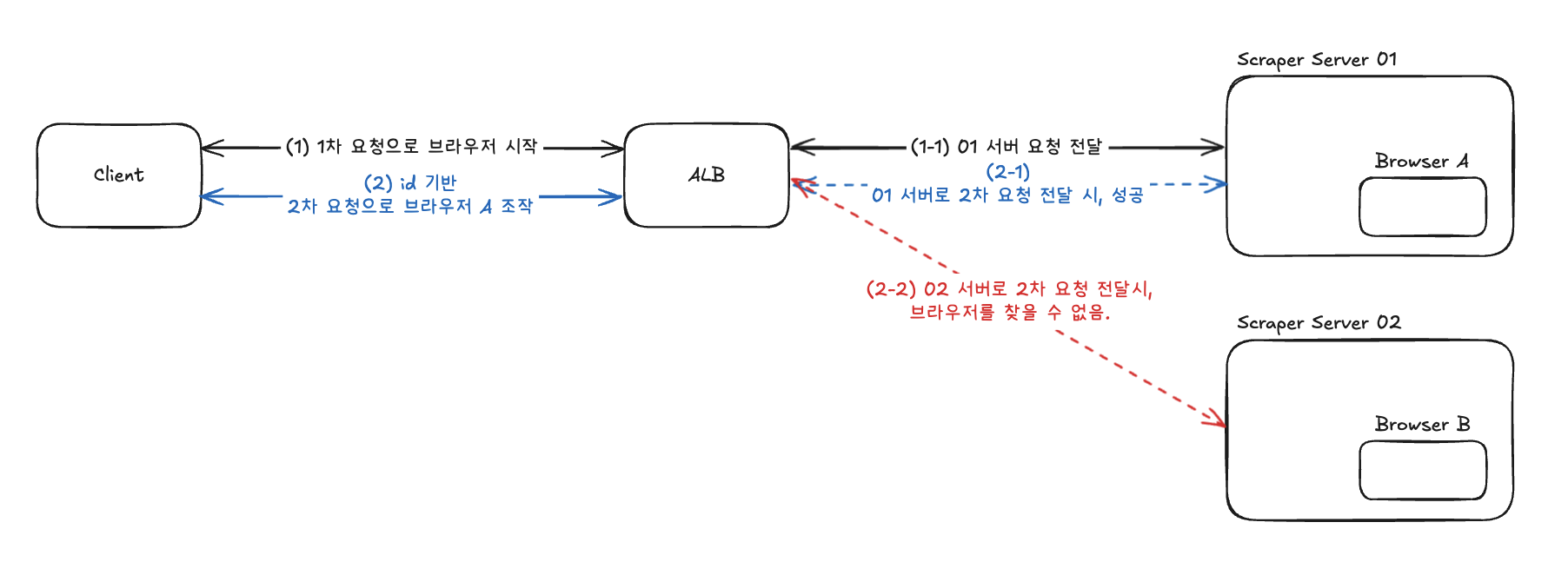
서버가 여러 대로 증가하면, 어떻게 특정 브라우저 세션에 대한 후속 요청이 해당 브라우저가 실행 중인 서버로 정확히 라우팅될 수 있는가라는 근본적인 문제가 발생한다.
단일 서버 환경: 모든 요청이 동일한 서버로 들어오므로 메모리에 관리되는 브라우저 세션에 접근 가능하다.
