Three Valued Logic
- NULL = NULL 은 알수 없다.
- SQL은 Three-Valued logic 을 사용한다.
- True, False, Unknown

- True, False, Unknown
- FALSE AND UNKNOWN : FALSE
- TRUE OR UNKNOWN : TRUE
- NOT UNKNOWN : NOT UNKOWN
IS NULL
- NULL값인지 확인 한다.

중첩쿼리
- 외부의 포함하는 outer query와 내부의 포함되는 sub query로 구성된다.

- IN 연산자 : 서브쿼리의 결과중에 값이 포함이 되는지를 확인하는 연산자이다.

- 위와 같이 여러 칼럼의 값에 대해 확인 할수도 있다.

- ALL과 연산자를 이용해 가져온 모든 값들과 비교해볼수도 있다.

- Subquery에서 Outerquery와 Join하듯 사용할수도 있다.
- Correlated Nested Query : 상호 연관된 중첩 질의
- Outer Query의 각 튜플마다 Sub query가 Evaluate 된다.
- 위 경우는 사원마다 Sub query가 Evaluate
EXIST 연산자
- 상호 연관 질의에서 서브쿼리의 존재 유무로 조건을 검사한다.

- 부양가족이 있고, 부서장인 사원
- 반대로 NOT EXIST 연산자도 있다.

- 2중 부정을 할때 주로 사용한다.
- 예시 : 부서 5번에 모두 참여하는 직원을 고르기.
- 부서 5번의 모든 프로젝트 번호에 특정 직원이 일하는 모든 프로젝트 번호를 뺀다.
- 모두 참여하면 쿼리 결과가 없으나, 하나라도 참여하지 않으면 쿼리 결과가 존재할것이다.

- 동일한 의미를 가지는 쿼리
IN
- 값을 직접적으로 표기할수 있다.

JOIN TABLE
- FROM 부분에 JOIN을 사용한다.

- EMPLOYEE와 DEPARTMENT를 JOIN 하는 예시
- INNER JOIN
- PK와 FK가 같은지 확인하는 조건문을 ON뒤에 적는다.
JOIN의 종류
NATURAL JOIN
- 왼쪽 테이블 R과 오른쪽 테이블 S에 대한 JOIN condition이 미적시된다.
- 두 테이블은 동일한 이름의 Attribute가 있어야 한다.
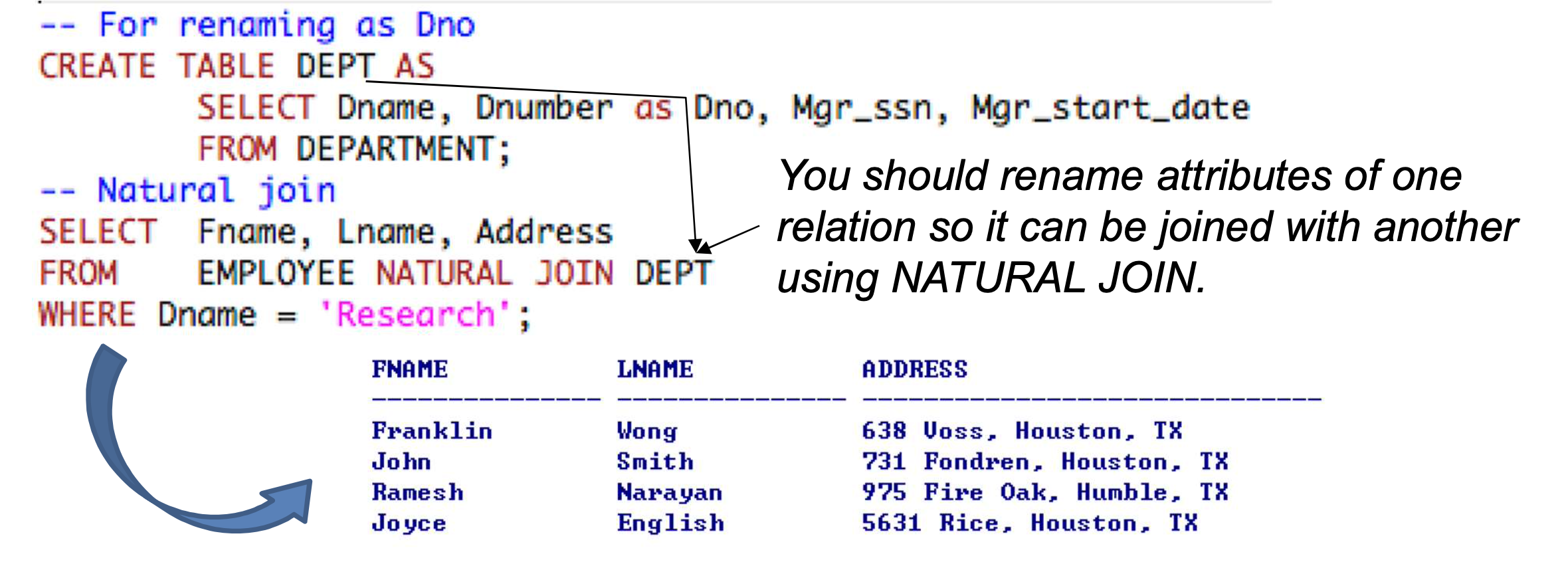
- EMPLOYEE와 DEPT 둘다 Dno Attribute가 있다.
- 두 Attribute가 같은 WHERE에서 =을 쓰는 EQUIJOIN과 유사하다.
INNER JOIN
- JOIN의 기본 타입
- 조건에 맞는 튜플만 결과에 포함된다.
LEFT/RIGHT OUTER JOIN
- 왼쪽 혹은 오른쪽 테이블에서 조건에 맞지 않는 튜플도 결과에 포함하도록 한다.

