Relational Model
Set theory ( 집합이론 ), First-order predicate logic ( 1차 술어 논리 ) 에 기반을 둔다.
First-order predicate logic
-
서술은 다른 함수나 서술어가 아닌 개인에게만 적용된다.
- Socrates is mortal : 소크라테스 - 개인, 필멸이다 - 서술
- First-order logic 이 맞다.
- Being beautiful is good : 이뻐지는것 - 서술, 좋다 - 서술
- 서술을 서술하기에 First-order logic 이 아니다.
Relation ( Table )
집합에 기반을 둔 수학적 개념
- Socrates is mortal : 소크라테스 - 개인, 필멸이다 - 서술
-
값들의 Table/표, Record/레코드들의 모임 등으로 표현된다.
-
여러개의 Row/행을 포함한다.
- 각각의 행의 데이터는 엔티티 혹은 Relationship 에 관련된 사실을 가지고 있다.
-
각각의 열은 Column-header 를 가지며, 열에 있는 데이터의 의미를 전달한다.
- Formal 하게는 Attribute ( 속성 ) 으로 칭한다.
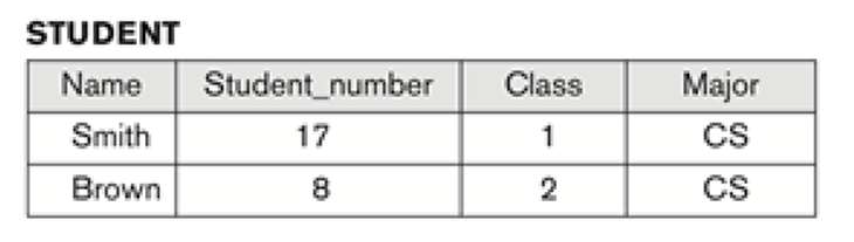
- Formal 하게는 Attribute ( 속성 ) 으로 칭한다.
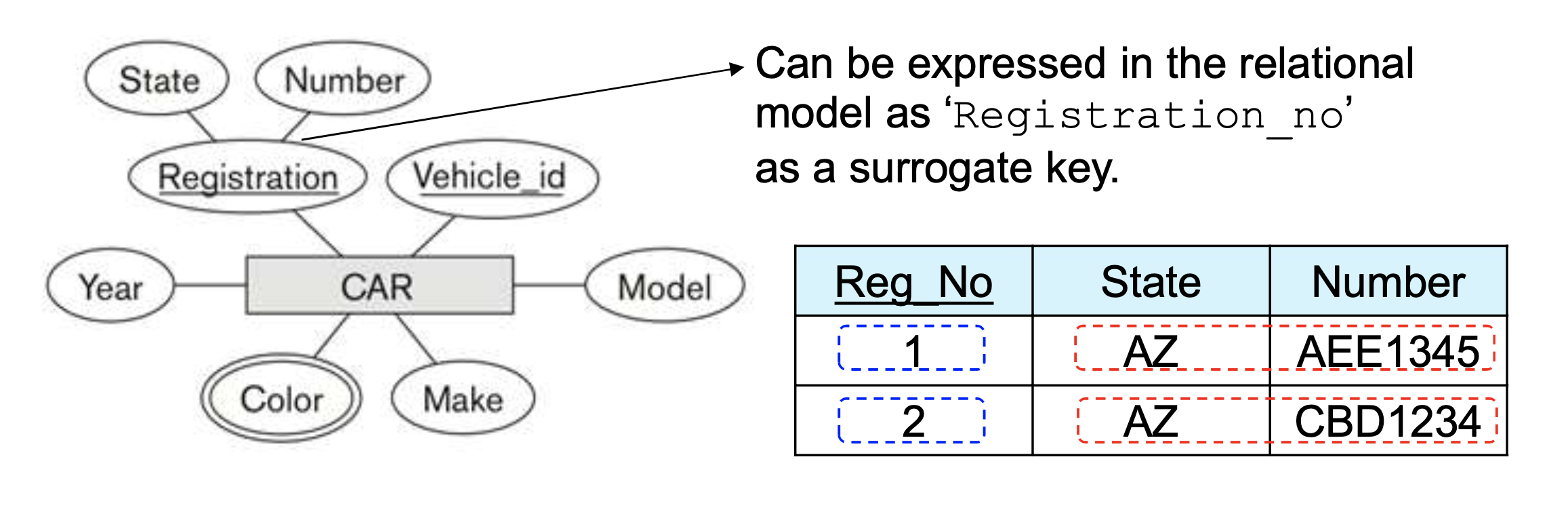
Key or relation
- 각각의 행이 가져야 하는 데이터
- 행을 식별하기 위해 반드시 필요하다.
