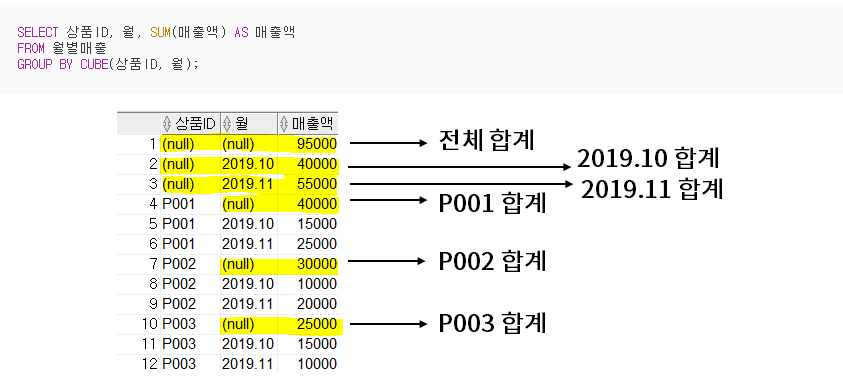
cube
- 모든 경우의 수의 집계를 포함한다.
- 전체 집계가 제일 먼저 나온다.
grouping set

위 테이블에서
SELECT firstname, lastname, COUNT(*) FROM PERSON GROUP BY GROUPING SETS((firstname, lastname), lastname)실행시

- 즉 (firstname, lastname) 그룹과 lastname 그룹을 번갈아 묶는다.
rollup
- 오른쪽에서부터 지워나가며 집계한다
- 전체 집계를 반드시 포함한다.
- 전체 집계가 마지막에 나온다.

논리적 모델링
- 개념, 물리 모델링에 비해 재사용성이 높다.
NULLS LAST
- 오라클 db에서 null을 맨 뒤로 보내고 싶을때 order by 구문의 맨 뒤에 사용한다.
CROSS JOIN
- ON 절로 조건을 추가할수 있다!
UNIQUE INDEX SCAN
- 2개의 속성이 index로 사용시, 2개가 한번에 사용되어야 unique index scan이 가능하다.
NVL2
- NVL2(값, a, b)
- 값이 NULL이 아니면 a, NULL이면 b
모델링
- 처음 : 정규화 수행
- 마지막 : 성능 관점에서 검증
PL/SQL
- 변수에 값을 넣기 위해선 INTO 를 사용한다.
CREATE, TRUNCATE
- DDL은 묵시적으로 COMMIT을 실행한다.
M:N 관계
- 를 해소하기 위해 인위적으로 만든 엔터티는 교차 엔터티
정규화
- 3정규화는 주 식별자와 제일 관련이 없다.
Alias
- Projection alias 의 경우 대소문자가 유지되어 이름이 출력된다.
- alias 가 없으면 대문자로 출력
SUBSTR
- 반드시 오른쪽 방향!
- SUBSTR(문자열, n, m)
- n번째부터 m길이의 부분 문자열
DB의 무결성
- 제약조건, 트리거, 로직을 통해 이룰수 있다.
NULLIF
- NULLIF(A, B)
- A와 B가 같으면 NULL
- A와 B가 다르면 A
LIKE
- _나 %의 유무 조회시 ESCAPE로 escape 문자를 지정해 조회 가능하다.
INSERT
- 기본값이 지정되어도 insert시엔 모든 칼럼을 주거나, 미리 어떤 칼럼 값에 지정 할 지지를 지정해야 한다.
LPAD
- LPAD("내용", 최소길이, 채울내용)
- EX: ("A", 3, "0")
00A
UNION
- union은 동일 테이블 내의 중복 튜플은 제거하지 않는다.
B 트리 인덱스
- 구성한다고 인덱스가 물리적으로 정렬되진 않는다!
- 파티션 키에 대해 인덱스를 생성할수 있다.
인덱스
- 기본키는 인덱스가 자동으로 만들어지며, 이름을 지정할수 있다.
AUTO COMMIT
- SQL SERVER : Auto commit 이 기본
- Oracle DB : Auto commit 이 꺼져 있다.
ER 모델링 표기법

- IE - 선택참여에 원, 필수참여에 선
- Barker - 점선이면 반대편이 선택참여
테이블 분할
- Range Partition
- 값의 범위를 기준으로 행을 분리한다.