- 상사가 있거나 없는 모든 직원들의 리스트
- 모든 사원이 표기되어야 하기에 LEFT OUTER JOIN을 사용한다.
- BORG는 상사가 없어 오른쪽이 NULL로 채워진것을 볼수 있다.
- 조건에 맞지 않는 튜플은 반대편은 NULL로 채워진다.
- FULL OUTER JOIN으로 양쪽의 모든 튜플이 표기되게 할수도 있다.

- 양쪽에 NULL이 채워진것을 볼수 있다.
Multiway

- 중첩해서 사용할수 있다.
Aggregate
- 그룹에 대해 단일 튜플로 집계를 할수 있다.
- 예시
- COUNT, SUM, MAX, MIN, MEDIAN, AVG
- 보통 GROUP BY를 사용해 그룹을 만든다.
- HAVING을 통해 그룹의 조건을 걸수 있다.
모든 튜플에 대한 Aggregate

JOIN과 카운트

- NULL은 카운트 되지 않는다.
- COUNT(*)는 튜플 자체의 갯수만을 확인한다.
GROUP BY

- Dno 가 같은 사원끼리 그룹 지은 예시
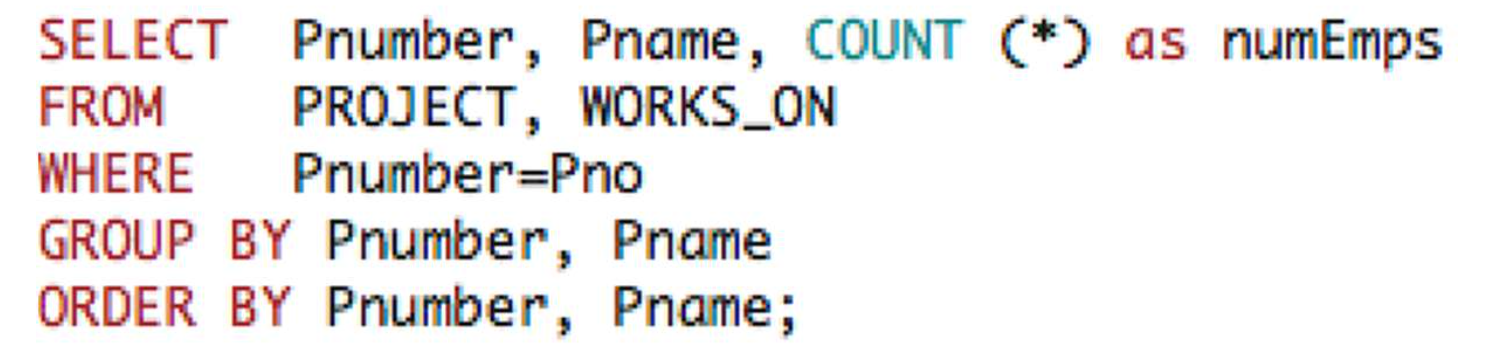
- JOIN과 같이 사용될수 있다.
HAVING
- 특정 조건을 만족하지 않는 그룹을 Reject한다.
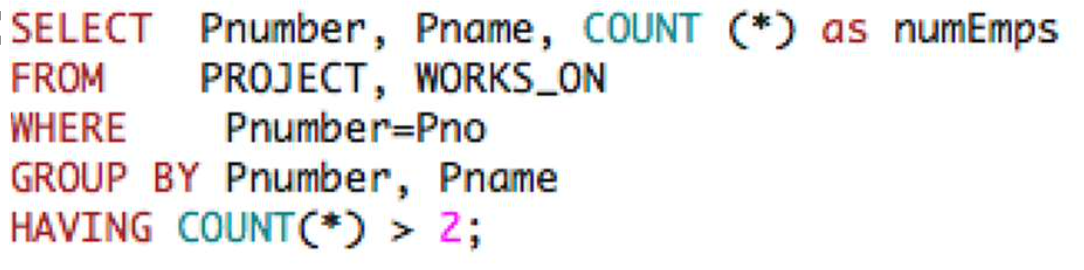
- 크기가 2개를 초과해야 하는 예시
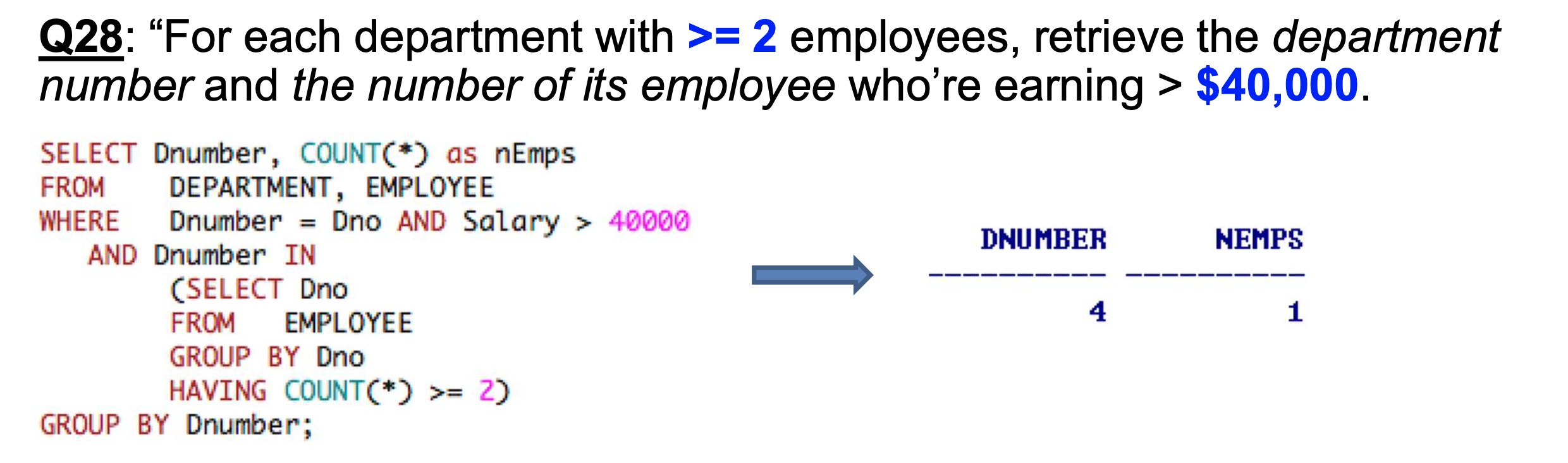
- 2명 이상 부서에서 40000달러 이상 버는 직원의 수
ROLLUP, CUBE, TOP-N
- 다차원 분석에 사용된다
- 차원 : 사용되는 카테고리의 갯수
- 여러 카테고리의 데이터를 시각화 하기위해 데이터의 큐브를 사용한다.
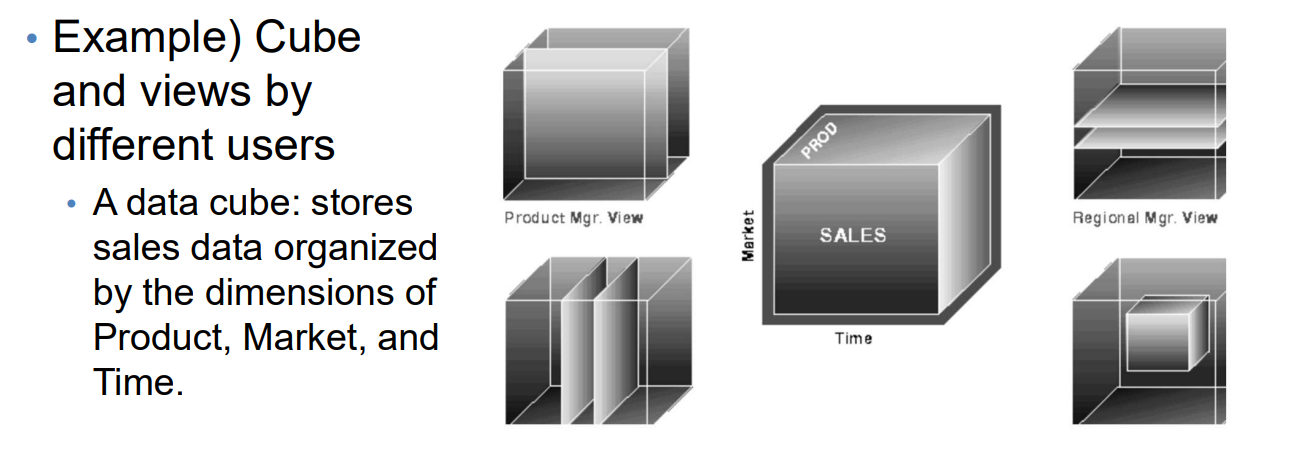
- 큐브와 여러사람의 관점 차이
ROLLUP
- GROUP BY ROLLUP ( 여러개 Attribute )