- 행의 ID, 연속되는 숫자가 사용될수도 있다.
- surrogate/대리(or artificial/인공) key 로 불린다.
Schema
Formal Definition of Relation
Schema of Relation
- 와 같이 표현한다.
- : Relation 의 이름
- : Attribute 리스트
- Relation 의 Degree/차수 는 Relation R 이 가지는 Attribute 의 갯수이다.
- 각각의 Attribute 는 올바른 값들의 집합인 Domain 을 가진다.
- 일종의 Constraint
- Ex. Name Attribute 는 25자 이하의 문자열이여야 한다.

이름은 CUSTOMER, Degree는 4인 Relation의 Schema
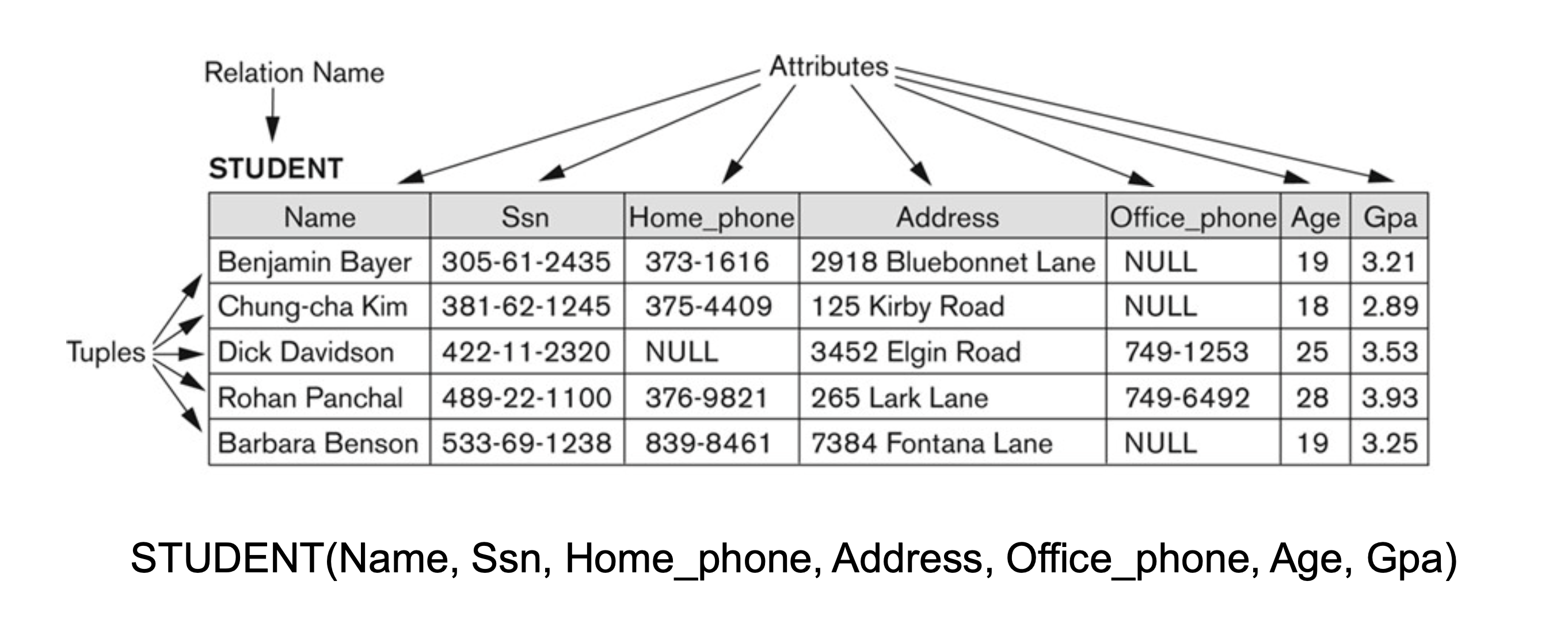
Tuple
순서를 가지는 값의 집합
- <> 를 이용해 표현한다.