- List Partition
- 특정 값을 기준으로 행을 분리한다.
- 어떤 값을 기준으로 할지는 임의로 정할수 있다.
- Hash Partition
- 내부적으로 해시함함수를 사용해 행을 분리한다.
- Composite Partition
- 위 방법들을 복합적으로 사용해 분리한다.
오라클 조인
- (+) 가 붙으면 반대편 방향의 조인이다.
- EX. a.empno = b.mgrno(+)
- == a left outer join b on a.empno = b.mgrno
DCL
- not null, default, type 수정을 위해선 alter modify 사용
- 권한을 부여할수 있는 권한을 박탈당하면 그 사람에게 권한을 받은 사람의 권한도 박탈된다.
- CASCADE는 SQL SERVER엔 없다.
- SQL SERVER는 참조하는 테이블을 먼저 삭제하고 해당 테이블을 삭제한다.
인덱스
- SQL SERVER : null 값을 인덱스 맨 앞에 저장
- ODB : null 값을 인덱스 맨 뒤에 저장
도메인
- 한 속성에는 여러 데이터 타입이 절대 들어갈수 없다.
SELECT 'a', 1 from dual
union all
SELECT 1, 'a' from dual- 'a'와 1은 데이터 타입이 달라 에러가 발생한다.
SQL 처리순서
- FROM
- 어디 테이블에서
- WHERE
- 어떤 행을
- GROUP BY
- 어떤 기준으로 묶어서
- HAVING
- 특정 그룹을 고르고
- SELECT
- 결과 행의 전부 혹은 일부분을
- ORDER BY
- 정렬해서 FETCH.
데이터 모델링
중요 개념
- Thing, Attribute, Relationship
스키마
- 외부/개념/내부 스키마
- 독립적인 의미와 고유한 기능을 가진다.
데이터 모델링 관점
- 데이터
- 업무가 어떤 데이터와 관련이 있는지, 데이터간 관계는 무엇인지
- 프로세스
- 업무가 실제로 하는일은 무엇인지
- 데이터와 프로세스 상관
- 업무가 처리하는 일의 방법에 따라 데이터가 어떻게 영향을 받는지
ERD 작성 방법
- 엔티티를 도출 및 그림
- 엔티티 배치
- 엔티티 관계 설정
- 엔티티 관계 서술
- 관계 참여도 표시
- 관계 필수 여부 표현
좋은 데이터 모델링의 요건
- 중복 배제
- Business Rule
- 완전성
Alias
- from 절에 alias 사용시 select에서는 반드시 이를 사용해야 한다.
- 일반 테이블 이름 사용 불가능
선택도
- 특정 조건에 의해 선택될 것으로 예상되는 레코드의 비율
엔티티
유무형에 따른 분류
- 유형 : 물리적 형태 있음
- 개념 : 물리적 형태 없고 개념적 정보로 구분
- 사건 : 물리적 형태 없고, 업무를 수행하면서 발생
발생시점에 따른 분류
- 기본/키 : 업무에 원래 존재하는 정보
- 중심/메인 : 기본 엔티티로부터 발생, 업무에 중심적인 역할
- 행위 : 두개 이상의 부모 엔티티로부터 발생, 내용이 자주 바뀌고 데이터가 증가
- EX. 주문 변경 이력
속성의 분류
특성에 따른 분류
- 기본 속성
- 설계 속성
- 파생 속성
기타 분류
- 단일 속성
- 하나의 의미로 구성
- 복합 속성
- 여러개의 의미가 있는것, 주소
- 다중값 속성
- 여러개의 값을 가질수 있는 속성
- 엔티티로 분해
카디널리티
- 선택도 * 전체 레코드 수
데이터 모델링의 고려사항
- 중복이 발생하지 않도록
- 비유연성/비일관성이 존재하지 않도록
주 식별자의 조건
- 유일성 - UNIQUE
- NOT NULL
- 최소성
- 대표성
반정규화
- 항상 조회속도가 빨라지진 않음
- 튜플이 너무 길어져서 로우 체이닝, 로우 마이그레이션이 생길수 있다.
