Index
- 특정 검색 환경에서 레코드를 가져오는 시간을 빠르게 하기 위해 사용한다.
- 추가적인 접근 경로를 제공하는 "디스크 내부의 추가 파일" 이다.
- 디스크 내 파일의 위치를 변경하지 않고 접근 방식을 제공한다.
- indexing field에 대한 효율적인 접근 방식을 제공한다.
추가설명
- 어떤 필드든 인덱스를 만드는데 사용될수 있다.
- 여러개도 있을수 있다.
- 레코드를 찾는것은 인덱스 필드에 기반한다.
- 인덱스를 정리하기 위해 보통 정렬과어 있거나, 트리 형태를 취한다.
Ordered Index
Indexing Field
- 단일 필드의 파일
- 각각의 값은 필드 값과 그에 연결되는 다른 블록의 포인터로 구성된다.
- 필드와 포인터만 저장되어 실제 데이터보다 크기가 매우 작다.
- 이진탐색을 통해 원하는 필드의 위치를 찾을수 있다.
Dense / Sparse
- 모든 레코드에 상응하는 엔트리가 있을경우 Dense
- 몇몇 레코드에 상응하는 엔트리가 없을경우 Sparse / Nondense

Primary Index
- key가 정렬된 상태로 저장하는것
- 색인에 사용될 Primary key 와 디스크의 위치를 가지는 포인터로 구성된다.

이름이 key로 사용된 예시 - bfr : 블록 별 엔트리 갯수
- 블록의 갯수에 따라 탐색 시간이 결정된다.
Primary Index - 문제점
- 레코드를 삭제/삽입 할때
- 제대로 된 위치에 넣어야 한다.
- 포인터의 위치를 바꾸어야 한다.
- 몇몇 저장된 데이터의 위치를 옮겨야 한다.
- 해결
- 레코드 갯수가 넘어가면 링크드 리스트로 이어준다.
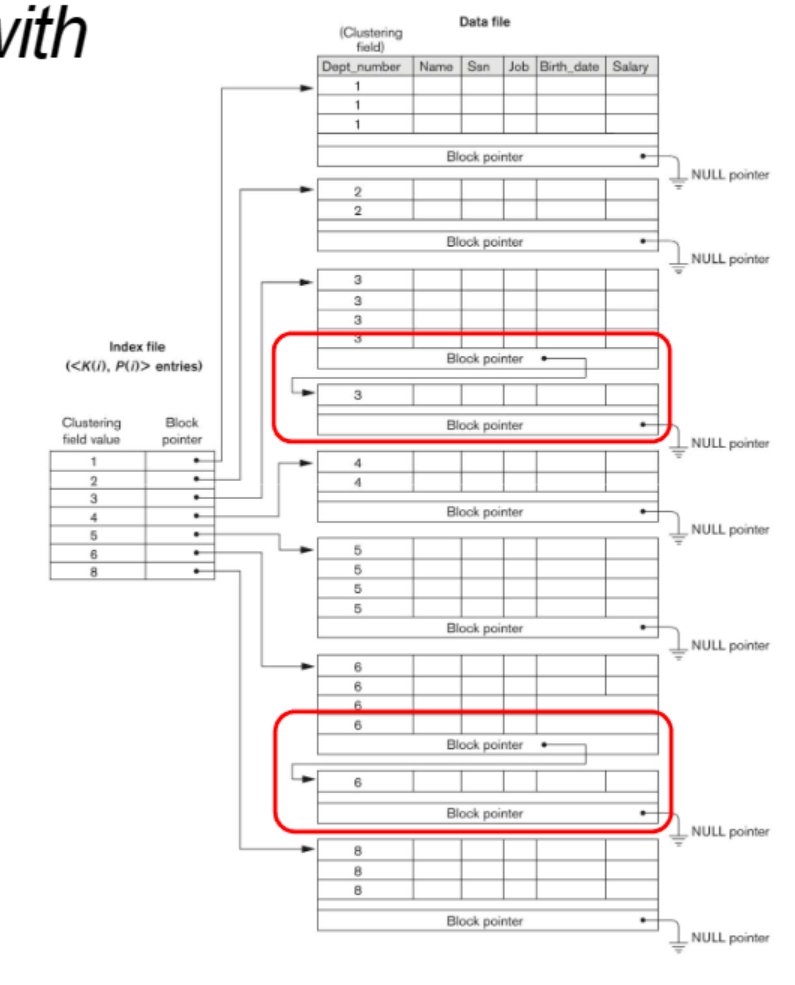
- 레코드 갯수가 넘어가면 링크드 리스트로 이어준다.
Clustering Index
- Key가 아닌 필드에 대해 인덱싱 한다.
- nondense 하다.
- 같은 필드 값을 가지는 여러 레코드를 빠르게 가져오기 위해 사용한다.
- key - 포인터 구조로 이루어진다.