- 각각의 값은 적절한 도메인으로부터 파생된다.
- 도메인 : 올바른 값들의 집합.
- Relation(Table) 은 이런 튜플들의 집합이다.
- 모든 값은 Atomic ( multi-valued / composite 불가능 ) 하다.
- 튜플의 모든 값은 해당하는 Column Attribute/열 속성 의 도메인을 따라야 한다.

Domain
(Individual/Atomic)개별 값들의 집합
- 즉, Attribute는 무조건 단일 값이 들어가야 한다.
- 배열/목록은 불가능하다.
- 논리적 정의 혹은 이름을 가지고 있다.
- Ex. “Korea_cell_phone_numbers” >> 010으로 시작하는 11자리 숫자로 구성된다.
- 데이터 타입 혹은 포맷을 가진다.
- Ex. “Korea_cell_phone_numbers” >> (010)-dddd-dddd 의 포맷을 가진다.
- Attribute/Column name 이 Relation/Table 에서 Domain 의 역할을 한다.
State
개별 속성의 도메인들의 Cartesian product의 부분집합.


- 여러 속성의 도메인으로 이루어질수 있는 모든 튜플들의 부분 집합이다.
- 즉 채워진 Relation 의 Tuple들이라고 볼수 있다.
- 튜플들의 순서는 상관이 없다.
- 순서가 바뀌어도 같다고 취급한다.
- 튜플 내의 값은 반드시 순서를 지켜야 한다.
NULL 값
- 특정 튜플의 NULL 값은 아래와 같다.
- 알려지지 않은것 / Unknown
- 모르는것
- 이용 불가능한 값 / Not available
- 전화번호가 없을경우
- 적용 불가능한 값 / Inaplicable
- 자동차에 비행 가능 길이는 없다.
- 알려지지 않은것 / Unknown
이 외 표기법
R.A
- R Relation 의 A Attribute name
component value of tuple
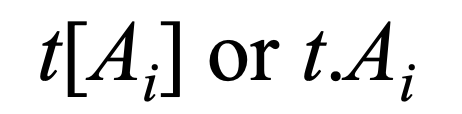
- Tuple t의 Attribute name 에 해당하는 값.

- Tupel t의 여러 Attribute name에 해당하는 값
Constraint
- 어떤 값들이 가능하고, 어떤값이 데이터베이스에 있어선 안되는지
Inherent or implicit constraints
- Relational Model 은 Atomic 하지 않는 배열이나 리스트와 같은 값을 가질수 없다.
Schema-based or explicit constraints
- 데이터 모델 스키마에 바로 표기된다.
- total/partial participation
- min/max cardinality ratio
Application-based or semantic constraints
- 응용 프로그램에 의해 강제되는것
- 데이터 모델을 통해 설명될수 없다.
- 나이가 65세 이상이고 40시간 이상 일할 경우 봉급이 두배가 되어야 한다.
Relational Integrity Constraints
- Constraint 는 모든 Relation State에 적용되어야 한다.
예시
1. Key constraints
- 유일해야 한다.
- 모든 튜플들이 달라야 하기 때문에 존재한다
슈퍼키 : 아래 조건을 따르는 attribute 의 부분집합- 슈퍼키 부분집합은 Relation state 내에서 유일하다
- Relation 의 key는 이 슈퍼키중 가장 minimal 한 것을 사용한다.
- 모든 키는 슈퍼키이나 모든 슈퍼키는 키가 아니다.