식별/비식별 관계
- 식별 관계는 실선
- 부모 테이블의 기본키 또는 유니크 키를 자식 테이블이 자신의 기본키로 사용
- 비식별 관계는 점선
- 부모 테이블의 기본키 또는 유니크 키를 자신의 기본키로 사용하지 않고, 외래 키로 사용하는 관계
슈퍼-서브 타입
One to One
- 서브타입 여러개로
Plus Type
- 슈퍼/서브 타입
All in One - Single
- 슈퍼 타입
특징
- 테이블이 많을수록 확장성 증가, IO 좋음, 조인 나쁨, 관리성 나쁨
DB TYPE
- varchar 과 char은 서로 비교시 공백도 비교한다.
- char끼리 비교할땐 공백 신경 쓰지 않는다.
용어
엔티티
- 테이블
- 2개 이상의 인스턴스, 1개 이상의 속성으로 구성된다.
인스턴스
- 엔티티에 속한 행 ( Row )
반정규화
- 테이블의 중복
- 관계의 중복
- 컬럼의 중복
블록IO
- 로우가 너무 길어 블록을 벗어남 : 로우 체이닝
- 로우 수정시 다른 블록에 저장해야 함 : 로우 마이그레이션
식별자
대체여부
- 본질 식별자 : 업무에 의해 만들어짐
- 인조 식별자 : 원조 식별자가 너무 복잡해 따로 만들어냄
- 모델 / SQL 이 단순해진다!
분산 데이터베이스
- 가용성이 증가한다.
- 병행 작업으로 빠르다.
- 무결성이 줄어들고 구축에 비용과 시간이 많이든다.
분할 투명성
- 하나의 Relation 이 여러 단편으로 분할된다.
위치 투명성
- 데이터의 저장 위치 명시 불필요
지역 사상 투명성
- 지역 DBMS와 물리적 사상이 자동으로 보장된다.
중복 투명성
- DB의 중복 여부를 사용자가 알 필요가 없다.
장애 투명성
- 시스템의 장애와 무관하게 무결성이 유지된다.
병행 투명성
- 여러 트랜잭션이 동시에 수행되어도 ACID가 유지된다.
분산 기법
- 위치 분산
- 분할 분산 : 수직-수평
- 복제 분산 : 부분-광역
- 요약 분산 : 분산-통합
ALTER
- 열 추가시 ADD (타입 이름) 이다.
- ADD COLUMN 아님!
트랜잭션
- ACID
- 무결성 보장, 변경사항 확인, 작업의 그룹화
- 행을 다른곳에서 사용중 ( 락 ) 이면 작업을 미뤄뒀다가 commit이 되면 ( 언락 ) 진행한다.
- 락이 되면 갱신, 조회 불가능.
ORDER BY
- ORACLE 에선 NULL값이 가장 큰 값으로 취급된다.
- NVL(값, 기본값)을 통해 가장 작은값으로 치환해 제일 작은값으로 되도록 할수 있다.
- SQL SERVER에선 NULL 이 가장 작은 값으로 취급된다.
GROUP BY
- HAVING에 집계함수를 통해 그룹의 조건을 정할수 있다.
- NULL 도 GROUP BY 에서 묶일수 있다!
- 그룹 대상이 없으면 그냥 공집합이 된다.
서브쿼리
- 메인쿼리는 서브쿼리의 칼럼을 직접적으로 사용할수 없다!
- 인라인 뷰 제외!
- 단일 행 서브쿼리
- 다중 행 서브쿼리
- 다중 칼럼 서브쿼리
상호연관 서브쿼리
- 서브쿼리가 메인쿼리 행 수만큼 실행
- 속도가 상대적으로 떨어짐, 다양한 활용 가능
서브쿼리 종류
- Access Subquery
- 제공자의 역할을 하는 서브쿼리
- Filter Subquery
- 확인자의 역할을 하는 서브쿼리
- Early Filter Subquery
- 먼저 실행하여 데이터를 걸러내는 서브쿼리리
IN / NOT IN
- NOT IN의 경우 a NOT IN (b) 에서 b에 NULL이 있으면 반드시 무조건 FALSE이다.
- IN의 경우 a NOT IN (b) 에서 b에 NULL이 있고 a가 NULL이여도 FALSE이다.
집합 연산자
- 실행 계획의 분리를 위해 사용되기도 한다.
