
회사에 재직한지 6개월이 됬습니다. 그동안에 회사 프로덕트를 클린아키텍처로 전환하는 과정에 대해서 기록을 남기고자 글을 작성합니다. 이 6개월 동안에도 수많은 개발에 대해 회고하게 되는 일들이 있었습니다. 매일이 배움의 연속이고 그로인해 항상 저의 부족함에 겸손해지는 일상을 보내고 있습니다.
1. 로버트 마틴(Robert C. Martin) 클린 아키텍쳐 vs Google의 앱 아키텍쳐
Google의 안드로이드 공식문서에서 가이드 되는 앱 아키텍쳐는 클린 아키텍쳐가 아닙니다. 그렇기 때문에 둘에는 차이점이 있습니다.
1. Presentation layer는 Domain layer를 알고 있는가? : 둘다 알고 있습니다.
2. Domain layer는 Data layer를 알고 있는가? : 구글 앱의 아키텍쳐만 알고 있습니다.
3. Data layer는 Domain layer를 알고 있는가? : 클린 아키텍쳐만 알고 있습니다.
위의 차이점을 인지하고 구글에서 제공하는 방법대로 구현하는게 아닌 클린 아키텍쳐에서 추구하는 구조로 개발을 진행을 했습니다. 그렇다면 이러한 의문이 들 수 있습니다.
왜 구글에서 제공하는 아키텍처를 사용하지 않고, 클린 아키텍처로 개발을 하시나요?

위의 그림은 공식문서의 Domain Layer 가 Data Layer 를 의존하고 있음을 보여주는 그림입니다. 기본적으로 구글 권장 앱은 도메인 레이어는 필수가 아니라 optional 입니다. 여기서 도메인 레이어는 애플리케이션의 주요 기능과 규칙을 정의하기 위함은 아닙니다. 그저, 도메인 레이어를 통해서 서로 다른 View 에서 중복적으로 쓰이는 비즈니스 로직을 재활용을 하는것이 목적인 것 입니다.
하지만, 도메인 레이어를 클린아키텍처의 측면으로 정의하게 된다면 도메인 영역은 애플리케이션의 핵심 비즈니스 로직을 포함하고, 애플리케이션의 주요 기능과 규칙을 정의합니다. 따라서 도메인 영역은 비즈니스 요구사항에 집중하고, 특정 데이터베이스나 외부 리소스와의 구체적인 구현에 직접 의존하지 않을 수 있습니다. 그러면 왜 구글에서 제공하는 아키텍처를 사용하지 않고, 클린 아키텍처로 개발을 하게 되었는지 좀더 상세히 알아보도록 하겠습니다.
1. 변경에 대한 취약성 해결
도메인 영역의 유스케이스와 리포지토리가 직접 의존하면, 리포지토리의 구현이 변경될 경우 유스케이스 코드도 함께 변경해야 합니다. 이는 개발자들이 변경에 대한 영향을 파악하는 데 어려움을 줄 수 있으며, 의존성이 높은 코드를 수정할 때 버그가 발생할 가능성을 높일 수 있습니다.
2. 유닛 테스트의 어려움 해결
도메인 영역의 유스케이스가 리포지토리에 직접 의존하면 유닛 테스트 작성이 어려워질 수 있습니다. 외부 리포지토리를 사용하는 경우, 테스트할 때마다 실제 데이터베이스나 외부 서버와 통신해야 할 수도 있습니다. 물론, 직접 의존하더라도 Mocking을 사용하여 외부 리포지토리를 가짜 객체로 대체하여 테스트할 수 있지만, 외부의 data 에 대한 의존성없이 도메인 영역의 비즈니스 로직만으로 Test 를 진행할 수 있다면, 앱 핵심 비즈니스 로직만을 별도로 프로덕트를 구현 및 테스트 할 수 있는 환경이 되어 앱이 독립적으로 개발될 수 있는 유리한 환경 조성이 됩니다.
3. 프레임 워크와의 종속성 탈피
프레임워크를 준비하지 않더라도 필요한 유스케이스 전부에 대해 단위 테스트를 할 수 있게 됩니다. 개발 환경 문제나 도구에 대해서는 결정을 따로 분리 진행 할 수 있습니다. 즉, 도메인을 그대로 고정하고 프레임워크가 서로 다르게 적용되는 (KMM 의 Android & IOS) Presentaion Layer 를 따로 개발하면서, 나머지 데이터 레이어 측면이 정해지면, 그 때 추가적으로 개발을 할 수도 있습니다.
4. KMM 멀티플랫폼으로 전환을 염두
코틀린 코드로 비즈니스 로직을 공유하는 KMM 멀티플랫폼으로 전환을 염두하여 클린아키텍처를 채택하게 되었습니다. Android, IOS 개발 시 ui 레이어를 제외한 동일하게 처리해야 하는 비지니스 로직 처리를 KMM에서 순수 Kotlin으로 작성되고 이를 컴파일된 코드가 각 플랫폼에서 사용할 수 있게 해줍니다.
2. 클린 아키텍처란?
위에서 클린아키텍처를 채택하여 개발하게 되는 이유를 알았습니다. 저러한 이점이 있다면, 장기적인 프로젝트가 될 시에는 관리되는 코드가 커지기 때문에 유지보수의 용의함을 위해서 사용 안할 이유가 없을 것 입니다. 그렇다면 우리는 클린아키텍처를 적용하기 위해 클린아키텍처가 무엇인지 더 자세히 관련 개념에 대해서 알아보도록 하겠습니다.