- 적힌 순서별로 그룹 및 Aggregate
- 위 경우는 성별 > 부서 이름 > 부서 번호 순서로 전부 확인하는 예시
- 특정 부서 + 성별의 경우는 확인하지 않는다.
CUBE
- GROUP BY CUBE ( 여러개 Attribute )
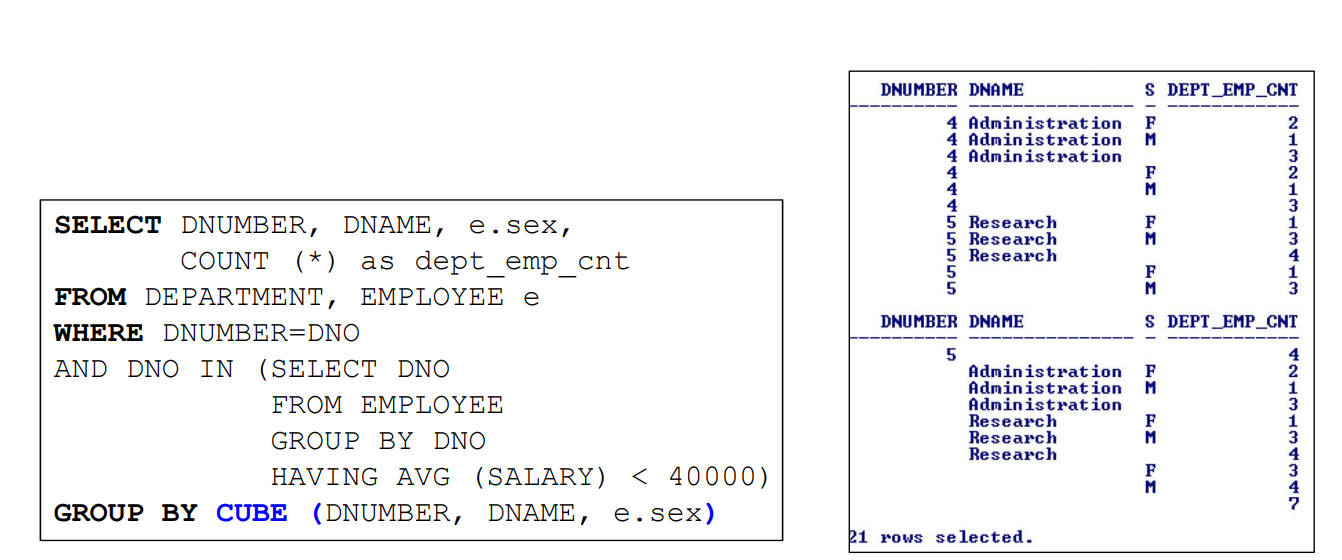
- 모든 경우의 수에 대해 그룹 및 Aggregate
- ROLLUP과는 다르게 특정 부서 번호 + 성별의 경우를 확인할수 있다.
TOP-N
- ROWNUM 이라는 내장 기능을 사용한다.
- ROW의 번호의 역할을 한다.
- WHERE ROWNUM <= 1 하면 맨 위에 있는 값만 출력한다.

