U-Net : Convolutional Networks for Biomedical Image Segmentation
- 해당 논문에서는 데이터 증강을 사용하여 주어진 의료 이미지를 효과적으로 학습시키는 네트워크와 학습 전략을 고안하였다.
- 네트워크의 구조는 context를 처리하기 위한 constracting path와 정확한 localization이 가능하도록 하는 대칭된 expanding path로 구성되어있다. 또한 그 사이의 skip connection 역시 존재한다.
- 논문에서는 neuronal sturcture에 대한 segmentation task에서, 해당 네트워크를 사용하여 적은 수의 이미지로도 효과적이고 강력한, 심지어 빠른 end to end learning을 할 수 있음을 보인다.
Segmentation
- 최근 다양한 CNN 모델들이 등장하였고 좋은 성능을 내고 있는데, CNN은 일반적으로 classification task에 쓰이고 있다. classification의 output은 하나의 class label이다.
- 반면, 다양한 visual task에서, 특히 의료 이미지에서는 localization을 포함한 output을 필요로 한다. 즉, class label이 각 pixel에 대해 부여되어야 한다. 즉 segmentation을 필요로 한다.
- 기존에 최고 성능을 내던 연구에서는 sliding window 방식을 사용하여 각각의 pixel 주변의 local region(patch)에 대해 class label을 예측하도록 네트워크를 학습시켰다.
- 이렇게 하면 network가 localize도 수행할 수 있을 뿐더러, 학습 데이터, 즉 patch가 학습 이미지의 수에 비해 훨씬 많아지는 효과도 존재한다.
- 하지만 이러한 방법은 명백하게 두개의 약점을 가지고 있다. 먼저, network가 각 patch에 대해서 동작해야 하므로 매우 느리다는 것과, 각 patch 사이에 겹치는 부분이 많아 중복이 많이 발생한다는 것이다.
- 두 번째는 localization accuracy와 use of context 사이의 trade off 문제이다. large patch를 사용하면 max pooling layer를 더 많이 사용해야 하므로 localization accuracy가 줄어들지만, small patch를 사용하면, 네트워크가 localization은 더 잘 해내는 반면, 작은 문맥 정보밖에 사용하지 못한다.
- 따라서 이를 해결하기 위해 최근의 방법들은 multiple layer의 feature를 사용하여 classifier가 output을 만들어내도록 하고 있기도 하다.
Model Architecture
- 해당 논문에서는 fully convolutional network를 사용하여 segmentation을 위한 network를 고안한다.
- FCN을 수정하고 확장하여 적은 수의 학습 이미지로도 정확한 segmentation을 해내는 모델을 만들 것이다.
- 기존 FCN의 메인 아이디어는, 일반적인 CNN(contracting path) 뒤에 pooling operator 대신 upsampling opertor를 사용한 레이어를 추가하는 것이었다. upsampling 레이어를 거친 output의 해상도는 증가할 것이다.
- 따라서 high resolution feature와 contracting path의 feature들을 함께 사용하여 사용한다면 convolution layer가 더 정확한 localization을 해낼 수 있었다.