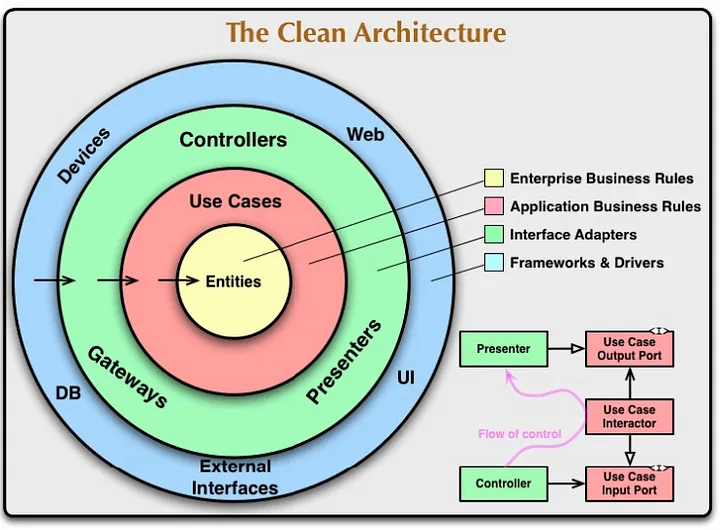
클린 아키텍처를 구글에 검색하면 가장 많이 나오는 원형 다이어그램입니다. 이 그림을 이해하게 된다면, 클린아키텍처가 무엇인지 남에게 설명할 수 있다고 볼 수 있습니다. 그러면 우선 그림에 있는 용어들부터 같이 이해해보도록 하겠습니다.
1. Entity
클린 아키텍처에서 엔티티(Entity)는 'Enterprise wide business rules'를 캡슐화하는 요소로서, 애플리케이션의 비즈니스 도메인에서 중요한 개념들을 표현하는 클래스 입니다. 엔티티는 프레임워크나 기술적인 세부사항과는 독립적이며, 애플리케이션 전반에서 사용되는 핵심 비즈니스 로직을 담고 있습니다. 예를 들어, 주문 시스템을 가정해보겠습니다. 주문을 나타내는 Order 엔티티는 아래와 같이 클래스로 구현될 수 있습니다.
data class Order(
val orderId: String,
val customerName: String,
val orderDate: Date,
val totalAmount: Double
)
참고 : "Enterprise wide business rules"는 기업이나 조직 전체의 영업 활동이나 운영을 규정하는 비즈니스 규칙들을 가리킵니다. 이런 규칙들은 해당 기업이나 조직이 어떻게 동작해야 하는지, 어떤 기준을 준수해야 하는지를 정의하며, 모든 시스템과 프로세스에 적용되는 일반적인 원칙이나 정책을 포함할 수 있습니다.
예를 들어, 기업의 비즈니스 규칙은 다음과 같은 것들을 포함할 수 있습니다.
- 주문이 처리되기 위한 최소 금액
- 특정 상품에 대한 할인 적용 규칙
- 고객이 특정 서비스에 대한 접근 권한을 가지기 위한 조건
이러한 규칙들은 기업의 전반적인 전략과 목표를 달성하는 데 중요한 역할을 하며, 클린 아키텍처의 엔티티(Entity)에서 중요하게 다루어집니다.
2. 유스케이스(Use Case)
사용자의 관점에서 시스템이 어떻게 동작하는지를 정의합니다. 그래서 이는 비즈니스 요구사항을 반영하여 사용자와 시스템 간의 상호작용을 기준으로 CreateOrderUseCase 와 같이 이름을 붙이게 됩니다.
클린 아키텍처에서, 유스케이스 계층은 애플리케이션의 비즈니스 로직을 포함하며, 엔티티를 조작하여 사용자의 요구를 수행하게 됩니다. 즉, 사용자의 입력에 따라 데이터를 변환하고, 비즈니스 규칙에 따라 그 변환을 수행하는 역할을 담당하게 됩니다.
예를 들어, 앞서 언급된 주문 시스템에서 '주문 생성'이라는 유스케이스를 고려하면 이 유스케이스는 다음과 같은 단계로 나타낼 수 있습니다.
1. 사용자가 주문 정보(고객 이름, 주문 날짜, 주문 총액 등)를 입력합니다.
2. '주문 생성' 유스케이스는 이 정보를 받아서 주문 엔티티(Order)를 생성합니다.
3. 생성된 주문 엔티티는 비즈니스 규칙을 확인합니다. (예: 주문 금액이 최소 주문 금액보다 큰지 확인)
4. 비즈니스 규칙을 모두 만족하면 주문 엔티티는 저장되고, 주문이 성공적으로 생성된 것에 대한 response 를 반환하게 됩니다.
이렇게 유스케이스는 사용자의 입력을 받아서 엔티티를 생성하고, 엔티티에 캡슐화된 비즈니스 규칙에 따라 동작하게 됩니다. 이 과정에서 비즈니스 로직이 실행되는 것입니다. 유스케이스는 이와 같이 사용자의 요구사항을 충족시키기 위해 필요한 작업을 담당하며, 각 유스케이스는 사용자가 요구한 한 가지 특정한 작업을 수행해서 엔티티에 캡슐화된 비즈니스 규칙들을 달성하게 된다고 볼 수 있습니다.