- 키를 포함하는 모든 Attribute 의 부분집합은 슈퍼키이다.
- minimal superkey 는 key이다.
- Relation schema 는 여러 키를 가질수 있다.
- 가능한 키들을 Candidate key 라 부르고 이들중 하나를 임의로 선택해 Primary key 라 부른다.
Primary key
- Relation 의 tuple을 유일하게 식별한다.
- 다른 튜플에서 특정 튜플을 참조할때 사용한다. 이 경우 foreign key로 부른다.
- Candidate key 중 가장 작은것을 주로 사용한다.
- Entity integrity constraints : 테이블은 Primary key 에 해당하는 Tuple 을 반드시 가져야 한다.
- Referential constraints : 참조 관계에 있는 두 테이블의 데이터가 항상 일관된 값을 갖는다.
- 참조하는 값은 반드시 존재해야 한다.
- Foreign key constarint 로도 불린다.
--

Relational Database Schema
- 동일한 데이터베이스에 속하는 Relation schema의 집합 S
- S : 전체 데이터베스 스키마의 이름
- 과 Integrity Constraint를 가진다.
Relational Database State
- DB가 , , ... 등의 Relation State 들로 이루어져 있을때, 이들을 Relational Database State 로 부른다.
- Snapshot 이라고도 부른다.
- Database state가 제약조건에 일치하지 않으면 invalid 하다.
Populated Database State
- 각각의 Relation은 현재 Relation state로 여러개의 튜플을 가진다.
- Relational database state는 개별 Relation state들의 집합이다.
- 데이터베이스 변경시, 새로운 State가 생성된다.
- INSERT / DELETE / MODIFY-UPDATE 가 된다.
Entity Integrity Constraint
- Relation Schema R 에서 Primary Key는 NULL값을 가질수 없다.
- Primary Key는 개별 tuple을 구별하기위해 반드시 필요하기 때문이다.
Referential Integrity Constraint
- 두 Relation 사이에 관여한다.
- 두 Relation 간 tuple의 관계에 대해 작성한다.
- 참조하는 쪽에서 FK가 있으면 참조되는 쪽에 그에 해당하는 PK가 존재해야 한다.
- Foreign Key Constraint