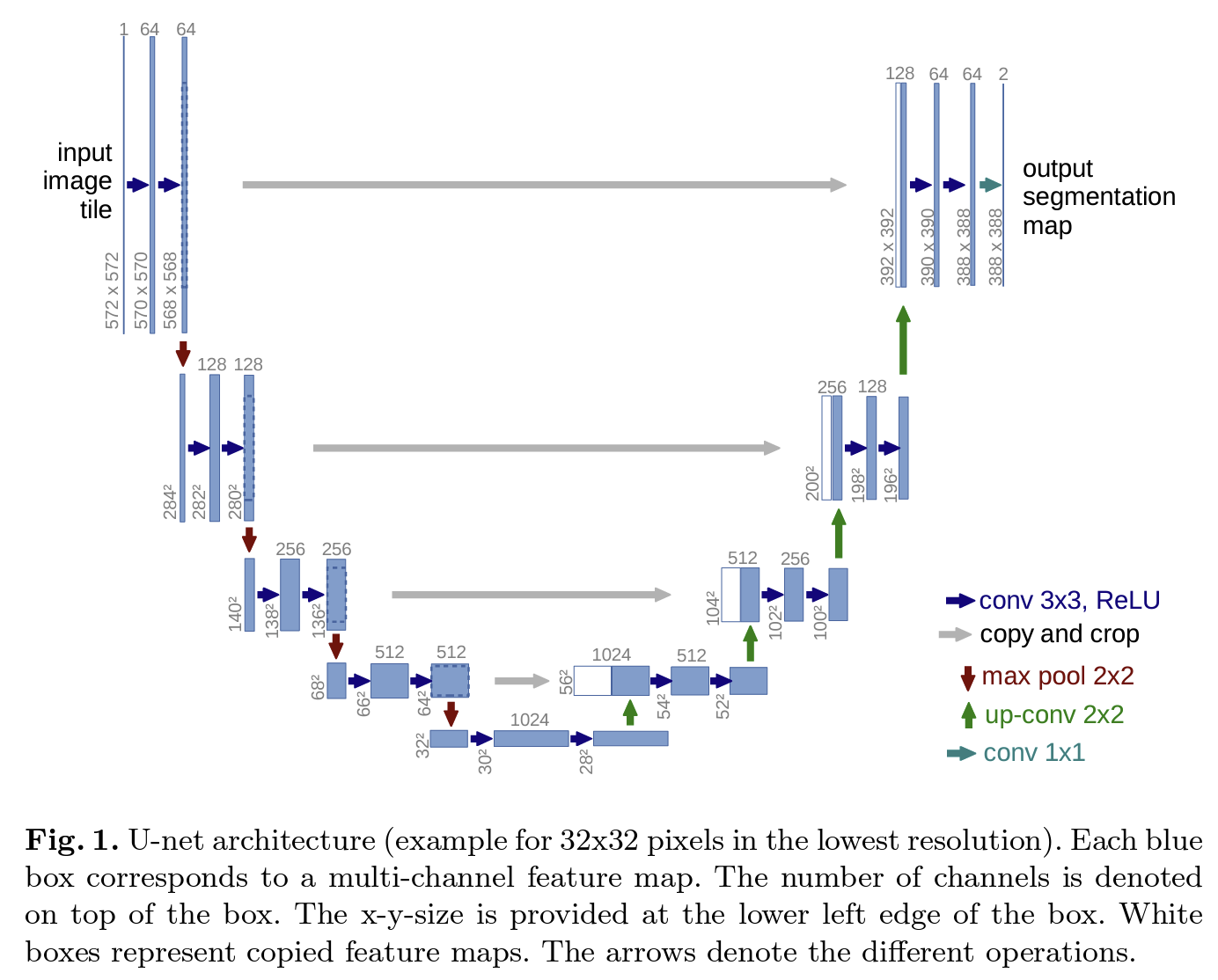
- U-Net에서는 이러한 FCN을, upsampling part에서도 많은 수의 feature channel을 가지도록 수정하였다. 이를 통해 네트워크가 higher resolution layer에 context 정보를 전달할 수 있도록 하였다.
- 그 결과로써, contracting path와 대칭되는, expansive path가 생기게 되었고, 네트워크는 U자형 형태를 가지게 되었다.
- Fig 1.에서 네트워크 architecture를 살펴보면, 왼쪽 부분의 contracting path와 오른쪽 부분의 expansive path를 확인할 수 있다.
- contracting path는 일반적인 convolutional network의 형태를 가지고 있어, 2개의 3x3 convolution layer 뒤에 relu function 이 적용되고, 2x2 max pooling이 stride 2로 적용되어 downsampling 된다.
- 이를 통해 각각의 downsampling step에서 channel 수를 2배로 늘리고, size를 줄여가며 convolution을 진행해 세부적인 feature를 뽑아낸다.
- expansive path는 feature map을 2x2 upconvolution을 통해 upsampling 한 후, contracting path에서의 feature map과 concatenate하여 2개의 3x3 conv layer 및 relu 함수를 적용시킨다. 이를 통해 맥락에 대한 정보를 얻어낸다.
- 이때, convolution 과정을 거치며 가장자리 pixel들이 사라졌기 때문에, concatenate를 위해서는 contracting path의 feature map을 cropping 해야만 한다.