다음으로, 주문을 생성하는 유스케이스의 예를 아래의 코드로 보겠습니다.
class CreateOrderUseCase @Inject constructor(
private val orderRepository: OrderRepository
) {
suspend operator fun invoke(
orderId: String,
customerName: String,
orderDate: Date,
totalAmount: Double,
minimumOrderAmount: Double
): OrderResponseModel {
if (totalAmount < minimumOrderAmount) {
throw IllegalArgumentException("Order amount must be greater than minimum order amount")
}
val order = Order(orderId, customerName, orderDate, totalAmount)
return orderRepository.save(order)
}
}
1. 유스케이스와 엔티티 (비즈니스 로직)
CreateOrderUseCase는 비즈니스 규칙을 캡슐화합니다. 여기서 비즈니스 규칙은 주문 정보를 입력으로 받아서 주문 엔티티를 생성합니다. 그리고 그 주문의 총액이 최소 주문액보다 큰지를 검사합니다. 만약 주문액이 최소 주문액보다 작으면, 유스케이스는 예외를 발생시킵니다. 만약 주문액이 최소 주문액보다 크면, 주문 엔티티는 저장소에 저장되고 반환됩니다.
이렇게 유스케이스는 사용자의 요구(주문 생성)를 처리하고, 비즈니스 규칙(최소 주문액 검사)을 적용하는 역할을 합니다. 이 유스케이스는 OrderRepository 인터페이스에 의존하고 있지만, 실제 데이터 저장 방식 (DB, 메모리, 클라우드 등)에 대해서는 알지 못합니다.
2. 인터페이스 (추상화)
위 코드에서 OrderRepository는 Order Entity를 CRUD(Create, Read, Update, Delete)하기 위해서 사용되는 인터페이스입니다. 실제 구현 방식과 독립적인 형태를 갖고 있습니다. 이렇게 함으로써 데이터 소스의 변경 (예: 로컬 DB에서 원격 서버로 변경)에도 유스케이스 코드는 변경되지 않습니다.
3. 외부 구현
OrderRepository의 실제 구현 (예: OrderDatabaseRepository, OrderMemoryRepository 등)은 유스케이스와 분리된 외부 층에서 이루어집니다. 이 구현은 DB나 메모리 등의 실제 데이터 저장 방식에 따라 달라지며, 이 변경이 유스케이스나 엔티티에 영향을 주지 않습니다.
4. 예제 상황
데이터 저장 방식을 로컬 데이터베이스에서 클라우드 기반의 원격 서버로 변경한다고 가정해보겠습니다.
-
기존: OrderDatabaseRepository는 OrderRepository 인터페이스를 구현하고 로컬 데이터베이스에 주문을 저장합니다.
-
변경 후: OrderCloudRepository라는 새로운 클래스를 만들어 OrderRepository 인터페이스를 구현하고 원격 서버에 주문을 저장합니다.
이 변경을 하더라도 CreateOrderUseCase는 영향을 받지 않습니다. 왜냐하면 유스케이스는 OrderRepository 인터페이스에만 의존하고 있기 때문입니다. 이렇게 클린 아키텍처는 세부 구현의 변경이 비즈니스 로직에 영향을 주지 않도록 합니다.
3. 인터페이스 어댑터(Interface Adapter)
클린 아키텍처의 한 부분으로, 외부 세계(프레임워크, UI, 데이터베이스 등)와 애플리케이션의 비즈니스 로직을 이어주는 역할을 합니다. 이 계층의 주요 목적은 내부와 외부 사이에서 데이터 형식을 변환하고, 애플리케이션의 비즈니스 로직을 프레임워크와 기술적인 세부사항으로부터 격리하는 것입니다.
이 계층의 이름에서도 알 수 있듯이, 인터페이스 어댑터는 "어댑터 패턴"을 사용합니다. 어댑터 패턴은 서로 호환되지 않는 인터페이스를 연결하여 함께 작동하게 하는 디자인 패턴입니다. 이 패턴을 사용함으로써, 인터페이스가 변경되더라도 내부 비즈니스 로직이 그에 따라 수정되지 않도록 보장할 수 있습니다.
예를 들어, 앞서 언급했던 주문 시스템에서 '주문 생성' 유스케이스를 수행하는 경우를 본다면, 이 과정에서 클라이언트측 어댑터 패턴을 사용하는 경우와 서버측 어댑터 패턴을 사용하는 경우가 존재하게 됩니다. 각각에 대해 통합적으로 아래에서 정리를 해보도록 하겠습니다.
- 클라이언트 측으로 어댑터 패턴을 사용하는 경우는, View에 정보를 입력하고 '주문 생성' 기능을 수행합니다. 그러면, 유스케이스는 View의 정보를 받아서 OrderModel 를 생성합니다. 위 Model 은 Domain Layer 의 Model 이기 때문에 Data Layer 의 Entity로 변환이 되야 합니다. 이 과정에서 OrderModel이 로컬 혹은 리모트 DB 에 CRUD 하기 위한 목적인 첫번 째 인터페이스 어댑터가 되는 레포지토리에서 Data Layer 의 Entity로 변환됩니다. 두번 째 인터페이스 어댑터로 ClientApiService(Retrofit 의 ConverterFactory)가 HTTP 요청을 하기 위해서 Data Layer 의 Entity 를 Json Data 으로 변환해서 서버 애플리케이션에 전달됩니다.
- 서버 측으로 어댑터 패턴을 사용하는 경우는, Controller 인터페이스 어댑터는 HTTP 요청의 형식에서 서버 애플리케이션이 이해할 수 있는 형식으로 데이터를 변환하는 역할을 합니다.
이 경우 또한, 애플리케이션에서 주문이 성공적으로 생성되었다는 응답을 생성하면, 인터페이스 어댑터는 이 응답을 HTTP 응답의 형식으로 변환하여 사용자에게 반환합니다.
- 이렇게 반환 된 Response 를 우리의 안드로이드와 같은 클라이언트가 받아서 또 클라이언트 애플리케이션이 이해할 수 있는 형식으로 데이터를 변환하게 되는데 이 경우에는 클라이언트 측 레포지토리와 ClientApiService가 어댑터가 됩니다. 아까와는 반대로 Json Data 를 Entity 객체로 변한해주고 Entity 객체는 Model로 변환해서 반환하게 됩니다.