WITH
- 쿼리 내에서 사용할수 있는 VIEW를 지정한다.
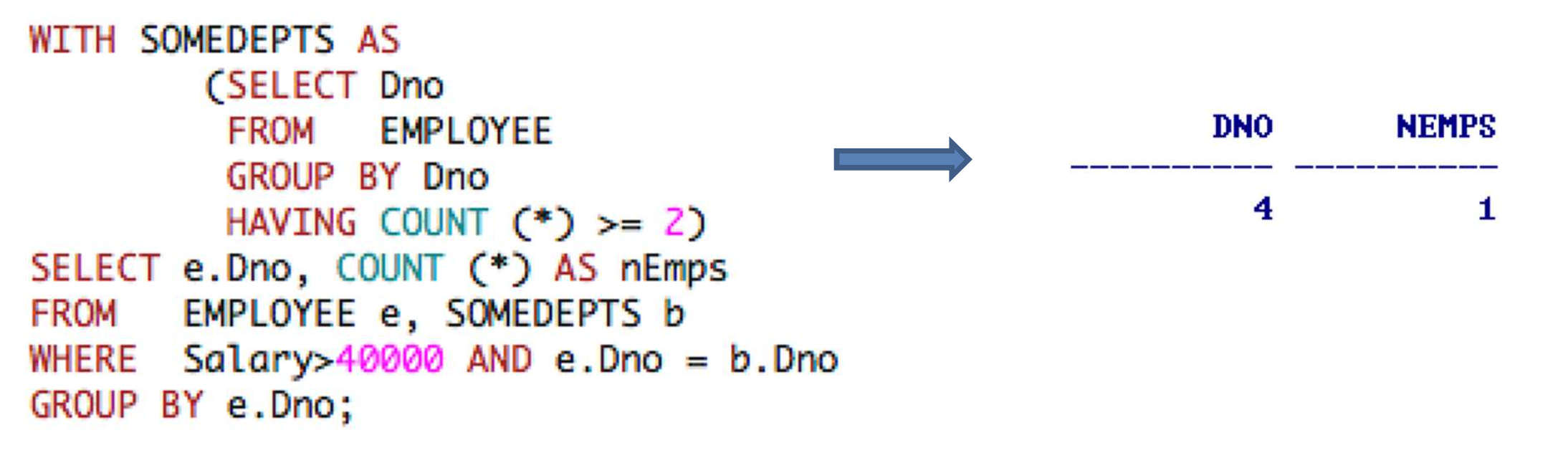
- 인원이 둘 이상인 부서 번호들을 SOMEDEPTS라는 뷰로 만든다
- 만들어진 뷰를 통해 쿼리를 진행한다.
CASE
- 조건에 따라 값이 바뀔수 있는 경우 사용한다.
CASE
WHEN 조건 THEN 값