UNION / UNION ALL
- UNION은 정렬후 중복을 제거한다.
- UNION ALL 은 중복을 제거하지 않는다.
계층형 질의
- START WITH : 시작 위치
- CONNECT BY : 자식 데이터
- ORDER SIBILINGS BY : 형제 노드끼리 정렬
- WHERE : 전부 수행후 만족 값 추출
리프 데이터인지 여부
- CONNECT_BY_ISLEAF
루트 데이터
- CONNET_BY_ROOT
순서
- PK = FK > 부모 -> 자식
- FK = PK > 자식 -> 부모
- 부모 = 자식 > 자식 -> 부모 역방향
- 자식 = 부모 > 부모 -> 자식 순방향
- 즉 거꾸로!
그룹함수

윈도우 함수
NTILE
- NTILE(n) OVER(ORDER BY 칼럼)
- 특정 칼럼 기준으로 1~n 단위를 이용 행을 분리한다.
- n이 3이고 행의 갯수가 9일 경우 1, 1, 1, 2, 2, 2, 3, 3, 3
LAG, LEAD
- LAG(접근컬럼, 얼마나 이전행인지 거리, NULL 대체값) OVER (ORDER BY 정렬컬럼)
- 정렬컬럼으로 정렬 후 접근 컬럼에 대해 특정 행만큼 이전의 값을 가져온다.
- 없으면 NULL 혹은 NULL 대체값을 사용한다.
- 이후 값은 LEAD로 가져올수 있다.
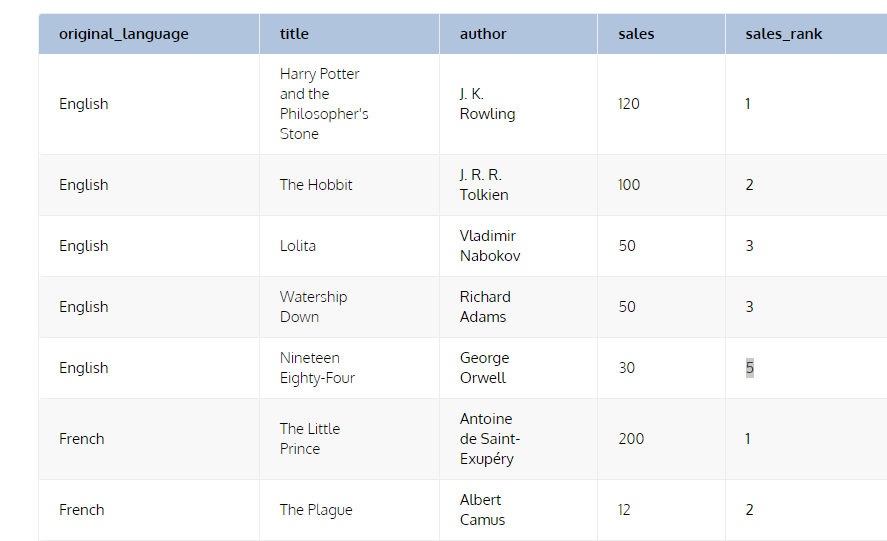
RANK, DENSE_RANK, ROW_NUMBER
- RANK : 1, 2, 2, 4
- 중복 랭크시 그만큼 다음 랭크와 간격이 늘어남
- DENSE_RANK : 1, 2, 2, 3
- 중복 랭크여도 다음 랭크 간격은 1
- ROW_NUMBER : 1, 2, 3, 4
- 중복 값이여도 같은 값이 아니다.
- RANK PARTITION BY
- PARTITION 된 소그룹 내에서 랭크가 주어진다.
- EX. PARTITION BY LANGUAGE
- ENGLISH 끼리 순위, FRENCH 끼리 순위
FIRST_VALUE, LAST_VALUE
- 파티션에서 조건에 맞는 가장 첫번째, 마지막 결과.
CUME_DIST
- 주어진 그룹에 대한 상대적인 누적 분포도 값 반환
PERCENT_WINDOW
- 인수로 지정한 값의 그룹 내 위치를 백분위로 나타냄
SELECT TOP(N) ...
- 결과의 맨 위 N개를 반환한다.
DROP
- 사용자를 제거할때 사용자가 테이블이 있을 경우 CASCADE를 붙혀야 테이블까지 제거가 된다.