- 마지막 layer는 1x1 convolution으로, 64 channel의 feature map을 class의 개수에 맞는 channel수를 가지도록 만들어준다.
- 따라서 전체 네트워크는 23개의 convolutional layer를 가지고 있다.
Training
- 논문에서는 SGD를 사용하여 훈련을 진행하였고, 훈련에 있어 GPU memory를 최대한 사용하기 위해 large input tile과 large batch size를 사용하였고, high momentum(0.99)을 사용하여 이전 training sample들의 optimization에서의 영향을 크게 하였다.
- loss function(energy function)은 cross entropy function과, final feature map에서의 pixelwise softmax를 결합하여 계산한다.
- softmax function은 해당 pixel의 feature map의 각 채널에서의 activation 중 해당 class를 나타내는 channel의 확률을 나타낸다. 따라서 정답 class에서는 1이고, 나머지 채널에 대해서는 0이다.
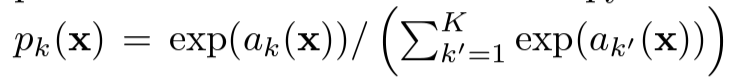
- cross entropy도 살짝 변형하여 사용하는데, 기존 cross entorpy와는 달리 확률값에 로그를 씌운 값에 weight map w를 곱한 값의 합이다.
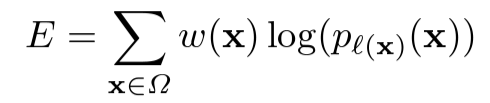
- 또한 이는 인접한 세포들 사이의 작은 seperation border를 잘 학습하기 위해서도 사용되는데, 이를 위해 인접한 cell과의 거리에 따른 가중치를 부여하는 방식으로 다음과 같이 계산된다. wc는 class freqeuncy의 균형을 맞춰주기 위해 ground truth를 토대로 미리 계산된 weight map이다.
- 뒤의 항은 가장 가까운 cell과 두번째로 가까운 cell의 경계까지의 거리 d1, d2를 포함하고 있다. 논문에서는 w0 = 10, 시그마 = 5pixel을 사용하였다. 이를 통해 인접한 세포와의 거리가 가까운 pixel에 대해 더 큰 가중치를 부여하여 small seperation border를 더 잘 학습할 수 있도록 하였다.
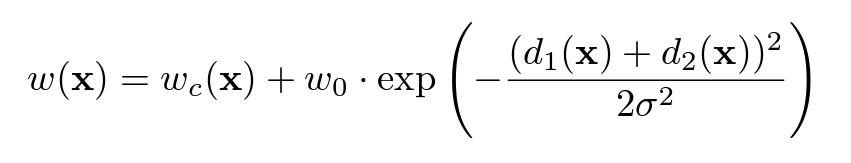
- initial weights는 네트워크의 각각의 feature map이 unit variance를 가지도록 초기화되었다. 이는 weights를 표준편차를 으로 하는 gaussian distribution으로부터 초기화함으로써 얻어내었다. 여기서 N은 하나의 뉴런에 대해 incoming node의 수이다.