우리는 이제 대략적인 클라이언트와 서버가 어떻게 인터페이스 어댑터(Interface Adapter) 를 통해서 서로 데이터를 변환 하면서 통신을 하는지 알게되었습니다. 그렇다면 안드로이드에서 구체적으로 어떻게 코드로 구현되는지 추가적으로 자세히 알아보도록 하겠습니다.
data class Order(
val orderId: String,
val customerName: String,
val orderDate: Date,
val totalAmount: Double
)
@HiltViewModel
class OrderViewModel @Inject constructor(
private val createOrderUseCase: CreateOrderUseCase
) : ViewModel() {
fun createOrder(
orderId: String,
customerName: String,
orderDate: Date,
totalAmount: Double
) {
viewModelScope.launch {
val order = createOrderUseCase(orderId, customerName, orderDate, totalAmount)
// Handle the created order
}
}
}
class CreateOrderUseCase @Inject constructor(
private val orderRepository: OrderRepository
) {
suspend operator fun invoke(
orderId: String,
customerName: String,
orderDate: Date,
totalAmount: Double,
minimumOrderAmount: Double
): OrderResponseModel {
if (totalAmount < minimumOrderAmount) {
throw IllegalArgumentException("Order amount must be greater than minimum order amount")
}
val order = Order(orderId, customerName, orderDate, totalAmount)
return orderRepository.save(order)
}
}
class OrderRepository @Inject constructor(
private val apiService: ApiService
) {
suspend fun save(order: Order): OrderResponseModel {
val orderResponse = apiService.createOrder(OrderRequest.from(order))
return OrderResponse.toOrderResponseModel(orderResponse)
}
}
//data layer 의 OrderResponse 를 domain layer 를 의존하여 OrderResponseModel 형변환 해서 반환.
interface ApiService {
@PUT("order")
suspend fun createOrder(@Body orderRequest: OrderRequest): OrderResponse
}
위 예제 코드를 통해서 위의 글에 대한 상세한 이해를 같이 해보겠습니다.
1. OrderViewModel의 createOrder 메소드는 '주문 생성'이라는 비즈니스 로직을 담당합니다. 이 메소드는 주문 ID, 고객 이름, 주문 날짜, 총액을 입력으로 받아 CreateOrderUseCase를 실행합니다.
2. CreateOrderUseCase는 주문 총액이 최소 주문액 이상인지 검사하고, 조건이 충족되면 OrderRepository의 save 메소드를 호출하여 주문을 저장합니다.
3. OrderRepository의 save 메소드는 ApiService의 createOrder 메소드를 호출하여 주문 생성 요청을 서버에 보냅니다. 이때 OrderRequest 객체를 생성하여 요청 본문으로 사용합니다.
4. ApiService의 createOrder 메소드는 주문 생성 API를 호출하는 역할을 합니다. 만약 이 API의 경로나 요청 형식이 변경된다면 이 메소드만 수정하면 됩니다. 이런 변경이 OrderViewModel의 createOrder 메소드에는 전혀 영향을 미치지 않습니다. 이는 OrderRepository가 ApiService의 변경 사항을 적절히 처리하고 그 결과를 OrderResponseModel 객체로 변환하기 때문입니다. 어떻게 적절히 처리하는지에 대해서 세부적으로 설명해 보겠습니다.
- 1. ApiService의 변경 : 웹 서비스의 API 경로, 요청 형식, 응답 형식 등이 변경될 수 있습니다. 예를 들면, 처음에는 createOrder API가 JSON 형식의 데이터를 반환했는데, 나중에는 XML 형식으로 바뀔 수 있습니다. 이러한 변경이 생기더라도, OrderRepository는 이를 적절하게 처리하고 내부 로직에 전달할 수 있어야 합니다.
- 2. JSON을 Entity로 맵핑 : 웹 서비스로부터 받은 데이터는 대개 원시 형식 (JSON, XML 등)입니다. 이 데이터를 앱 내에서 처리하기 용이한 형태, 예를 들면 코틀린 또는 자바의 객체로 변환해야 합니다. 이 과정에서 데이터는 'Entity'로 맵핑될 수 있습니다.
- 3. Entity를 Domain Model로 변환 : Entity가 도메인 로직을 포함하는 중심 계층 (도메인 레이어)으로 전달될 때, 이 Entity는 Domain Model로 변환될 수 있습니다. Domain Model은 비즈니스 규칙 및 로직을 표현하며, Entity와는 다르게 외부 세계의 변화 (예: 데이터베이스 스키마 변경, API 응답 구조 변경 등)에 의존적이지 않아야 합니다.
이처럼 ApiService와 OrderRepository는 '주문 생성'이라는 유스케이스의 구현에 필요한 외부 서비스와 내부 로직 사이의 '어댑터' 역할을 합니다. 아래에 추가적인 요약 설명을 더 하겠습니다.
-
ApiService (Network Adapter): 실제 네트워크 호출을 추상화합니다. 이곳에서는 Retrofit, OkHttp, Gson 등 외부 라이브러리나 프레임워크를 활용하여 웹 서비스와의 통신을 처리하게 됩니다. 서비스의 응답 (보통은 JSON)을 앱에서 사용할 수 있는 데이터 형식, 즉 Entity 클래스로 변환합니다. 이러한 변환 과정을 통해, 네트워크의 세부 구현 (예: 통신 방식이나 데이터 형식)이 앱의 내부 로직에 영향을 주지 않게 합니다.