TCL
권한 추가
- GRANT 권한 TO 유저
권한 삭제
- REVOKE 권한 FROM 유저
NULL 값
- NOT IN, IN 에서 왼쪽에 포함시 무조건 공집합
- 비교 연산자 사용시 무조건 FALSE
- is null, is not null 을 사용해야 한다.
PL/SQL
- 프로시저와 트리거 둘다 소스코드와 실행코드 생성, 소스코드는 데이터베이스 내에 저장된다.
프로시저
- COMMIT / ROLLBACK 이 가능하다.
트리거
- COMMIT / ROLLBACK 이 불가능하다.
함수
- IN 패러미터만 받는다.
- 성능상의 이점은 없다.
비용기반 옵티마이저
- 단순한 조건의 종류로 일의 양 판단 불가
- access 항목 : 인덱스
- filter 항목 : 비 인덱스
- ALL_ROWS는 옵티마이저의 모드로 행의 갯수와는 연관이 없다!
- 적절한 인덱스가 있더라도 풀스캔이 유리하면 풀스캔을 한다.
비용 기반 옵티마이저 구성
- 질의 변환기 : 처리하기 용이하게 SQL 변환
- 대안 계획 생성기 : 동일한 결과 생성하는 대안 계획 생성
- 비용 예측기 : 생성된 대안 계획의 비용을 예측
규칙 기반 옵티마이저
- 규칙/우선순위 를 가지고 실행계획 생성
- 인덱스 유무, 연산자, 객체 종류로 SQL 실행
효율적 인덱스 구성
- = 조건을 앞에 두어 범위를 제한한다.
- 뒤에 BETWEEN 조건을 둔다
- 부정 조건은 인덱스 구성에 영향을 줄수 없다.
- 인덱스가 아니면 테이블 필터 처리를 줄일수 없다.
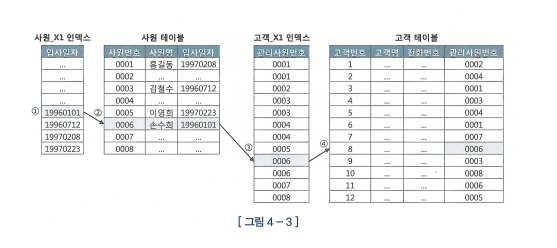
NL조인
- OUTER 에서 조건에 만족하는 첫 ROW 찾기
- 조인 키로 INNER에 해당 값이 존재하는지 찾는다 ( RANDOM ACCESS )
- 값의 존재를 확인시 ROW에 결과를 포함한다. - > 반복
- OUTER에 만족하는 행이 적을수록 유리
- 소량의 값 계산시 유리하다.
- 조인 조건 컬럼은 인덱스가 있어야 한다.
**- 외래키에 인덱스가 없을 경우 불리하다.- sort merge join 을 주로 사용한다.**
테이블 전체스캔 > 인덱스 스캔
HASH조인
- CPU를 많이 쓴다!
- 정렬이 필요없어 대량 작업에 유리하다.
- OUTER에 조건 만족하는 행 찾음
- OUTER 통해 해시 테이블 생성
- 모든 대상 집합이 해시 테이블에 들어가도록
- INNER 집합에서 조건에 맞는 행 찾음
- 즉, 해시 테이블 조회 전에 먼저 조건에 맞는 행을 찾는다.
- INNER 집합 조인 키와 HASH 통해 버킷을 찾는다.
- 성공 시 결과 집합에 포함한다 > 모두 찾을때까지 반복
= 을 사용한 조인만 HASH 조인을 사용할수 있다!
SORT MERGE조인
- NOT EQUAL 조인에서도 사용이 가능하다.
- 선행 테이블에서 조건에 만족하는 행 찾는다.
- 해당 행에서 조인 키 기준 데이터 정렬
- 후행 테이블에서 조건에 만족하는 행 찾는다.
- 해당 행에서 조인 키 기준 데이터 정렬
- 조인 수행
조인 순서
OUTER TABLE, DRIVING TABLE, BUILD TABLE
- 먼저 조인을 수행한다.
INNER TABLE, LOOKUP TABLE, PROBE TABLE
- 조인을 나중에 수행한다.
TRUNCATE
- 테이블의 데이터를 삭제한다.
