이전 프로젝트에서 Redis를 cache로 활용하여 검색api에 대한 속도를 증가하였습니다.
하지만 프로젝트 기간에 맞춰 기능 구현을 하였고, Redis를 활용한 cache구현에 대한
고찰이 없었습니다.
이에 다시 한번 Redis에 대한 개념부터 설계를 위한 지침까지 글을 올려 공부하려 합니다.Redis란?
- Redis는 Remote Dictionary Server의 약자로서 '키-값'(key-value) 구조의 비 관계형 데이터를 저장하고 관리하기 위한 노에스큐엘(NoSQL)의 일종.
- Redis는 In-Memory 솔루션으로도 분류되는데, 이는 다양한 데이터 구조체를 지원하여 DB, Cache, Message Queue, Shared Memory 용도로 사용할 수 있다.
- 일반 데이터베이스와 달리 Redis는 메모리(Ram)에서 데이터를 처리하기 때문에 비교적 용량이 작지만 작업속도가 매우 빠르다.
Redis 사용
빠른 성능
기존 데이터 베이스 관리 시스템과 다르게 Redis 데이터는 서버의 주 메모리에 상주한다.
Redis와 같은 인 메모리 데이터베이스는 디스크에 액세스해야 할 필요를 없앰으로써 검색 시간으로 인한 지연을 방지하고 CPU 명령을 적게 사용하는 좀 더 간단한 알고리즘으로 데이터에 액세스할 수 있습니다.
In_Memory
Redis를 사용하면 사용자가 다양한 데이터 유형에 매핑되는 키를 저장할 수 있습니다.
이는 거의 모든 유형의 데이터가 Redis를 사용하여 인 메모리에 저장될 수 있습니다.
다양성 & 사용 편의성
Redis는 개발과 운영을 좀 더 쉽고 좀 더 빠르게 수행할 수 있는 여러 가지 도구를 제공한다.
이에 Pub/Sub는 메시지를 채널에 게시하며, 채널에서 구독자에게 전달하고, 때문에 채팅과 메시징 시스템에 매우 적합하다.
TTL 키는 해당 기간 후에는 스스로를 삭제하는 지정된 Time To Live 값을 가질 수 있다.
DB를 불필요한 데이터로 채우지 않도록 하는 데 유용하다.
원자성 카운터는 경합 상태가 일관성 없는 결과를 생성하지 않도록 한다.
복제 및 지속성
Redis는 안정성을 제공하기 위해 특정 시점 스냅샷과 데이터가 변경될 때마다 이를 디스크에 저장하는 Append Only File_AOF 생성을 모두 지원한다.
때문에 두 방법으로 장애 발생 시 Redis 데이터를 신속하게 복원할 수 있다.
뿐만 아니라 Redis는 비동시식 복제를 지우너하여 데이터가 여러 슬레이브 서버에 복제 될 수 있다. 때문에 주 서버에 장애가 발생하더라도 여러 서버로 분산하여 향상된 읽기 및 복구 기능을 제공할 수 있다.
다수 언어 지원
Redis를 사용하기 위해 백개가 넘는 오픈 소스 클라이언트를 사용할 수 있고,
다수의 언어 또한 지원된다.
Redis 사용 사례
Caching
다른 데이터베이스보다 앞에 배치된 Redis는 성능이 뛰어난 인 메모리 캐시를 생성하여 액세스 지연 시간을 줄이고, 처리량을 늘리며, 관계형 또는 NoSQL 데이터베이스의 부담을 줄여준다.
Session 관리
Redis를 세션 키에 대한 적절한 TTL과 함께 빠른 키 값 스토어로 사용하면 간단하게 세션 정보를 관리할 수 있다. 세션 관리는 주로 온라인 애플리케이션에 필요하다.
실시간 순위표
Redis Sorted Set 데이터 구조를 사용하여 요소가 목록에 유지되고 점수에 따라 정렬시킬 수 있다. 이를 활용하여 동적 순위표를 생성할 수 있다.
속도 제한
Redis는 이벤트 속도를 측정하고 필요한 경우 제한할 수 있다. 클라이언트의 API 키에 연결된 Redis 카운터를 사용하여 특정 기간 동안 액세스 요청의 수를 세고 한도가 초과되는 경우 조치를 취해 제한이 가능하다.
대기열
Redis List 데이터 구조를 사용하면 영구 대기열을 구현할 수 있다.
이는 자동 작업 처리 및 차단 기능을 제공하므로 신뢰할 수 있는 메세지 브로커로 사용이 가능하다.
Redis 주의사항
싱글쓰레드_시간 복잡도
Redis는 싱글 쓰레드 기반으로 돌아간다.
때문에 한 번에 한가지 명령만 실행하기 때문에 처리시간이 긴 명령어에는 불리하고,
해당 요청 건을 처리하기 위해 다른 서비스 요청을 처리할 수 없다.
때문에 전체 데이터를 다루거나 시간 복잡도 O(N)에 대해 주의해서 설계해야한다.
메모리 파편화
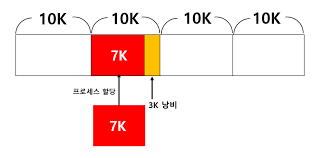
위 그림처럼 여유 저장공간이 10K *4 일때, 7K에 해당하는 프로세스를 할당 하려 한다면 3K에 저장공간이 낭비가 된다.
결국, 이러한 현상이 반복되면, 실제 물리 메모리가 커져 프로세스에 문제를 야기한다.
때문에 Redis를 사용할 때 메모리를 여유있게 사용해야한다.
안그래도,,, 용량적은데 여유있게 사용해야한다...
때문에 이후 계속될 포스팅에서 Redis를 효과적으로 사용하기 위한 방법과 전략을 기재할 것이다.