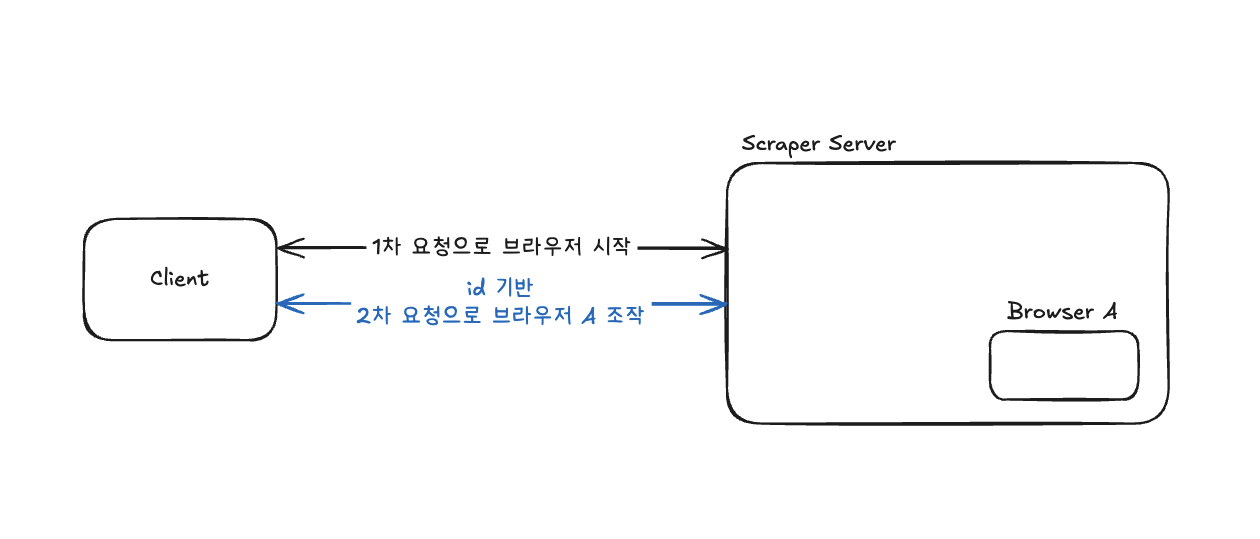
멀티 서버 환경: 로드 밸런서에 의해 요청이 여러 서버로 분산되는데, 후속 요청이 다른 서버로 라우팅되면 기존 로그인 세션을 찾을 수 없다.
쉽게 말해, "특정 사용자의 요청은 항상 같은 서버로 가야 한다"는 것에 대한 문제다.
이런 상황은 서버가 사용자별 정보를 메모리에 저장하고 있을 때 발생한다.
결국, 단일 서버로 사용할때는 문제가 없었으나, 고객사를 늘려야 하는 상황에 추가적으로 문제가 발생했다.
본론
문제의 근본 원인 분석
이 문제의 핵심은 각 서버가 브라우저 인스턴스의 상태를 로컬 메모리에서 관리하기 때문이다.
일반적인 웹 애플리케이션에서는 이런 문제가 발생하지 않는다.
데이터베이스 기반 애플리케이션의 경우에는 서버가 상태를 가지지 않는다.
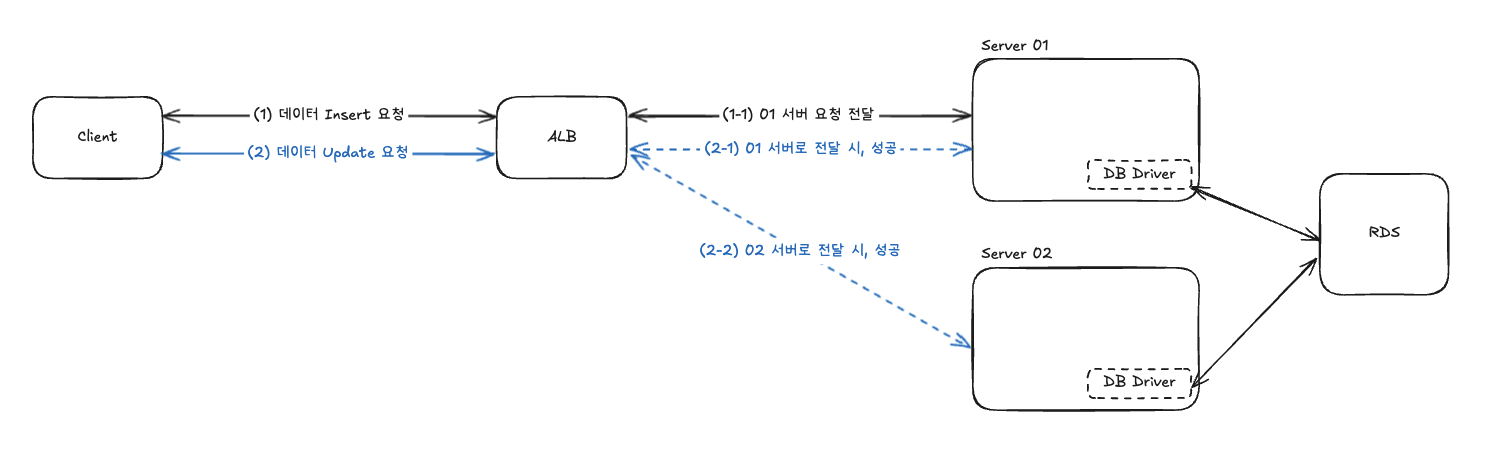
- 무상태성(Stateless): 각 서버는 DB 드라이버만 가지고 있을 뿐, 실제 데이터 상태는 중앙 DB에 저장된다
- 중앙집중식 상태 관리: 모든 서버가 동일한 DB에 접근하여 일관된 상태를 확인할 수 있다
하지만 브라우저 세션의 경우, 로그인 상태, 쿠키, 세션 스토리지 등의 정보가 브라우저 인스턴스 자체에 저장되어 있어 외부로 추상화하기 어렵다.