- ROLLBACK으로 복구 불가능하다.
CASE
CASE 변수
WHEN 값 THEN ---
ELSE ---- 변수와 값이 같은지 확인하는 예시
- 값을 NULL로 비교할수는 없다.
CASE
WHEN 조건 THEN ---
ELSE ---- 값이 아닌 조건으로 확인하는 예시
- DECODE 문법으로 대체 가능
- ELSE가 없을때 WHEN 조건을 전부 만족하지 않으면 NULL이 된다.
DECODE(A, B, 1, 2)- A와 B가 시같으면 1, 다르면 2가 된다.
집계함수
- COUNT를 제외한 나머지 집계함수는 NULL값을 제외한다.
- 어차피 제외되기에 포함된다고 에러가 생기진 않는다!
- NULL을 포함한 행의 경우 행 자체를 제외한다.
- MAX, MIN, COUNT 는 숫자, 문자, 날짜에 적용이 가능하다.
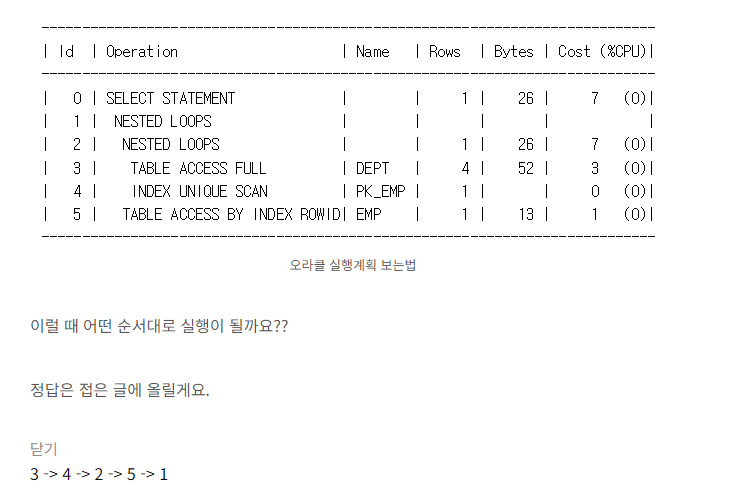
실행계획


- 밖에서 안으로
- 같은 레벨은 위에서 아래로
조인 기법
- NESTED LOOP : NL
- HASH
- SORT MERGE
인덱스 스캔 ( 액세스 기법 )
- 범위 스캔 ( RANGE SCAN )
- 특정 범위 스캔해 대상 레코드들 리턴
- 유일 스캔 ( UNIQUE SCAN )
- 하나의 데이터 추출
- 중복 레코드 비 허용
- = 로 비교
- 랜덤 액세스
- 전체 스캔 ( FULL SCAN )
- 처음부터 끝까지 읽으며 추출
- 추출시 조건에 부합하면 해당 행 리턴
- != 조건에서 주로 사용한다.
- 인덱스 스킵 스캔 ( SKIP SCAN )
- 컬럼 값 정보 이용해 조건에 부합할것 같은 리프 블록만 액세스
- 역순 범위 스캔 ( RANCE SCAN DESCENDING )
- 범위 스캔의 역순, 주로 내림차순에서 사용한다.
최적화 정보
- 통계 정보를 바탕으로 계산한 예상치
SQLD 2024
TOP N Query
- ROWNUM을 사용해 행의 갯수를 제한한다.
- WHERE과 ORDER BY를 같이 쓸 경우 WHERE이 먼저이기에 무작위 데이터 3개중 정렬된 데이터가 출력된다.
- ROWNUM 비교 -> ORDER BY 로 정렬
- 인라인 뷰를 사용한다.
- 오라클이 아닌 경우 TOP(n) 을 사용한다.
- = 비교시 1과는 비교 가능, 그 이상은 결과가 안나온다.