-
OrderRepository (Data Adapter): 데이터 소스 (DB, API, 메모리 캐시 등)와 앱의 도메인 로직 사이의 어댑터 역할을 합니다. OrderRepository는 데이터를 가져오고, 필요에 따라 변환하여 도메인 레이어로 전달합니다. 이 때, Entity를 Domain Model로 변환하는 과정이 포함될 수 있습니다. 또한, 여러 데이터 소스 사이에서 데이터를 동기화하는 로직도 OrderRepository 내부에서 처리될 수 있습니다.
따라서, ApiService와 OrderRepository 둘 다 각각의 레벨에서 어댑터 역할을 하지만, 그들이 중점적으로 다루는 관심사는 다릅니다. ApiService는 네트워크와의 통신에 초점을 맞추고, OrderRepository는 앱의 비즈니스 로직과 데이터 소스 사이의 교량 역할에 초점을 맞춥니다.
즉, 위의 이야기를 다시 정리하자면 인터페이스 어댑터는 외부 세계(예: HTTP, SQL, 외부 API 등)의 세부사항과 애플리케이션의 비즈니스 로직 사이에서 중개자 역할을 하여, 두 영역을 격리시킵니다. 이를 통해 비즈니스 로직은 순수하게 비즈니스 규칙에만 집중하고, 인프라스트럭처나 프레임워크 등의 세부사항에 의존하지 않도록 만들어줍니다. 이는 시스템의 유연성을 높이고, 유지보수를 쉽게 하며, 테스트를 용이하게 합니다.
4. 프레임워크와 드라이버(Frameworks & Drivers)
클린 아키텍처에서 프레임워크와 드라이버는 어플리케이션의 가장 바깥쪽 계층인 '프레임워크 및 드라이버' 계층에 속합니다. 이 계층에는 웹 프레임워크, 데이터베이스, UI, 외부 라이브러리 등이 포함될 수 있습니다. 안드로이드 개발에 있어서 프레임워크 및 드라이버는 아래와 같이 이해할 수 있습니다.
1. 프레임워크
안드로이드 앱 개발에 필요한 모든 기본 API를 포함하고 있습니다. 예를 들어, Activity와 Fragment, Service, ContentProvider, BroadcastReceiver 등의 클래스와 인터페이스, 그리고 AndroidManifest.xml 등의 구성 요소가 포함됩니다. 또한, 이 계층에는 개발자가 선택하여 사용할 수 있는 추가적인 프레임워크나 라이브러리도 포함됩니다. 예를 들어, Jetpack, Retrofit, Room, Glide 등의 라이브러리가 이에 해당합니다.
예를 들면, 안드로이드 프레임워크와 관련된 코드는 주로 액티비티, 프래그먼트 등에서 볼 수 있습니다. 이들은 사용자 인터페이스(UI) 및 생명주기 관리와 같은 프레임워크의 기능을 사용합니다.
class MainActivity : AppCompatActivity() {
private val viewModel: MainViewModel by viewModels()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
viewModel.data.observe(viewLifecycleOwner) {
// Update UI
}
}
}
또한, 개발자가 선택하여 사용할 수 있는 추가적인 라이브러리들을 사용하는 것도 볼 수 있습니다. 예를 들어, 네트워크 요청을 처리하기 위해 Retrofit을 사용하는 경우, 아래와 같이 구성할 수 있습니다.
interface ApiService {
@GET("endpoint")
suspend fun getData(): Response<Data>
}
class RetrofitInstance {
companion object {
private val retrofit by lazy {
Retrofit.Builder()
.baseUrl(BASE_URL)
.addConverterFactory(GsonConverterFactory.create())
.build()
}
val api by lazy {
retrofit.create(ApiService::class.java)
}
}
}
2. 드라이버
이는 어플리케이션과 외부 시스템 간의 인터페이스를 담당하는 구성 요소를 의미합니다. 안드로이드 앱에서는 이들이 주로 데이터베이스, 네트워크, 센서 등의 하드웨어와의 인터페이스를 제공하는 역할을 합니다. 예를 들어, SQLiteOpenHelper나 Room Database가 이에 해당하며, 네트워크 요청을 처리하는 Retrofit 인스턴스 또는 센서와 통신하는 SensorManager도 이 계층에 속합니다.
예를 들면, 아래 예시는 SQLiteOpenHelper를 이용하여 데이터베이스를 처리하는 예시입니다.
class DatabaseHelper(context: Context) : SQLiteOpenHelper(context, DATABASE_NAME, null, DATABASE_VERSION) {
override fun onCreate(db: SQLiteDatabase) {
val createTable = "CREATE TABLE $TABLE_NAME (" +
COL_ID + " INTEGER PRIMARY KEY," +
COL_NAME + " TEXT)"
db.execSQL(createTable)
}
override fun onUpgrade(db: SQLiteDatabase, oldVersion: Int, newVersion: Int) {
db.execSQL("DROP TABLE IF EXISTS $TABLE_NAME")
onCreate(db)
}
}또는 Room 라이브러리를 사용해 데이터베이스와의 인터페이스를 구현하는 방법도 있습니다.
@Dao
interface UserDao {
@Query("SELECT * FROM user")
fun getAll(): List<User>
@Insert
fun insertAll(vararg users: User)
}
@Database(entities = arrayOf(User::class), version = 1)
abstract class AppDatabase : RoomDatabase() {
abstract fun userDao(): UserDao
}
이 계층의 중요한 특징 중 하나는, 내부 로직에서는 이 계층의 구체적인 구현에 의존하지 않는다는 것입니다. 즉, 비즈니스 로직이나 애플리케이션 로직은 안드로이드 프레임워크나 특정 라이브러리, 데이터베이스 등의 세부 구현에 의존하지 않고 독립적으로 작동하게 됩니다. 이를 통해 테스트와 유지보수가 용이하며, 기술의 변화에 더 유연하게 대응할 수 있습니다.