이 문제를 해결하기 위해 여러가지 접근 방법을 시도해보았다.
첫 번째 시도: 브라우저 드라이버 분리
DB 패턴을 모방하여 브라우저 관리를 중앙집중화하려고 시도했다. Playwright 서버를 별도로 두고 각 Scraper 서버가 이에 접근하는 구조를 고려했다.

시도 결과 Playwright 서버를 분리하는 것 자체는 좋은 아이디어였다. 브라우저를 실행하는 무거운 작업을 별도 서버에서 처리하니까 스크래핑 서버들의 부담이 크게 줄어들었기 때문이다.
하지만 핵심 문제인 "브라우저 공유"는 해결되지 않았다. Playwright에서 브라우저에 접근하는 방법은 크게 두 가지가 있다:
- 웹소켓(WS) 방식: 가장 일반적인 방법이지만, 각 연결마다 독립적인 브라우저가 생성된다. 즉, 서버 A에서 만든 브라우저를 서버 B에서 사용할 수 없다.
- CDP(Chrome DevTools Protocol) 방식: 포트 번호로 특정 브라우저에 직접 접근할 수 있다. 하지만 이 방법을 쓰려면 각 브라우저마다 할당된 포트를 일일이 관리해야 한다. 브라우저가 수십, 수백 개가 되면 포트 관리만으로도 복잡해진다.
결국 CDP 방식은 관리 포인트가 너무 많아져서 포기하게 되었다.
시도를 통한 아키텍처 변경
비록 브라우저 공유 문제는 해결하지 못했지만, 내부 회의를 통해 Playwright 서버를 분리하는 것 자체는 유지하기로 결정했다. 당장의 문제 해결과는 무관하지만, 장기적으로 보면 다음과 같은 이유로 좋은 판단이었다:
- 스크래핑 서버의 리소스 사용량 대폭 감소
- 브라우저 관련 장애가 스크래핑 로직에 미치는 영향 최소화
- 향후 브라우저 풀 관리나 최적화 작업의 독립적 진행 가능
결국 각 서버가 독립적으로 브라우저를 관리하되, 네트워크 리소스는 절약하는 하이브리드 구조를 채택했다.