PIVOT
- 식에 있는 열의 값을 회전해 열으로 사용하는것
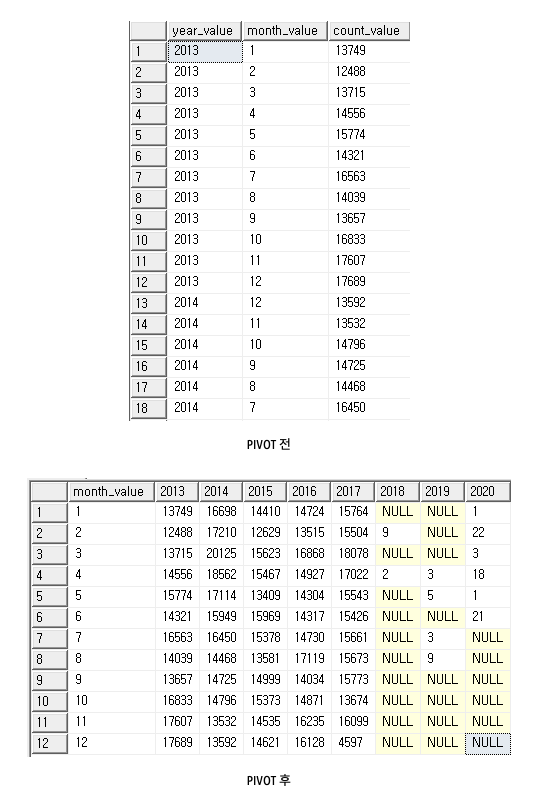
예시


- PRODUCT A, B, C 에 대해 각 Customer에 대한 Quantity의 합

UNPIVOT

- 다시 되돌리기도 가능


정규표현식
- / 로 시작해 /로 끝이 난다.
일치
- * : 해당 문자 0개 이상 일치
- + : 해당 문자 1개 이상 일치
- ? : 해당 문자 0~1개 일치
- . : 임의의 문자 1개
문자열에서의 위치
- ^ : 문자열의 시작
- $ : 문자열의 끝
묶기
- [a-z] : 그룹
- 예시는 모든 소문자
- {n} : n회 일치
- {n,} : 최소 n회 일치
- {,m} : 최대 m회 일치
- {n,m} : 최소 n회 - 최대 m회 일치
정규표현식 함수
REGEXP_LIKE(값, 패턴)
- 패턴에 일치하는지 여부
REGEXP_REPLACE(값, 패턴, 변경)
- 일치한 패턴을 해당 값으로 변경한다.
REGEXP_SUBSTR(값, 패턴)
- 값에서 패턴과 일치한 부분을 반환한다.
REGEXP_INSTR(값, 패턴)
- 일치한 패턴의 시작위치를 반환한다.
REGEXP_COUNT(값, 패턴)
- 패턴이 일치한 갯수를 반환한다.
정규표현식 그룹
- 알파벳
[:alpha:]- 숫자
[:digit:]- 알파벳 + 숫자
[:alnum:]SQL 의 실행 순서
- Parsing > Execution > Fetch
차집합
MINUS
- Oracle DB
EXCEPT
- MSSQL
NoLogging
- INSERT 문의 성능을 향상시키기 위해 Buffer cache 기록을 생략하는 옵션
TO_CHAR()
- 숫자, 날짜, 문자를 지정된 포맷으로 변환한다.
예시
- TO_CHAR(SYSDATE, "yyyy") => 2024
- 현재 날짜에서 연도만 빼내는 포맷을 사용한 것.
ROWID
- Oracle DB 에서 데이터를 구분할수 있는 유일한 값
- select rowid from 테이블명 으로 값을 확인할수 있다.
내부적 형변환
- 숫자 칼럼 EMPNO 에 대해 아래와 같이 비교하면 내부적으로 형변환이 일어난다.
EMPNO LIKE '100%'외래키
- 논리 모델링에서 외래키는 물리 모델에서 구현시 필수가 아닌 선택이다.
계층 쿼리 - CONNECT BY
- Oracle DB 에서 지원, 계층형으로 데이터의 조회가 가능하다.
- START WITH 에서 시작 행의 조건을 적는다.
- EX. 특정 속성이 NULL인 행부터 시작
- CONNECT BY 로 순서를 지정한다.
- CONNECT BY PRIOR A=B
- 윗 행에 해당하는 A가 들어가고, 같은 값의 B속성을 가지는 행이 바로 아래에 들어간다.
- 트리의 깊이 우선 순회와 순서가 유사하다.
계층쿼리와 WHERE
- 계층 쿼리를 모두 실행 후 나온 Row에서 where절을 통해 필터링한다.