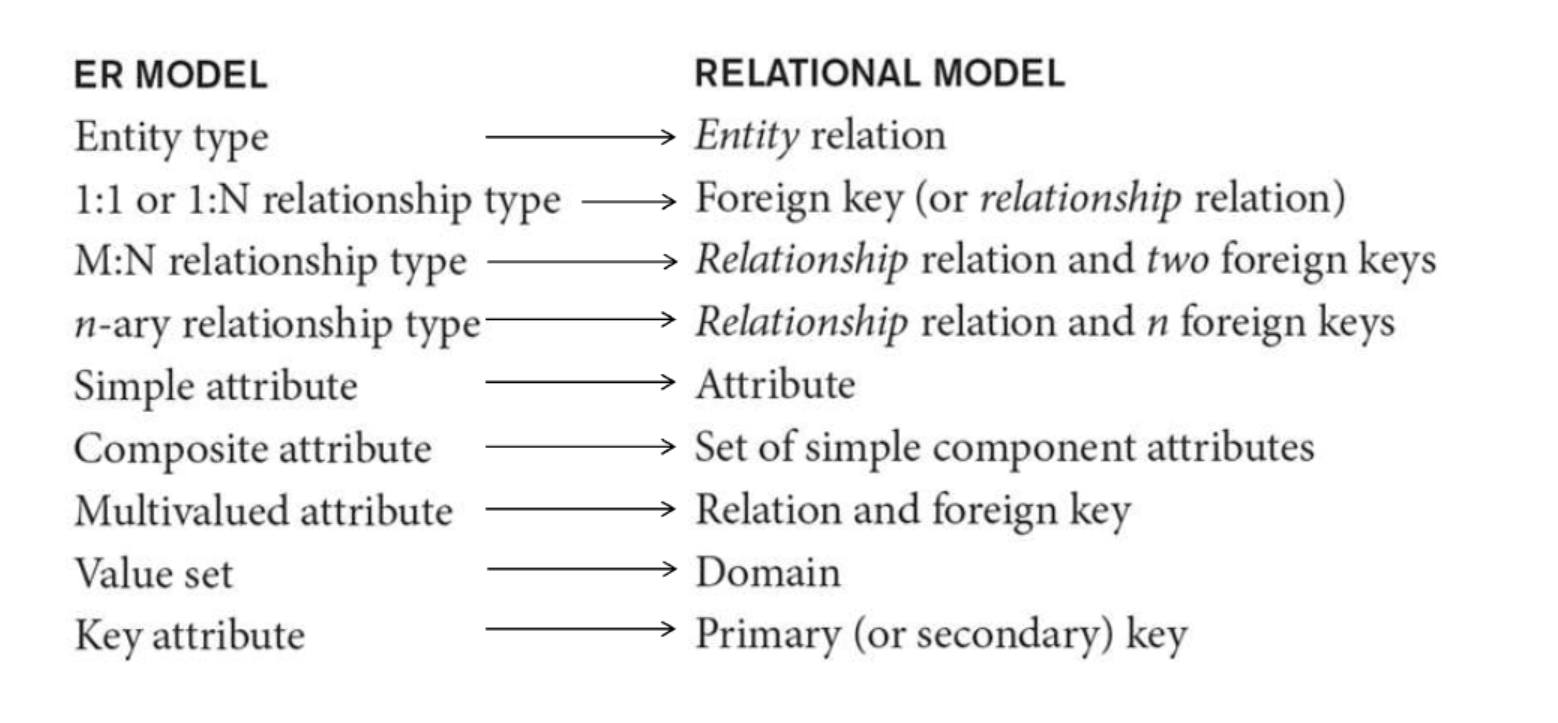
ER to Relational Mapping
- Entity -> Relation 로 맵핑한다.
Goal
- 모든 값을 유지한다.
- 특정 Cardiality Ratio 같은것을 제외한 ( Ex. 1:10 ) 나머지 제한요소를 유지한다.
- NULL 값을 최소화한다.
STEP1 : Regular entity mapping
Strong entity type E
- 모든 Attribute를 포함하는 Relation R을 생성한다.
- E의 Attribute 중 하나를 R의 Primary key로 선택한다.
- 선택된 Key가 Composite일 경우 안의 모든 Simple attribute들이 전부 Primary key가 된다.
STEP2: Weak entity mapping
- 모든 Simple Attribute를 포함한다.
- Owner entity type의 PK를 FK로서 포함한다.
- 위 Weak entity의 Relation 의 PK는 Owner entity PK와 Partial key를 조합해 사용한다.
STEP3: 1:1 Relationship
1. Foreign key approach
- 한개의 Relation을 선택해 거기에 FK로 상대방의 PK를 넣는다.
- FK는 보통 Total participation인 쪽에 넣는다.
2. Merged relation
- 두 Relation을 합친다.
- 둘다 Total participation 일 경우 유용하다.
3. Cross reference / Relationship relation
- 둘 사이의 Relationship을 표기하기 위해 둘의 PK를 FK로 가지는 Relation을 만든다.
- 이 Relation의 PK는 두 FK중 하나를 사용한다.
- JOIN operation 이 필요하다.
STEP4. 1:N Relationship
- N쪽에 FK로 1쪽의 PK를 넣는다.
STEP5. M:N Relationship
- JOIN Table을 이용한다.
- 두 Relation 의 PK를 FK로 가진다.
- 새로 생긴 Relation의 PK는 두 FK를 조합해 사용한다.
STEP6. Multivalued
- 새로운 Relation을 만들고 이의 FK로 원래 Row의 PK를 넣는다.
- 새로 생긴 Relation은 Multivalue를 포함한다.
- 이의 PK는 multivalue들과 FK를 포함한다.
STEP7. N-ary Relationship
- 여러개의 FK를 사용해 해결한다.

만능 컴덕후 겸 번지 팬