3. 실무 프로덕트에 적용된 클린아키텍처(작성 중...)
위에서 클린아키텍처에 대해서 알아보았습니다. 그러면 그 클린아키텍처라는 것을 안드로이드에 어떻게 적용할것인가? 라는 의문이 생길 것 입니다. 아래의 그림과 함께 차근히 안드로이드에 적용하는 클린아키텍처에 대하여 알아보도록 하겠습니다.
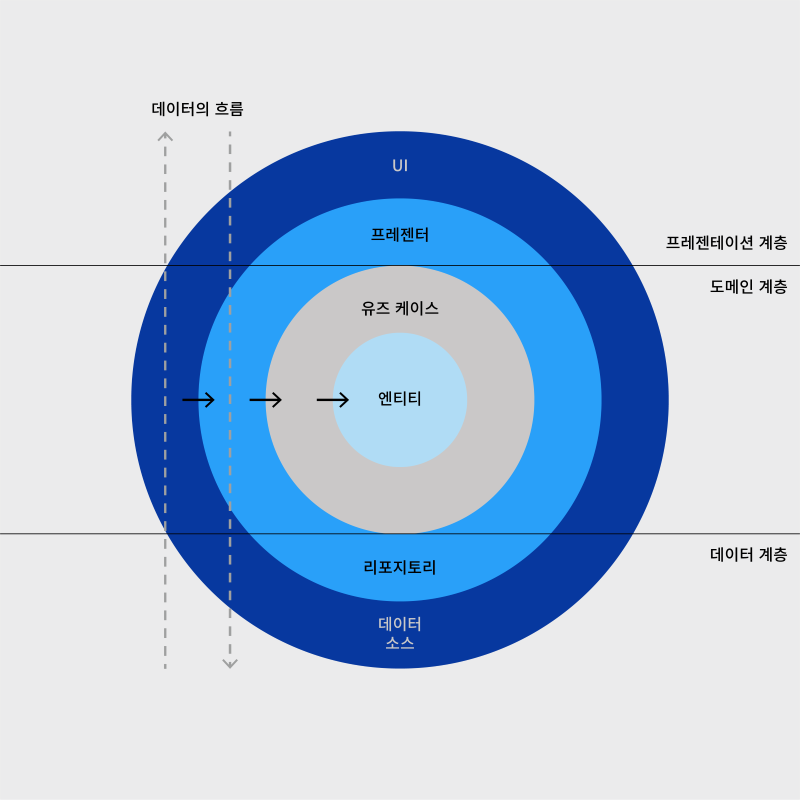
NHN Meetup 의 블로그 포스팅에 위의 클린아키텍처 그림과 비슷하게 설명하기에 좋은 그림이 있어서 이렇게 제가 레퍼런스를 달고 퍼오게 되었습니다. 위 그림을 기준으로 설명을 이어가도록 하겠습니다.
1. 데이터 계층(Data Layer)
데이터 계층은 클린 아키텍처에서 애플리케이션의 정보를 저장하고 검색하는 책임을 가집니다. 데이터 계층은 리포지토리와 데이터 소스로 이루어집니다.
1. 리포지토리(Repository)
선수 지식 : Repository Pattern 이란?
리포지토리는 비즈니스 로직이 필요로 하는 데이터 연산을 추상화한 인터페이스입니다. 일반적으로 CRUD(Create, Read, Update, Delete)와 같은 기본적인 데이터 액세스 기능을 제공합니다. 애플리케이션의 비즈니스 로직은 데이터 소스의 구체적인 세부사항을 몰라도 되며, 대신 리포지토리 인터페이스를 통해 데이터를 다룹니다. 이는 데이터 소스가 변경되더라도 비즈니스 로직을 변경하지 않고도 유연하게 대응할 수 있게 해줍니다.
2. 데이터 소스(Data Source)
3. 실제 적용 사례
저같은 경우는 실무 프로덕트에서는 데이터 소스를 사용하지는 않았습니다. 왜냐하면 어떠한 데이터소스가 여러군대의 레포지토리에서 계속 재활용이 되면 따로 만들어둬서 가져오는게 편하지만, 제가 개발한 화면과 관련화면에서의 리팩토링만을 진행해서 위와 같이 데이터 소스를 따로 만들어서 관리하는 것이 클래스가 늘어나서 번거롭다고 생각했습니다.
그러나 데이터 소스가 필요하다면, 적용하는 것에는 확실한 profit 이 있을 수 있기 때문에 상황에 맞게 잘 적용하면 될 것 같습니다. 그러면 아래의 데이터 소스를 제외한 레포지토리 패턴을 적용한 예제 코드를 보여드리겠습니다.
@Singleton
class OrderRepositoryImpl @Inject constructor(
private val apiService: ApiService,
@Dispatcher(DispatcherType.IO) private val ioDispatcher: CoroutineDispatcher
) : OrderRepository {
override suspend fun save(
order: Order
): OrderResponseModel? {
return withContext(ioDispatcher) {
try {
val response = apiService.createOrder(OrderRequest.from(order))
if (response.isSuccessful) {
response.body()?.toOrderResponseModel()
} else {
throw HttpException(response)
}
} catch (e: Throwable) {
throw DataThrowableResponse(e)
}
}
}
class OrderRepository @Inject constructor(
private val apiService: ApiService
) {
suspend fun save(order: Order): OrderResponseModel {
val orderResponse = apiService.createOrder(OrderRequest.from(order))
return OrderResponse.toOrderResponseModel(orderResponse)
}
}
저는 위의 예제 코드를 구현하면서 DataThrowableResponse(e) 와 같이 Throwable 를 어떻게 관리하면 좋을지 고민을 했었습니다. 왜냐하면, 데이터 레이어에서는 데이터 레이어의 예외 처리가 있을 것이고, 도메인 레이어는 도메인 레이어의 예외 처리, 프리젠테이션 레이어에서는 프리젠테이션 예외처리가 있을 것이기 때문입니다.