Recursive Query
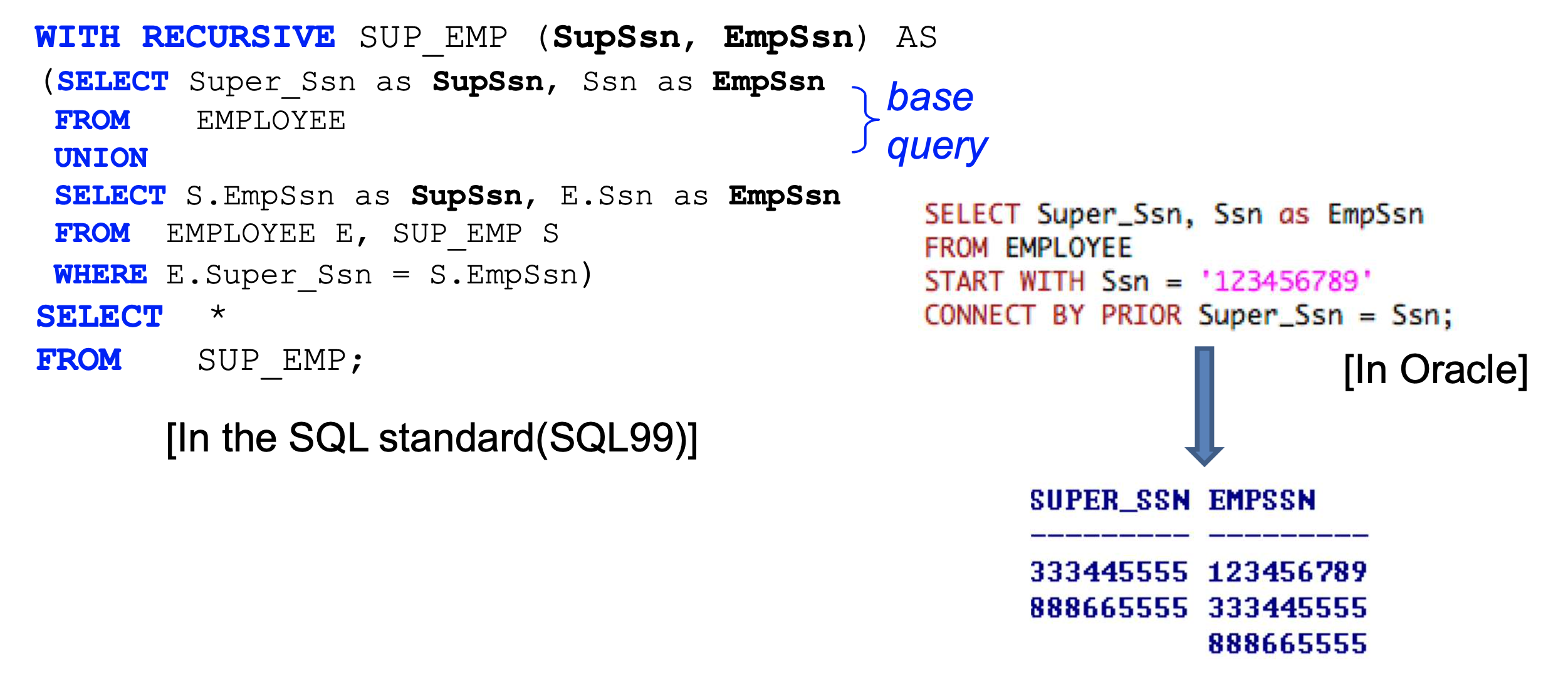
- 동일 타입의 관계를 추적할때 사용 가능하다.
- base query 로 최초 튜플을 먼저 가져 온다.
- UNION 에서 FROM에 자기자신을 두고 WHERE 조건이 아닐때까지 더 가져온다.
- 가져온 결과는 UNION에 의해 SUP_EMP에 추가된다.