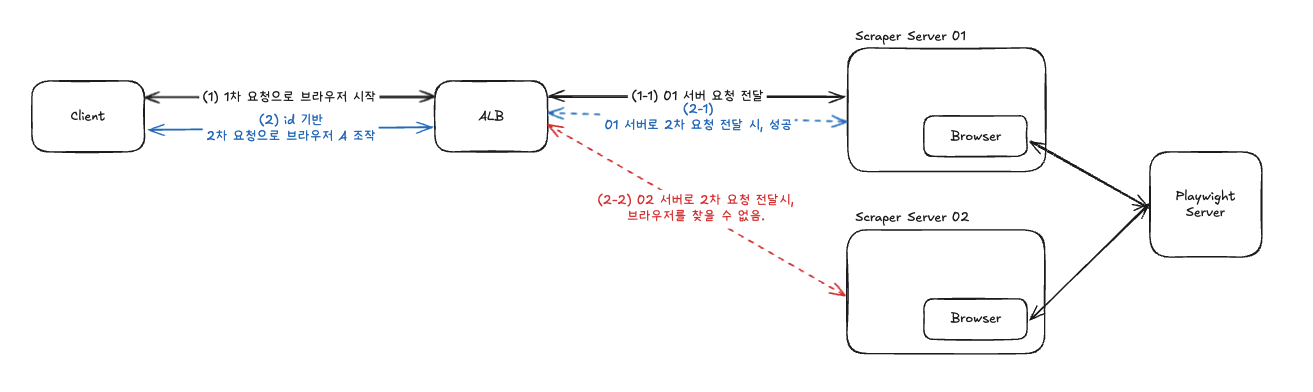
이 아키텍처의 특징은 다음과 같다.
- 각 Scraper 서버는 독립적인 브라우저 인스턴스를 관리한다
- Playwright 서버는 네트워크 최적화만 담당한다
- 명확한 한계점: 브라우저 세션은 특정 서버에 종속된다
하지만 아직, 문제를 해결한 것은 아니었다. 여전히 서버 확장 시 사용자의 요청이 1차 요청의 서버가 아닌 다른 서버로 라우팅 되면 브라우저를 찾을 수 없다.
해결책: 세션 인식 라우팅 (Session-Aware Routing)
이제 핵심 문제를 해결할 차례다. 이 문제를 해결하는 방법은, 요청을 받았을 때 해당 브라우저 세션이 존재하는 서버로 정확히 라우팅하는 것이다.
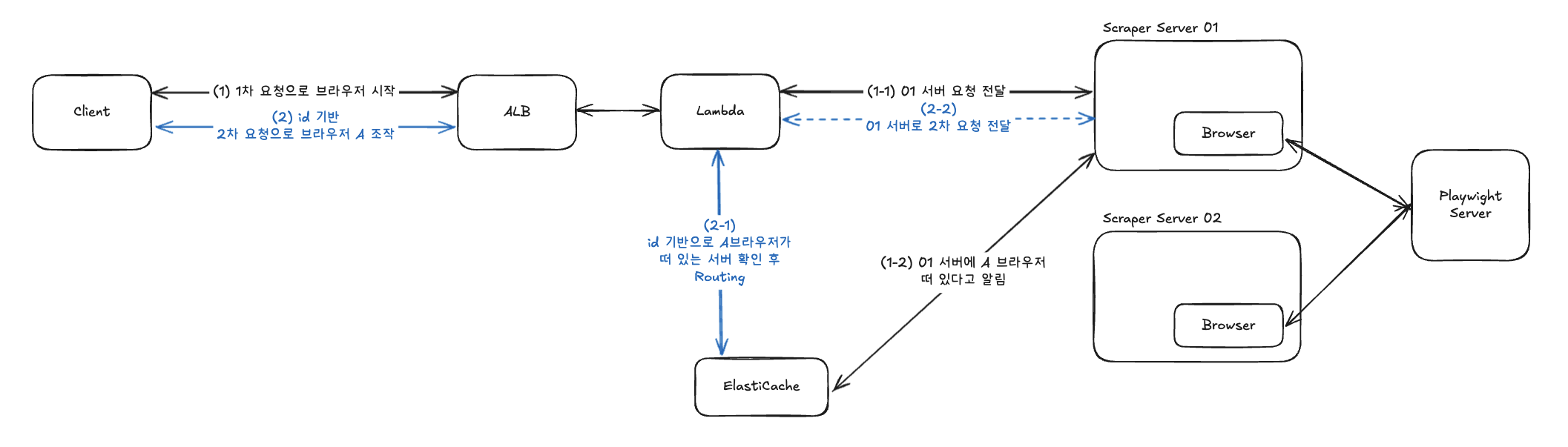
설계 원칙
- 세션 상태 외부화: 어떤 서버에 어떤 브라우저 세션이 있는지 중앙에서 관리한다
- 지능형 라우팅: 요청의 세션 정보를 기반으로 적절한 서버를 선택한다
- 장애 복구: 서버 다운 시 세션 정보 정리 및 에러 핸들링을 수행한다
구현 아키텍처
전체 AWS 기반 구조에서 다음과 같은 컴포넌트들을 활용한다
- ALB (Application Load Balancer): 클라이언트 요청의 진입점
- Lambda: 세션 기반 라우팅 로직 실행
- ElastiCache (Redis): 세션-서버 매핑 정보 저장
- EC2 Scraper Servers: 실제 브라우저 세션 관리
라우팅 로직의 핵심 개념
세션 생성 시 (1차 요청): 새로운 세션이 생성되면 해당 세션 ID와 서버 정보를 ElastiCache에 저장한다. 이때 TTL을 설정하여 세션의 수명을 관리한다.