이것을 원래는 ViewModel 에서 한번에 몰아서 처리를 했었는데 뷰모델에서 각각의 케이스를 전부 나눠서 처리하기에는 코드가 복잡하다는 생각이 들었고, 레이어를 나눈다는게 각 책임에대해서 코드의 응집성을 지켜줄 수 있기 때문에 DataThrowableResponse 를 구현합니다.
response.isSuccessful가 아닐 때 HttpException(response)가 발생하게 한 이유는, HttpException()이 300..500 번대의 http 예외처리를 잡아 줄 수 있기 때문입니다. 그래서 HttpException()이 발생하면, 즉시 현재의 try 블록이 종료되고, catch 블록으로 제어가 이동합니다.
그리고 HttpException() 이 아니라 wifi 나 LTE 연결이 안되어서 발생하는 문제는 자동으로 IOException이 발생하면서 catch 블록으로 이동하기 때문에 HttpException() 처럼 따로 랩핑해서 처리해 줄 필요가 없습니다.
data class DataThrowableResponse(
val code: Int?,
var statusCode: Int?,
var path: String? = null,
override var message: String
) : Exception() {
constructor(throwable: Throwable) : this(
code = null
,statusCode = null
,path = null
,message = throwable.localizedMessage ?: ""
) {
when (throwable) {
is HttpException -> {
statusCode = throwable.code()
path = throwable.response()?.raw()?.request?.url.toString()
when (throwable.code()) {
in 300..500 -> {
throwable.response()?.let {
try {
val error = Gson().fromJson(
it.errorBody()?.charStream(),
DataThrowableResponse::class.java
)
message = error.message
} catch (e: IllegalStateException) {
}
}
}
else -> {
message = "일시적인 오류가 발생 했습니다. \n" + "다시 시도해 주세요."
}
}
}
is IOException -> {
when (throwable) {
is UnknownHostException -> { message = "네트워크 연결이 끊어졌습니다.\n다시 시도해 주세요." }
is SocketTimeoutException -> { message = "연결 시간이 초과 되었습니다.\n다시 시도해 주세요." }
is ConnectException -> { message = "네트워크 연결이 끊어졌습니다.\n다시 시도해 주세요." }
}
}
}
}
constructor(message: String) : this(
code = null, statusCode = null, path = null, message = message
)
}이렇게 데이터 레이어에서 발생할 수 있는 예외처리는 Exception() 을 상속받아서 DataThrowableResponse 로 한번에 처리할 수 있게 진행해서 예외 처리 또한 레이어별로 구현하게 되었습니다.
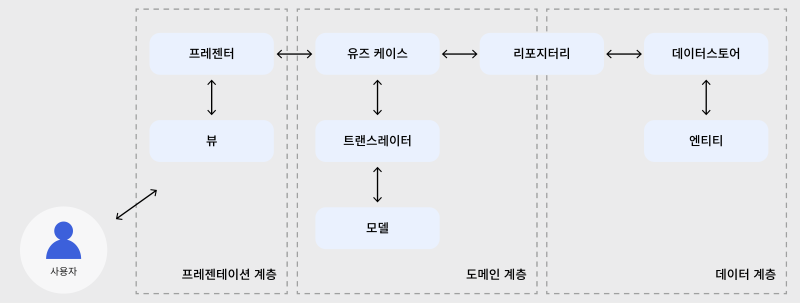
NHN Meetup 의 블로그 포스팅에 위의 데이터 레이어에서 받아온 값들이 어떻게 도메인 레이어와 프레젠테이션 레이어에 전파되게 되는지 설명하기에 좋은 그림이 있어서 이렇게 제가 레퍼런스를 달고 퍼오게 되었습니다. 위 그림을 기준으로 도메인 레이어와 프리젠테이션 레이어에 대한 설명을 이어가도록 하겠습니다.
사용자의 인터렉션이 발생하면 이벤트는 처음 제시한 원을 기준으로 위에서 아래로, 아래서 위로 흐릅니다. 사용자가 버튼을 클릭하면 UI → 프레젠터 → 유즈 케이스 → 엔티티 → 리포지터리 → 데이터 소스로 이동하게 됩니다.
그런데 위 흐름을 보면 다음과 같은 의문이 생길 수 있습니다.
- 위 원에서 도메인 레이어에 속해 있던 엔티티가 왜 데이터 레이어에 있지?
- 트랜스레이터(mapper)는 왜 필요한 것일까?
- 도메인 레이어가 데이터 레이어를 알고 있어야 데이터를 보낼 수 있는 게 아닌가?
위 질문에 대한 생각은 저도 클린아키텍처를 처음 접했을 때 헷갈렸던 부분 입니다.
먼저, 데이터 레이어의 엔티티는 맨 처음 제시한 원의 엔티티가 아닙니다. 원의 엔티티는 도메인 레이어의 Model이며, 데이터 레이어의 엔티티는 네트워크나 로컬 DB에서 받아온 DTO를 의미합니다. 따라서 레이어를 이동할 때 해당 레이어에 맞게 데이터 형변환을 해야 합니다.