VIEW
- 다른 테이블에서 유래된 단일 테이블
- 가상 테이블로 고려되기도 한다.
- 여러번 참조되어야 하는 테이블을 표기하는 방식 중 하나이다.
- 여러차례 사용되는 JOIN 테이블을 캐싱해두는 목적으로 사용 가능하다.
예시

- BASE TABLE에 의해 속성이 정의된다.

- 집계값을 저장하는 경우, Attribute의 이름을 따로 정한다.

- FROM에 들어가 사용될수 있다.

- DROP VIEW {이름} 으로 삭제한다.
장점
- 쿼리를 단순하게 만들어준다.
- 뷰는 보안 및 접근 권한에 대한 메커니즘을 제공한다.
- 공간을 차지하면서 JOIN 비용을 아낄수 있다.
상태
- 뷰는 반드시 최신 상태여야 한다.
- 베이스 Relation에서 변경이 생기면 뷰에도 적용이 되어야 한다.
- 뷰에 쿼리가 들어오는 동시에 구체화 되어야 한다.
- DBMS는 VIEW가 최신화 됨을 유지할 의무가 있다.
구현
- Query Modification Approach
- 뷰를 따로 영구히 저장하지 않는다.
- 뷰를 사용하는 쿼리를 변환한다.
- 복잡하게 구현된 뷰를 사용할때 성능상 단점을 가진다.
- View materialiazion
- 뷰가 처음 쿼리 될때 물리적으로 임시적인 뷰 테이블을 생성한다.
- 다른 쿼리가 올때까지 이를 유지한다.
- 베이스 테이블이 업데이트 되면 효율적으로 이를 업데이트한다.
- 주로 여러개로 나누어 업데이트 ( 증분 업데이트 ) 를 한다. - 쿼리가 유지되는 한 테이블이 유지된다.
업데이트 예시
- 즉각 업데이트 ( Write-Through )
- 나중에 업데이트 ( Write-Back )
- 쿼리 요청이 올때 업데이트한다.
- 주기적으로 업데이트
- 뷰를 주기적으로 업데이트한다.
뷰의 업데이트
- 뷰에 INSERT, DELETE, UPDATE는 불가능하다.
- 베이스 테이블의 aggregate 없이 update로 변환될수 있는 경우만 가능하다.
뷰의 권한 메커니즘
- 특정 유저가 특정값만 쿼리할수 있도록 강제할수 있다.
스키마 변경
- 테이블이나 뷰를 추가/삭제
- Attribute, Constraint 등을 추가/삭제
- 데이터베이스 스키마를 재컴파일 할 필요는 없다.
- 변하지 않는 나머지 부분은 영향을 받지 않는다.
DROP
- 테이블, 도메인, 제약조건 등을 제거
- CASCADE 옵션
- 모든 하위요소도 같이 제거한다.
- RESTRICT 옵션
- 스키마의 경우 안에 테이블이 없을때에만, 테이블의 경우 이를 참조하는 다른 테이블이 없을때에만 삭제한다.
ALTER TABLE
- 테이블의 칼럼 추가 혹은 삭제

- 칼럼의 정의 변경
- 테이블에 제약조건 추가/삭제

DROP DEFAULT : 기본값 정의 삭제, SET DEFAULT : 기본값 재정의
CREATE ASSERTION
- 일반적인 제약조건을 선언적으로 만들수 있다.
- 특정 조건을 만족하지 않는 튜플을 선택한다.
- 간단한 CHECK로 확인이 어려울때 사용한다.
- 오라클에 없음.
트리거
- 특정 이벤트/조건 만족시 일어날 일련의 행동을 정의한다.
- 예시 : 부서에 일하는 사원의 수가 일정 수를 넘으면 새로운 입사를 받아들이지 않는다.
- 세가지 요소로 이루어진다.
- EVENT, CONDITION, ACTION

트리거 작성법
CREATE [OR REPLACE] TRIGGER 트리거명
BEFORE or AFTER -- 언제 트리거가 실행될지
INSERT or UPDATE or DELETE ON 테이블명 -- 테이블의 어떤 명령에 트리거가 작동할지
[FOR EACH ROW] -- 각 행에 트리거를 적용할지 지정
[WHEN 조건] -- 트리거의 조건
[DECLARE 변수 선언] -- 트리거에 사용될 변수
BEGIN
트리거 본문 코드 -- 조건에 맞을시 실행할 코드
END 트리거명;
/ -- 줄 끝내기추가 예시
CREATE OR REPLACE
TRIGGER SALARY_VIOLATION
BEFORE INSERT OR UPDATE OF Salary ON EMPLOYEE
FOR EACH ROW
WHEN(NEW.Salary > 100000)
BEGIN
dbms_output.put_line('Salary Cannot Exceed 100000');
RAISE_APPLICATION_ERROR(-20000, 'error occured');
END SALARY_VIOLATION;
/- 월급이 10만이 넘으면 에러가 발생하는 트리거의 예시
추가 사항
- dbms_output.put_line() 로 리포트 가능
- raise_application_error() 로 에러 발생 가능, 에러코드를 argument로 가진다.
- 에러코드는 -20000 ~ -20999 사이여야 한다.
- ALTER TRIGGER SALARY_VIOLATION ENABLE; 로 트리거 활성화
- SET SERVEROUTPUT ON; 로 출력 확인
UNIQUE({쿼리}) 함수
- 결과 쿼리에 중복 튜플이 없으면 TRUE를 리턴한다.

만능 컴덕후 겸 번지 팬