세션 기반 라우팅 (2차 이후 요청): Lambda 라우터가 요청에서 세션 ID를 추출하고, ElastiCache에서 해당 세션이 존재하는 서버 정보를 조회한 후 적절한 서버로 라우팅한다.
고려사항과 한계점
장점:
- 수평 확장 가능: 서버 추가 시 자동으로 새 세션이 분산된다
- 세션 일관성 보장: 동일 세션의 모든 요청이 올바른 서버로 라우팅된다
- 메모리 효율성: 각 서버는 자신의 세션만 관리한다
잠재적 한계점과 대응방안
- 단일 장애점: ElastiCache 장애 시 라우팅이 불가능하다
- 대응: Multi-AZ ElastiCache 클러스터 구성이 필요하다
- 서버 다운 시 세션 손실: 특정 서버 장애 시 해당 세션들이 모두 손실된다
- 대응: 클라이언트 측 재시도 로직으로 새 세션 생성이 필요하다
- Lambda Cold Start: 라우터가 Lambda일 경우 초기 지연이 발생할 수 있다
- 대응: 프로비저닝된 동시성 설정을 고려해야 한다
결론
이번 프로젝트를 통해 상태를 가진 서비스의 수평 확장이 얼마나 복잡한 문제인지 직접 경험할 수 있었다.
핵심 학습 내용
Stateful vs Stateless의 실제 영향
이론적으로만 알고 있던 개념이 실제 비즈니스 요구사항과 충돌할 때의 복잡성을 이해하게 되었다
세션 친화성 패턴의 필요성
브라우저 세션처럼 외부로 추상화하기 어려운 상태의 경우, 지능형 라우팅이 현실적 해결책이 된다
트레이드오프 분석의 중요성
각 아키텍처 결정이 가져오는 장단점을 명확히 파악하고 비즈니스 요구사항에 맞는 선택을 해야 한다
일반화 가능한 패턴
이 문제는 웹 스크래핑뿐만 아니라 다음과 같은 상황에서도 동일하게 적용될 수 있다:
- 웹소켓 연결 관리: 실시간 채팅, 게임 서버
- 파일 업로드 세션: 대용량 파일의 청크 업로드
- 상태 기계 기반 워크플로우: 복잡한 비즈니스 프로세스 관리
핵심은 상태의 생명주기를 명확히 정의하고, 적절한 라우팅 전략을 통해 세션 일관성을 보장하는 것이다.
서버를 확장하는데 있어서 서버를 Stateful하게 두면 안 되는 이유는 알고 있었지만, 몇몇 경우에는 서버가 Stateful하게 될 수밖에 없다는 것을 깨달았다. 이번 경우가 딱 그런 경우였는데, 브라우저 세션이 하나로 묶여서 여러 서버가 사용할 수 있는 형태가 아니다 보니 이런 문제가 발생했다.
이렇게 서버가 늘어남에 따라서 각 서버별로 처리해야 할 것들이 있는 경우에는 요청을 먼저 보고 각 서버에 할당할 수 있는 라우터의 필요성을 알게 되었다.
이러한 라우터 사용 구조는 상태가 있는 여러 환경에서 유용할 것 같아서 블로그 글을 써 보았다 ^^