도메인 레이어에서 모델이 트랜스레이터를 거쳐, 데이터 레이어의 엔티티로 변환되는 것입니다(이는 반대로도 가능합니다). 또한 실제로 도메인 레이어는 데이터 레이어를 참고하고 있지 않습니다. 그것은 바로 리포지터리에서 이루어지는 의존성 역전 법칙 때문입니다.
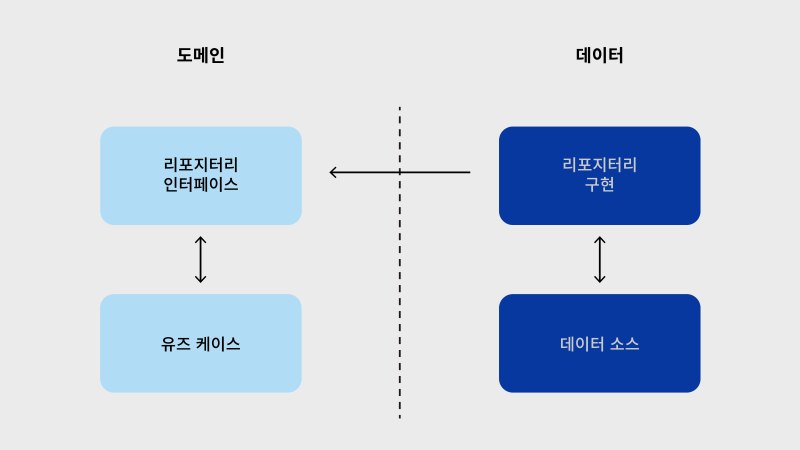
의존성 역전이란?
참고 링크 : 의존성 주입 : DI (Dependency Injection) (1)
객체 지향 프로그래밍에서 의존 관계 역전 원칙은 소프트웨어 모듈들을 분리하는 특정 형식을 지칭한다. 이 원칙을 따르면, 상위 계층(정책 결정)이 하위 계층(세부 사항)에 의존하는 전통적인 의존 관계를 반전(역전)시킴으로써 상위 계층이 하위 계층의 구현으로부터 독립되게 할 수 있다.
즉, 도메인 레이어에서 리포지토리 인터페이스를 만들어서 유즈케이스에서는 이 인터페이스를 참조하면 됩니다. 그렇게 되면 데이터 레이어에 직접 의존하는 것이 아니게 되어 클린아키텍처 원칙에 위배되지 않게 됩니다.
2. 도메인 계층(Domain Layer)
3. 프리젠테이션 계층(Presentation Layer)
- 선수 지식
클린 아키텍처에서의 프레젠터는 View와 비즈니스 로직 사이의 중간 계층입니다. View가 사용자의 입력을 프레젠터에 전달하고, 프레젠터는 이를 처리한 후 적절한 결과를 다시 View에 전달합니다. 이를 통해 View는 자신의 기능에만 집중할 수 있고, 프레젠터는 비즈니스 로직과 데이터를 처리하는 역할을 담당합니다.
그리고 가장 중요한 것은 우리가 사용하는 디자인패턴 MVVM, MVP, MVI 등이 이 프리젠테이션 계층을 어떻게 효율적으로 코드를 분리 유지 보수를 할 것인가에 대한 고민으로 부터 파생되었다는 것 입니다. 그렇기 때문에 개인적으로, 프리젠테이션 계층이 안드로이드 개발의 꽃이 아닌가라는 생각이 있습니다. 그러면 아래에서 프리젠테이션 계층에 대해서 세부적으로 알아보도록 하겠습니다.
1. 사용자 입력 처리
프레젠터는 View 로부터 입력을 받아 비즈니스 로직을 수행하고 그 결과를 View에 전달하는 역할을 합니다. 예를 들어, 사용자가 어떤 버튼을 누르면 프레젠터는 이를 처리하여 적절한 비즈니스 로직을 호출하고 그 결과를 View에 전달합니다.
2. 데이터 변환
프레젠터는 View가 이해할 수 있는 형태로 데이터를 변환하는 역할도 합니다. 비즈니스 로직이나 데이터 계층에서 가져온 데이터를 View에 맞게 변환하여 표시해야 하는 경우가 많은데, 이런 작업은 프레젠터에서 이루어집니다.
3. 상태 관리
프레젠터는 애플리케이션의 현재 상태를 관리하는 역할도 합니다. 예를 들어, View가 특정 상태에 있는지, 어떤 데이터를 보여주고 있는지 등을 추적하고 관리합니다.
안드로이드에서는 일반적으로 MVP(Model-View-Presenter) 패턴이나 MVVM(Model-View-ViewModel) 패턴을 사용하여 프레젠터를 구현합니다. MVP 패턴에서 프레젠터는 사용자 인터페이스와 모델 사이의 중개자 역할을 하며, 사용자 인터페이스가 비즈니스 로직을 직접 처리하지 않도록 합니다. MVVM 패턴에서는 ViewModel이 프레젠터의 역할을 하며, 뷰와 모델 사이의 데이터 바인딩을 관리합니다.
프레젠터 또는 ViewModel을 사용함으로써, 애플리케이션의 로직을 테스트하기 쉬워지고, 뷰와 모델 사이의 의존성이 줄어들게 됩니다. 이로 인해 코드의 유지 보수성이 향상되고 애플리케이션의 전체적인 품질이 향상될 수 있습니다.
4. reference
https://developer.android.com/topic/architecture?hl=ko
https://meetup.nhncloud.com/posts/345
https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html#:~:text=We%20also%20do%20not%20expect%20this%20layer%20to%20be%20affected%20by%20changes%20to%20externalities%20such%20as%20the%20database%2C%20the%20UI%2C%20or%20any%20of%20the%20common%20frameworks.%20This%20layer%20is%20isolated%20from%20such%20concerns.