2는 1번째 블럭에서 처음 나오기에 최대한 1블럭의 앞을 indexing 한다
Clustering Index - 문제점
- 여전히 삭제, 추가가 어렵다.
- 각각의 clustering field 에 대한 빈 공간을 남겨둬 해결 가능하다.
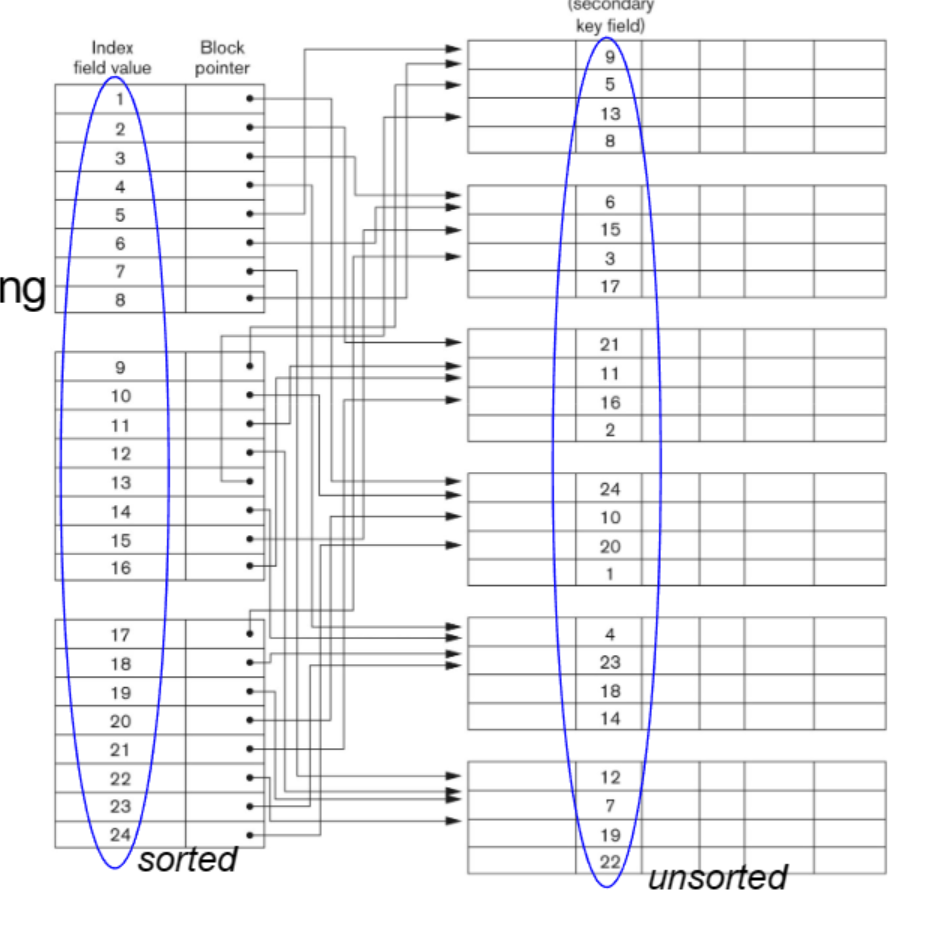
Secondary Indexes
- 부차적인 접근방법을 제공한다.
- Primary 나 Clustering 은 둘중 하나만 있어야 하는 반면 이건 여러개 있어도 된다.
- 중복값을 포함할수 있다.
- indexing field - 레코드/블럭/포인터 로 구성된다.
- Secondary index는 같은 데이터 파일에 생성될수 있다.
Secondary - Key Field
- 하나의 레코드마다 하나의 index entry 를 가진다.
- Dense!
Oracle Database - Index
- 자동으로 생성된다.
- Primary Key / Unique 지정시 이를 Primary / Secondary index로 사용한다.
- 혹은 사용자의 필요에 따라 생성될수 있다.
- EX. SSN보다 이름으로 직원을 더 많이 참조시 이 둘을 secondary index로 지정할수 있다.
- 쿼리 속도가 증가하나, 항상 권장되진 않는다.
권장
- 튜플이 너무 많을때
- 조인에 사용되는 칼럼 혹은 WHERE에서 조건으로 사용되는 컬럼
비권장
- 적은 튜플을 가질때
- WHERE에서 조건으로 사용되지 않는 컬럼
생성 문법

- 중복 값이 있는 필드는 unique를 붙히지 않아도 된다.

DROP

만능 컴덕후 겸 번지 팬