키워드
- LEVEL : 검색 항목의 깊이, 1에서 시작한다.
- CONNECT_BY_ROOT : 가장 최상위 값
- CONNECT_BY_ISLEAF : 가장 최하위 값의 여부 표시
- NOCYCLE : 순환 발생 지점까지만 전개
- CONNECT_BY_ISCYCLE : 순환구조 발생지점 표시
- NOCYCLE : 순환 방지
예시
- EMPNO 사원번호
- MGR 해당하는 사원의 매니저의 사원번호
SELECT *
FROM EMP
START WITH MGR IS NULL
CONNECT BY PRIOR EMPNO = MGR- 자신의 매니저가 없는 사람부터 시작 ( 최종 결정권자 )
| EMPNO | MGR |
|---|---|
| 1 | NULL |
| 3 | 1 |
| 4 | 3 |
...
ALL, ANY
WHERE ID <= ALL(30, 40)
==
WHERE ID <= 30 AND ID <= 40WHERE ID <= ANY(30, 40)
==
WHERE ID <= 30 OR ID <= 40CUBE
- 전체 합계를 포함한 모든 경우의 수
- EX. CUBE(A, B)
- 전체합
- 특정 A일때 합
- 특정 B일때 합
- A, B 조합에서의 합
INDEX 사용 불가능한 경우
- NVL 로 널밸류 검사
- 형변환
- 문자열을 결합
Index Organized Table
- 테이블을 참조하지 않는 인덱스
- ORGANIZATION INDEX 를 맨 뒤에 붙힌다.
ROWNUM
- ROWNUM을 이용해 2개 이상의 행을 가져오기 위해선 Inline view를 사용해야 한다.
SELECT *
FROM ( SELECT ROWNUM FROM ** )
WHERE ROWNUM < 4BCNF (Boyce-Codd Normal Form)은 데이터베이스 정규화 과정에서 사용되는 높은 수준의 정규형 중 하나입니다. BCNF는 관계형 데이터베이스에서 데이터의 중복을 최소화하고 무결성을 유지하기 위해 고안된 규칙 집합입니다. BCNF는 제3정규형(3NF)을 강화한 형태로, 다음과 같은 조건을 만족해야 합니다:
- 제3정규형(3NF): BCNF는 기본적으로 제3정규형을 만족해야 합니다. 즉, 모든 속성이 기본 키가 아닌 속성에 대해 이행적 함수 종속성을 가지지 않아야 합니다.
- 모든 결정자가 후보 키여야 함: BCNF는 테이블의 모든 함수적 종속성 ( X \rightarrow Y )에 대해, ( X )가 반드시 후보 키(Candidate Key)여야 한다는 추가 조건을 부과합니다. 후보 키는 테이블에서 유일하게 식별 가능한 최소한의 속성 집합입니다.
이 조건을 충족하면 데이터베이스 스키마는 BCNF에 속한다고 할 수 있습니다. 예를 들어, 아래와 같은 테이블을 생각해 봅시다:
예시
| StudentID | CourseID | Instructor |
|---|---|---|
| 1 | Math | Dr. Smith |
| 2 | Math | Dr. Smith |
| 3 | History | Dr. Brown |
여기서 함수적 종속성은 다음과 같습니다:
- ( {StudentID, CourseID} \rightarrow Instructor )
- ( CourseID \rightarrow Instructor )
위의 함수적 종속성을 보면, ( CourseID \rightarrow Instructor )가 존재합니다. 이 경우 ( CourseID )는 후보 키가 아니므로, 이 테이블은 BCNF를 만족하지 않습니다. 이를 BCNF로 변환하려면 다음과 같은 두 테이블로 분리할 수 있습니다:
-
Course_Instructor 테이블:
| CourseID | Instructor |
|----------|------------|
| Math | Dr. Smith |
| History | Dr. Brown | -
Student_Course 테이블:
| StudentID | CourseID |
|-----------|----------|
| 1 | Math |
| 2 | Math |
| 3 | History |
이제 모든 결정자가 후보 키이므로, 두 테이블 모두 BCNF를 만족하게 됩니다.
이와 같이, BCNF는 데이터베이스 스키마에서 모든 함수적 종속성의 결정자가 후보 키가 되도록 함으로써 데이터의 무결성과 중복을 최소화하는 정규형입니다.