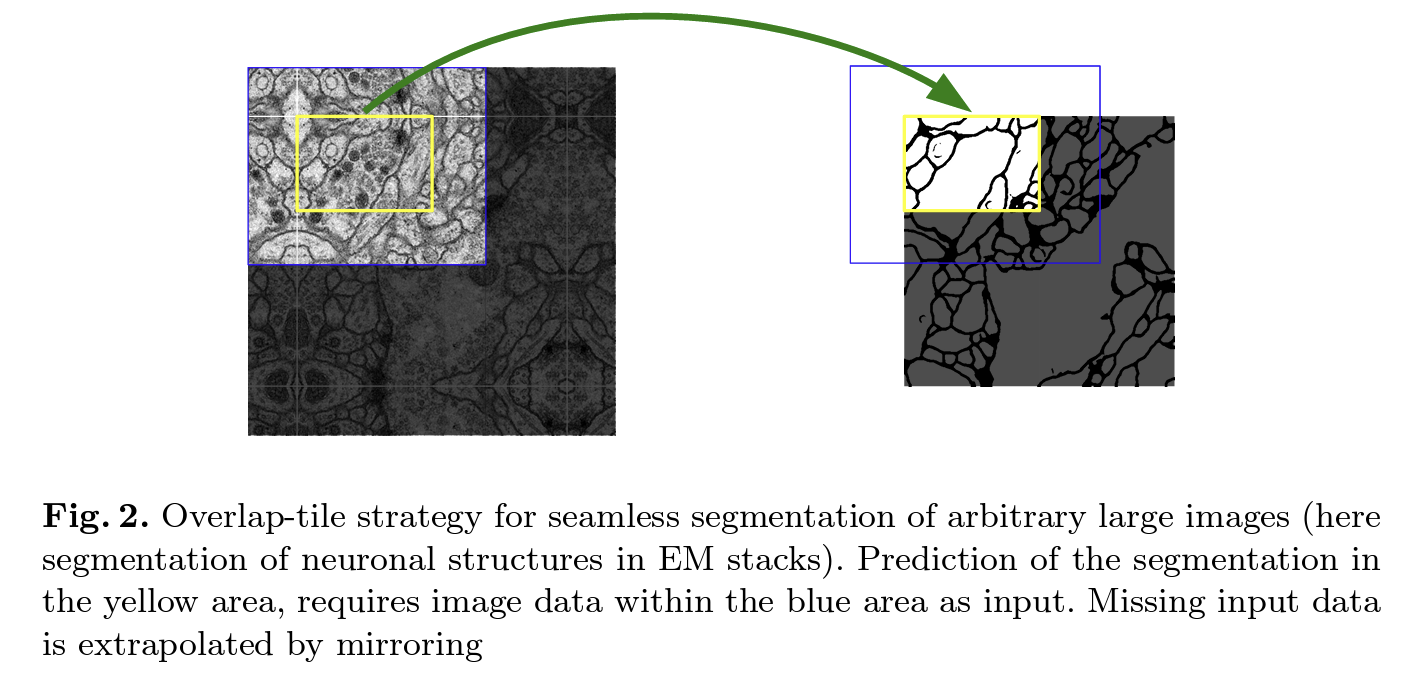
- U-Net은 overlap tile strategy를 사용하여 매끄러운 segmentation이 진행될 수 있도록 한다.
- overlap tile strategy는 입력 이미지를 겹쳐지는 부분이 존재하는 여러 개의 타일로 나누고, 각 타일에 대해 segmentation을 진행한 후 이를 조합하여 최종 segmentation map을 만드는 방법이다.
- input의 size가 output의 size보다 크므로, input의 가장자리에 있는 pixel에 대한 예측을 진행하기 위해서, input image를 mirroring 함으로써 missing context를 extrapolation 시켜준다. 이를 통해 경계부분에 대한 segmentation 성능을 높일 수 있다.
- 큰 사이즈의 이미지는 GPU memory의 한계로 인해 작은 사이즈로 resizing 될 것이기 때문에, 이미지를 여러개의 tile로 나누어 처리하는 overlap tile strategy가 매우 중요한 기법이다.
Data Augmentation
- training sample의 수가 적을 때, 네트워크가 invariance하고 robust하게 하기 위해서는 data augmentation이 필수적이다.
- 의료 이미지 task에서는 아주 적은 training data를 사용가능하다. 따라서, traning image에 대해 elastic deformation(비선형적인 변환)을 통해 추가적인 data augmentation을 진행하였다. 이를 통해 network가 그러한 변형에 대해서도 불변하도록 학습시켰다.
- 구체적으로는, 이미지를 3x3 grid로 나누어 각각의 grid에 대해 random displacement를 진행하였다.
- 세포 조직에 대해서 실제로 가장 자주 일어나는 변형이 deformation이기 때문에, 이는 biomedical segmentation에 있어 아주 중요하다.
Experiments
- neronal sturctures in electorn microsocpic recordings을 segmentation 하는 task에서 최고의 성능(warping error, rand error, pixel error)을 내었다.
- 또한 두개의 다른 task에서도 최고 성능(IOU)을 내었다.

ai school 기간 동안의 TIL!